
实验室研发的基于多帧跨通道注意力机制(MFCCA)的多说话人语音识别模型近日上线魔搭(ModelScope)社区,该模型在AliMeeting会议数据集上获得当前最优性能。欢迎大家下载。开发者可以基于此模型进一步利用ModelScope的微调和推理功能或者项目对应的Github代码仓库FunASR进一步进行模型的领域定制化。
背景介绍
多说话人语音识别(Multi-talker ASR)的目标是识别包含多个说话人的语音,希望能够正确识别极具挑战的说话人重叠(speaker overlap)语音。近年来,随着深度学习的发展,许多端到端多说话人ASR的方法出现,并在多说话人模拟数据集(如LibriCSS)上取得了良好的效果。然而,包括会议在内的真实场景中包含了更多挑战,如说话人重叠率较高的多人讨论、自由对话风格的语音、说话人数量未知、远场语音信号衰减、噪声和混响干扰等。当前,如何结合深度学习的优势,更为有效利用麦克风阵列(microphone array)拾取的多通道音频,提升多说话人语音识别性能,是当前大家关注的热点之一。


MFCCA介绍
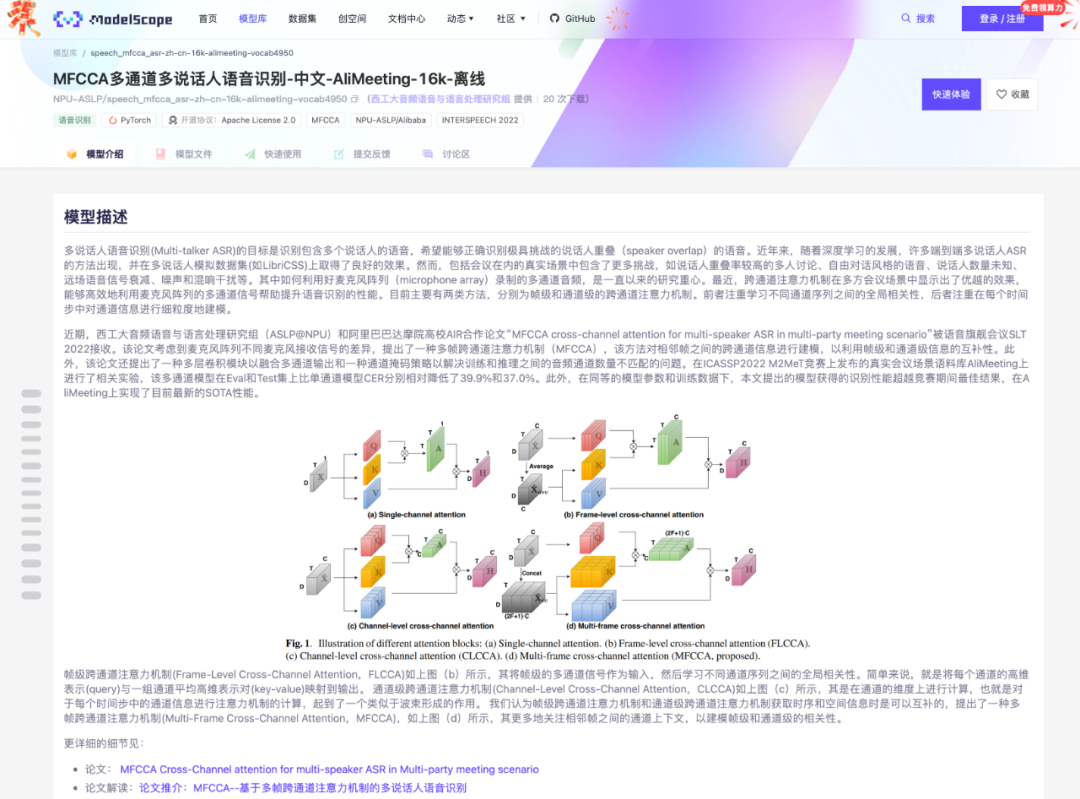
最近,跨通道注意力机制(cross-channel attention)在多方会议场景中显示出了优越的效果,能够高效地利用麦克风阵列的多通道信号帮助提升语音识别的性能。目前主要有两类方法,分别为帧级和通道级的跨通道注意力机制。前者注重学习不同通道序列之间的全局相关性,后者注重在每个时间步中对通道信息进行细粒度地建模。考虑到麦克风阵列不同麦克风接收信号的差异,实验室俞帆等同学近期提出了一种多帧跨通道注意力机制(multi-frame cross-channel attention, MFCCA),该方法对相邻帧之间的跨通道信息进行建模,以利用帧级和通道级信息的互补性。此外,该论文还提出了一种多层卷积模块以融合多通道输出和一种通道掩码策略以解决训练和推理之间的音频通道数量不匹配的问题。在ICASSP2022 M2MeT竞赛上发布的真实会议场景语料库AliMeeting上进行了相关实验,该多通道模型在Eval和Test集上比单通道模型CER分别相对降低了39.9%和37.0%。此外,在同等的模型参数量和训练数据规模下,该模型的识别性能超越竞赛期间最佳系统获得的结果,在AliMeeting上实现了目前最新的SOTA性能。
Modelscope开源
MFCCA多通道多说话人语音识别模型目前已经在魔搭(modelscope)开源社区开源。该项目提供的预训练模型正如论文所述,是基于AliMeeting、AISHELL-4和700小时模拟说话人重叠音频共计917小时数据训练而成的多通道多说话人识别模型,开发者可以基于此模型进一步利用ModelScope的微调和推理功能或者项目对应的Github代码仓库FunASR进一步进行模型的领域定制化。
开源项目网址:https://www.modelscope.cn/models/NPU-ASLP/speech_mfcca_asr-zh-cn-16k-alimeeting-vocab4950/summary
欢迎关注ASLP实验室微信公众号,获取更多语音研究相关资讯!
“打造最开放、最前沿、最落地的人工智能实验室”
作者:俞帆 音频语音与语言处理研究组
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。