
文章来源:arxiv 2506
论文题目:MagiCodec: A Simple Yet High-Performance Single-Layer Streaming Audio Codec with Masked Gaussian Injection
论文作者:Yakun Song, Jiawei Chen, Xiaobin Zhuang, Chenpeng Du, Ziyang Ma, Jian Wu, Jian Cong, Dongya Jia, Zhuo Chen, Yuping Wang, Yuxuan Wang, Xie Chen
原文链接:https://arxiv.org/abs/2506.00385
代码链接:https://github.com/Ereboas/MagiCodec
内容整理:刘昱涵
神经音频编解码器将原始波形映射为离散token,为音频生成模型提供了基础。然而,现有方法主要针对重建质量优化,忽略了离散token的下游可建模性。本文提出 MagiCodec,一个单层、流式Transformer音频编解码器,通过多阶段训练 + 高斯噪声注入 + 隐空间正则化,显式提升token的语义表达能力,同时保持高保真重建。理论分析表明,噪声注入在频域等价于低通滤波,衰减高频成分,促使模型关注低频语义结构。实验证明,MagiCodec在重建质量(PESQ、STOI、UTMOS)和下游任务(零样本TTS、音素识别、情感分类、非语音检测)上均超越现有SOTA,且其token分布呈现类似自然语言的齐普夫分布,更有利于语言模型建模。
1. 研究背景与核心问题
1.1 神经音频编解码器与生成式音频
现代神经音频编解码器(如EnCodec、SoundStream、DAC)通常采用编码器-量化器-解码器架构,将连续音频信号离散化为token序列,广泛用于音频语言模型的tokenizer。其优化目标通常是重建保真度(如频谱损失、对抗损失),追求在低比特率下还原高质量音频。
然而,在生成式任务(如TTS、语音LLM)中,离散token不仅需要支持高保真重建,还需要具备:
- 语义可建模性:token序列应易于被自回归模型学习,分布结构清晰(如齐普夫分布)。
- 压缩高效性:低比特率、低帧率、单层量化以减少生成模型的计算负担。
- 流式推理:支持实时低延迟处理。
1.2 现有方法的困境
| 方法类型 | 代表工作 | 优点 | 缺点 |
|---|---|---|---|
| 纯重建优化 | EnCodec, DAC, BigCodec | 重建质量高,保真度好 | token语义弱,下游生成模型难以学习;多层RVQ复杂度高 |
| 语义增强 | SemanticCodec, X-Codec | 借助自监督模型(AudioMAE等)显式注入语义 | 依赖外部预训练模型;可能丢失高频细节;非流式,参数大 |
| 单层轻量 | TS3Codec, WavTokenizer | 流式、低延迟、参数少 | 重建与建模之间的权衡仍不理想,码本利用率低 |
EnCodec、SoundStream:将保真度和计算效率作为重建的主要目标,常常忽视离散表示的语义可建模性。
生成能力与重建质量之间的优化困境:提高重建质量可能会损害生成性能,并需要更大的模型和更多的训练资源;反之,限制重建能力则会降低生成质量的上限。因此,过分强调重建目标往往会显著复杂化生成模型的训练。
SemanticCodec、Xcodec:融入语义信息,会导致高频纹理细节的丢失以及轻微伪像的引入。
1.3 本文要解决的问题
在不引入外部监督模型的前提下,如何让单层流式音频编解码器同时实现高保真重建和强语义可建模性?
本文提出MagiCodec,通过频域正则化视角的高斯噪声注入和三阶段渐进训练,内生地引导编解码器学习低频主导的、结构化的离散表示,使token分布接近自然语言的齐普夫定律,从而在重建和下游任务中均达到SOTA。
2. 核心技术方案:MagiCodec
2.1 整体架构概览


MagiCodec采用单层、流式Transformer架构,包含三大组件:
- 编码器:
- 线性下采样: 下采样因子 r∈{160,320,640},对应帧率 100/50/25 Hz
- 窗口大小为32,潜空间维度4096的Transformer(仅左上下文,保证流式)
- 最后一层降维linear层,输出匹配VQ的向量维度 D=16。
- 量化器:单层VQ,码本大小 K=131072(17bit),维度16。训练时使用直通估计器(STE),推理时硬量化。
- 解码器:对称结构,线性升维至H=4096。左窗口32+右窗口2的Transformer (50Hz下lookahead为40ms,提升质量)→ 线性上采样重建波形。
关键设计:超大型码本(13万)配合三阶段训练避免坍塌;单层量化降低下游建模复杂度;非对称上下文窗口(解码器有右上下文2)在不破坏流式的前提下提升重建质量。
2.2 高斯噪声注入:频域正则化
2.2.1 动机
神经网络存在频谱偏差:优先学习低频结构,高频分量难以拟合且易过拟合噪声。过度保留高频细节会浪费比特、增加下游模型拟合难度。本文提出掩码高斯噪声注入,在训练时以概率 p 将输入帧替换为独立同分布高斯噪声 ε~N(0,σ²I),从傅里叶分析的角度可以证明它对高频分量施加了指数衰减的正则化。
2.2.2 理论分析(命题1)
使用随机加性噪声的训练已被证明等价于在损失函数中引入 Tikhonov 正则项,后续研究进一步将其解释为显式的高频正则化器。
通过使用替换噪声而非加性噪声,我们彻底移除了掩码帧中的局部时域信息,迫使模型依赖更长范围的上下文来进行重建和整体语义建模。利用更长的上下文依赖关系使语言模型能够学习更平滑、低频主导的潜在动态,从而减少下游语言模型达到相同语义覆盖所需的感受野。
命题1. 对于任意可傅里叶变换的网络映射 ff,对输入 xx 应用高斯噪声注入,我们有

即高频成分被指数级衰减,低频成分几乎不受影响。
实现细节:掩码概率 p(0%-30%)控制正则化强度;噪声方差 σ² 固定。仅训练时使用,推理时不注入。
2.3 三阶段训练:避免码本坍塌
传统端到端VQ训练中,未预训练的编码器与随机初始化的码本一起往往会将大部分输入映射到几乎相同的嵌入,导致 VQ 坍塌。
阶段1:自编码器
在不使用任何量化的情况下训练编码器-解码器。同时使用隐空间正则化损失。

阶段2:量化+解码器
冻结编码器,仅优化向量量化器和解码器。

权重0.25
与 SimVQ 采用的方法一致,我们通过基于可学习潜在基的线性变换层对码向量进行重参数化。

阶段3:声码器
编码器量化器冻结只训练解码器。
引入GAN训练:使用BigCodec的MPD(HiFiCodec)+MS-STFT(EnCodec)

3. 实验设置与结果
3.1 训练设置
- 数据集:Libri-light(~6万小时无标注英语语音,16kHz),训练裁剪至每条10s
- 模型配置:帧率50 Hz(主配置,r=320),码本大小131072×16,参数量209.7M
- 优化器:AdamW (β1=0.8, β2=0.99),学习率1e-4 → 余弦退火至1e-5,100k步
- 硬件:16×NVIDIA A100 80GB
- 对比基线:

3.2 评估任务与指标
| 任务类型 | 具体任务 | 评估指标 |
|---|---|---|
| 重建质量 | 客观感知质量 | PESQ↑, STOI↑, ViSQOL↑, UTMOS↑ |
| 内容保真度 | WER↓ (Whisper-large-v3), PER↓ | |
| 说话人相似度 | SPK-SIM↑ (WavLM-based) | |
| 下游生成 | 零样本TTS | WER, PER, UTMOS, SPK-SIM |
| 下游理解 | 音素级ASR | PER↓ |
| 情感分类(ESD) | ACC, F1 | |
| 非语音检测(VocalSound) | ACC, F1 | |
| 码本分析 | token分布 | 齐普夫分布拟合(1-6 gram) |
| 潜在空间聚类 | t-SNE可视化(ESC-50) |
3.3 主要结果
3.3.1 重建质量
在相似比特率(~850-1000 bps)和帧率(50 token/s)下,MagiCodec全面领先:

- MagiCodec 在相似比特率下实现了所有神经编解码器中最低的词错误率(WER 3.155)和音素错误率(PER 1.634)。这归功于其带噪声注入的码本优化。
- PESQ 2.56、STOI 0.93为神经编解码器中的最佳,接近传统高质量编码器上限。
- UTMOS分数说明其生成语音十分自然。SPK-sim说明音色相近。
3.3.2 下游生成:零样本TTS
使用GPT-2 backbone在LibriSpeech上训练TTS模型,用不同编解码器的token作为中间表示:

- MagiCodec在更低比特率下取得最低WER/PER和最高自然度UTMOS,证明token更易被语言模型建模。
- 说话人相似度略低于BigCodec,但此时BigCodec非流式且比特率高20%。
3.3.3 下游理解:音素识别与情感/非语音检测


- 音素识别:MagiCodec PER=7.7%,优于BigCodec (8.0%) 和 WavTokenizer (13.1%),说明保留了更细粒度的发音信息。
- 情感分类(ESD):MagiCodec ACC/F1=0.70,远超DAC(0.54)、BigCodec(0.59)、WavTokenizer(0.62)。
- 非语音检测(VocalSound):MagiCodec ACC/F1=0.63,同样最优。
这表明MagiCodec的token编码了丰富的副语言信息(情感、非语音发声),而不仅仅是语音内容。
3.4 消融与机制分析
表6、表7:考察掩码比例(0%/10%/20%/30%)和帧率(25/50/100 Hz)的影响。


- 掩码比例:从0%增至20%,WER从3.34降至3.16,PER从1.77降至1.63,下游TTS的WER从5.51降至3.37,情感分类ACC从0.68升至0.70。30%时性能饱和或轻微下降。结论:适度噪声注入(20%掩码)强制模型利用长程上下文,改善鲁棒性和语义紧凑性。
- 帧率:25 Hz对应425bps;100 Hz对应1700bps,下游任务提升有限且序列长度翻倍,增加生成模型负担,Emotion表现有限。50 Hz为最佳平衡点。
图2:t-SNE潜在空间可视化(ESC-50数据集)
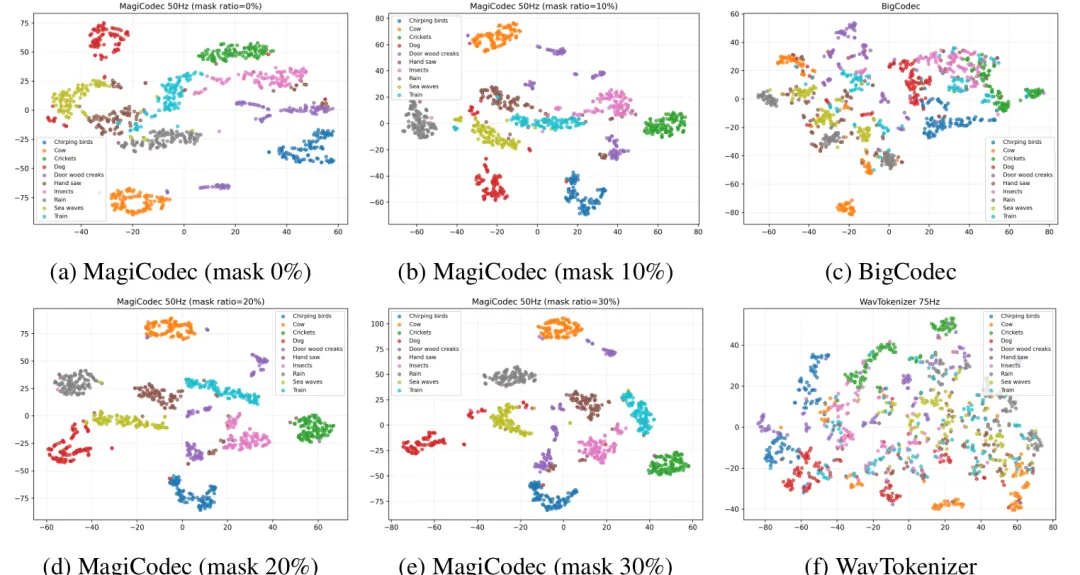
- MagiCodec的类内聚集最紧密,类间分离清晰;BigCodec和WavTokenizer存在大量重叠。
- 随着掩码比例增加,聚类更紧凑,表明高频正则化促使学习抽象语义。

- 自然语言单词token中少数高频token占主导,而许多低频token稀疏分布,反映了丰富的语义层次。
-
- 单词令牌在所有 n-gram 上呈现清晰的幂律衰减,与自然语言一致。
- 音素令牌具有更平坦的分布,尤其是 1-gram 和 2-gram,表明语义层次较弱。
- 现有音频令牌介于音素和单词令牌之间;随着 n 的增加,它们的分布接近单词,但语义丰富度仍然较低。
- MagiCodec 的分布在所有 n-gram 上都与单词令牌紧密匹配,特别是对于 n≥3,表明其表示中具有很强的语义结构和上下文依赖性。
总结
本文提出 MagiCodec,一个单层流式Transformer音频编解码器,核心贡献如下:
- 频域正则化视角的高斯噪声注入:理论证明其等价于低通滤波,衰减高频分量,强制模型学习低频语义结构,无需外部监督即可提升token的可建模性。
- 三阶段渐进训练框架:自编码器预训练 → 量化器冻结编码器训练 → 声码器GAN微调,彻底避免码本坍塌,支持超大码本(13万)的单层量化。
- 卓越的综合性能:在850 bps下,重建质量(PESQ 2.56, STOI 0.93)和下游任务(TTS WER 3.30%,情感分类ACC 0.70)均超越现有SOTA,且token分布符合齐普夫定律,潜在空间聚类清晰。
- 轻量流式设计:单层Transformer,支持实时推理,参数适中(209.7M),比多层级RVQ方法更适配音频语言模型。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。