
背景介绍
随着 AIGC 和大模型在各个领域逐渐应用,消费者对于个性化、高效、便捷的客户服务和体验需求越来越高。而语音算法作为一种人工智能技术,可以实现语音识别、语音合成、语音情感识别等功能,为企业提供更智能化、个性化的客户服务和营销服务。
在网易云商的产品和服务中,语音算法已经广泛应用于 AI 外呼、呼叫中心、智能坐席辅助、在线机器人、呼入机器人等场景,通过提高客户服务和营销的效率和质量,帮助企业实现全渠道客户服务、精细化客户关系管理、优化客户体验,提升商业价值和品牌价值。
本文首先介绍在云商深耕的语音算法和相关业务,重点展开语音算法在 AI 外呼中的应用、挑战和优势。最后,展望未来语音技术的发展趋势,探讨语音算法在云商业务中的发展前景。
语音相关业务简介
网易云商针对客户痛点,打造了全面的智能化解决方案,构建了服务营销一体化平台,覆盖多种业务。红框为应用语音技术的部分业务。
- 智能外呼:实时转写用户电话语音,精准理解用户意图,高效触达用户。
- 坐席辅助:实时转写用户电话语音,界面展示通话内容,推荐最佳服务策略。
- 留言工单:离线转写用户留言电话,生成工单,快速响应留言需求。
- 呼入机器人:实时转写用户电话语音,提供智能接待服务。
- 智能质检:转写客户与用户对话语音,质检违规内容,提升服务质量。

语音算法及业务应用场景
- 语音识别(ASR,automatic speech recognition):一种将说话人的语音转换为文字的技术。在智能坐席辅助场景中,语音识别将用户的语音转换成文字,应用自然语言理解技术精准理解文字意图,快速向客服推送知识和话术,从而辅助客服高效专业的服务用户。
- 语音关键词检测(KWS,keyword Spotting):在语音中检测出特定关键词的技术。在呼叫中心业务中用于反欺诈检测,检测对话中是否包含诈骗等敏感词,为用户的呼叫安全保驾护航。在 AI 外呼业务中用于回铃检测环节中,检测未接通电话回铃音频的中文提示音,从而获取电话未接通的原因,提升外呼的触达能力。
- 音频事件检测(SED,sound event detection):用于检测音频中发生事件的类别和时间点。在 AI 外呼业务的虚拟号外呼场景下,用于检测电话的接通时机。
- 语音活性检测(VAD,voice activity detection):用于检测声音中的有效语音,区分语音和噪声片段。语音活性检测一般应用于语音识别技术之前,提高语音识别算法的效率和识别结果准确度。
- 语音合成(TTS,text to speech):是指将文字转换为语音的技术,它可以模拟人类语音并生成自然流畅的语音输出。在 AI 外呼和呼入机器人业务中,广泛使用语音合成技术,支持多种维度的定制化需求,极大解放了客服的工作量。
AI 外呼业务中语音算法典型应用
AI 外呼是什么
AI 外呼是智能化的呼叫系统,自动对外呼叫无需客服参与,基于 AI 技术打造的机器人自动完成与用户的对话,精准理解用户的意图,筛选意向用户,达到智能化服务和精准营销的目的。AI 技术由三大业内顶尖算法支撑:语音识别、自然语言理解、语音合成。此外系统支持外呼任务管理、自动拨打、智能沟通、智能意图分析、智能电销辅助等功能,形成全面的服务营销一体化方案。
应用场景
- 客户筛选
- 问卷调查
- 信息通知
- 活动邀约
- 微信导流
… …
整体流程与技术指标
- 意向率所有电话接通的用户中,有明确意向的用户比例。AI 外呼的核心指标,主要依赖于“智能对话模块”的体验和准确率。
- 接通率所有呼出电话的用户中,电话接通的用户比例。影响意向率指标,取决于“线路保障”质量和策略。
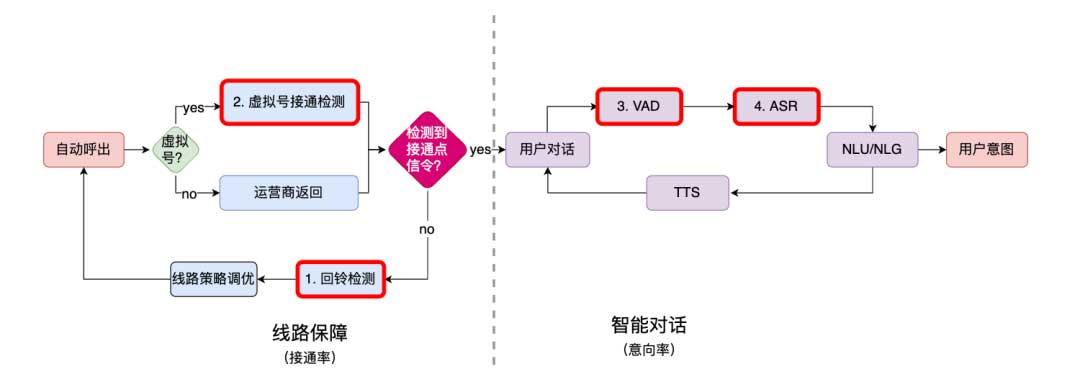
关键语音算法
- 回铃检测回铃检测是 AI 外呼中的一个关键环节,目的是为了获取未接通电话的原因,感知线路状态,针对性调整外呼策略,从而提高接通率。然而,由于存在多种未接通状态和线路质量失真等难点,如何提高检测精度是需要解决的问题。云商的解决方案包括:归纳 11 类状态、采用语音关键词检测算法和 dilated cnn 分类模型、跳帧解码技术、数据增强、帧概率平滑、累计计数等,同时采用 chunk 方式送入特征加快解码。通过这些技术手段,方案实现了精准率达到 98% 的业务指标,相比基于轻量化 ASR 方案,速度提升了 15 倍。
- 虚拟号接通点检测实际外呼时,出于隐私保护的角度,部分号码为虚拟号码。而虚拟号码外呼时,运营商不会返回接通信令,检测接通电话时机则为一个至关重要的环节。然而,在接通之前,音频模式复杂,如何准确检测接通时机是一个难点。云商的解决方案采用了音频事件检测算法,包括能量 vad、dilated cnn 分类模型和模式匹配等技术,能够适时接入 ASR 算法,提高语音转写精度。业务指标表明,F1 score 超过 96%,latency 低于 1s。该算法为虚拟号外呼场景下的接通检测问题提供了高效、精准的解决方案,可广泛应用于企业外呼客服等领域,提升客户服务质量。
- VAD 算法VAD 算法通常被用于分离出声音信号中的语音部分,过滤掉其他噪声部分。AI 外呼场景充斥着各色噪声,如何在复杂的噪声环境中,精准找到语音片段并通过语音识别算法转写,成为了影响用户对话体验的一个关键因素。云商采用了 chunk-based self-attention 技术,比传统的 cnn-based、rnn-based 等 VSD 方案,具有更高的噪声鲁棒性,并且计算量更低。业务指标显示,在外呼场景下,F1 大于 95%,延迟小于 400ms,人机对话快速响应,极大地提升了客户体验。
- ASR 算法准确转写用户语音是理解用户意图的前提。实际外呼时,转写精度易受方言、口音、高噪声、实体词等问题的影响。云商基于具备海量的自有数据和完善的深度学习基建,针对外呼的特性提供了专业的 ASR 解决方案,包括 badcase 快修、领域迁移、热词增强等,能有效提高ASR算法的鲁棒性和识别效果。采用半监督算法 NST(noisy student training)和置信度模型 NCM(normalized confidence model),基于海量数据利用伪标签进行 Self-Training,错误率相对降低 11%。基于 WFST 的热词增强功能,能够快速修复实体词识别不准的问题,支持通话级别的调优。支持不同领域的语言模型定制,形成数个行业专属模型。打造数据闭环平台,能够自动发现线上 badcase,并主动收集训练数据,支持快速迭代 ASR 模型。采用模型量化和算子优化等方式,实现效果不变的情况下,IT 成本降低 30%。
ASR 系统相关优化方案
- 定制化ASR方案在不同行业和企业中,智能外呼系统的服务范围非常广泛。每个客户的话术和业务背景可能会涉及许多特定领域的专业术语和行业词汇。为了提供更精准、自然流畅的语音识别结果,我们的语音识别系统具备强大的全自动定制化能力,可以根据不同客户的需求和语言习惯来优化语音识别效果,从而提升 AI 外呼的用户体验。为了实现这一目标,我们采用了多种策略和技术。比如,在智能外呼系统中,我们根据客户提供的话术文本,借助多种算法的组合,进行自动行业匹配、语言模型训练和热词自动提取等操作,通过这些定制化策略能够显著提高特定领域词汇的识别准确率。下图是所述技术方案的流程图。
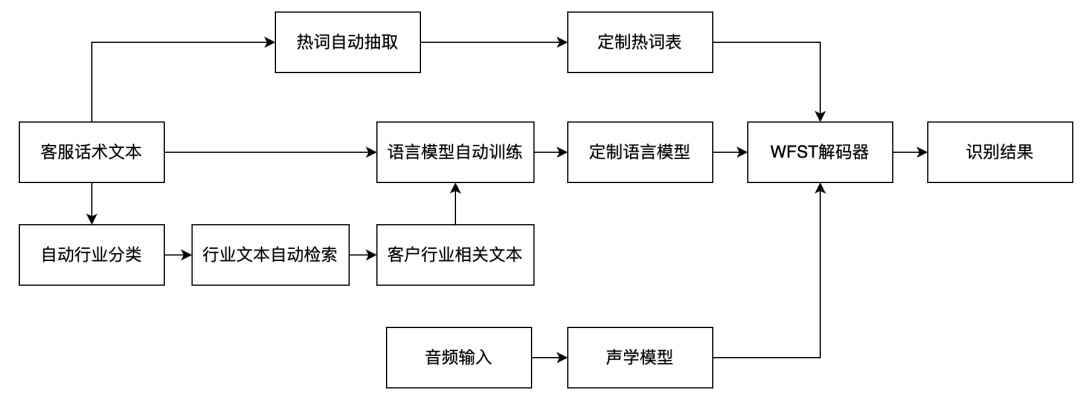
实时 ASR 引擎加速方案
在实时 ASR 场景中,我们需要确保识别结果准确性,同时也需要为实时语音交互和人机对话提供更加流畅和自然的体验。因此,为了提高实时 ASR 流式引擎的计算效率并快速输出识别结果,我们进行了很多优化工作,其中比较重要的有以下两个:
– 模型量化:通过模型量化,可以将模型中的浮点数参数转换为整数或低精度的固定点数,从而减少模型的存储空间需求。此外,量化后的模型在推理过程中所需的计算量也大大减少,进而提高了实时 ASR 引擎的计算效率。对于实时流式引擎来说,计算效率的提升可以使得引擎能够更快地进行语音识别推理并实时输出结果。实验结果表明,通过模型量化,我们能够在不降低识别准确率的前提下,将推理速度相对提升 54.3%。
– Encoder模块拆分:将 Encoder 模块拆分为 Encoder Online 和 Encoder Offline 两个部分。Encoder Online 负责实时处理部分识别结果,为提供快速反馈和互动式体验而设计。该部分能够迅速将用户讲话的音频数据转化为文本的中间结果,以便在识别过程中逐步输出。而 Encoder Offline 则是在 Encoder Online 的基础上进一步优化,搭配 Encoder Online 一起工作,共同生成最终的识别结果。通过这种 Encoder 的拆分式架构设计和精心的优化策略,我们成功提升了实时 ASR 引擎的推理效率,保证实时推理过程的流畅性和响应速度。这样的设计虽然会牺牲一部分中间结果的准确率,但对最终识别结果的准确率无影响。实验结果表明,相对于传统 ASR 引擎,我们的改进使引擎推理速度相对提高了 24.2%,中间结果准确率相对下降 9.7%,最终结果准确率不变。
LLM辅助下的异常案例智能检测方案
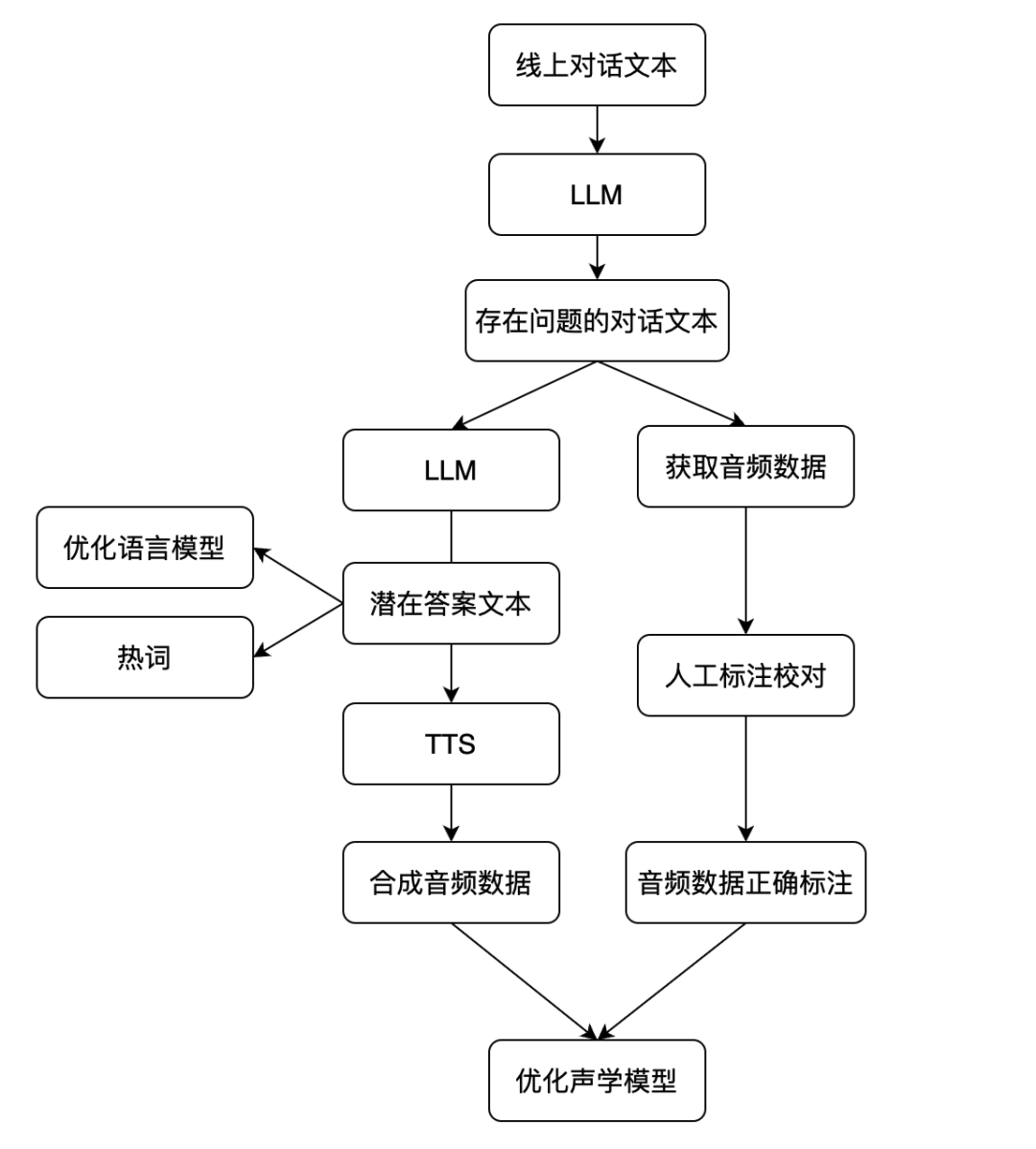
我们通过利用大语言模型(LLM),可以对问答场景下的识别结果进行合理性判断。如果判断发现回复不合理,则可能是由于语音识别错误导致的。同时,我们可以结合 ASR 模型的置信度以及多模型结果的一致性等指标,进一步进行筛选,自动发现线上的 badcase。基于这些 badcase,我们可以借助 LLM 进一步生成正确的文本语料,并通过 TTS 生成音频数据。这些数据可以作为训练数据,更有针对性地更新 ASR 声学模型和语言模型,从而不断提升语音识别的准确率。下图是方案的流程图。
语音算法发展趋势和云商业务未来应用
最近深度学习领域给大家感受最深的就是 AIGC 技术和自然语言大模型层出不穷,云商在这方面布局已久。已有多个百亿参数的自然语言大模型应用在智能客服等业务中。同时也在探索语音自监督学习、语音大模型、语音多模态等前沿技术。
- 语音自监督学习不需要任何有标注数据,通过生成,预测,重构等方法,学到本质声学表征,经过少量有监督数据即可迁移到不同的语音任务上,常见的自监督学习模型有wav2vec 2.0和data2vec等。
- 语音大模型通过大量有标注数据或者海量无标注数据,利用有监督学习或者无监督学习训练大模型,充分发挥大模型学习能力强鲁棒性好的优势。Meta 推出了 10 亿参数的 MMS 语音大模型,可支持多达 1167 种语言的语音识别。
- 语音多模态多模态信息提供了更加丰富的上下文信息,并且可以交叉验证,取得比单模态模型更好的效果。Google 的 AudioPaLM 大模型统一了文本和语音两个模态,在语音领域的 ASR 任务和文本领域的 MT 都取得了不错的效果。
目前云商已利用海量数据优势,构建基于业务的语音大模型,有效利用无标签数据和小样本数据。在 ASR 多语言识别场景下,能有效提升模型在复杂场景下的鲁棒性和识别效果上限。增强产品差异性优势,深度赋能服务营销一体化,提供更优质的客户体验。
作者:云商 AI 技术组
原文:https://mp.weixin.qq.com/s/mFtv3YOwCi1Ya6ROto89Pg
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。