
物理世界的信息由图像、声音、文字交织而成。今天的大模型,本质上仍然是以语言为中心的建模系统,语言作为人类智慧符号化表述,在“压缩即智能”的范式下表现出强大的能力。但通往真正的物理世界智能,也许语言并不是世界的边界。视觉、语音与文本等多模态信号,实际上是对现实物理对象的不同侧面投影。
这就引出一个根本问题:能否让 AI 像处理语言一样,用同一种方式简洁有效地处理物理世界的多种信息? 如果能,那么物理世界的AI就有了统一的“母语”,Token 不再局限于文本,而是成为描述一切物理信号的原生表示。对这些信号进行统一建模与压缩,可能使模型学到更加本质的表示,并实现更深层的模态内化。
LongCat 团队经过研究发现:在统一的建模框架与优化目标下,可以构造一种语义完备的离散表示。我们将图像、语音与文本统一映射为同源的离散 Token,使模型从学习连续空间的映射,转向学习离散 ID 之间的关系结构,并通过纯粹的下一个Token 预测(Next Token Prediction, NTP)范式,以一种统一的、优雅地方式建模各种物理信号。
LongCat-Next 是我们在通往物理世界 AI 道路上的一次探索。今天,我们把研究思路的核心——LongCat-Next 模型和它的离散分词器全部开源,希望更多开发者能基于它,构建真正能感知、理解并作用于真实世界的AI。
01 我们如何构造物理世界的“母语”
接下来,我们将逐一拆解三项核心技术,看看我们是如何让 AI 真正拥有物理世界的“母语”。
1.1 离散原生自回归架构 DiNA:简洁统一
业界主流的多模态大模型长期受制于“语言基座+外挂视觉/语音模块”的拼凑式架构,非语言模态往往只作为辅助组件存在。这种设计带来很多结构性问题,比如图像理解与生成在结构与优化上长期割裂:前者依赖对齐机制,后者依赖扩散等独立模型,多模态信息始终停留在“被投影”,而非“被内化”。
为此,我们构建了 DiNA(Discrete Native Autoregressive )离散原生自回归架构。其核心非常简单:
|将所有模态统一为离散 Token,并用同一个自回归模型进行建模。
它将物理世界广泛存在的多模态信号收敛为同源的离散特征,实现了视觉、语音、文本多模态的底层建模统一。作为整个大语言模型体系的自然扩展,DiNA 彻底打破了模态间的隔阂。它通过极简的下一Token预测(NTP)范式,将图像、声音和文字统一转化为同源的离散Token。在这套原生的统一架构下,视觉的“看”与“画”、听觉的“听”与“说”,不再是拼接的异构模块,而是同一套预测逻辑的自然涌现。
简单而言:我们把文字、图像、语音都变成同一种东西——离散Token。无论读文字、看图片还是听声音,对AI来说都是同一件事:预测下一个Token是什么。
这个设计带来3个根本性改变:
- 架构极简:所有模态共享同一个自回归骨干,这意味着,无论输入的是文字、图像还是音频,模型都用同一套参数、同一个注意力机制、同一个损失函数。这种统一设计,让模型在训练时更稳定,部署时更轻量。我们用LongCat-Flash-Lite MoE(68.5B总参数,3B激活参数)作为基座,在这个框架基础上训练了LongCat-Next。实验表明,DiNA的MoE路由在训练中逐渐出现模态专精化,激活专家数量相比纯语言设置有所增加,模型正在用更大容量支撑能力扩展。


理解与生成对称:LongCat-Next用同一个自回归模型同时实现了视觉理解和生成,通过这样解决了长期困扰的理解生成架构和优化不一致问题,在统一 Token 空间中,理解与生成被统一为同一数学问题,两者本质上都是条件下的 Token 预测:
· 图像 → 文本:理解
· 文本 → 图像:生成
给定图像Token预测文字Token是“理解”,给定文字Token预测图像Token是“生成”——数学形式完全一致,从此不再割裂。实验证明,这种对称设计在优化上消弭了冲突:统一模型的理解损失仅比纯理解模型高 0.006,而生成损失比纯生成模型低 0.02。理解没有损害生成,反而表现出协同潜力。

模态内化:在离散原生训练范式下,不同模态被统一编码为 Token,并以相同方式建模。我们观察到:
· 不同模态的 Token 表征在表示空间中自然融合(t-SNE 可视化)
· MoE 专家自发形成模态偏好分化
这表明模型并非在“对齐模态”,而是在内部形成统一的多模态表征结构。

(b) LongCat-Next 的表征空间体现出更融合内化的模态间关系
1.2 离散原生分辨率视觉分词器 dNaViT:构造“视觉单词”
如果说 DiNA 解决的是“如何统一建模”,那么 dNaViT 解决的是:
|如何让图像本身能够被离散化为可建模的 Token。
LongCat 团队首创的 dNaViT 技术相当于语言模型中的tokenizer(分词器)——就像把句子拆成单词,它把一张图拆解成一系列有意义的“视觉词汇”。
- 原生任意分辨率支持(Native Resolution for Understanding and Generation):不做缩放、不裁剪、不填充,每一处细节都完整保留。通过我们精心设计的训练策略,dNaViT 实现了任意分辨率的图像编码与解码——在文档解析(OCR)、复杂图表推理等对细节敏感的任务中具备优势,如在 OmniDocBench、OCRBench 等密集文本场景的的测试中均表现优异。
- 8层残差向量量化 (Residual Vector Quantization, RVQ): 细节多了怎么办?分层打包。类比于第一层打包轮廓,第二层打包颜色,第三层打包纹理……8层级联递归拟合“残差中的残差”,可以实现高达28倍极致像素空间压缩。解码时,DepthTransformer 将多级 Token 合并重建,让压缩与还原高效协同。
- 解耦的双轨生成解码器 (Dual-Path Detokenization):离散token还原图像时,先由“结构像素解码器”保住布局,再由“扩散像素细化器”注入纹理细节。解耦设计降低生成方差,确保文本渲染无损清晰。
更妙的是,这套“视觉词汇”实现了 image → token → image 的完整回环——像语言tokenizer一样,既用于“看懂”图像,也用于“画出”图像。理解时学到的对应关系,生成时正好反过来用——图像描述和图像生成在同一套token序列中闭环流转。
更关键的是,在 LongCat-Next 中:
|视觉 Token 完成的是图像到离散ID的映射,真正的特征是原生学习的。
真正的视觉表征,是在语言模型内部通过 embedding 学习得到的。这意味着模型不是“接入视觉能力”,而是在内部学习并形成自己的视觉语言。
这种从“借用模态”到“内生模态”的转变,是原生多模态建模的核心。


1.3 语义对齐完备编码器:破解“离散化必然损失信息”的难题
离散建模通常被认为受限于两方面:表征容量与离散化损失。然而,我们进一步分析发现,真正决定上限的关键在于:
|离散 Token 本身是否具备语义完备性(Semantic Completeness)。
也就是说,问题不在于“是否离散”,而在于离散后的表示,是否能够同时承载高层语义与细粒度信息(如颜色、纹理与空间结构),从而支撑统一的理解与生成。
基于这一视角,我们提出:实现语义完备离散表示的关键,在于构建合适的表征基础。其中,一类重要的候选范式是 SAE(Semantic-and-Aligned Encoder)。不同于以对比学习为主的模型(如 SigLIP),SAE 通过大规模视觉-语言监督(涵盖图像描述、视觉问答乃至视觉推理等任务),学习高信息密度、多属性的表征。这类表征不仅具备丰富的语义结构,同时我们发现在网络的残差传递机制下,底层视觉细节能够持续向高层传播,从而在抽象语义中保留细粒度信息,为离散 Token 的语义完备性提供基础。
在此之上,离散化过程本身仍需尽可能减少信息损失。为此,我们采用多级残差向量量化(Residual Vector Quantization, RVQ)机制,对表征进行逐级离散建模:通过层级化拟合“残差中的残差”,在有限离散空间内逼近高维连续表示,从而在压缩率与信息保真之间取得平衡。
最终得到的离散视觉 Token,不仅能够支撑细粒度理解任务(例如在密集文本识别中优于连续表征模型),同时也具备高保真的图像重建能力。这表明:
|离散表示并非信息的退化形式,而可以成为统一理解与生成的完备表达载体。

02 实证与洞察
LongCat-Next 在视觉理解、图像生成、音频、智能体等多个维度上,以一套离散原生框架展现出与多模专用模型相当甚至领先的性能。
更重要的是,这些成绩验证了三个关键发现:
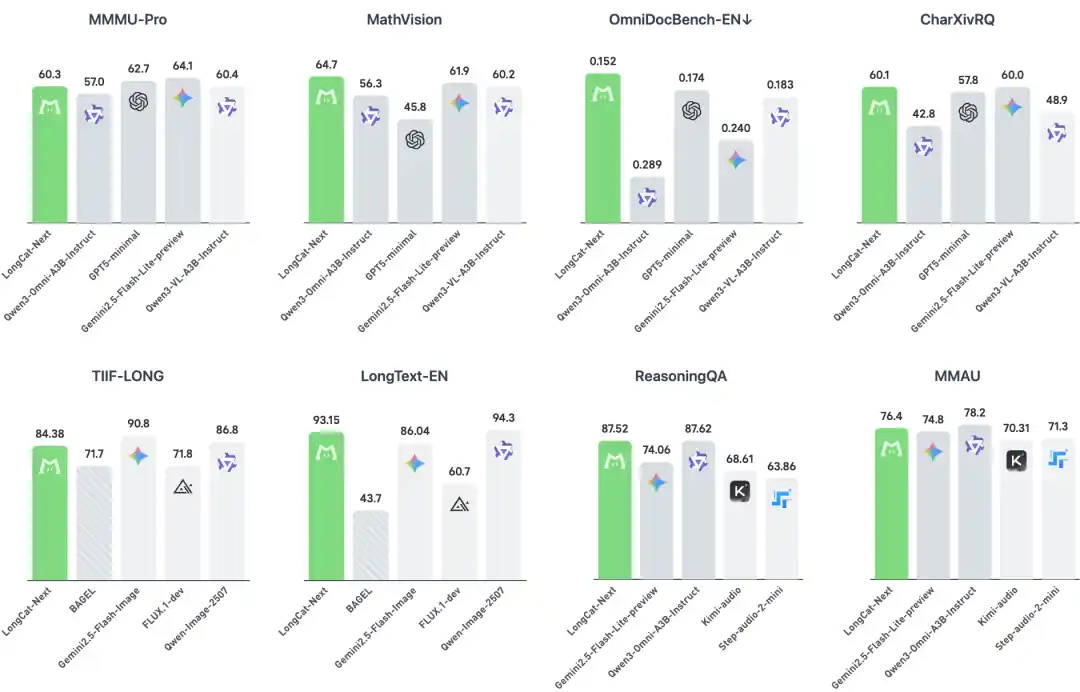
发现一:离散视觉没有天花板
行业长期认为,离散模型在细粒度文本识别上必然不如连续模型,这也是一直阻碍业界使用离散建模作为选项的原因。值得一提的是,经过我们dNaViT的设计以及DiNA的建模框架,LongCat-Next表现出了非凡的细粒度感知能力和高质量的视觉推理能力。
LongCat-Next 在 OmniDocBench(学术论文、财报、行政表格)上的表现(0.152 / 0.226)挑战了这一刻板印象——不仅超越 Qwen3-Omni,还超过了专用视觉模型 Qwen3-VL。离散化不是细粒度感知的天花板,关键在于如何构建语义完备的离散视觉表征。
发现二:理解与生成可以协同
传统观点认为,一个模型很难同时做好理解和生成。但我们发现:消融实验对比中,LongCat-Next 统一模型的理解损失仅比纯理解模型高 0.006,而生成损失比纯生成模型低 0.02。在图像生成上,LongCat-Next 在 LongText-Bench(英文 93.15);在图像理解上,MathVista(83.1)达到领先水平,成为一个具备工业级潜力的理解生成统一方案。理解没有损害生成,反而表现出协同潜力。
发现三:统一框架不折损语言能力,与智能体与音频交互上形成跨模态协同
在纯文本任务上,LongCat-Next 的 MMLU-Pro(77.02)和 C-Eval(86.80)表现领先,证明原生多模态训练未削弱语言核心能力。在工具调用上,τ²-Bench 零售场景(73.68)大幅领先 Qwen3-Next-80B-A3B-Instruct(57.3);在代码能力上,SWE-Bench(43.0)显著超越同类模型。
在音频领域,这一框架同样展现出良好的通用性。TTS任务上,SeedTTS的中文和英文WER分别低至1.90和1.89;音频理解上,MMAU(76.40)、TUT2017(43.09)均达到先进水平。更重要的是,模型支持低延迟的并行文本语音生成与可定制的语音克隆,让语音交互更自然、更个性化。
当模型学会用同一种方式理解图像、声音和文字,它在理解世界时变得更聪明了——无论是看懂图表、听懂语音,甚至是调用工具、编写代码。
LongCat-Next 现已开源
作为一个初步的尝试,我们展示了一个有意义的视角:物理世界的信息可以被离散化、统一化、像语言一样被建模,让 AI 第一次能够像处理文字一样原生地理解物理世界的多模态信号。
今天,我们把这个探索研究的过程及产物——LongCat-Next模型和dNaViT分词器全部开源:
🚀 开源平台链接:
- Paper:https://github.com/meituan-longcat/LongCat-Next/blob/main/tech_report.pdf
- GitHub:https://github.com/meituan-longcat/LongCat-Next
- HuggingFace: https://huggingface.co/meituan-longcat/LongCat-Next
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。