
本文分享视频编解码的意义、编码标准发展史;HEVC编码框架、块划分、帧内预测、帧间预测、变换、量化以及滤波等知识,为全面了解HEVC视频编解码打下基础。
视频编解码
视频编解码的意义
为什么要编解码?首先是视频压缩的必要性:随着高清、超高清视频的发展,视频数据量越来越大,如果不压缩,占用的带宽太大,传输的成本太高。例如一个30fps 4k视频,不压缩的情况下一秒的数据量大概是2847Mbps,这很难进行传输及下载,因此压缩是必然的。
视频数据一般由信息和冗余信息组成,去除冗余数据不影响视频的重建,这为视频压缩提供可能。而冗余一般有:空间冗余,比如下面T时刻这张图中的地面部分纹理都是重复的,这就是空间的冗余;时间冗余指的是帧之间的重复部分,比如T+1时刻,红色框内内容几乎都是重复的;还有由于HVS的特性造成的冗余,比如人眼对非ROI区域的敏感度远低于ROI区域。

编码标准发展史
由于视频压缩的必要性和可行性,出现了多种多样的编解码器,但为了解码器之间能够互相沟通,一些专业的人就组织起来拟定了一些国际标准,大家依据标准定义码流,这样对应的解码器就能认识相同标准不同实现的编码器编出来的码流。主要的标准组织有:ISO、ITU及国内的AVS及AOM。图2展示了编码标准的发展历程,在相同的画质情况下,每一代标准的码率大概减少了50%。主要是新的编码标准提出的更多更优的编码工具,使得预测、运动搜索等更加准确,但这也导致预测、搜索的耗时更高,主要体现在编码复杂度的增加。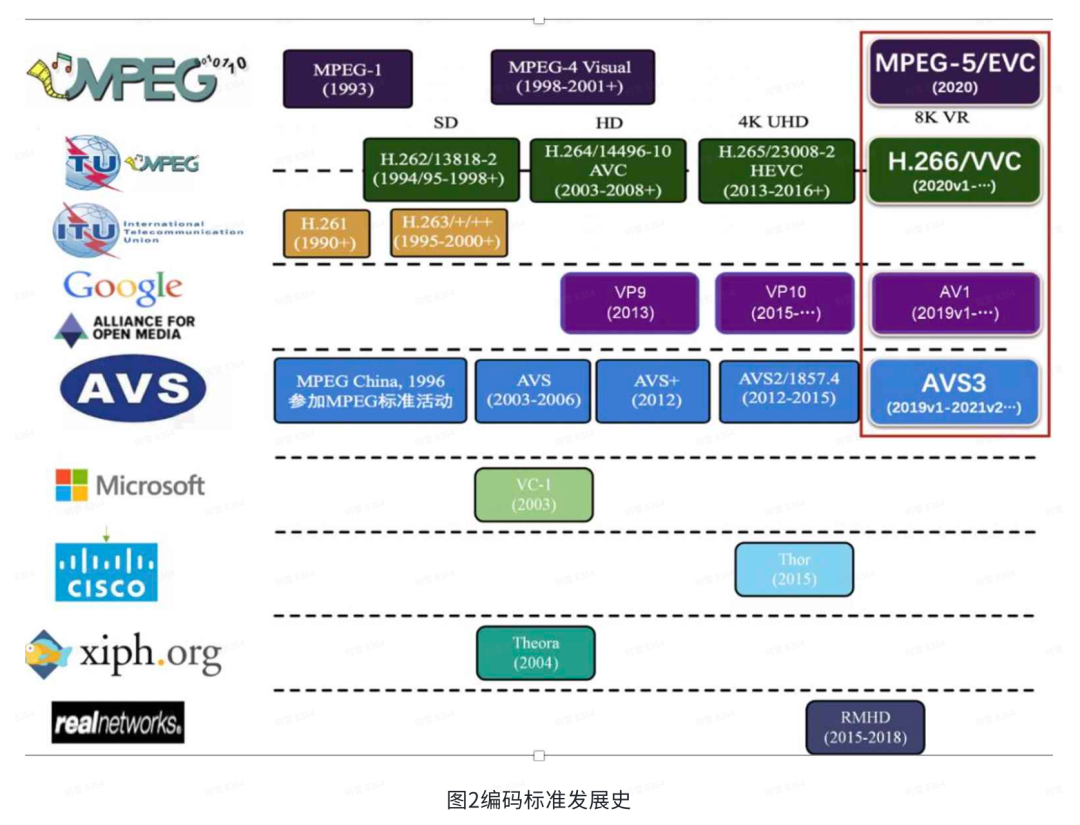
HEVC标准
HEVC编码框架
下面我们就HEVC做一个概括性介绍。下图是HEVC的编码框架,流程是从左往右的,大致是块划分、预测、变换、量化、最后熵编码,解码过程是相反的过程。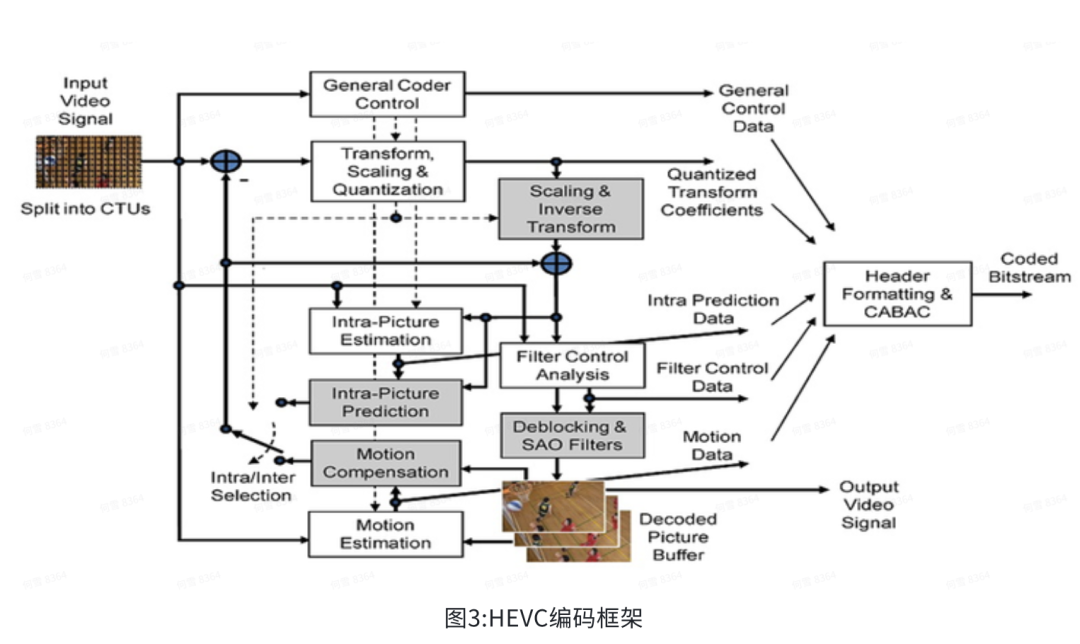
块划分
HEVC中引入了树形编码单元即CTU,一帧图像可以被划分为若干个不重叠的CTU。在高分辨率视频编码中,平坦区域(纹理变化缓慢)使用较大的CTB可以获得更好的压缩性能,小CB可以很好的处理图像局部细节,使复杂图像的预测更加准确。
举个极端的例子,假设有一个32×32块,该块是由红、黄、绿、蓝四个16×16组成,假设直接使用32×32的块进行编码,则该块对应一种预测模式,因为该块是由4种不同颜色的16×16块组成,一种模式预测,难以避免会产生误差。但如果将32×32的块首先划分为4个16×16的块,对于每个16×16的块,可以很准确的使用一种模式预测它,而且预测的误差很小;但对于图右的32×32的红色块,则不需要划分,因为它没有颜色的变化。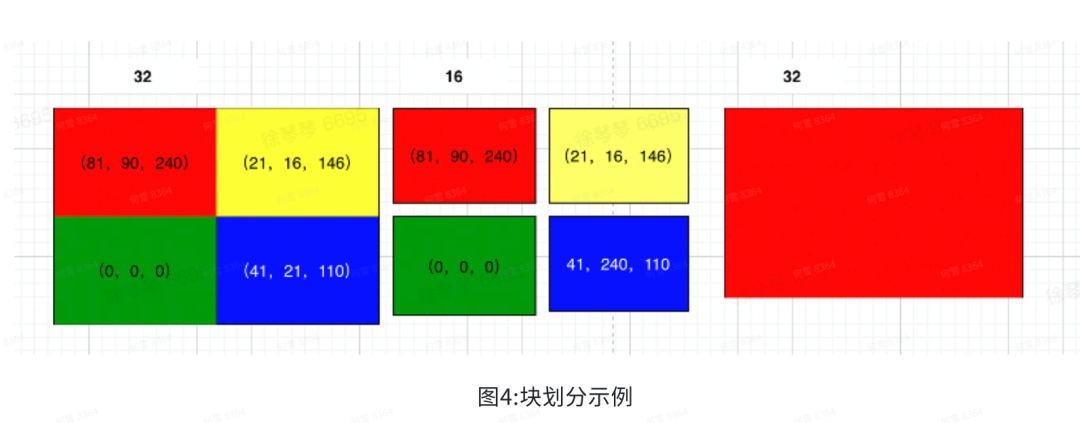
预测
预测编码视频压缩中最基本的编码工具,常见的包括帧内预测、帧间预测。预测编码的思路是指编码预测值与实际值之间的差别。
帧内预测
帧内预测简单来说就是利用当前块的相邻像素直接对每个像素做预测。HEVC提供了35种帧内预测模式。分别为DC+planar及33种方向预测。
这里举例说明为什么帧内预测可以去除空域的冗余。假设有一个4×4的像素矩阵(见图5红色矩形框内),如果不进行预测直接编码,就需要对该16个像素值为98的像素进行编码(98的二进制为1100010),则需要112 bit,假设现在对4×4的块采用DC预测,预测值为图5下所示矩阵(30的二进制为11110),对该矩阵进行编码,需要80bit,可以看到进行预测之后编码需要的bit数大大减少了。
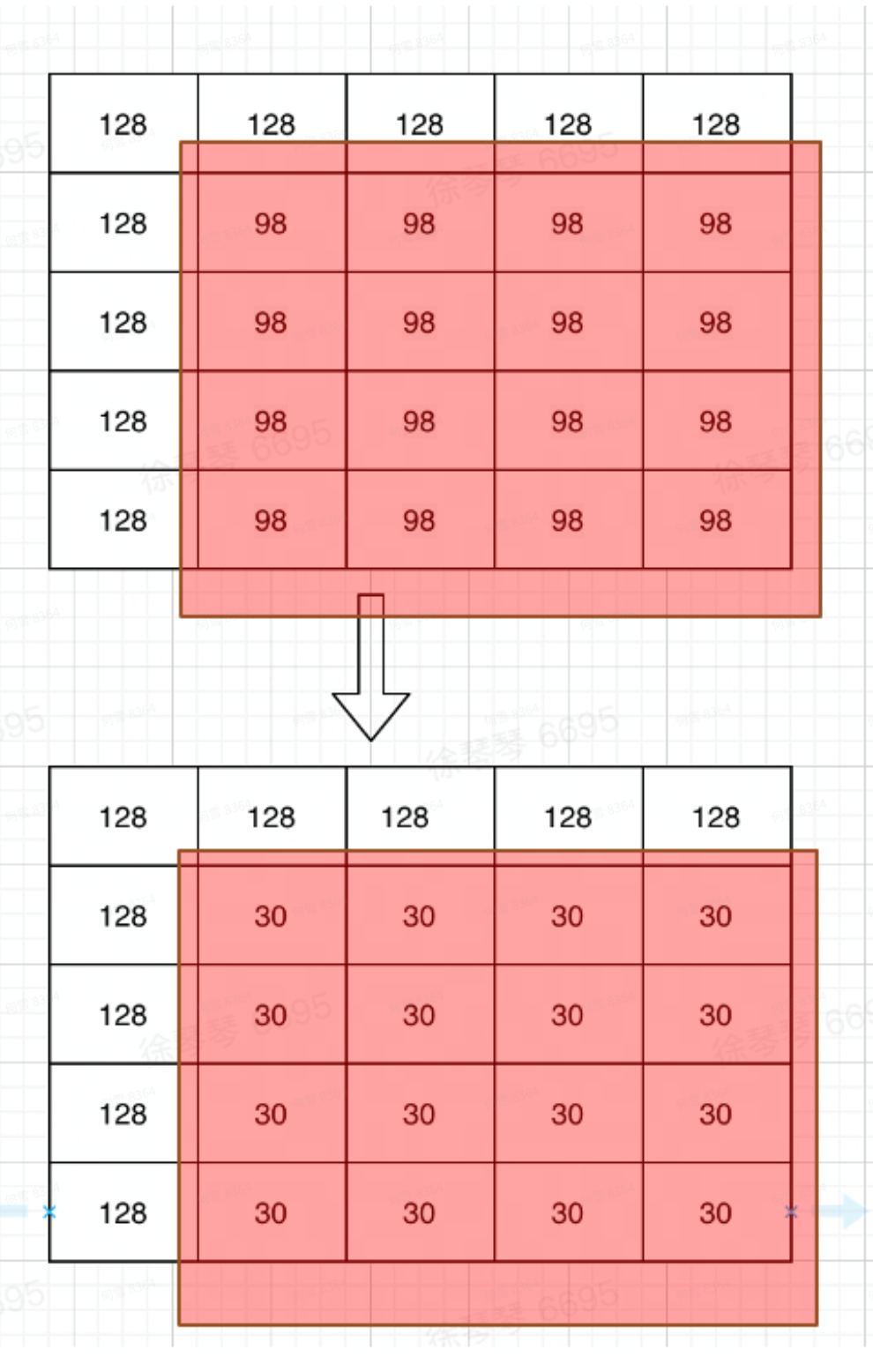
图5 预测像素矩阵
帧间预测
帧间预测就是时域预测,目的是为了消除时域冗余,简单来说就是利用之前已编码过图像来预测现在要编码的图像。HEVC提出了新的MV的预测方式:merge、AMVP。Merge通过构建空域和时域的MV候选列表,从这个列表里选取一个率失真最小的MV直接作为该块的MV,没有MVD。AMVP:高级运动向量预测,通过构建空域和时域的候选列表,从中选择最优的MV作为该块的MVP,有MVD。
帧间预测有两个重要的概念:运动估计、运动补偿。运动估计就是寻找当前编码的块在已编码的图像中的最佳对应块,并计算出对应块的偏移,即运动矢量MV。运动估计之后得到的是MV和参考索引,运动补偿信息就是通过这些信息来构造预测图像。在实际场景中,由于物体的运动的距离并不一定是像素的整数倍,因此运动估计的精度需要提升到亚像素级别,首先需要进行亚像素的差值,然后再进行搜索,搜索类似整数像素。TZsearch算法是HEVC中出现的新技术。主要步骤是:从AMVP的候选列表里选出率失真最小的作为预测MV,并用其作为搜索起始点。以步长为1开始按照棱形搜索模版,每次步长以2的整数次幂递增,选出率失真代价最小的点作为搜索结果。若该点对应起始点步长为1,在周围做两点搜索,补充周围未搜到的点;若该点的步长大于1 ,则以该点为中心,做全搜索,选择一个率失真最小的作为搜索结果。以这个搜索结果为新的起始点,重复上述步骤直至两个细化搜索的点是一致的,此时得到MV为最终的MV。
变换
预测之后是变换。变换的目的是为了消除频域的冗余。HEVC提供DCT和DST变换做时域到频域的变化。DCT变化有能量集中的特征。例如下面的例子,一个4×4的像素矩阵,经过DCT变换后,系数矩阵如右边所示,可以发现系数矩阵中,能量都集中到了DC分量,这也符合现实生活中的图像大部分的都是低频分量。根据DCT变换后的矩阵特性做不同程度的量化,更好的压缩图像。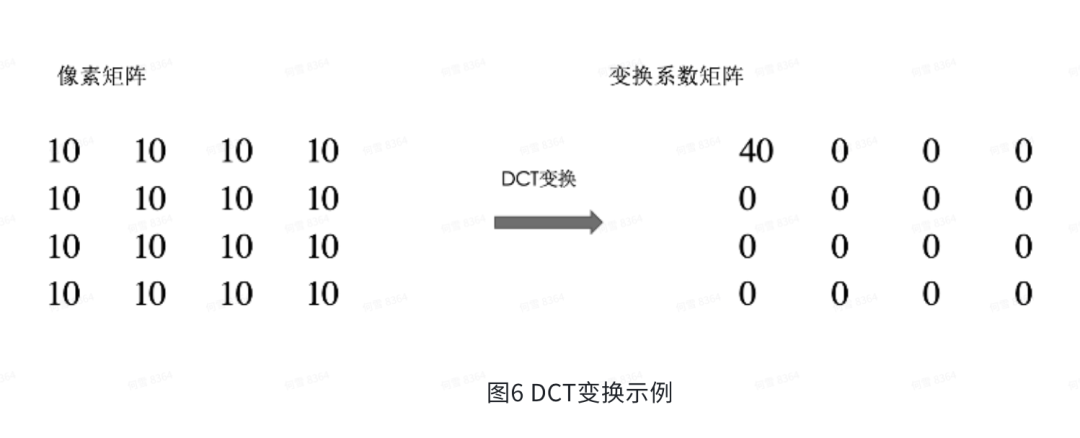
量化
量化和变换是密不可分的。变换本身不减少冗余,但是它表现出来图像的频域特征,根据这个特征进行量化,消除频域冗余。量化是编码过程中唯一产生失真的过程。具体失真的产生可以通过下面的例子来说明:
假设一整数集X= 1 2 …10..20…30…40…50…100,设量化步长Qstep=10,量化公式为:
Y=floor(X/10)
其中Y为量化后数集,floor为向下取整。则Y=0 0 0 …1 1 1 …2 2 2 …3 3 3 ……10,对Y进行反量化得到X’ = 0 0 0 …10 10 10 …20 20 20 ….30 30 30 ……100,对比X和X’,可以发现,由X’相对于X发生了信息损失,在0~9之间的值反量化回去后都为0,而10的整数倍数之间的数值也无法反量化回原来的值。
滤波
类似于以往的视频编码标准,HEVC仍采用基于块的混合编码框架。方块效应及振铃效应仍然存在(见图7a、7b)。块效应产生的原因主要是图像被划分为不同的块,不同的块的参考像素不一样、量化参数不一样,重建后会导致原本属于同一区域的块出现不连续的现象。振铃效应主要是由于对高频分量的量化,导致物体的边缘产生波纹现象。
为了降低这类失真对视频质量的影响,HEVC采用了环路滤波技术,主要包括去方块滤波(DF)和像素自适应补偿(SAO)。DF主要技术是根据块边界两边的像素对边界的像素做平滑,SAO的主要技术是从像素域上削峰填谷。有边界补偿和边带补偿两种方式,主要是对重建的CTB进行像素的补偿。
熵编码
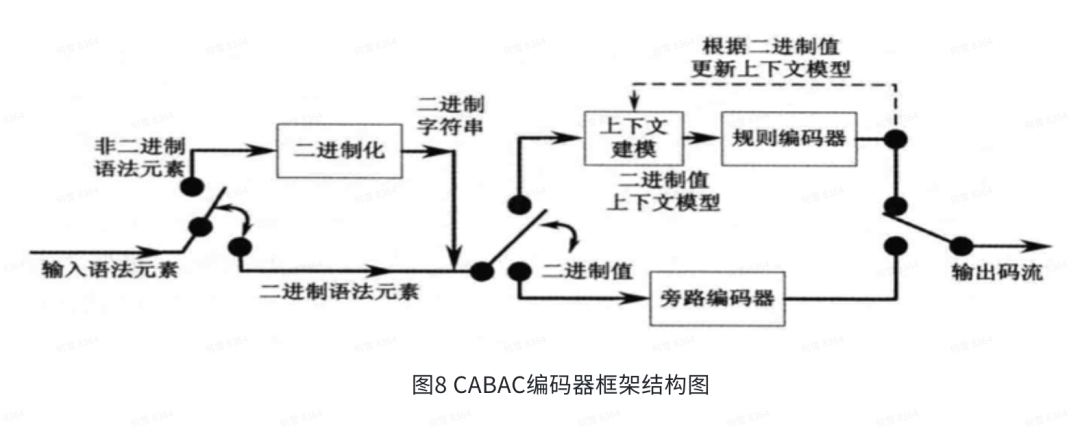
熵编码是将前面经过变换量化的语法元素编码为二进制数据。熵编码是根据熵原理进行的编码方式,就是极致压缩比。但无损是一种理想状态,一般编码的平均码字是无法达到熵值的。HEVC提供了CABAC编码方式,基于上下文主要体现在根据已编码的符号的概率更新当前元素的概率,这种编码方式的流程如图8所示。
以上部分图片来源于网络。
来源:抖音多媒体评测实验室
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。