
2022卡塔尔世界杯顺利收官,作为世界顶级体育赛事,此次卡塔尔世界杯在全球掀起了足球观赛热潮。在这场足球盛宴中,中国移动作为本届世界杯持权转播商,为“科技观赛”注入了“人文情怀”。


手语数字人弋瑭
据悉,全球有超 4亿人听力受损,被“听不清、听不真”所困扰,为了打破“无声的世界”,让更多人同频感受到体育赛事的激情,中国移动咪咕公司推出首个数字人手语主播弋瑭,为听障人士打通“信息无障碍”的桥梁。
 弋瑭解说画面
弋瑭解说画面
整体技术路线
北京冬奥会期间,咪咕视频针对各项赛事转播上线的“AI智能字幕”,有个温暖的名字——“为了听不到的你”,在国内首次实现大型国际赛事超高清直播的实时双语字幕创新规划化应用,也被网友称为冬奥观赛最暖心的功能之一。
习近平总书记叮嘱:“办冬奥不是一锤子买卖,不能办过之后就成了‘寂静的山林’。”冬奥会后,咪咕技术团队持续优化智能播报课题,融合动作数据捕捉、神经网络自然语言处理、高逼真度3D渲染等多项技术,搭建手语数字人播报引擎,实现了手语数字人在大型体育赛事直播场景中的应用。
 弋瑭解说画面
弋瑭解说画面
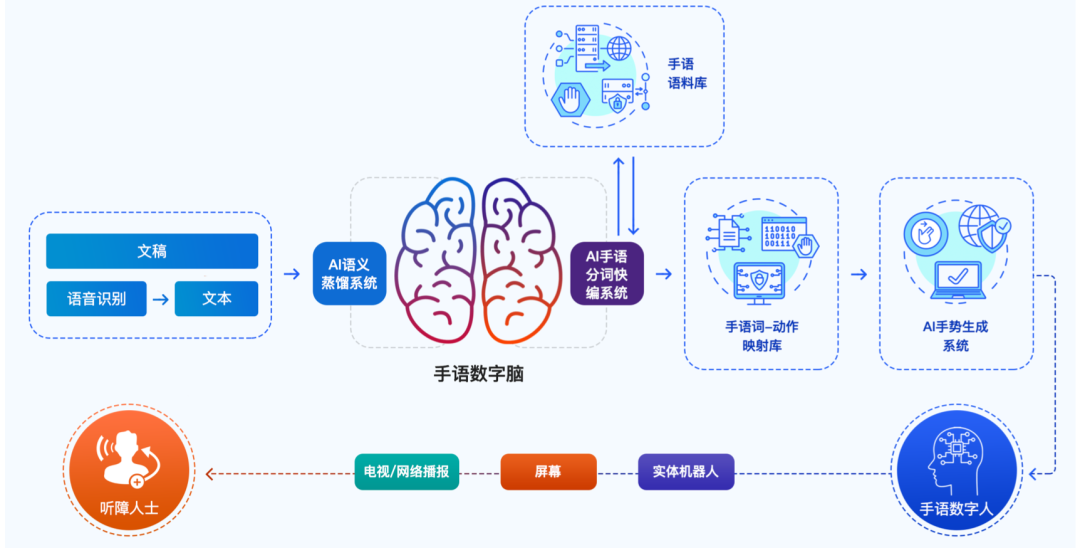
咪咕AI手语数字人整体技术路线为:通过文稿或语音作为源数据输入;以手语与料库为基础,由AI语义蒸馏系统和AI手语分词快编系统组合成的手语数字脑,进行手语转写;通过手语词—动作映射库,进行AI手势生成;最后驱动手语数字人,在实体机器人、屏幕或电视/网络播报终端进行展示,服务于听障人群。
 整体技术路线
整体技术路线
直播技术框架
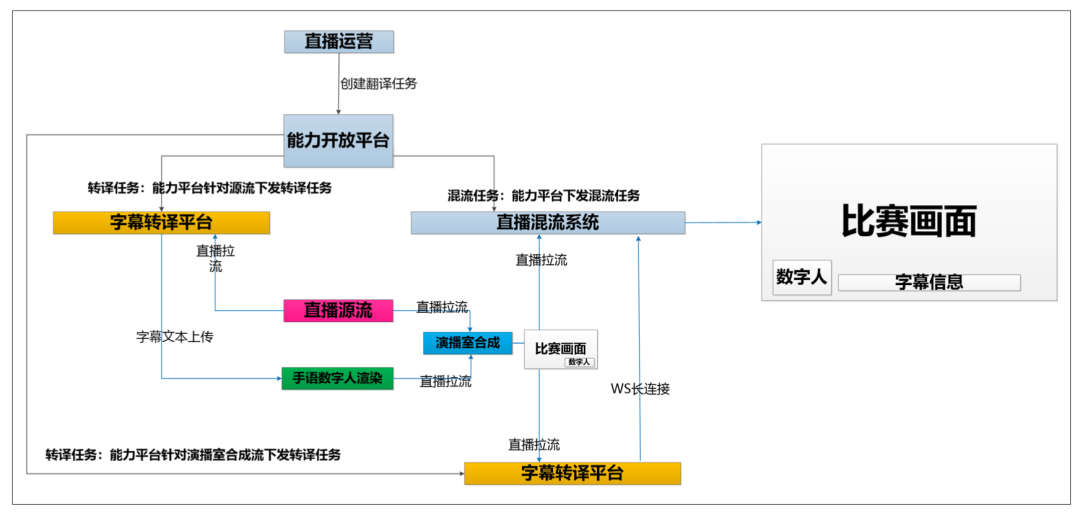
手语数字人在世界杯期间应用于10场重点赛事,从直播技术层面,整合了咪咕公司多个技术平台与系统能力,分别为:
直播运营系统:所有直播频道的任务下发。
能力开放平台:接收运营系统任务,并将相关技术参数下发给相关技术平台和系统。
字幕转译平台:针对直播源流进行实时AI字幕转译,输出WS字幕流。
演播室系统:对手语数字人进行实时、高精度渲染、抠像,并实现与直播源流的实时合成输出。
直播混流系统:对演播室合成流、字幕流进行编码混流,输出最终直播流给直播频道,完成直播流程。
多平台整合的难处在于需要实现各个平台和系统的优势互补,为了实现源流、数字人、字幕3路信源在延时量、准确性的最优化,手语数智播报技术框架经过接近一个月时间的技术验证和多版方案迭代后才正式成型。
 直播技术框架
直播技术框架
直播混流系统的优势在于对字幕流的SEI编解码处理,但其图形渲染能力较弱;演播室系统优势在于基于Unreal引擎的影视级渲染能力,但缺乏对于字幕信息的SEI编码能力,因为需要在APP播放器中实现字幕的语种切换、开关等操作,而传统演播室制作的字幕形式并不适合用在本案例中。
因此在整体框架中,字幕转译平台进行了2次字幕转译处理:
第1次输出字幕流,实现了对于演播室图形渲染引擎中的手语数字人动作驱动,在演播室环境内完成了源流+数字人画面的合成。
第2次输出字幕流至混流系统,实现了演播室画面和字幕流的合成并输出给直播频道。两路字幕流处理之间的时延差异,通过演播室技术系统内的延时器来拉齐,综合多方面因素,用一定的延时量换取了多路信源在视觉上的绝对统一,取得了良好的播出效果。
关键技术
高精准驱动字幕
字幕是AI手语的源驱动力,字幕的准确率直接影响AI手语的表达准确与否。但是,影响体育场景AI字幕准确率的因素众多,例如场上噪音干扰、专业体育术语名词、解说语速过快、解说口音等,智能字幕采取多种技术实现高精准驱动字幕,提供高质量的输入源。
针对噪音干扰,采用基于深度学习的场景化前置语音降噪技术,选用基于时频域方法中的基于时频掩蔽(mask)的方法进行模型搭建,利用傅立叶变换提取音频帧的频域特征,将傅立叶变换后的特征提供给长短记忆网络(LSTM)+全连接网络,训练得到音频特征在频域的mask,然后利用mask得到纯净语音信号的在频域特征,利用反傅立叶变换得到时域的音频帧,有效降低球场欢呼声、音乐等场上音的干扰影响,提升转写输入音频质量。
 基于深度学习的场景化语音降噪
基于深度学习的场景化语音降噪
针对体育场景人名及运动术语众多、难于正确转写的难题,依托中国移动九天人工智能平台大体育精细化知识图谱,深度构建世界杯足球图谱热词体系,词汇量超20万,针对每场比赛的球队特征,自动关联出每场比赛相关的热词,包括双方球队、首发球员、替补球员、教练、主裁判等专业术语词汇集合。
 知识图谱球队球员关联样例
知识图谱球队球员关联样例
结合比赛的时间维度,实现时效图谱热词,关联出解说可能提及的热门球员及话题热词等,最精准地覆盖解说可能提及的专业术语范围,为下一步的智能纠错提供基础。
针对解说过快与口音的问题,研发智能语义纠错系统,制定多种纠错策略,并结合行业领先的快速纠正(fastcorrect)语音纠错模型及上千场次的解说语料深度训练,对偏离语义的字幕进行AI纠错优化,让字幕更能还原解说本意,让智能字幕更“懂足球”。
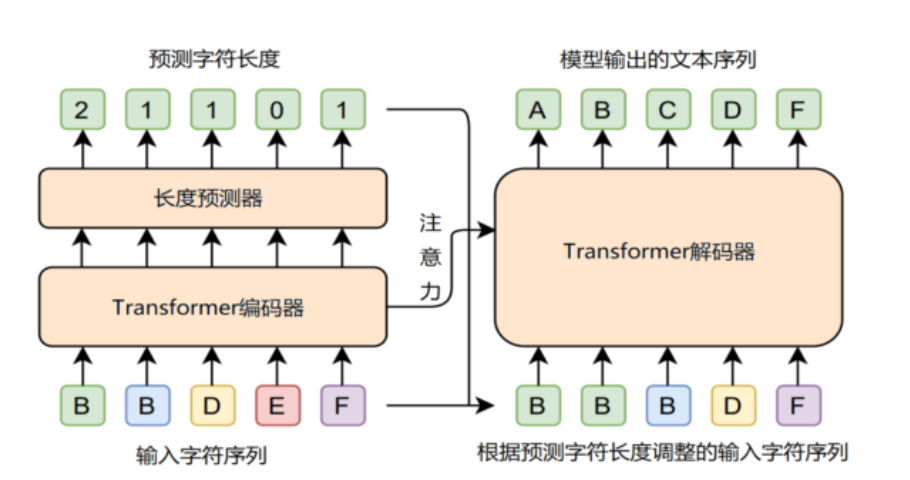 Fastcorrect语音纠错模型
Fastcorrect语音纠错模型
纠错技术通常存在误纠的情况,为及时发现误纠,降低误纠带来的影响,自研全流程循环迭代的字幕转写优化方案,建立误纠检测与纠错回溯机制,基于赛后的词热度分析等技术,回馈与校正纠错系统,进而不断提升语言学模型精准度。目前,世界杯足球场景中文字幕平均准确率超96%,最高达98%。
中文语义蒸馏与分词快编
由于手播速度不及口播速度,字幕和手语词序列的长度存在不对等问题,需要对字幕进行语义提取,采用语义蒸馏技术,主要包括质量控制信号、广义线性(GLM)预训练模型和对比学习,三者有效配合实现精准高效提取语义词汇。
为了使语义蒸馏后的句子内容语义相对可控,设置质量控制信号作为有限制生成信号。质量控制信号是指句对中的复杂句与简单句之间的比值信息来表示词法复杂度、句法复杂度以及句子长度等。
具体来说,质量控制信号包括句子长度比、编辑距离比、词汇复杂度比和句法树深度比等信息。由于标注数据集缺乏,采用基于无监督学习方式挖掘复杂句—简单句句对并计算每个句对之间的质量控制信号。
GLM预训练模型基本原理是基于自回归空白填充,按照自编码的思路,从输入文本中随机地空白出连续跨度的token,并按照自回归预训练的思路,训练模型依次重建这些跨度。
鉴于GLM可以在自然语言理解(NLU)和文本生成(含有条件和无条件)方面表现出色,采用GLM预训练模型进行微调以实现语义蒸馏。
GLM预训练模型在各种条件文本生成任务上取得了显著的性能。然而,其中大多数研究是在Teacher-Forcing机制下训练,容易出现暴露偏差问题。为解决该问题,采用对比学习框架,将模型暴露于给定输入语句的各种有效或不正确的输出序列。
根据对比学习框架,可以通过对比正对和负对训练模型学习基础真句的表示,其中从同一批中选择负对作为随机的非目标输出序列,然后将源文本序列和目标文本序列投影到潜在嵌入空间。最终使源序列和目标序列对之间的相似度最大化,同时使负序列对之间的相似度最小化。
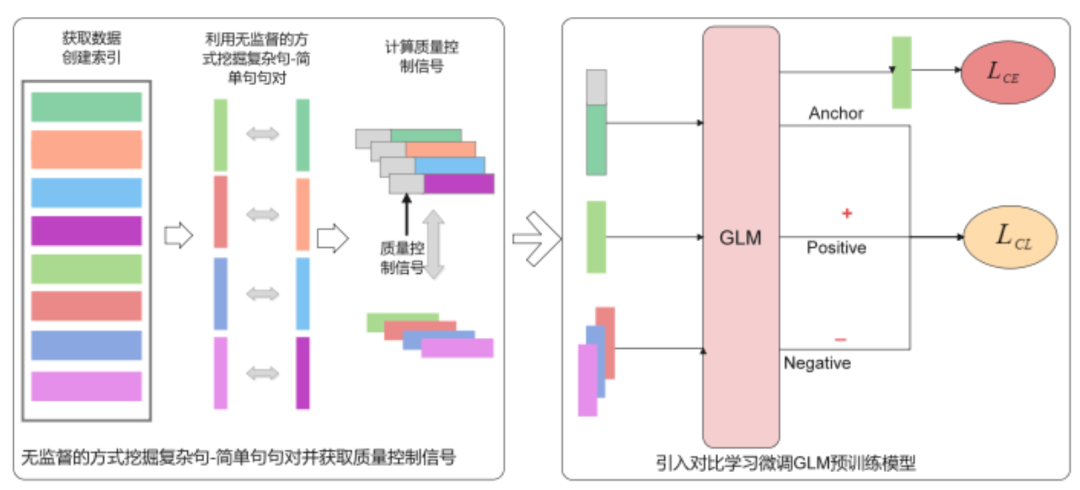 融合无监督学习和对比学习的语义蒸馏模型
融合无监督学习和对比学习的语义蒸馏模型
通过以上方法的结合,不仅可以保证简化内容质量可控,并且能够提高简化句子的忠实度,为下一步AI手语分词奠定基础。
通过中文语义蒸馏模型提取文本语义信息,将语义信息发给手语分词快编模型;基于手语词典库,通过手语翻译编码算法进行分词,然后发送给手语解码器进行手语匹配。因此基于序列到序列、端到端的深度学习手语分词快编模型,能够有效地将输入中文语句转换成符合手语表达的词汇序列,驱动数智手语主播完成一系列相应动作。
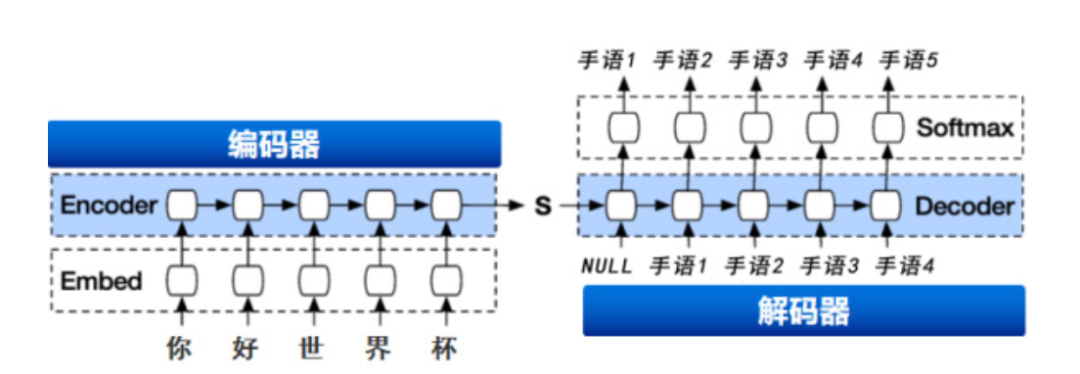 基于编码器-解码器的AI 手语分词快编算法
基于编码器-解码器的AI 手语分词快编算法
人体三维结构化参数表征
人体三维结构化参数表达是数字人运动驱动核心关键,基于人体运动学和计算机图形学知识,通过骨骼关键点和物体基础形变参数结构化定义三维数字人运动状态,从而实现引擎快速实时渲染驱动。
数字人形象制作完成后,需要根据角色模型定义骨骼模型,将骨骼映射分为Body、Head、Hand三个部分。
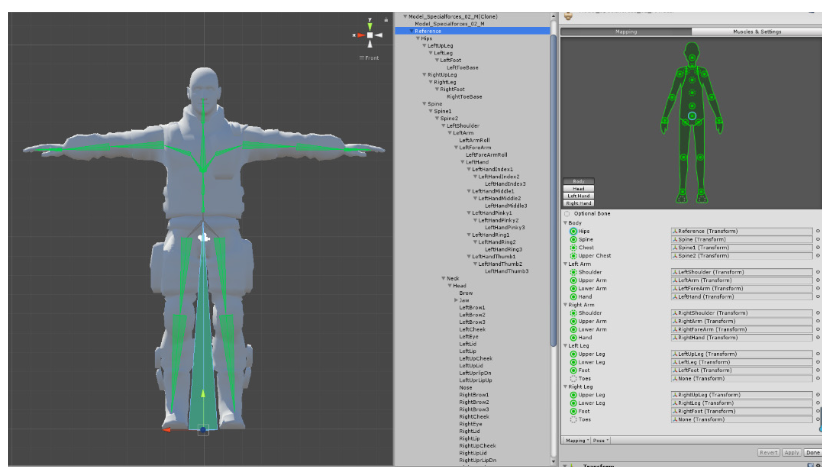 数字人骨骼映射
数字人骨骼映射
其中,身体骨骼分为Body、LeftArm、RightArm、LeftLeg和RightLeg五个分组,包含了人形角色模型骨骼的基本结构。
人物脊椎的骨骼分为四部分:髋关节Hips、脊柱Spine、胸部Chest和上胸部UpperChest,结合“Hierarchy”面板中的骨骼层级结构来看,这四部分是人体模型的主要节点,髋关节的子节点为左腿、右腿和脊柱,脊柱的子节点为胸部,胸部的子节点为上胸部,上胸部的子节点是左肩、右肩和颈部。通过这样的层级将模型骨骼构建成类人骨骼Humanoid。
人物脊椎决定了骨骼结构,四肢分别作为脊椎上某一关节点的子节点分支,并以相同的方式构建肢体骨骼。由髋关节分支的左腿和右腿UpperLeg,子节点分别为其小腿LowerLeg,小腿子节点为脚部Foot,如此构建了腿部骨骼。由上胸部分支的左肩和右肩Shoulder,子节点分别为其上臂UpperArm,上臂子节点为下臂LowerArm(骨骼上或命名为前臂ForeArm),下臂子节点为手部Hand,如此构建了手臂骨骼。
三维手势姿态估计,是一种通过多个特定关键点的三维位置坐标,来近似整个手各个关节点信息的细粒度手势识别。
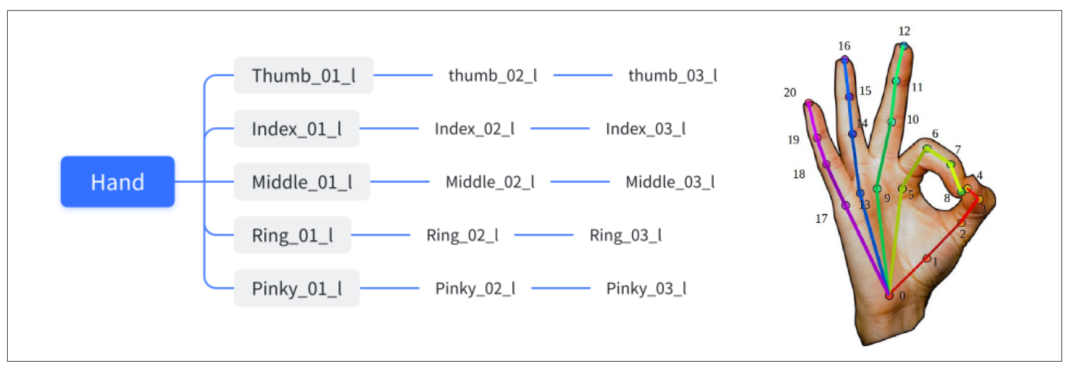 手部骨骼定义
手部骨骼定义
人体面部表情包含两个不同维度信息,一个是面部形态信息,一个是面部表情信息。面部形态和面部表情因人而异,不同的两个人做同样的表情动作,面部形态和面部表情存在很大差异。
尤其是手语表达,不同的面部表情信息在语义上亦有不同。项目设计一种新的表情编码系统,将面部表情语义与特征点信息进行关联。
面部表情编码系统FACS(FacialActionCodingSystem,FACS)以人脸解剖学结构为基础,根据人脸各部分肌肉功能将面部表情划分为若干个相互独立的表情单元,通过选取不同的表情单元进行组合,即可得到不同的表情情功能。
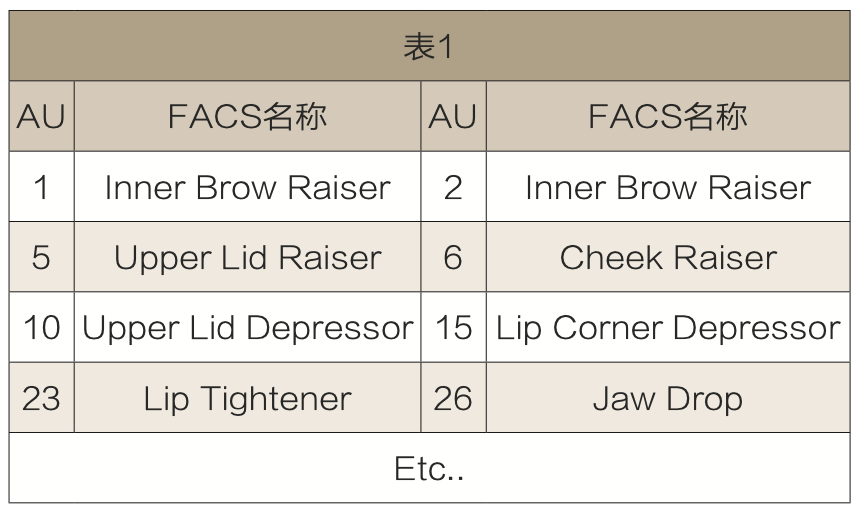
通过组合AU1(眉毛内侧上扬)、AU6(脸颊上扬)、AU12(眼角紧缩)、AU14(产生酒窝)就可以产生高兴的表情,每个表情单元可以拥有一个独立的组合系数,从而建立面部特征点与FACS之间的关联得到带有语义信息的面部表情参数。
通常情况下,系数0表示AU单元未激活,系数1表征AU单元激活幅度达到最大。人体面部表情可以通过调节各个AU单元系统大小灵活表征。
快速人体三维运动数据捕捉
手语数字人的实现依赖庞大的手语动作库,在前期实践过程中,需要通过手语老师进行海量的动作库建立。动作捕捉是一项基本的采集手段,其目标是使计算机对数据中多个人体的不同关节及五官(如眼、头、手、髋、踝)等关键点进行准确定位,并将属于同一行人个体的关键点准确连接,以描述多人不同的姿态信息。
 人体三维运动捕捉
人体三维运动捕捉
关键点检测技术作为一种具有广泛应用场景的基础算法,其描述的关键点信息可用于对行人个体的静止姿态、连续动作进行刻画,从而对异常行为检测、动作分类、行人再识别等相关研究起到辅助推断作用。
通过对目标上特定光点的监视和跟踪来完成运动捕捉的任务。从理论上说,对于空间的任意一个点,只要它能同时被两台摄像机所见,则根据同一瞬间两相机所拍摄的图像和相机参数,即可以确定这一时刻该点的空间位置。
当相机以足够高的速率连续拍摄时,从图像序列中就可以得到该点的运动轨迹。相机连续拍摄表演者的动作,并将图像序列保存下来,然后再进行分析和处理,识别其中的标志点,并计算其在每一瞬间的空间位置,进而得到其运动轨迹。
动作捕捉技术基本原理在于通过不同视角的相机对人身体上的反光Marker点进行拍摄,通过多相机定位原理,定位出该Marker点的空间位置,通过点的位置推算出人体骨骼运动数据,但是由于人体在运动过程中不可避免地出现遮挡,遮挡Marker点后,会导致人体骨骼数据解算不稳定,最终导致捕获的数据无法直接运用于影视动漫等行业中。
本项目采用关键点定位解算其余点的位置信息,当Marker点出现遮挡时,会造成数据计算量瞬间增大,这也是高精度实时动作捕捉的重大挑战。
多视点图像精准采集和配准是动捕数据采集的基础,项目设计PTP同步触发,实现多台高清相机每帧图像的同步拍摄,在无需外部信号的前提下保证同步精度在10微秒量级;提升相机分辨率,保持多相机系统的一致性,保证多相机系统视频采集的实时性。
通过拍摄并解算出手语老师身上关键节点粘贴的反光Marker点的位置信息,解算出人体骨骼信息,获取人体骨骼精确的运动轨迹,并输出人体骨骼运动轨迹信息推算出出现遮挡情况下的骨骼信息:
创建人体骨骼时,保存各个Marker点之间的相对位置信息,在人体运动出现遮挡时,通过保存的相对位置信息,推算出被遮挡点的实时位置,并保持人体骨骼信息稳定输出,即当小臂出现遮挡时,通过手掌和上臂的点信息推算出小臂信息。
高逼真度3D渲染
将接收到的手势动作序列融合表情、唇语、肢体等信息,通过多模态的高逼真度3D渲染,用多种表现形式呈现给用户。
在高逼真度3D渲染这一步,我们将前序算法输出的动作、唇语、表情等参数应用到构建的3D人物模型上,生成具有高逼真度的视频输出。主要需要解决皮肤渲染、头发渲染等问题。
人体皮肤是一种典型的半透明材质,尤其在鼻子、耳朵等区域尤为明显,在高逼真度的皮肤渲染中,需要考虑次表面散射效应,实践中常常使用屏幕空间模糊算法对这一效应进行近似模拟,通过一系列高斯函数来近似模拟皮肤的半透明效果。
人物头发细节也是提升真实感的重要部分,头发由大量细纤维组成,具有特殊的反射性质,故在渲染时不能使用漫反射等简单模型进行刻画,实践中常使用Kaiya-Kay模型和Marchner模型等算法。
手语作为听障者参与现代社会生活的重要媒介,在手语翻译员稀缺、手语翻译质量得不到保障等背景下,手语字幕帮助听障人士打破了“无声的世界”,打通了“信息无障碍”的桥梁,具有广阔的应用前景和社会经济价值。
中国移动有温度的科技将快乐与美好无限放大,让听障人士同频共振“听到”到世界的声音,真正做到“科技不让每一个人掉队”,将全球目光持续聚焦卡塔尔的绿茵场。奥运、冬奥、世界杯、亚运会,作为这一系列大型国际赛事的特权转播商,中国移动咪咕公司将结合5G传输优势,深耕元宇宙技术,持续为观众们带来沉浸式观赛体验。
作者 | 咪咕视讯科技有限公司 陈望都 林晓青
来源:影视制作
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。