
本文主要介绍了一种新的用于实时视频通信的自适应前向纠错(AFEC)。能够改善由于视频包丢失导致的视频质量,同时最小化额外带宽。工作主要包括两部分:PL-VQA —— 一种新的无参考分组级视频质量评价方法、RL-AEFC —— 基于强化学习的 AFEC,用 PL-VQA 作为组件来实施估计视频质量。
AFEC
在实际生活中,我们需要实时的视频通信,也有视频点播任务。对于视频点播任务而言,采用 TCP 协议,当出现丢包损失时,我们可以重新传输进行解决,这不会对用户体验产生较大影响。但是对于实时视频通信,通常采用 RTP ,重新传输是不可取的,比较好的解决方法就是利用 AFEC。
丢包损失主要影响的就是视频质量。视频质量对比如下图所示。


基于监督学习的 PL-VQA
视频质量评价主要分为全参考评价和无参考评价,全参考评价需要原始视频与传输视频进行对比,而无参考评价不需要原始视频。因此对于实时视频通信而言,我们没有原始视频,只能进行无参考质量评价。无参考质量评价速度快但是准确度却远小于全参考质量评价,因此综合考虑,我们采用一个好的全参考 VQA 作为 ground truth 加上好的视频特征表达建立了 PL-VQA 模型。
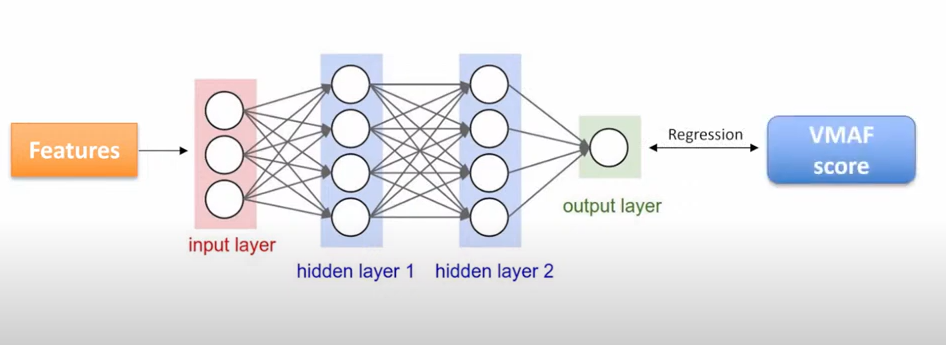
在实际中,我们采用了 VMAF 作为ground truth。训练了一个全连接网络,输入特征,对 VMAF 分值进行回归拟合。
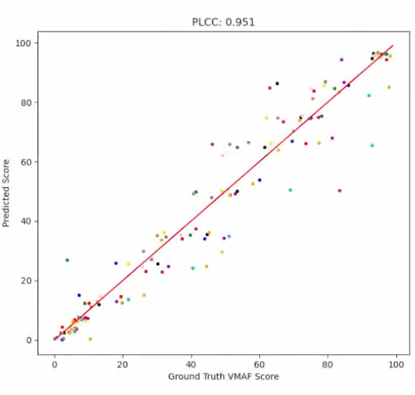
上图展示了每个视频的预测分值与 VMAF 分值之间的关系,横轴 VMAF 分值,纵轴是预测分值,不同颜色表示不同视频,相同颜色的不同点代表了 11 种不同的损失率(0.1%,0.5%,1%,…,4.6%,5%)。PLCC 结果为0.951,证明了模型的准确性,预测值接近 ground truth。
基于强化学习的 AFEC
动机
我们面临的主要挑战是网络的不稳定性,没有人知道网络下一秒的状况如何。因此 RL-AEFC 的主要目标是用最小的带宽损失修复丢失的包。
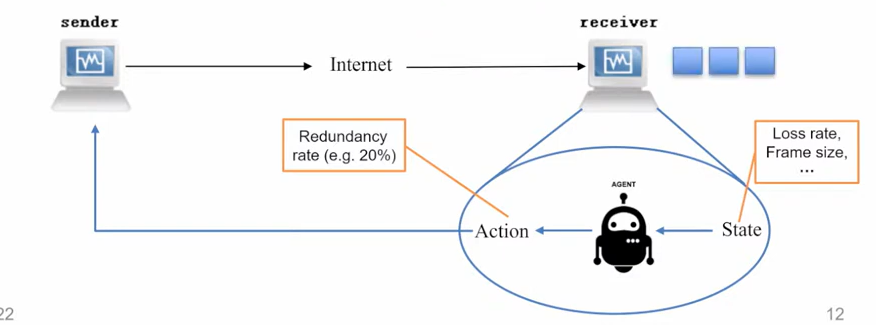
模型设计
State 设计
State 应该包含丢包损失和视频特性的相关信息。我们每秒(30 帧)对视频包流进行一次信息提取,包括每帧的丢包损失率、每帧的大小、运动估计,计算方式如下。
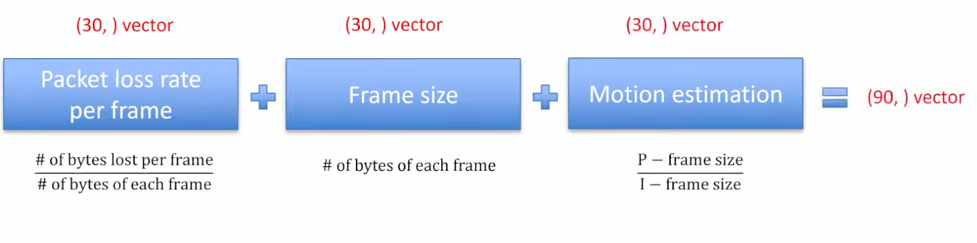
这样处理得到的每秒特征向量的维数是 90 ,每个 State 包含 5 秒,这样得到一个 90×5 的矩阵。
Action 设计
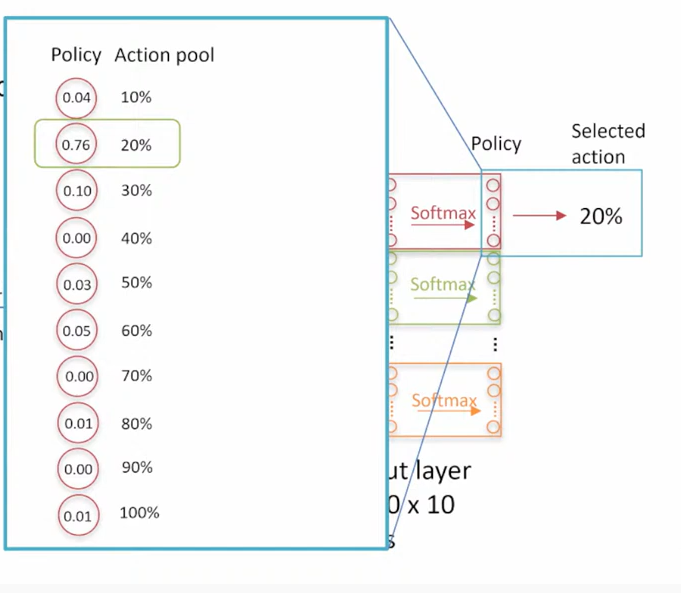
每帧进行 Reed-Solomon 编码,属于相同帧的包作为一个数据块(block)。Action pool 中包含 10%-100% 不同的冗余率。Agent 每帧选择一个冗余率。比如选择了 20% 作为 I 帧的冗余率,该帧包含 10 个包,然后根据指示添加了 20% 的冗余包进行传输。
方法
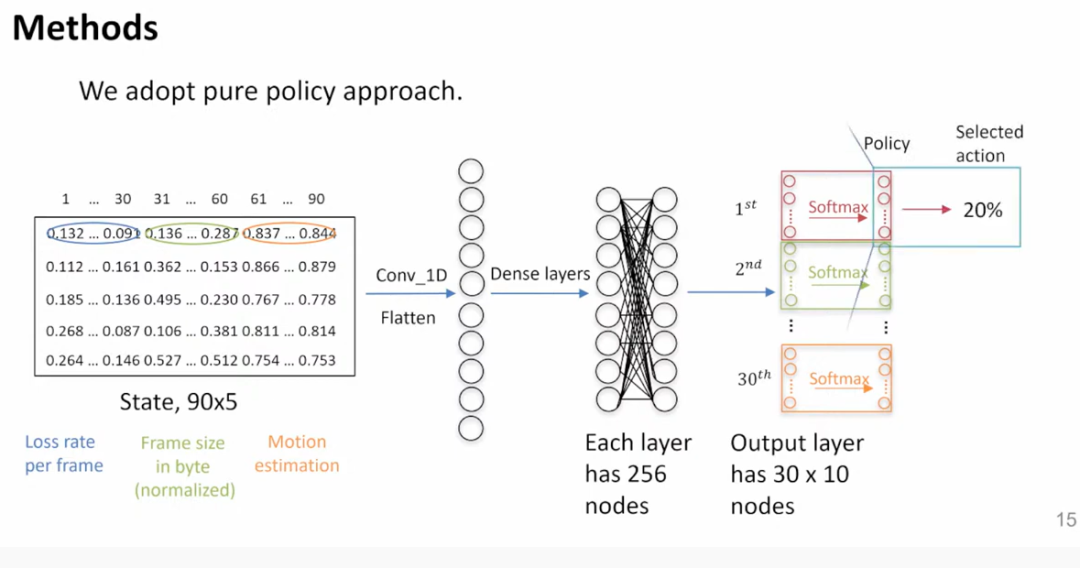
90×5 的状态矩,阵作为输入,通过全连接网络层,输入层包括 30×10 个节点,经过 Softmax 处理,选择不同概率的点进行添加不同大小的冗余率,分布如下图。
评价
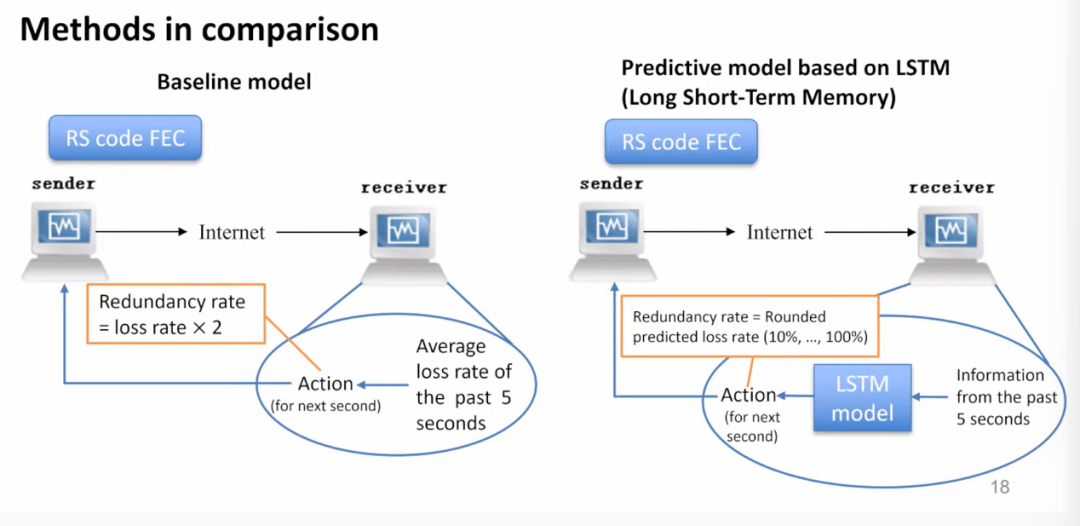
上图展示了 Baseline 和 LSTM 方法的框架,将本文方法与其进行了比较,实验结果如下。
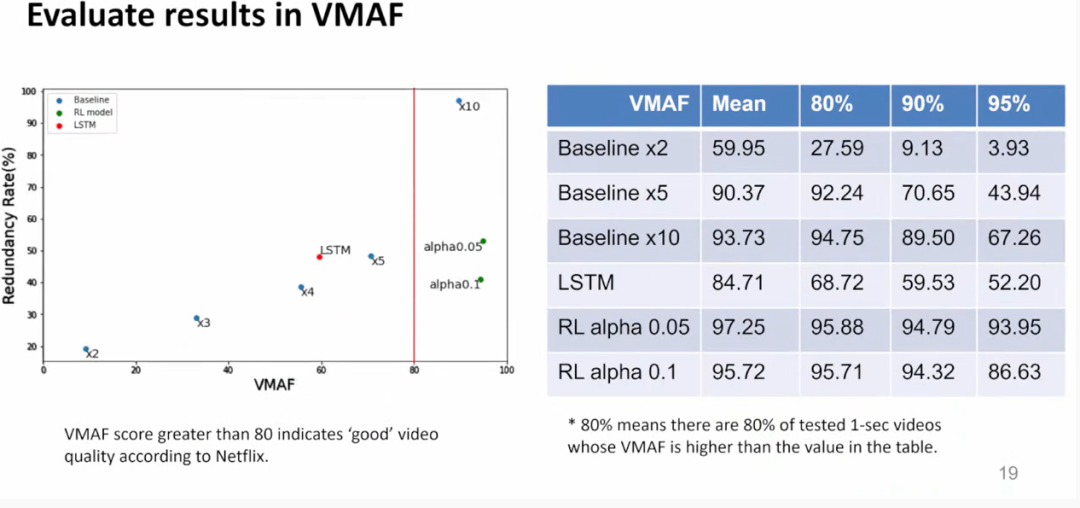
结果表明, RL-AFEC 可以实现在较低冗余率下取得较高的 VMAF值。
结论
本文提出了解决实时通信丢包问题的 PL-VQA 和 RL-AFEC。方法具有实时性、鲁棒性、快速性。实时性:每一秒,RL-AFEC 都会根据过去相邻 5 秒信息的反馈,选择合适的冗余率来解决下一个 1 秒间隔视频传输中可能存在的丢包问题。鲁棒性:根据实验结果,RL-AFEC 实现了测试集中超过 95% 的 1 秒视频的 VMAF 分数大于 80,而额外的带宽消耗**低至 40%**。快速性:RL-AFEC在普通电脑上每次选择action 仅需1ms左右。
来源:ACM MMSys2022
主讲人:Ke Chen
内容整理:张雨虹
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。