
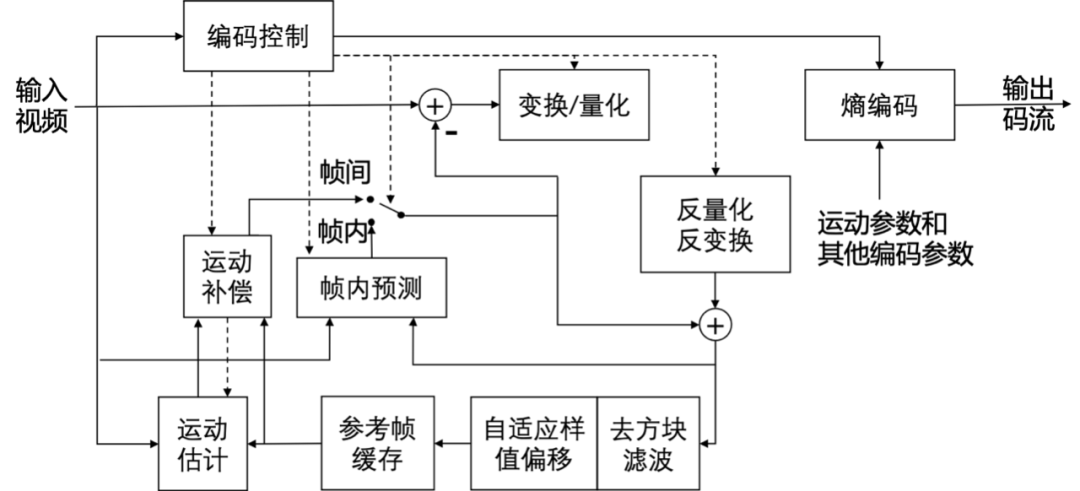
视频编码的目的是为了压缩原始视频,压缩的主要思路是从空间、时间、编码、视觉等几个主要角度去除冗余信息。由于 H.264 出色的数据压缩比率和视频质量,成为当前市场上最为流行的编解码标准。而 H.265 是在 H.264 的基础上,保证相同视频质量的同时,视频流的码率还可以减少50%。随着H.265编码格式越来越流行,本文将主要介绍 H.265 的编码原理,以下是 H.265 的编码框架流程图。

01 编码结构
H.265在编码结构上分为视频编码层(VCL)和网络提取层(NAL)。
- VCL:Video Coding Layer,主要包括视频压缩引擎和图像分块的语法定义,原始视频在 VCL 层,被编码成视频数据。简单版本的编码过程如下:
- 将每一帧的图像分块,将块信息添加到码流中;
- 对单元块进行预测编码,帧内预测生成残差,帧间预测进行运动估计和运动补偿;
- 对残差进行变换,对变换系数进行量化、扫描。
- 对量化后的变换系数、运动信息、预测信息等进行熵编码,形成压缩的视频码流输出。
- NAL:Network Abstraction Layer,主要定义数据的封装格式,把 VCL 产生的视频数据封装成一个个 NAL 单元的数据包,适配不同的网络环境并传输。
02 分块
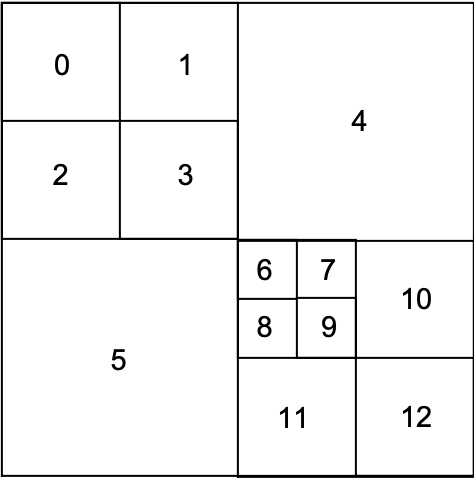
从编码顺序和结构上讲,H.265首先将一个视频划分成若干个序列,一个序列划分成若干个图像组(GOP),每一个GOP代表一组连续的视频帧。H.265 在对图像做预测编码和变换编码时,会先对图像进行划分,划分方式是四叉树。在划分四叉树时,会将整个视频帧划分成若干个正方形的编码树块(CTB),CTB 可以继续划分成编码块(CB),CB 还可以划分为预测块(PB)和变换块(TB)。因此,H.265对视频的结构划分如下图所示:
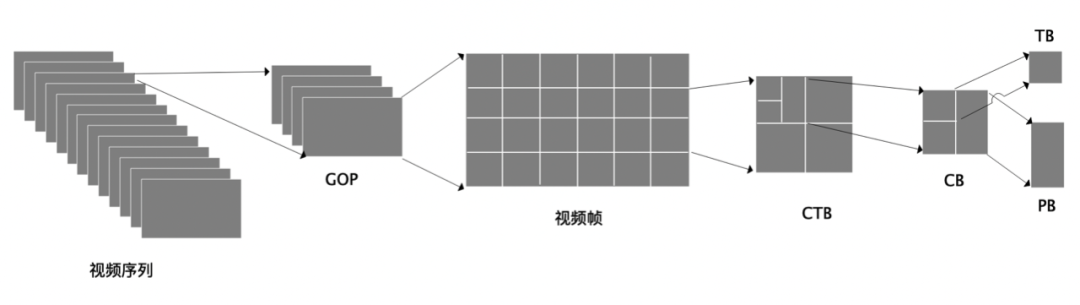
同一位置处的一个亮度 CB 和两个色度 CB ,加上一些相应的语法元素,组成一个编码单元(CU)。CU 是决定进行帧内预测、帧间预测、Skip/Merge模式的单元。
同一位置处的一个亮度 CTB 和两个色度 CTB ,加上一些相应的语法元素,和包含的 CU ,组成一个编码树单元(CTU)。CTU 相当于 H.264 中的宏块,区别是 CTU 的尺寸是由编码器制定,最大可以支持到 64×64,最小可以支持到 16×16。而宏块的大小固定为 16×16。
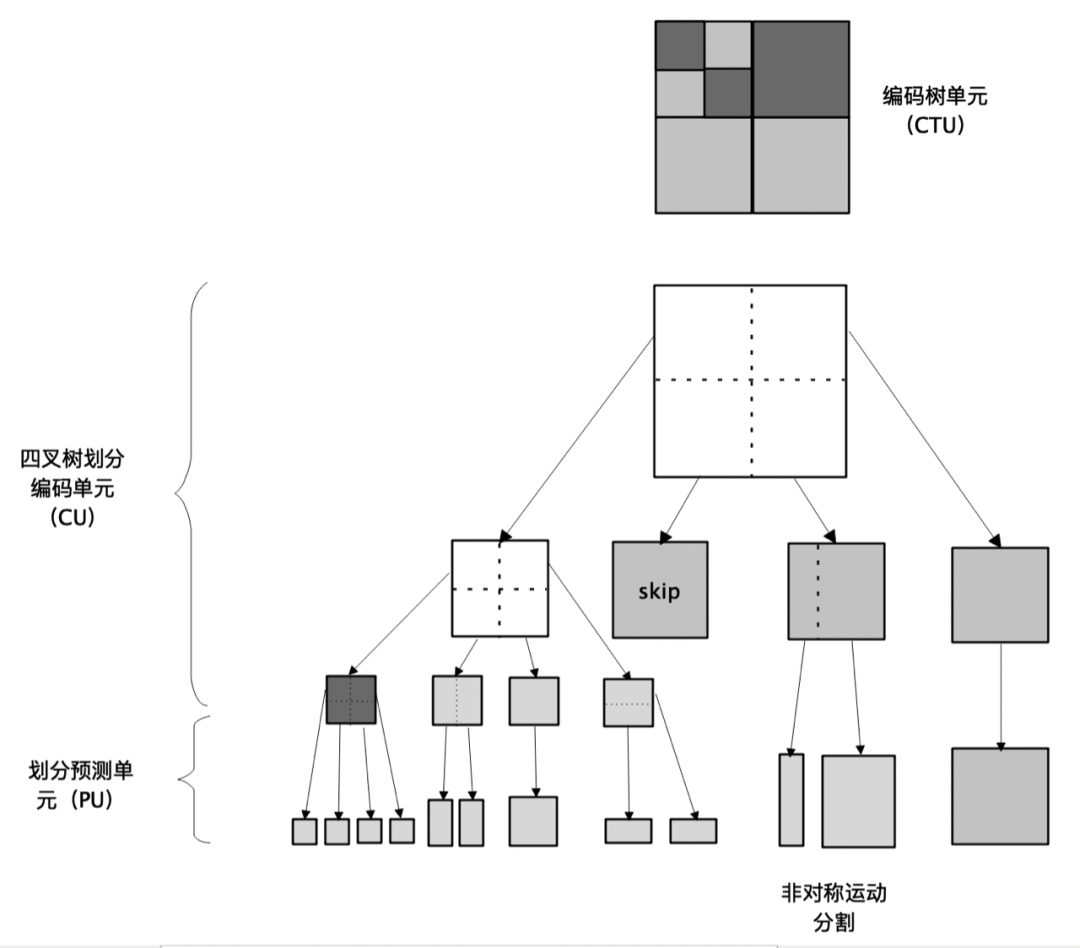
一个 CTU 在进行编码时,按照深度优先的顺序进行 CU 编码,像数据结构中的四叉树一样,一个大的方块代表父节点,里面有四个小方块分别代表四个子节点。
03 预测
视频的本质是由一系列连续的视频帧组成,在单个视频帧内部和多个视频帧之间都存在大量的冗余。从空间的角度看,单个视频帧内部的像素点之间的像素值相差很小。从时间的角度看,两个连续的视频帧之间也有很多相同的像素点。预测编码就是基于图像统计特性进行数据压缩的一种方法,利用了图像在时间和空间上的相关性,通过已经重建的像素数据预测当前正在编码的像素。
3.1 帧内预测
帧内预测是指用于预测的像素和当前正在编码的像素都在同一个视频帧内,并且一般都在邻近的区域内。由于邻近的像素之间有很强的相关性,像素值一般都非常接近,发生突变的概率非常小,差值都是0或者非常小的数。所以,帧内预测编码后传输的是预测值和真实值之间的差值,即0附近的值,叫做预测误差或残差,这样就用较少的比特传输,达到压缩的效果。
H.265帧内预测编码以块为单位,使用相邻已经重建的块的重建值对正在编码的块进行预测。预测分量分为亮度和色度两个,对应的预测块分别是亮度预测块和色度预测块。为了适应高清视频的内容特征,提高预测精度,H.265采用了更加丰富的预测块尺寸和预测模式。
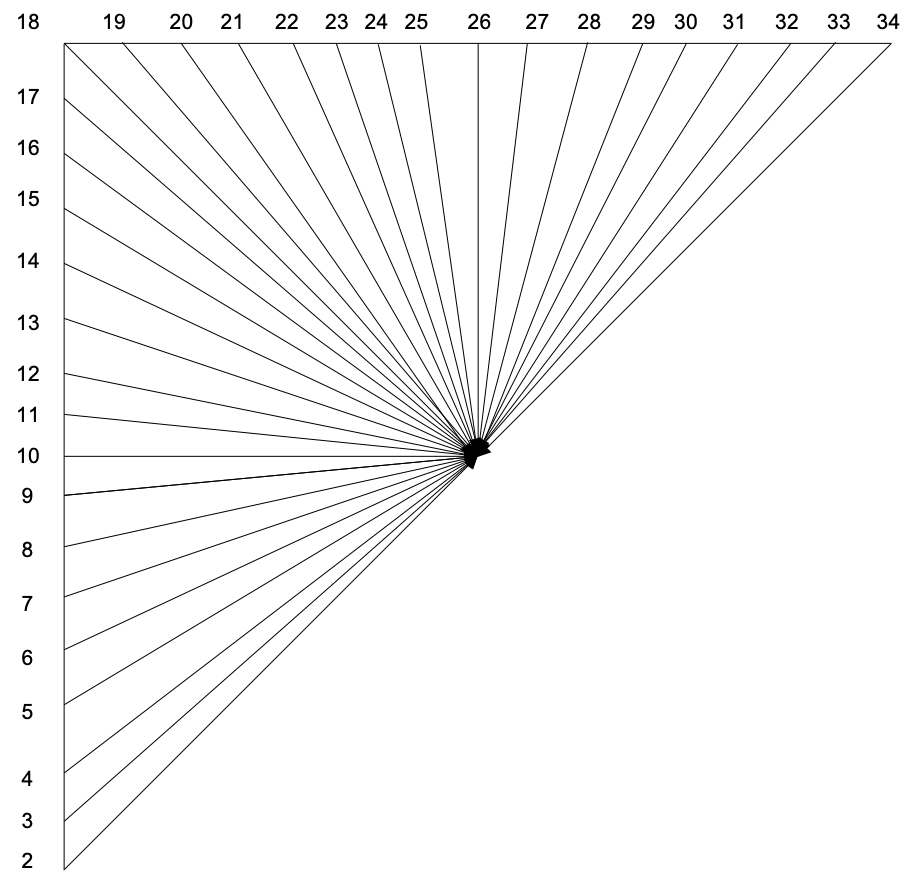
H.265亮度预测块的尺寸在4*4到32*32之间,所有尺寸的预测块都有35种预测模式,这些预测模式可以分为3类:平面(Planar)模式、直流(DC)模式和角度(Angular)模式。
- Planar模式:亮度模式0,适用于像素值变换缓慢的区域,例如像素渐变的场景。对预测块中的每个像素都使用不同的预测值。预测值等于:该像素在水平和垂直两个方向线性插值的平均值。
- DC模式:亮度模式1,适用于图像的大面积平坦区域,该模式对预测块中的所有像素都使用相同的预测值。
- 如果预测块是正方形,预测值等于左边和上边的参考像素的平均值;
- 如果预测块是长方形,预测值等于长的那一边的平均值;
- 角度模式:亮度模式2~34,总共33个预测方向,其中模式10是水平方向,模式26是垂直方向。角度模式每个像素的预测值都是从对应预测方向前已经重建的像素集的样值进行水平或垂直方向偏移角度预测。
由于彩色视频中,相同位置的色度信号和亮度信号的特征类似,因此色度预测块和亮度预测块的预测模式也类似。H.265中色度预测块的预测模式有Planar模式、垂直模式、水平模式、DC模式和导出模式5种:
- Planar模式:色度模式0,和亮度模式0一样。
- 垂直模式:色度模式1,和亮度模式26一样。
- 水平模式:色度模式2,和亮度模式10一样。
- DC模式:色度模式3,和亮度模式1一样。
- 导出模式:色度模式4,采用和对应亮度预测块相同的预测模式。如果对应的亮度预测块模式是0、1、10、26中的一种,则替换为模式34。
3.2 帧间预测
帧间预测是指用于预测的像素和当前正在编码的像素不在同一个视频帧内,但是一般在相邻或附近的位置。一般情况下,帧间预测编码的压缩效果要比帧内预测好,主要原因是视频帧之间的相关性非常强。如果视频帧中的运动物体变化速度很慢,那么视频帧之间的像素差值也就很小,时间冗余度就非常大。
帧间预测评估运动物体运动状况的方法是运动估计,它的主要思想就是对预测块从参考帧的给定范围中搜索匹配块,计算匹配块和预测块之间的相对位移,该相对位移就是运动矢量。得到运动矢量后,需要对预测修正,也就是运动补偿。将运动矢量输入到运动补偿模块,”补偿”参考帧,即可得到当前编码帧的预测帧。预测帧和当前帧的差,就是帧间预测误差。
如果帧间预测只用到了前一帧图像,就称为前向帧间预测或单向预测。该预测帧也就是P帧,P帧可以参考前面的I帧或者P帧。
如果帧间预测不仅用到了前一帧图像预测当前块,还用到了后一帧图像,那么就是双向预测。该预测帧也就是B帧,B帧可以参考前面的I帧或P帧和后面的P帧。
由于P帧需要参考前面的I帧或P帧,而B帧需要参考前面I帧或P帧和后面的P帧,如果在一个视频流中,先到了B帧,而依赖的I帧、P帧还没有到,那么该B帧还不能立即解码,那么应该怎么保证播放顺序呢?其实,在视频编码时,会生成PTS和DTS。通常情况下,编码器在生成一个I帧后,会向后跳过几个帧,用前面的I帧作为参考帧对P帧编码,I帧和P帧之间的帧被编码为B帧。推流的视频帧顺序在编码的时候就已经按照I帧、P帧、B帧的依赖顺序编好了,收到数据后直接解码即可。所以,不可能先收到B帧,再收到依赖的I帧和P帧。
- PTS:Presentation Time Stamp,显示时间戳,告诉播放器在什么时间显示这一帧。
- DTS:Decoding Time Stamp,解码时间戳,告诉播放器在什么时间解码这一帧。
04 变换
变换编码是指将图像中的空间域信号映射变换到频域(频率域),然后对生成的变换系数编码。由于在空间域中,数据之间的相关性比较大,经过预测编码后的残差变化较小,存在大量的数据冗余,在图像中亮度值变化缓慢的平坦区域特别明显。而变换为频域后,会将空间域分散分布的残差数据转换成集中分布,可以降低相关性,减少数据冗余,从而达到去除空间冗余的目的。
在H.265中,一个编码块(CB)可以通过四叉树划分成若干个预测块(PB)和变换块(TB)。由于从 CB 到 TB 之间的四叉树划分主要是为了残差的变换运算,因此这种四叉树又称为残差四叉树(RQT)。如下图所示,就是一个 RQT 划分实例,将一个 32*32 的残差 CB 划分成13个不同大小的 TB 。
每个 TB 的大小有四种,分别是从 4*4、8*8、16*16、32*32,每个 TB 都对应一个整数变换系数矩阵。大尺寸的 TB 适用于图像亮度值变化缓慢的平坦区域,小尺寸的 TB 适用于图像亮度值变化剧烈的复杂区域。所有尺寸都可以使用离散余弦变换(DCT)变换。另外,对于 4*4 的帧内预测亮度残差块,还可以使用离散正弦变换(DST)。
由于帧内预测编码是基于左边和上边已经编码块的数据,因此预测块距离已编码块越近,相关性越强,预测误差越小;距离已编码块越远,相关性越小,预测误差越大。预测误差的这种数据分布特征和 DST 的正弦基函数 sin 非常相似,起始点最小,然后逐渐变大。但是因为 DST 计算量比 DCT 大,需要增加更多的变换类型标识,因此 DST 仅用于 4*4的帧内预测亮度残差块。
05 量化
由于变换编码只是将图像数据从空间域矩阵转换为频域的变换系数矩阵,矩阵的系数个数和数据量都没有减少。要想压缩数据,还需要对频域中的统计特征进行量化和熵编码。
常见的量化方法可以分为**标量量化(SQ)和矢量量化(VQ)**两类:
- 标量量化:将图像中的数据划分成若干个区间,然后在每个区间用一个值代表这个区间内所有样点的取值。
- 矢量量化:将图像中的数据划分成若干个区间,然后在每个区间用一个代表矢量代表这个区间的所有矢量取值。
由于矢量量化引入了多个像素之间的关联,并且使用了概率的方法,一般压缩率比标量量化高。但是由于其计算复杂度高,所以目前广泛使用的量化方法是标量量化。
量化的压缩率取决于划分的区间大小,即量化步长。量化步长越大,表示量化越粗,对应的视频码率越低,失真越大;量化步长越小,表示量化越细,对应的视频码率越高,失真越小。
H.265量化时是以**变换单元(TU)为基本单位,处理对象包括 TU 中的亮度分量和色度分量。H.265采用了非线性标量量化,通过量化参数(QP)**控制每个编码块的量化步长,QP 和量化步长的关系近似呈指数关系。QP 是个整数,亮度分量的 QP 值范围是 0~51,色度分量的亮度 QP 值范围是0~45。QP 值在0~29范围时,亮度分量和色度分量的量化步长相等,从QP=30开始,两者开始产生差异。QP 和量化步长的关系如下图所示:
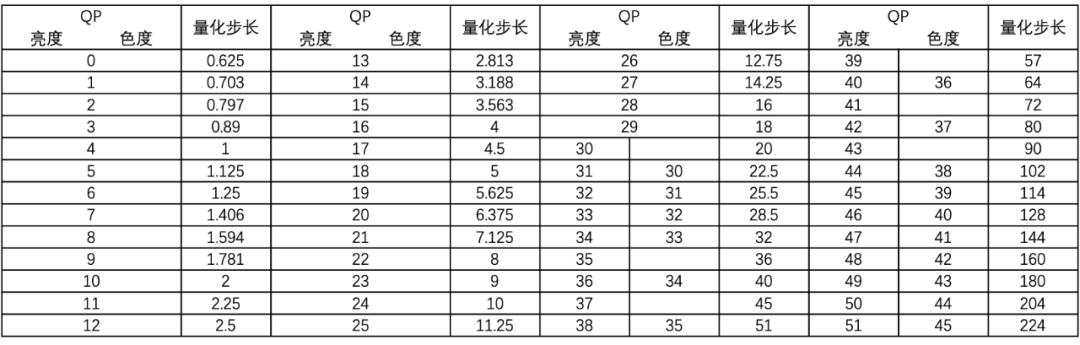
编码端的量化过程可以简单理解为是每个 DCT 变换系数除以量化步长得到量化值。在解码端对应的反量化过程就是量化值乘以量化步长得到 DCT 变化系数值。
06 熵编码
熵编码是指在编码过程中按熵原理不丢失任何信息的编码。量化是一种有损的压缩方式,而熵编码是用更紧凑的方式标记和原数据之间的映射关系,属于无损压缩。常见的熵编码有香农(Shannon)编码、哈夫曼(Huffman)编码、算术(Arithmetic)编码、游程编码等。
6.1 哈夫曼编码
哈夫曼编码是一种变长编码,即不同字符的编码长度是变化的。该编码利用字符出现的概率构造哈夫曼二叉树,目标是让出现概率大的字符编码时用短码(距离根节点近),概率小的字符编码时用长码(距离根节点远),从而让平均码字长度最短。
码字:字符经过哈夫曼编码后得到的编码。
例:字符A、B、C、D、E、F对应的出现的概率分别是0.32、0.22、0.18、0.16、0.08、0.04。哈夫曼树的构造过程如下:
- 选择概率最小的 E、F 作为叶子节点,计算 E、F 的概率和作为它们父节点;
- 将父节点的值与剩下的 A、B、C、D 概率值排序,再选择最小的两个树求和;
- 重复以上过程;
最终构造出来的哈夫曼二叉树如下图所示:
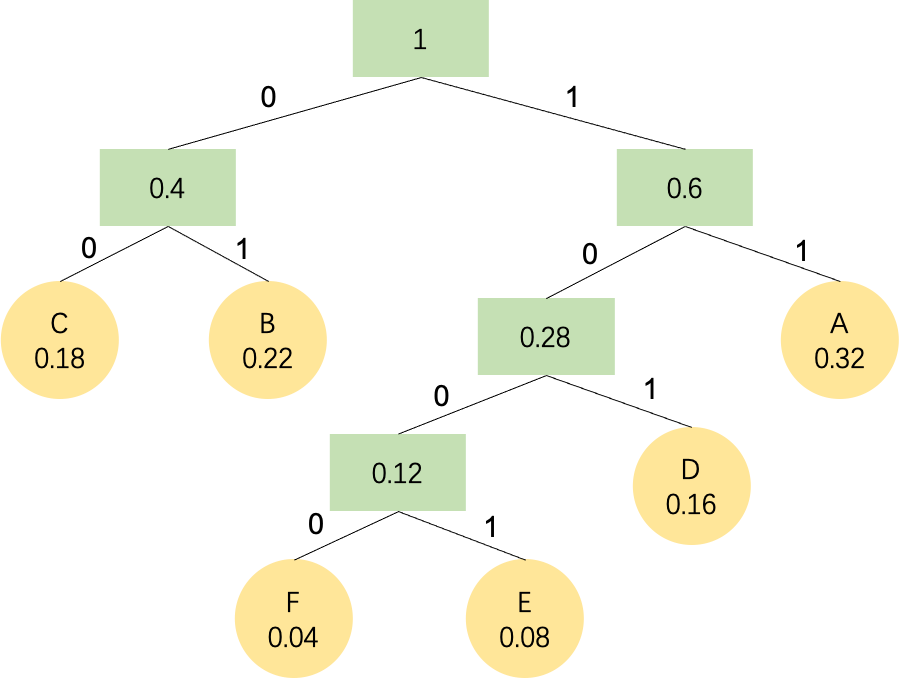
左节点的路径为0,右节点的路径为1,求得A、B、C、D、E、F的编码结果:
| 字符 | A | B | C | D | E | F |
| 概率 | 0.32 | 0.22 | 0.18 | 0.16 | 0.08 | 0.04 |
| 码字 | 11 | 01 | 00 | 101 | 1001 | 1000 |
| 码字长度 | 2 | 2 | 2 | 3 | 4 | 4 |
平均码字长度 = 0.32*2 + 0.22*2 + 0.18*2 + 0.16*3 + 0.08*4 + 0.04*4 = 2.4bit
6.2 算术编码
虽然哈夫曼编码在理论上可以获得最佳编码结果,但是在实际编码中,由于计算机处理的最小数据单位是1bit,对于包含小数点的码字长度只能按照整数处理,所以实际编码效果往往略逊于理论编码效果。在图像压缩领域,通常使用算术编码代替哈夫曼编码。不过,算术编码的理论基础和哈夫曼编码是一致的,都是概率大的字符用短码,概率小的字符用长码。
算术编码分为固定模式算术编码、自适应算术编码(AAC)、二进制算术编码、自适应二进制算术编码(CABAC)等,H.265 中使用了 CABAC 。此处将只介绍固定模式算术编码流程:
- 统计输入的符号序列中各个字符和出现的概率;
- 按照概率分布,将[0, 1)区间划分成多个子区间,每个子区间代表一个字符,子区间的大小代表字符出现的概率;所有子区间大小的和等于1;假设该字符的区间范围为 [L, H);
- 设置初始变量low=0, high=1,不断读取符号序列中的每个字符,找到该字符对应的区间范围 [L, H),更新low和high的值:
- low = low + (high – low) * L
- high = low + (high – low) * H
- 遍历完符号序列后,得到最终的low和high,转换二进制形式输出得到编码数据;
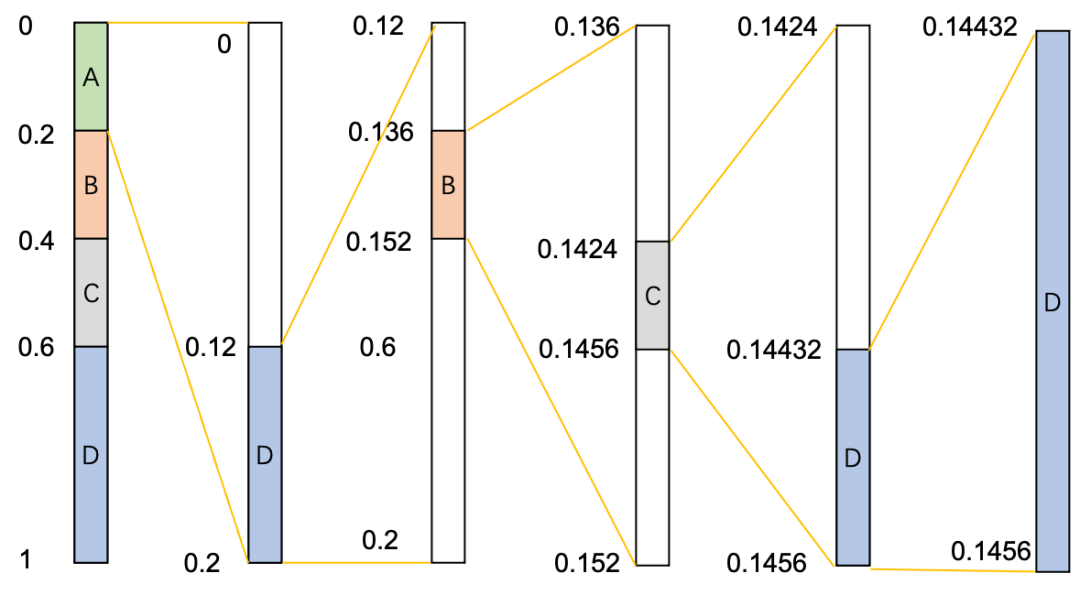
例:输入符号序列是 ADBCD,统计各个字符出现的概率:
| 字符 | 出现次数 | 出现概率 | 概率区间 |
| A | 1 | 0.2 | [0, 0.2) |
| B | 1 | 0.2 | [0.2, 0.4) |
| C | 1 | 0.2 | [0.4, 0.6) |
| D | 2 | 0.4 | [0.6, 1) |
- 遍历第一个字符 A 时,low = 0, high = 1, L = 0, H = 0.2
- low = low + (high – low) * L = 0
- high = low + (high – low) * H = 0.2
- 遍历第二个字符 D 时,low = 0, high = 0.2, L = 0.6, H = 1
- low = low + (high – low) * L = 0.12(注:此处计算的low不代入下面计算high值的公式中)
- high = low + (high – low) * H = 0.2
- 遍历第三个字符 B 时,low = 0.12,high = 0.2,L = 0.2,H = 0.4
- low = low + (high – low) * L = 0.136
- high = low + (high – low) * H = 0.152
- 遍历第四个字符 C 时,low = 0.136,high = 0.152,L = 0.4,H = 0.6
- low = low + (high – low) * L = 0.1424
- high = low + (high – low) * H = 0.1456
- 遍历第五个字符D时,low = 0.1424,high = 0.1456,L = 0.6,H = 1
- low = low + (high – low) * L = 0.14432
- high = low + (high – low) * H = 0.1456
得到最后的[low, high)区间是[0.14432, 0.1456),在这个区间内取任意值转二进制后都是对 “ADBCD”的算术编码。对应的编码流程可以简化到下面这张图中:
07 环路滤波
由于 H.265 采用分块编码,在图像反量化、反变换重建的时候,会存在一些失真效应,例如块效应、振铃效应。为了解决这些问题,H.265 采用了环路滤波技术,其中包括去方块滤波(DBF)和样点自适应补偿(SAO)。
DBF 作用于边界像素,用于解决块效应。块效应是指一些相邻编码块边界处的灰度值存在明显的不连续性,产生块效应主要有两个原因:
- 编码器对残差的DCT变换和量化是基于块的,忽略了块与块之间的相关性,导致块之间的处理不一致;
- 帧间预测运动补偿块的不完全匹配,存在误差;而编码时的预测参考帧通常来自这些重建图像,导致待预测图像失真;
DBF 针对边界类型采用强滤波、弱滤波或者不处理,边界类型的判定是由边界像素梯度阈值和边界块的量化参数决定的。DBF 处理时,先对整个图像的垂直边缘进行水平滤波,然后对水平边缘进行垂直滤波。滤波过程实际上就是对像素值进行修正的过程,让方块看起来不那么明显。H.264 中也存在 DBF 技术,但是应用于 4*4 大小的处理块,而 H.265 中应用于 8*8 大小的处理块。
SAO 是 H.265 新引入的对重建图像的误差补偿机制,用于改善振铃效应。振铃效应是指图像的灰度值剧烈变化产生的震荡,产生振铃效应主要原因是DCT变换后高频信息丢失。SAO 的原理就是通过对重构曲线的波峰像素添加负值补偿,波谷添加正值补偿,从而减小高频信息的失真。和 DBF 只作用于边界像素不同,SAO 作用于块中所有的像素。
08 小结
本文从 H.265 整体编码流程的角度,介绍了 H.265 编码涉及到的分块、预测、变换、量化、编码、环路滤波等技术点。通过了解这些编码原理,为我们后续进一步学习音视频开发技术奠定扎实的基础。
文章来源于百度Geek说 ,作者天蓝
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。