
华为东京研究所 – Digital Human Lab 与东京大学等合作进行了研究,提出了目前为止最大规模的数字人多模态数据集:BEAT。
随着元宇宙的火爆以及数字人建模技术的商业化,AI 数字人驱动算法,作为数字人动画技术链的下一关键环节,获得了学界和工业界越来越广泛的兴趣和关注。其中谈话动作生成 (由声音等控制信号生成肢体和手部动作)由于可以降低 VR Chat, 虚拟直播,游戏 NPC 等场景下的驱动成本,在近两年成为研究热点。然而,由于缺乏开源数据,现有的模型往往在由姿态检测算法提供的伪标签数据集或者单个说话人的小规模动捕数据集上进行测试。由于数据量,数据标注的缺乏和数据质量的限制,现有的算法很难生成个性化,高手部质量,情感相关,动作 – 语义相关的动作。
针对上述问题,华为东京研究所 – Digital Human Lab 与东京大学等合作进行了研究,提出了目前为止最大规模的数字人多模态数据集:BEAT (Body-Expression-Audio-Text),由 76 小时动捕设备采集的谈话数据和语义 – 情感标注组成。原始数据包含肢体和手部动捕数据,AR Kit 标准 52 维面部 blendshape 权重,音频与文本,标注数据包含 8 类情感分类标签,以及动作类型分类和语义相关度打分。在 BEAT 的基础上提出的新基线模型 CaMN (Cascade-Motion-Network) 采取级联神经网络结构,由 BEAT 中其余三种模态和标注作为输入,在动作生成任务上显著优于现有 SoTA (state-of-the-art) 算法。论文《BEAT: A Large-Scale Semantic and Emotional Multi-Modal Dataset for Conversational Gestures Synthesis》已于 ECCV2022 上发表,数据集已经开源。


- 作者: Haiyang Liu, Zihao Zhu, Naoya Iwamoto, Yichen Peng, Zhengqing Li, You Zhou, Elif Bozkurt, Bo Zheng.
- 单位:Digital Human Lab – 华为东京研究所,东京大学,庆应大学,北陆先端科技大学.
- 论文地址:https://www.ecva.net/papers/eccv_2022/papers_ECCV/papers/136670605.pdf
- 项目主页:https://pantomatrix.github.io/BEAT/
- 数据集主页:https://pantomatrix.github.io/BEAT-Dataset/
- 视频结果:https://www.youtube.com/watch?v=F6nXVTUY0KQ
部分渲染后的数据如下(从上到下依次为,生气 – 恐惧 – 惊讶 – 伤心情感下人的动作):


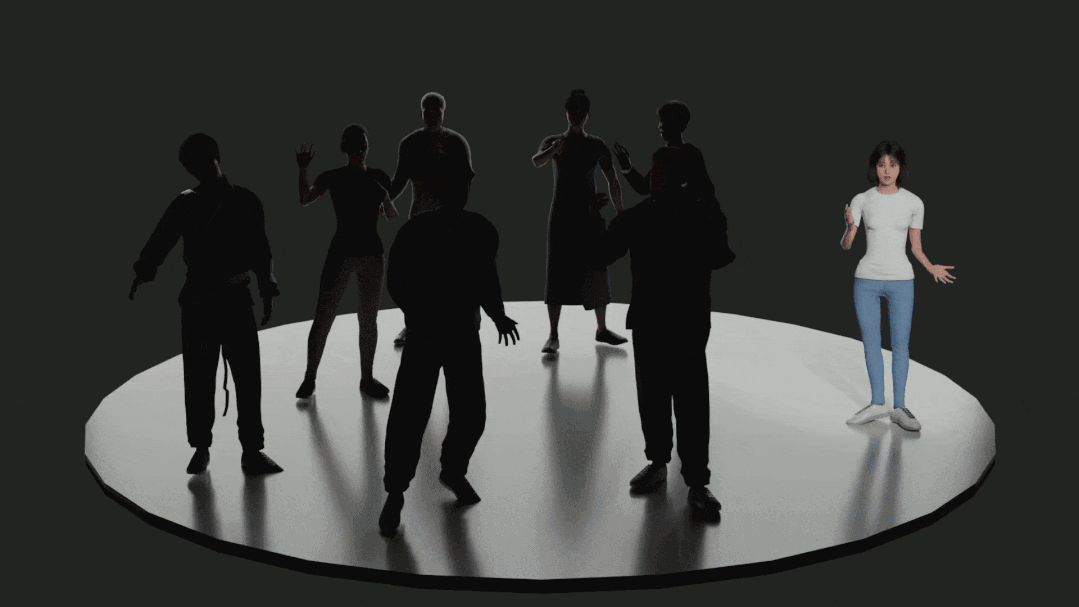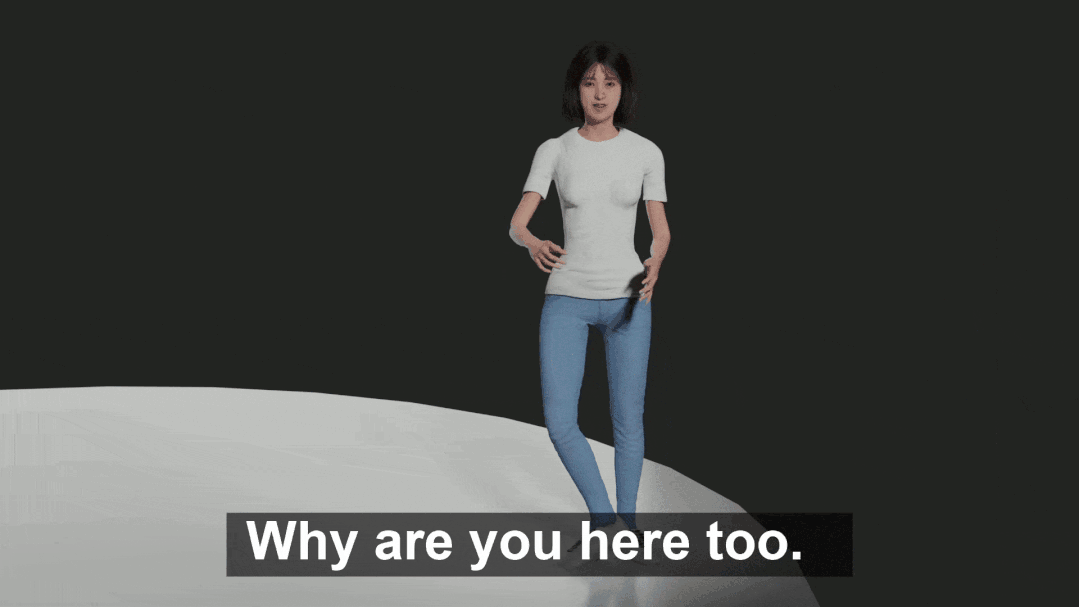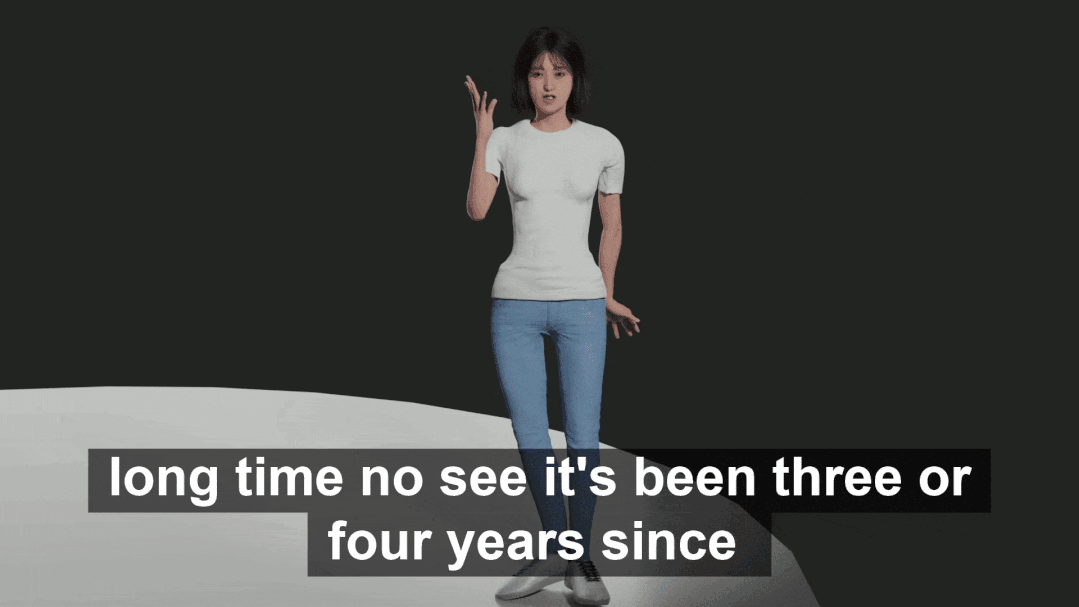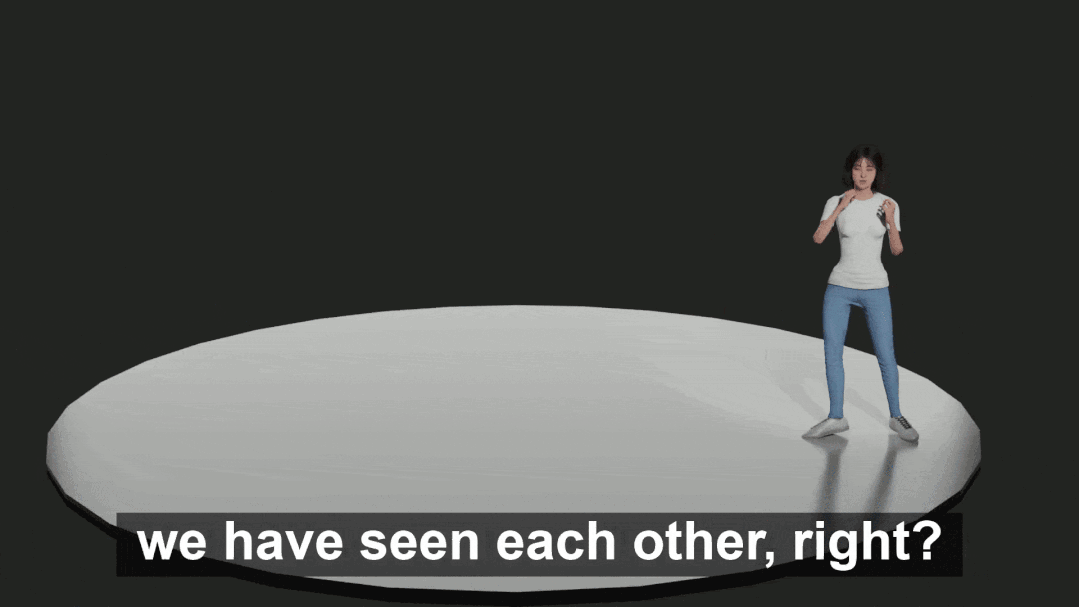

渲染结果使用了 HumanGeneratorV3 产生的身体和脸部模型。
BEAT 数据集细节
动作 – 文本语义相关度标注
谈话动作生成领域的关键问题是:如何生成和评估生成的动作和文本在语义上的关联程度。该关联程度很大程度上影响了人对生成动作质量的主观评价。由于缺乏标注,现有的研究往往挑选一系列主观结果用于评估,增加了不确定性。在 BEAT 数据集中,对于动作给出了基于动作类别分类的相关度分数,共分为四类 10 档:beat(1),deictic (2-4), icnoic(5-7),metaphoic(8-10)。该分类参考 McNeill 等人在 1992 年对谈话动作的分类,其中后三类各自存在低 – 中 – 高质量三档。
然而,实际谈话中,与当前文本语义对应的动作可能提前或滞后出现,为了解决这个问题,在标注过程中,标注者判断当前动作所属类别之后:
1. 以动作的开始和结束确定标注范围,保证了动作的完整性。
2. 输入与当前动作最相关的关键字,获取动作和对应文本的准确出现时间。
基于情感的对话
BEAT 数据集要求每个演讲者必须录制 8 种不同情绪下的谈话动作,用于分析动作与情感之间的内在联系。在演讲环节中,自然情绪占比 51%,愤怒、快乐、恐惧、厌恶、悲伤、蔑视和惊讶这七类情绪分别占比 7%。对动作进行聚类的结果证明,动作和情感之间存在相关性,如下图所示。

数据规模及采集细节
BEAT 采用了 ViCon,16 个摄像头的动作捕捉系统来记录演讲和对话数据,最终所有数据以 120FPS, 记载关节点旋转角的表示形式的 bvh 文件发布。对于面部数据,BEAT 采用 Iphone12Pro 录制谈话人的 52 维面部 blendsshape 权重,并不包括每个人的头部模型,推荐使用 Iphone 的中性脸做可视化。BEAT 采用 16KHZ 音频数据,并通过语音识别算法生成文本伪标签,并依此生成具有时间标注的 TextGrid 数据。
BEAT 包含四种语言的数据:英语,中文,西班牙语,日语,数据量分别为 60,12,2,2 小时。由来自 10 个国家的 30 名演讲者进行录制。其中中文,西班牙语,日语的演讲者也同时录制了英语数据,用于分析不同语言下的动作差异。
在演讲部分(数据集的 50%),30 个演讲者被要求读相同的大量文本,每段文本长度约 1 分钟,总计 120 段文本。目的是控制文本内容相同来研究不同演讲者之间的风格差异,来实现个性化的动作生成。谈话部分(50%)演讲者将和导演在给定话题下进行 10 分钟左右的讨论,但为了去除噪声,只有演讲者的数据被记录。
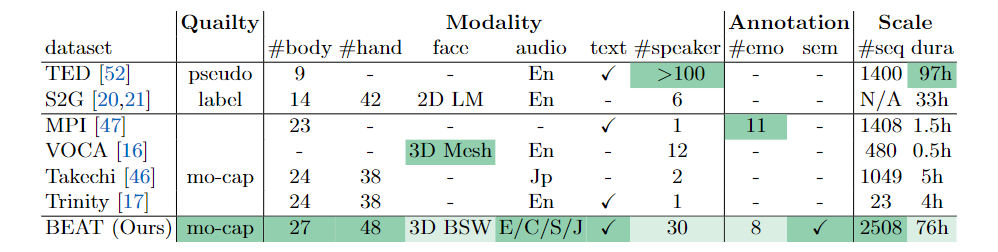
下表还将 BEAT 与现有的数据集进行了比较,绿色高光表示最佳值,可以看出,BEAT 是现阶段包含多模态数据和标注的最大的运动捕捉数据集。
多模态驱动的动作生成基线模型
BEAT 提出了一个多模态驱动的动作生成基线模型,CaMN(Cascade Montion Network),将音频 – 文本 – 面部数据以及情感,语义标注作为输入,以生成更高质量的谈话动作。网络主干由多个级联编码器和两个级联 LSTM+MLP 解码器组成,生成躯体和手部动作,数据被降频到 15FPS,单词句子被插入填充标记以对应音频的沉默时间。具体的网络结构如下图所示。
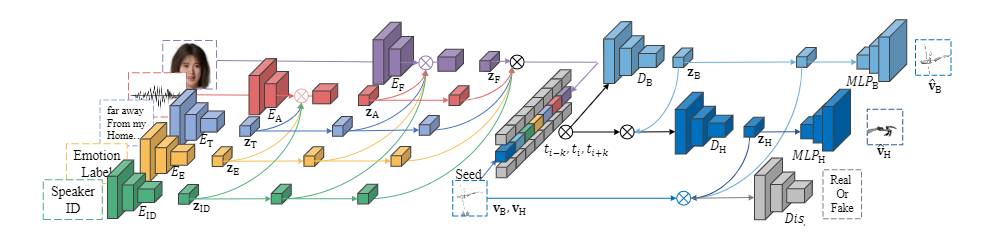
文本、语音和 Speaker-ID 编码器的网络选择是基于现有研究,并针对 BEAT 数据集在结构上进行了修改。对于面部 blendshape weight 数据,采用了基于残差网络的一维 TCN 结构。最终网络的损失函数来自语义标注权重和动作重建损失的组合:
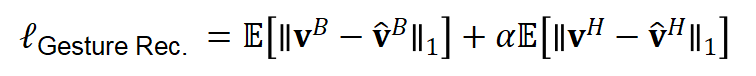
其中针对不同演讲者的数据,网络也采取了不同的对抗损失来辅助提升生成动作的多样性。

实验结果
研究者首先验证了一个新的评价指标 SRGR,然后基于主观实验验证了 BEAT 的数据质量,并将提出的模型与现有的方法进行了比较。
SRGR 的有效性
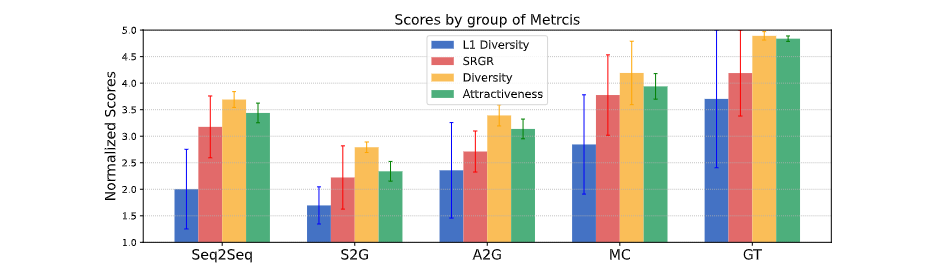
为了验证 SRGR 的有效性,研究者将动作序列被随机切割成 40 秒左右的片段,要求参与者根据动作的正确性,多样性和吸引力对每个片段进行评分。最终共有 160 人参与评分,平均每个人对 15 个随机的手势片段打分。图表显示,与 L1 多样性相比,SRGR 在评估手势多样性方面与人类感官更为相似。
数据质量
为了评估 BEAT 这一新型数据集的质量,研究者使用了现有研究中广泛使用的动捕数据集 Trinity 作为对比目标。每个数据集被分成 19:2:2 的比例,分别作为训练 / 验证 / 测试数据,并使用现有方法 S2G 和 audio2gestures 进行比较。评估主要针对不同数据集训练结果的正确性(身体动作的准确性)、手部正确性(手部动作的准确性)、多样性(动作的多样性)和同步性(动作和语音的同步性)。结果见下表。


表中显示,BEAT 在各方面的主管评分都很高,表明这个数据集远远优于 Trinity。同时在数据质量上也超过了现有的视频数据集 S2G-3D。
对 Baseline 模型的评价
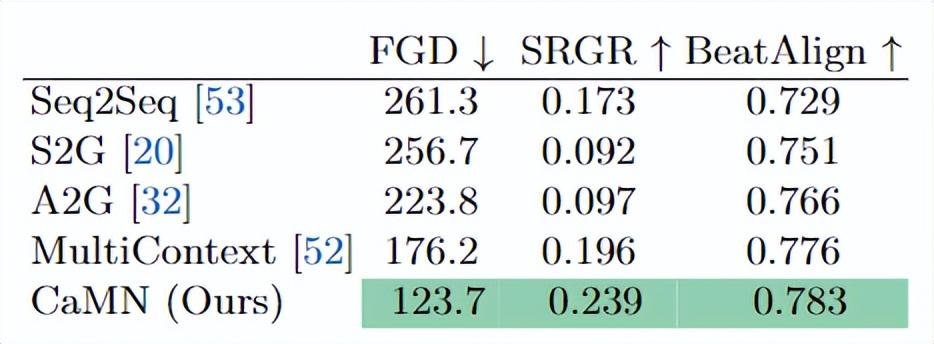
为了验证本文提出的模型 CaMN 的性能,在以下条件下与现有方法 Seq2Seq,S2G,A2G 和 MultiContext 进行了比较验证。一些实验的细节如下:
- 使用数据集中四名演讲者的数据进行 15 小时的训练,选取不同模型在验证集上最优的权重在测试集上测试。
- FGD 被采用为评价指标,因为已被证明 L1 损失不适合于评价生成动作的性能。
- 为了评估手势的多样性和与语音的同步性,研究者采用了本文提出的 SRGR 和舞蹈动作生成中常用的指数 BeatAlign。
验证结果如下表所示,CaMN 在所有评价指标上得分最高。
下面是一个由 CaMN 生成的手势的例子。
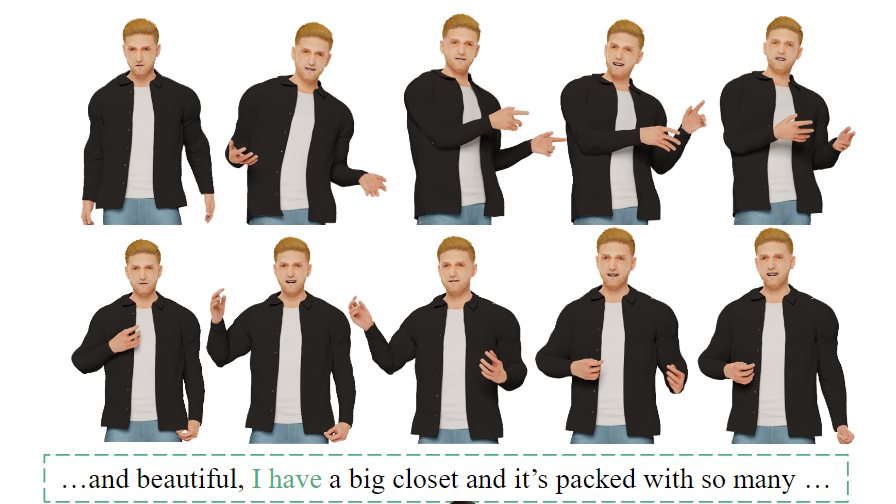
图中展示了一个真实数据样本(上)和一个 CaMN 生成的动作(下),生成的动作具备语义相关性。
总结
本文研究者提出大规模的多模态数字人驱动数据集 BEAT,用于生成更生动的谈话动作。该数据集还可应用于数字人驱动的其他领域,如 LipSync,表情识别,语音风格转换等等。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。