
随着虚拟开播在B站等平台的火爆,越来越多的用户和主播对虚拟直播产生了浓厚的兴趣。3D写实风格的虚拟人不仅视觉效果出众,还能提供沉浸式的直播体验,为用户带来全新的观看感受。如抖音推出的3D超写实虚拟主播令颜欢,出道一周粉丝就突破了60万,全网视频播放量破亿,直播间更是突破了百万人次的场观水平。3D写实风格的虚拟人有望成为未来虚拟直播领域的市场趋势。


然而,在3D虚拟人领域高昂的制作成本(几十万~几百万)和漫长的制作周期成为了规模化和商业化的阻碍,复杂的流程也令普通内容创作者望而却步。虚拟人的制做流程主要分为:建模、绑定、驱动、渲染。通过建模获得虚拟人漂亮的外表,然后给3D模型绑定骨骼让他能够像人一样动起来。按不同的精度要求,制作周期通常需要3-6个月以上的时间,价格从几万到百万的级别。传统上完成一场3D虚拟开播,还需要实时高精度动捕,业界通常采用光学设备来完成,单场的开播成本需要几万元。捕捉到的数据还需要经过引擎的驱动、重定向,准确的完成目标人物的动作还原,最终采用CG实时渲染技术,完成整个场景、人物、服饰、头发等细节的渲染效果。
为了降低3D虚拟数字人的制作成本,B站人工智能平台和天工工作室共同打造了一套给普通用户的3D写实风幻星数字人技术解决方案,让每个普通人都可以实现自己的虚拟偶像梦!欢迎关注技术落地案例(https://space.bilibili.com/3494365152414319),梨雅Lya在直播间等你哦~

用户可以通过幻星数字人技术解决方案提供的捏脸、塑体和换装能力,花几分钟到十几分钟的时间获取到符合个性化需求的3D虚拟人形象。使用普通的单目摄像头实现对创作者面部、身体以及手势动作的捕捉,并且实时的渲染到虚拟的场景中,即使在家里也能完成一场内容精彩的虚拟直播。
背景和概述
随着VR/AR等技术和应用的兴起,对于动作捕捉到需求越来越多。通过3D动捕捉技术,可以极大提升效率,提高用户的沉浸感,增加现实世界和虚拟世界的流畅结合。当前,不同的虚拟直播公司和项目使用的动捕技术可能会有所不同,主流动捕技术分为三类:
- 光学动捕技术(Optical Motion Capture):该技术使用多个摄像头捕捉演员身上的特定标记,然后计算出角色的运动轨迹。这种技术通常需要在特定的拍摄场地中进行,而且需要使用专业的摄像机和跟踪软件。
- 惯性动捕技术(Inertial Motion Capture):这种技术使用传感器和陀螺仪来捕捉演员的运动,然后将数据传输到计算机中进行处理。相比光学动捕技术,惯性动捕技术不需要特定的拍摄场地,并且可以在室内和室外使用。
- 混合动捕技术(Hybrid Motion Capture):该技术是光学动捕技术和惯性动捕技术的结合。在混合动捕技术中,演员身上同时搭载有传感器和特定标记,通过多个摄像头和传感器捕捉演员的运动,进而生成虚拟角色的动画。
上述动捕方案都需要额外的硬件支持,对于普通用户来说成本过高,并且使用环境也比较受限。如果能有一款基于普通摄像头的动捕方案,可以极大的降低用户使用门槛,减少用户投入成本。基于此目的,我们开发了这套纯视觉的动捕方案,只需要一个摄像头即可实现全套动捕,包括面部表情捕捉,身体动作捕捉以及手部动作捕捉。
详细技术特点
视觉动捕的核心是计算机视觉领域的3D重建技术:使用二维图像作为输入,算法恢复出二维目标的三维模型。我们系统的总体技术框架如下:输入视频流,分别进行人脸表情估计、人体3D重建以及手势3D姿态预测,之后根据置信度等信息,对于人体和手势点位进行后处理,然后传给IK,得到每个关节旋转四元数,最终传给渲染引擎进行Avatar的驱动。
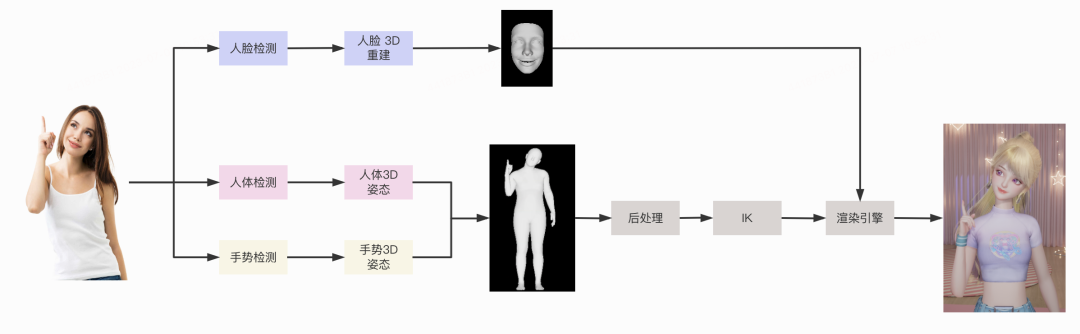
通过对不同技术模块的深入调优以及对不同模块整体配合效果的持续优化,我们的半身动捕技术能够在普通的PC电脑上实现实时动作捕捉,并且保证较好的动作还原度。
同时为了保持长时间开播的效果稳定性,我们重点对视觉动捕中比较难的遮挡、出镜、运动模糊、边界状态等问题进行了优化,确保在正常开播的场景中,不会发生驱动效果异常问题。
分模块介绍
面部表情捕捉与3D人脸重建
由于人脸的细节丰富性,获取高质量3D实时数据通常昂贵且复杂,而且大多数数据采集都在实验室环境中进行,这导致训练出的模型在实际应用场景中存在领域间差距(Domain Gap)。为了解决这一难题,学术界通常采用基于可微渲染技术的自监督训练,这种方法在很大程度上缓解了这一问题。我们为了进一步提升捕捉精度并保持模型的泛化能力,首先利用iPhone深度摄像头以低成本获取人脸3D点云数据和RGB图像对,通过点云处理/拓扑对齐/注册,构建了包含十万级别3D标签的自然场景图像数据,同时构建了百万级别的视频数据集用于提升模型的泛化性能。
关键方法:基于可微渲染技术弱监督训练及其优化
我们以基于可微渲染的半监督3D人脸重建模型为基础,并提出了如下改进点:
- 使用带有3D监督的自然场景数据进行预训练,并在模型全量数据训练中进行对抗性训练,引导模型学习人脸的先验信息。
- 基于人工标注的2D标记来提升表情细节表现和泛化能力。为此,我们对人脸五官设计了更为稠密的标注规则,从而获取表情细节上更好的监督。
- 使用同一个人的视频片段数据来提升模型对形状、姿势和表情的解构能力,同时进一步拓展模型的泛化性能。
通过这些关键方法的应用和优化,我们可以在面部表情捕捉和3D人脸重建领域实现显著的改进,相比于iphone拓展了更多的光照、姿态、距离的应用场景,为实际应用提供更精确和逼真的虚拟人物表情。
3D人体重建
基于单目相机感知人体3D动作本身就是一个存在巨大挑战的问题。此外,直播半身场景下,用户四肢频繁进出画面、肢体遮挡、运动模糊和背景复杂多样等问题,进一步提高了对人体半身动捕稳定性的要求,为了解决这些难点并为用户提供更好的直播体验,我们从数据、模型和自适应后处理等多个角度进行了深度优化。
3D人体核心数据集构建
从单目相机估计人物身体的3D姿态,本质上是一个ill-posed问题。为了让模型能够充分学习到直播场景下用户动作的泛化信息,我们需要大量的目标场景训练数据。然而,大量标注人物3D姿态数据所需的时间成本、金钱成本以及标注难度都很高。因此,我们构建了一套半自动数据收集系统,如下图所示。利用该系统,我们已经储备了千万级别的直播目标场景数据,从而能够提供稳定可靠的动捕效果。
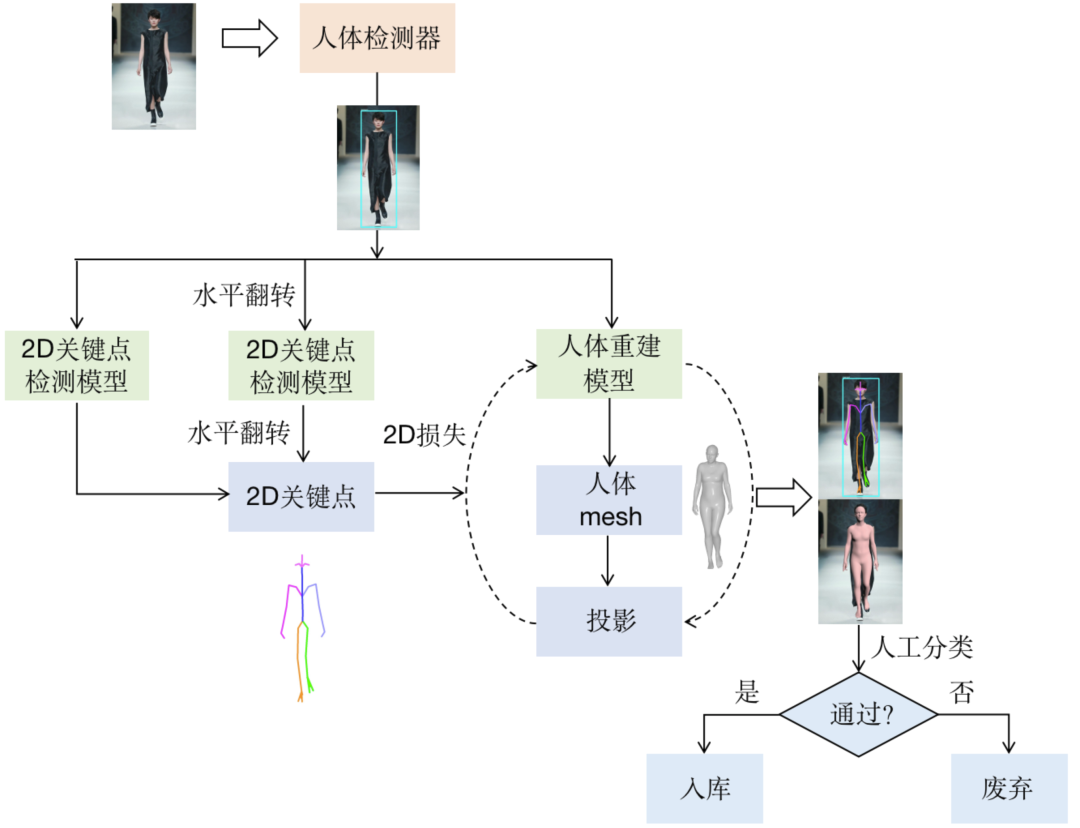
模型设计与特点
泛娱乐场景下,用户设备的计算资源极为有限,即使用户有高计算性能的GPU,为了确保流畅的渲染效果,能分摊到算法模块的计算资源也很苛刻。为了保证在计算资源匮乏的背景下,仍需输出稳定准确的人体动捕效果,我们采取了多种策略,包括大模型蒸馏、模型剪枝和训练时量化等,对人体动捕模型的推理性能和效果进行了深度优化。目前,即使在普通的Nvidia 2060设备上,人体动捕模型仅需3毫秒即可完成所有的工作。
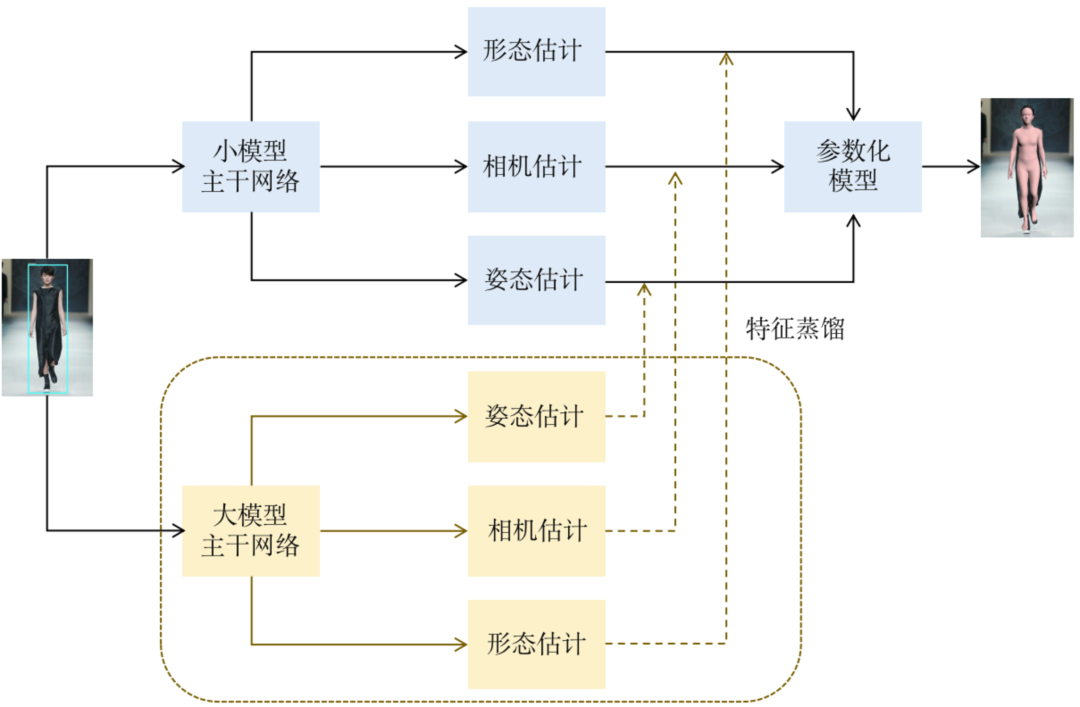
自适应后处理
在直播场景中,主播经常进行类似于挥手打招呼等交互动作,这时用户肢体通常处于模糊状态。为了确保这种状态下的稳定性,竞品通常采用低通滤波的方法实现平滑后处理,但这往往会导致明显的动作迟滞感。为了解决这个问题,我们自主研发了一种后处理模块,结合时空信息,可以捕捉实时直播过程中可能出现的异常,并进行稳定去噪,同时保证准确捕捉动作的高灵活性。与竞品的树懒式挥手相比,我们的自研算法可以非常真实地感知用户快速运动时的加速度,为用户提供更有体感的动作反馈。
手势3D姿态估计
手势3D姿态估计是指在给定一张手势图像的情况下,预测手的三维姿态。这是一个非常具有挑战性的问题,其中一些难点包括:
- 视角变化:由于手势可以在各种不同的方向和视角下出现,因此在不同的视角下准确估计手的3D姿态是一个挑战。这涉及到解决深度感知和空间变换等问题。
- 遮挡和噪声:手势图像通常会受到遮挡和噪声的影响,这会使得手势3D姿态估计变得更加困难。遮挡可能会导致某些部分无法被观察到,从而导致姿态估计不准确。
- 双手识别:双手手势交叉和自遮挡,导致任务变得更复杂,同时,要准确的估计出双手手势,需要精确的估计出双手之间的控制位置关系
- 数据集:在手势3D姿态估计的训练过程中,需要大量的标记数据,但是获得高质量的数据集非常困难。大部分带有3D标签的数据都是实验室场景获取,基于此训练的模型泛化性比较差。
- 计算效率:手势3D姿态估计涉及大量的计算,需要高效的算法和计算设备,但实际使用场景,虚拟主播可能没有很好的硬件设备,在此硬件上能够做到实时流程动捕,是比较大的挑战
综上所述,手势3D姿态估计是一个非常有挑战性的问题,需要在视角变化、遮挡和噪声、多手势识别、数据集和计算效率等方面进行解决。我们提出了一种同时利用2D和3D数据,通过两种方式来估计手势的3D姿态,一个是通过一个参数化的手势模型,另一个是直接归手势的3D骨骼点。其次,我们设计了一种基于热力图+回归的方式,既保留了热力图方式的准确性,又提升了计算效率。算法整体的框架图如下:
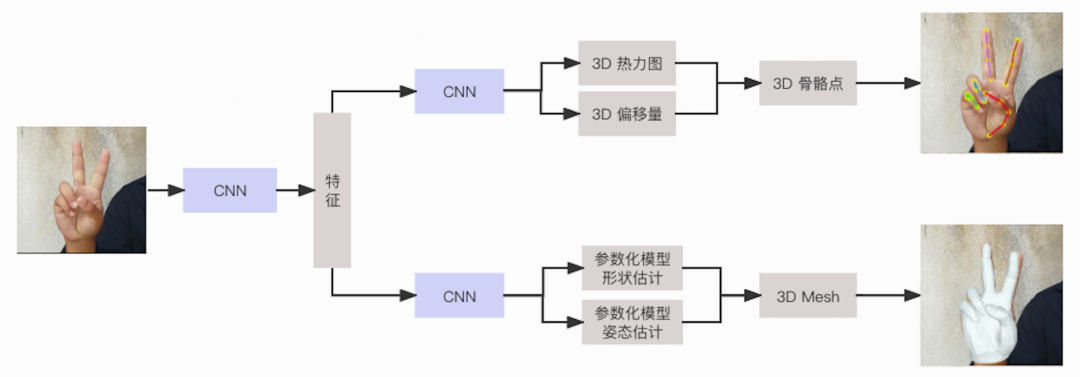
输入图片经过backbone网络,得到特征分别进行参数化手势模型预测以及3D热力图+offset预测,两个分支得到的3D坐标进行L2一致性约束。这样做既可以通过参数手势模型分支保持手的形态学约束,又能利用3D直接预测分支的灵活性,提升点位准确性。
训练数据方面,我们采用了一部分动捕房采集的带有3D标签的数据(大约50W帧),以及一些只标注了2D关键点(大约20W帧)的数据,分别用对应的3D和2D信息进行监督。
最终,我们算法的量化指标达到了当前业界SOTA标准。在实际应用场景,通过和虚拟开播业务更好的结合,在各种复杂场景下的效果达到了工业界一流水平。性能方面,在GPU2060上,速度可以达到3ms以内,满足多应用场景下的性能要求。
未来方向
下一步我们还将AI技术与虚拟技术进行更深程度的结合,提升整个虚拟内容创作的效率。更大程度的增强虚拟内容制作的自由度,降低制作门槛,赋能更多的内容创作者。
作者 / 蒋宇东:哔哩哔哩技术专家;何涛:哔哩哔哩资深算法工程师;杜睿:哔哩哔哩资深算法工程师;陈卫东:哔哩哔哩资深算法工程师;陈保友:哔哩哔哩资深算法工程师
来源:B站虚拟人团队 / 哔哩哔哩技术
原文:https://mp.weixin.qq.com/s/XNYD0CUC4XPeS1tjxLYQtw
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。