
摘 要:全光传送网络作为新基建和算力网络的坚实底座,需要从带宽驱动的管道网络向面向泛在算力业务的全光算力网络演进。首先介绍了算力网络发展演进趋势及国内运营商算力网络布局现状,随后对全光算力网络总体架构及关键创新技术进行了研究分析,在此基础上提出了推动全光算力网络发展建设的四个重要举措,打造大带宽、低时延、高可靠、高安全、灵活可调的全光算力网络,为泛在算力资源提供超强的运送服务能力,实现用户一跳接入、一跳入算。
01 概 述
以数据资源为关键要素,以现代信息网络为主要载体,以信息通信技术融合应用、全要素数字化转型为重要推动力的数字经济正加速发展,对现有生产方式、生活方式和治理方式产生了深刻的影响和变革。数字经济发展已经成为重组全球要素资源、重塑全球经济结构、改变全球竞争格局的关键力量。以5G、人工智能、大数据中心、工业互联网等为代表的新型基础设施建设是助力数据经济发展的重要支撑和关键抓手。
在2021年10月18日中共中央政治局第三十四次集体学习中,习近平总书记提出:要加快新型基础设施建设,加强战略布局,加快建设高速泛在、天地一体、云网融合、智能敏捷、绿色低碳、安全可控的智能化综合性数字信息基础设施,打通经济社会发展的信息“大动脉”。2021年5月,国家发改委等四部委联合出台《全国一体化大数据中心协同创新体系算力枢纽实施方案》,明确提出布局全国算力网络国家枢纽节点,打通网络传输通道,提升跨区域算力调度水平,加快实施“东数西算”工程,构建国家算力网络体系。从网络角度,算力网络是面向计算和智能服务的新型网络体系,全光底座和IPv6+是算力网络的技术基石,增强网络内生算力是算力网络演进的重要方向;从算力角度看,算力网络是网络化的算力基础设施,是依托网络构建的多样化算力资源调度和服务体系;从服务角度看,算力网络的目标是提供算网一体服务,是云网融合服务的新阶段,是数字基础设施服务的新形态。作为国家第四大资源调配工程,“东数西算”是算力网络现阶段的关键着力点。如何服务好国家“东数西算”战略,打造超强运力、超低时延、算力与网络协同的一体化算网服务能力,高品质的全光算力网络是关键要素之一,也是整个算力网络最重要的基石。
本文通过分析算力网络发展演进趋势及国内运营商算力网络布局现状,研究全光算力网络演进架构及关键创新技术,提出全光算力网络未来发展建设策略,为运营商服务国家“东数西算”战略,打造面向算力网络的高品质全光传送底座提供思路和方向。
02 算力网络发展及趋势分析
2.1 算力网络发展趋势
数字经济时代,新技术、新业态、新场景和新模式不断涌现,数字经济形态成为经济发展的新动能。随着新一轮科技革命和产业变革的深入发展,以算力为核心生产力的时代正在加速到来。算力网络作为连接用户、数据、算力的主动脉,与算力的融合共生不断深入。算力网络发展目标是推动计算与网络的深度融合,提供算网一体服务。过去几年行业一直在推动云网融合,通过SDN技术增强网络的弹性和灵活性,使网络能更好支撑云计算的发展。近年随着人工智能和边缘计算的发展,云计算开始从中心云走向边缘,算力呈现泛在化和多样性趋势。为了顺应这一新趋势,算力网络需要具备一网多云、云边协同和一体供给能力,为智能时代提供算网一体化基础设施。算力网络发展趋势分析如图1所示。
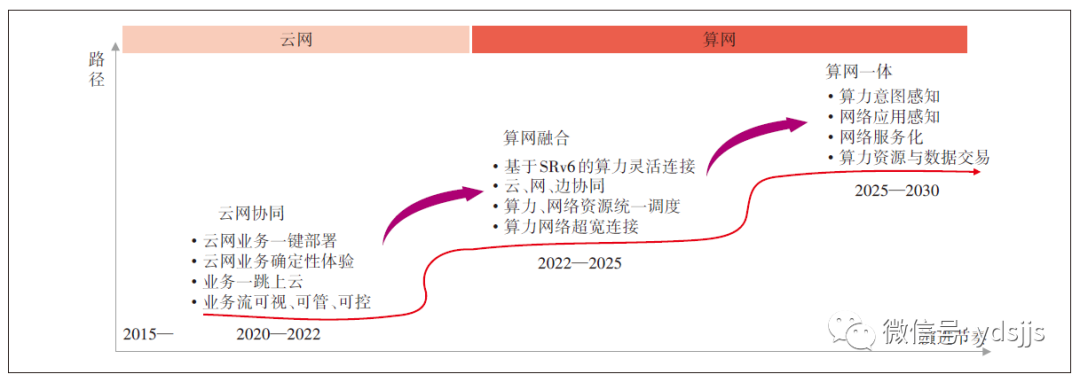

图1 算力网络发展趋势分析
2.2 国内运营商算网架构及全光网发展目标
政策、技术和业务三大因素驱动算力网络走向前台,为运营商数智化转型、实现价值重构提供新动能。以算力为核心的能力建设是运营商实现转型升级、重构产业价值生态的重要契机,提供了继基础网络、云之后的新的业务增长点,为运营商实现“第2曲线”增长注入新动能。作为数字信息基础设施建设和运营的国家队和主力军,三大运营商正加快对算力网络的布局和建设。
中国移动2021年11月发布《算力网络白皮书》,将以算力为中心,网络为根基,打造网、云、数、智、安、边、端、链等多要素融合的新型信息基础设施,推动算力成为与水电一样“一点接入、即取即用”的社会级服务,最终达成“网络无所不达,算力无所不在,智能无所不及”的发展愿景。在整个算网架构中,全光底座是算网底座的基石,其目标是面向算力网络、5G+垂直行业、政企专线三大场景,打造基于OXC的全光高速互联、全光灵活调度的光电联动全光网络底座。
中国电信实施“云改数转”战略,深入推进云网融合,结合天翼云打造基础底座,并着重云网技术的自研和自主可控。《云网融合2030技术白皮书》中提出云网融合发展愿景是形成云网一体化的融合技术架构,实现简洁、敏捷、开放、融合、安全、智能的新型基础设施的资源供给。在整个算网架构中,全光网络是云网基础设施的组成部分,其目标是面向单点入单云、单点入多云、多点入多云三大场景,打造具备全光传输、全光交换、全光接入、全光承载、全光智治和全光云网这六大特征的全光网2.0目标架构。
中国联通2021年12月发布《中国联通建设新型数字信息基础设施行动计划》,明确以CUBE-Net3.0网络创新体系为目标架构,将算力网络与计算资源整合,推进架构领先、质量领先、服务领先的算力新网络布局,不断增强网络内生动力,提升算力资源感知,打造中国联通低时延、广联接、智能化、便捷化的一体化新型算力网络,实现“联接+感知+计算+智能”的算网一体化服务。在整个算网架构中,全光底座是算力网络最重要的承载基石,其目标是面向算力和上层业务,构建“ROADM+OTN”光电双平面立体架构,打造为算力提供超强运送能力的智能、开放的全光传送底座,实现业务的高质量传送。
03 全光算力网络架构及关键技术
3.1 全光算力网络架构
随着国家“新基建”和“东数西算”战略的发布和实施,对光网络的布局和建设提出更高的要求。当前光网络还存在架构复杂、适应性差、智能化程度低等问题,迫切需要从传统的带宽驱动的管道网络向算力和体验驱动的全光算力网络演进。全光算力网络可提供超大带宽、超长距离、超低时延、超高安全、超高可靠、灵活可调、绿色节能的高品质连接,能够快速高效地将“东数”运送到“西算”,助力国家“东数西算”战略实施,提升跨区域算力调度水平,为泛在算力资源提供运力保障。
全光算力网络以实现算网一体服务为目标,提升光网络基础承载能力和业务提供能力,推动全光底座的智能开放和云光一体化服务,为泛在算力资源的高效连接调度提供高品质、低时延的运力保障。这需要通过以下3方面来实现。
一是提升全光底座基础承载能力,为算力调度提供强大的运力保障。以超高速率、超大容量、超长距离、超宽灵活、超强智能为目标,保障算力资源高效连接调度。
二是实现高速泛在光接入,推动高品质光业务网发展。构建架构稳、覆盖全的综合业务区和全光锚点,提供多种技术体制的高速泛在光接入,实现灵活便捷全光入云。
三是推进光网络开放解耦与智能化调度。以SDN化为抓手,推动光网络开放与解耦;并通过网络AI、数字孪生等技术创新,不断提升光网络自动化和智能化水平。
全光算力网络总体架构如图2所示。
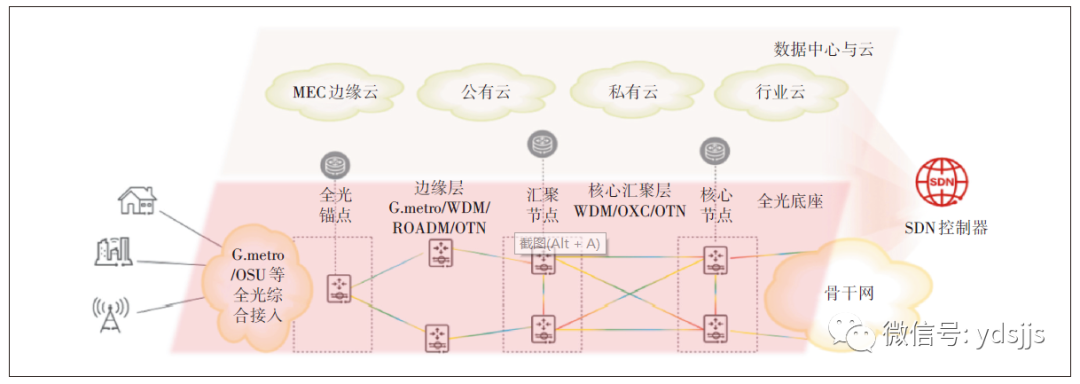
图2 全光算力网络总体架构
3.2 全光算力网络关键技术
3.2.1 超100G传输技术
高速率、长距离、大容量永远是传输技术追求的方向和目标,也是为算力网络提供超强运力保障的内在要求,全光算力网络需要依托超高速传输。200G/400G/800G等超100G传输技术在100G基础上进一步提升系统容量,降低每比特光传输成本和功耗,有效地解决运营商业务流量及网络带宽持续增长的压力。提升线路侧速率的主要手段包括提升线路波特率、使用高阶调制和多载波,如图3所示。
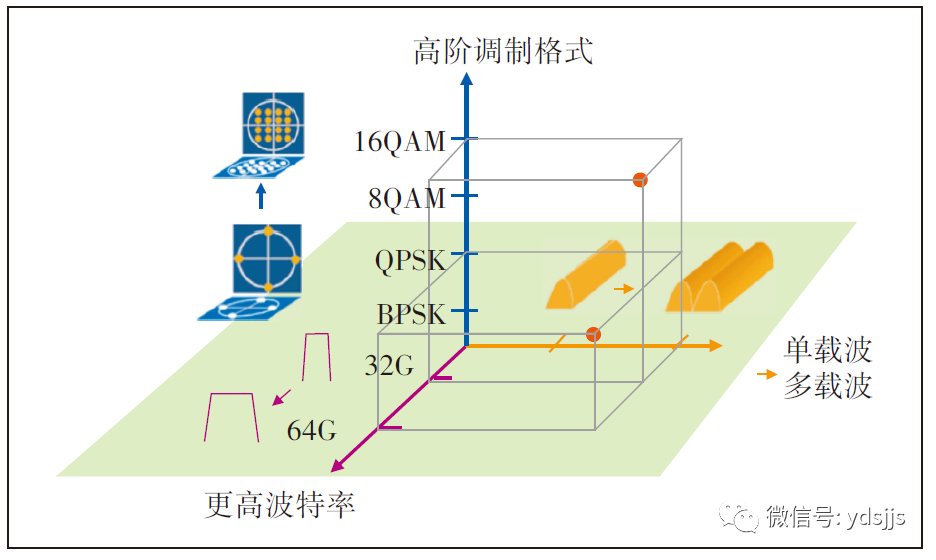
图3 提升传输线路速率的技术方向
目前200G 16QAM技术已经成熟,在50 GHz通道间隔下,相比100G能够实现容量翻倍,但是传输距离明显减小。200G QPSK可实现长距离传输,但是需要使用75 GHz通道间隔传输,与现有100G使用的50 GHz通道间隔不一致,会提升运营商系统规划和维护的复杂度。目前各主流厂家均有成熟的单波200G产品,16QAM码型频谱利用率较高,QPSK码型传输性能指标较好,可以根据不同的应用场景选择不同的调制码型。400G 16QAM在业界已有少量商用,但主要是城域点到点应用场景。800G技术仍在研发阶段,尚不具备商用条件。
3.2.2 频谱扩展技术
在现有的器件技术水平下,传输距离一定(传输性能指标一定),很难有效提升频谱利用效率,传输距离和系统容量往往不可兼得。在频谱效率无法继续提升的情况下,要获得更大的传输容量,必须扩展光纤频谱,提升光纤使用效率。在传统的C波段WDM系统中,使用的光频谱带宽一般不大于4.8 THz,最多可支持96个50 GHz间隔的波长。随着光纤拉制工艺的不断提升,现在的光纤已经可以基本消除水峰的影响,其理论上可用的传输频谱带宽范围已经可以扩展到1 260~1 675nm,涵盖O波段到L波段。扩展可用光频谱带宽,或者说扩展波段,不仅是现阶段提升单纤容量的有效手段,而且还存在着巨大的挖掘空间。G.652光纤的衰减随波长变化示意如图4所示。
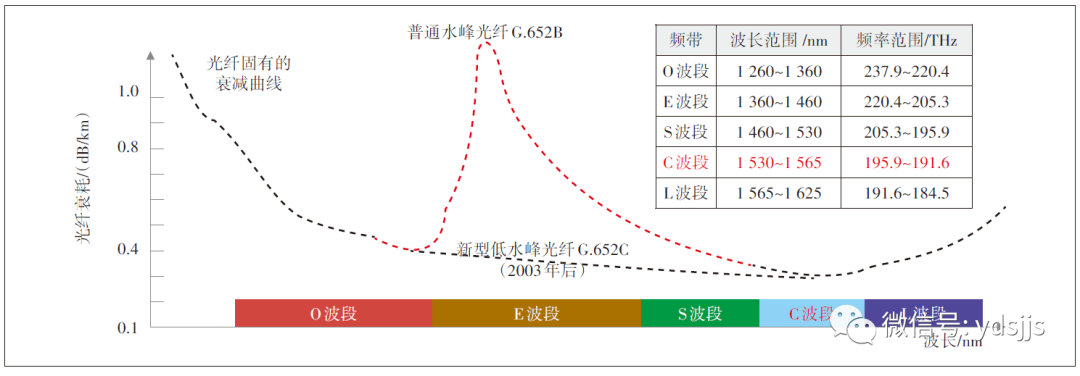
图4 G.652光纤的衰减随波长变化示意
目前业界研究的频谱扩展有2种技术路径:C++和C+L波段扩展。C++波段扩展是在C波段的基础上,向短波长和长波长频谱区域继续扩展,其目标是将50 GHz间隔的波长数量从80个扩展到120个,对应的C波段4 THz(32nm)的频谱带宽扩展到6 THz(48nm),系统的传输容量可以增加50%。不过由于频谱带宽的扩展,C++相对扩展前C波段的传输性能有所下降,需要对器件和系统进行相应的优化。
C+L波段,顾名思义,除了传统的C波段(1 530~1 565nm)之外,还将L波段(1 565~1 625nm)的频谱资源利用起来,共同作为系统的传输频谱区域,可以实现C波段和L波段各容纳96个50 GHz间隔的波长,所以C+L的波长总数可以达到192个,频谱带宽可以达到9.6 THz。相比于C波段,C+L方案的系统传输容量可以提升100%。但是,由于C/L合分波插损和更强的SRS非线性功率转移,传输带宽从C波段扩展到C+L后系统的传输性能与C波段相比会有一定劣化。DWDM系统的光频谱扩展路径示意如图5所示。
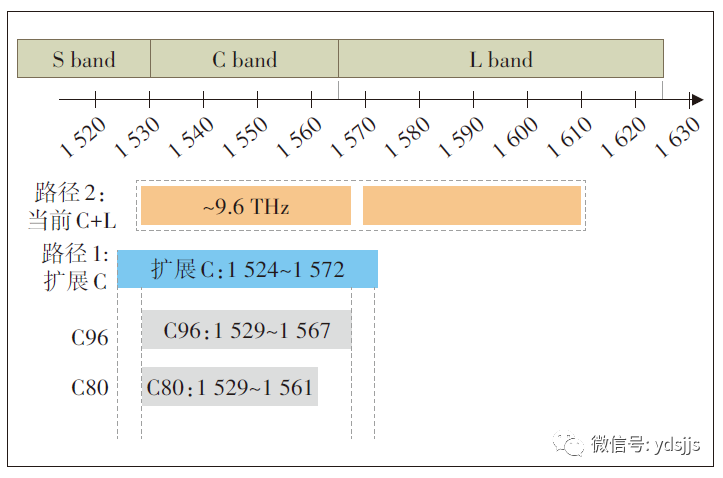
图5 DWDM系统的光频谱扩展路径示意图
对C++和C+L 2种频谱扩展技术路径,尽管C+L系统可以提供更大的可用光频谱带宽,但C++扩展系统的传输性能更好,在设备成本、性能指标、超100G承载等方面C++均优于C+L,同时C++运维相对简单。在目前的技术条件下,推荐采用C++频谱扩展方案。
3.2.3 全光交叉技术(OXC)
随着网络带宽的快速增长,在核心业务调度节点,对单节点的交叉调度容量需求越来越大,需要采用低功耗、高集成度、超大容量的全光交叉调度技术。相对于传统ROADM技术,超大容量全光交叉技术在维护性、集成度、维度、管理和应用等方面更具有优势。
3.2.3.1 可扩展性和可维护性更好
光交叉线路维度的扩展导致内部连纤数量指数级增长,人工连纤成本及错连率剧增。通过采用WSS+光背板和WSS+光纤连接盒等新型全光交叉节点结构,满足大容量调度节点的简化运维要求,可实现面向更大容量、超高速系统的平滑演进。
3.2.3.2 集成度和能耗更优
采用超大容量全光交叉技术的节点比传统ROADM节点可在空间上节省50%~75%,光纤连接数量下降>90%,功耗可下降20%~40%,单子架支线路间、线路维度间实现零手工连纤,可应对骨干机房高维度应用的挑战,且有效节省机房空间、降低机房能耗。另外,全光交叉技术在通过多种方式提供更高集成度并进一步降低功耗的同时,也使得光层组网调度像电层OTN交叉一样快捷简单,方便业务的快速开通。
3.2.3.3 交叉容量和调度维度更大
超大容量全光交叉技术的其中一种实现方式是通过采用WSS+光背板和WSS+光纤连接盒等新型节点结构,并伴随WSS器件维度的增加(20维或32维及以上),线路可调度维度和交叉容量显著增加,具有更好的维度可扩展的能力。
3.2.3.4 管理优势更明显
区别于传统ROADM,超大容量全光交叉技术由于其更优的集成度和更好的维护性,在管理方面也体现出更多优势,可以实现波长级的路径可视功能,完成光物理路径、光波长、光功率、OSNR以及其他信息的在线检测,可以用于波长信息资源的快速识别、波长路由可视和错误排查、闲置波长回收、波长全面梳理、基于波长统计的业务规划等应用场景。
3.2.3.5 支持高维端口级应用
全光交叉技术除了可应用于波长粒度的交叉调度之外,还可通过光开关矩阵实现高维度端口的交叉调度应用。全光交叉技术组网示意如图6所示。
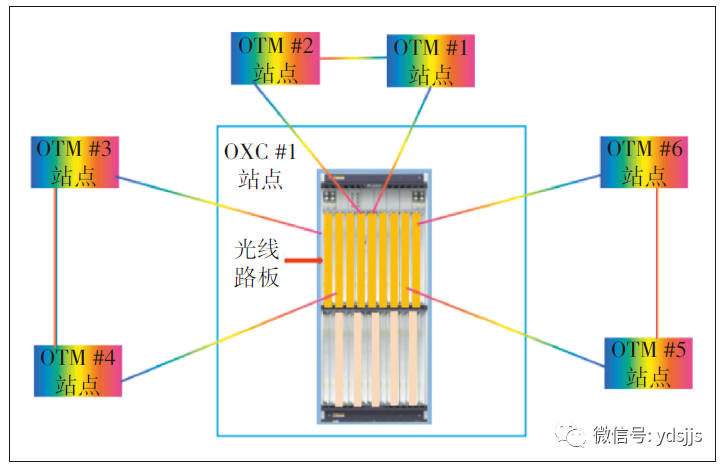
图6全光交叉技术组网示意
3.2.4 全光算力锚点+OSU灵活管道技术
全光算力锚点是光网与算力业务的衔接点。依托全光算力锚点,采用PON、G.metro、OSU、OTN、WDM等多样化接入手段,将光网络延伸至最终用户,提供无处不在的光连接服务,保障用户便捷获取和使用算力资源。
为进一步增强业务承载灵活性,面向低时延、小颗粒、多业务等差异化需求,光网络的业务属性需进一步增强。可以基于OSU技术,实现Mbit/s到Gbit/s不同速率等级算力业务的高效灵活承载,并不断增强光网络的业务感知能力,利用OSU/OTN网络提供业务灵活入云服务。
全光算力锚点如图7所示,支持多方式算力业务灵活接入,并在锚点内统一转换到ODU/OSU管道中,可提供高品质、高质量、灵活颗粒度的刚性管道,实现算力业务一跳入云,一跳入算。此外,在全光算力锚点引入基于业务流标识的静态匹配或者基于AI和算法的大数据模糊匹配识别技术,做到识别不同品质需求的业务,分流到不同的承载管道或者网络切片,提供差异化的承载服务。
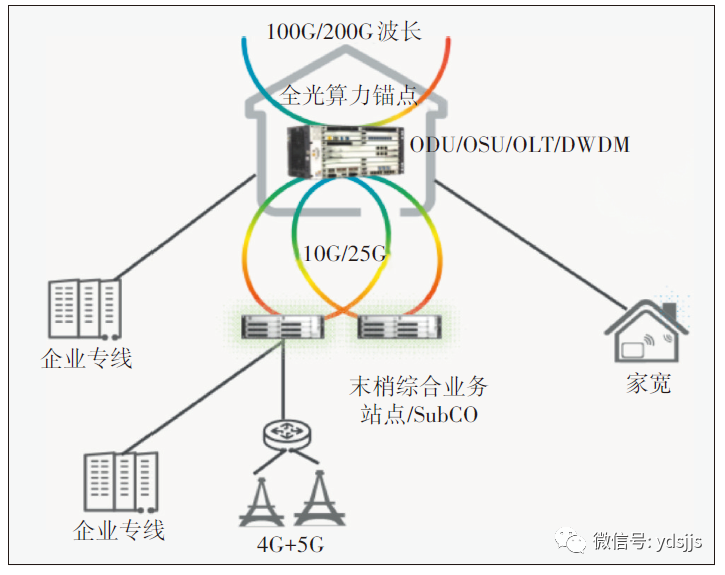
图7全光算力锚点
3.2.5 开放光网络技术
当前绝大部分的光网络都是采用传统封闭系统,即网络中所有硬件设备与控制软件都来自同一厂家,软硬件强耦合。过去几十年的通信发展历史证明这样的系统具有很好的性能保证以及很强的商业可实现性。然而随着网络业务的发展,人们逐渐发现这样的封闭系统也存在一系列的制约,难以应对当下层出不穷的各类网络应用,光网络需要从封闭走向开放。随着SDN技术规模部署,网络开放和解耦成为促进产业创新、降低建网成本的重要趋势。开放光网络将基于标准的南北向接口以及运营商统一管控系统和协同编排器,构建多供应商开放组网的全光底座,繁荣产业生态,加速业务创新,为算力网络提供高品质低成本的算力输送服务。
开放光网络总体架构包含电层设备、光层设备和管控平台3个部分(见图8)。目前面向专线接入的OTN-CPE设备、面向数据中心光互联的DCI波分、5G前传波分设备等的开放组网部署,已在多个运营商和互联网公司应用。
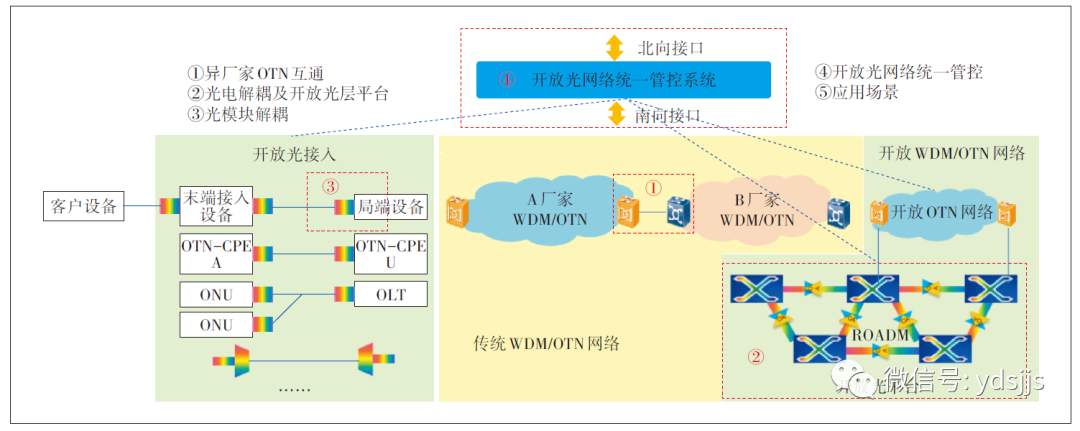
图8开放光网络总体架构
04 全光算力网络发展建设策略
全光算力网络是算力资源调度和运送的的大动脉,凭借超大容量、超长距离、灵活调度、高品质、确定性、高安全、低时延、硬隔离等优势,为算力资源提供覆盖广泛、灵活高效的超强运力保障。为了服务“东数西算”战略,筑牢面向算力的大带宽、低时延、高可靠、高安全、灵活调度的全光传送底座,实现算力业务高质量传送,应从4个维度重点推动全光算力网络的发展建设。
a) 打造低时延、高可靠、高安全的骨干光缆网。骨干光缆网作为全光算力网络的基石,需要围绕算力中心和业务流量中心,打造低时延骨干光缆网。持续优化八大核心/国家枢纽间骨干光缆,实现核心/国家枢纽节点间的高速直达双路由。同时优化区域光缆布局,打通跨省互联,加密光缆网格,实现区域内时延最优,重点聚焦京津冀、长三角、粤港澳大湾区、成渝四大城市群间光缆。此外,根据国家算力节点落地,提前规划布局,加快算力节点覆盖,保障最短光缆接入。
b) 打造大带宽、低时延、高可靠、高安全、灵活调度的骨干传输网。国家枢纽间部署应用超100G和OXC,建设高效直达超100G系统,打造超大带宽全光传送底座,具备提供400G/200G/100G超大带宽光传输通道和100G以下带宽动态可调的传输刚性管道的能力,实现业务的高质量传送。另一方面,打造“ROADM+OTN”光电双平面立体架构,增强网络健壮性及业务安全可靠性,依托低时延光缆网构建Mesh化低时延ROADM网络;围绕国家枢纽节点,打造京津冀、长三角、粤港澳大湾区、成渝等东数区域内、重点城市间低时延圈(京津冀区域重点城市间8ms/核心间2ms、长三角区域重点城市间8ms/核心间3ms、粤港澳大湾区重点城市间4ms/核心间2ms、成渝重点城市间4ms/核心间3ms),实现区域内、城市内最短时延接入。
c) 打造全光算力锚点,实现算力高速泛在接入。构建扁平化全光算力锚点架构,扩大全光算力锚点覆盖,以确定性锚点应对泛在接入。同时推动波分向城域和接入下沉来实现全光传送和接入的泛在化,提升高速泛在的光网络服务能力,实现算力业务一跳入云,一跳入算。
d) 推动光网络开放,提升自主可控和光智能调度能力。增强光网络的服务能力,实现全光业务的智能敏捷提供,推动光网络由基础网络向业务网络方向发展。进一步提升光网络的智能化与开放性,开展超长距开放光网络关键技术研究及试验、推进相关标准落地、加强光层自主可控能力,布局研究光层协同、光电一体化协同、IP+光协同多级协同调度。
05 总 结
想要让算力像水电一样一点接入、即取即用,需要构建无所不达的,联接用户、数据、算力的社会级算力网络。作为算力网络最基础的承载底座,如何持续打造更大带宽、更低时延、更高可靠、更高安全、更快调度的全光传送底座,为算力一体化调度提供高质量、差异化的联接和运送服务能力,是每个运营商都面临的问题和挑战。同时,应从国家层面加强顶层设计,统筹运营商间全光算力网络布局和协同调度,健全数字化基础设施共建共享机制,推动超高传输技术研发,加速形成社会级全光算力网络服务能力,让算力真正实现随处可连、随接随用。
作者简介
刘建新,毕业于西安电子科技大学,高级工程师,硕士,主要从事光纤通信网的咨询、规划、设计及新技术应用研究工作;
陈文雄,毕业于重庆邮电大学,高级工程师,长期从事光通信网络的规划、咨询、设计以及中国联通的技术支撑工作;
马贺荣,毕业于大连理工大学,高级工程师,长期从事码头自动化、无人机调度、远控清舱等网络智能化研究工作;
李乐坚,毕业于北京邮电大学,高级工程师,硕士,长期从事光通信网络的规划、设计和新技术应用研究工作;
赵璋卓,毕业于北京邮电大学,工程师,硕士,主要从事光纤通信网咨询、规划、设计以及技术服务工作;
黄为民,毕业于南京邮电大学,高级工程师,长期从事光纤通信网工程咨询、规划、设计、技术服务工作;
张曜晖,毕业于南京邮电大学,高级工程师,硕士,长期从事光纤通信网工程咨询、规划、设计、技术服务工作。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。