
在前面的技术短文(IM专题:分层架构IM系统(1)— 架构解读)中,我们已经非常明确入口层 Entry 的核心职责,即面向客户端提供 TCP 长连接的接入能力,并维护这些长连接。
Entry 怎么维护与客户端之间的长连接呢?常用的方式就是【心跳】,即客户端周期性地向服务端发送心跳包,告诉服务端,我客户端还活着。(在客户端数量非常少的情况下,服务端也可以向客户端周期性地发心跳)
大家有没有思考过心跳背后的原理是什么?为什么要用心跳呢?难道不发心跳,客户端与服务端之间的长连接就容易断掉吗? 我在大学期间,和寝室舍友做过一个实验,见下图。


用网线直连两台电脑(Windows系统),写一个简单的 TCP Demo 程序,电脑 A 作为客户端向电脑 B 发起并建立 TCP 连接;连接建立后,什么都不做,包括 TCP 层的心跳周期也设置到月级别。大家猜测一下,一周以后,电脑 A 和电脑 B 之间的长连接还存在吗?
一周以后,电脑 A 上的 TCP Demo 程序开始发送数据,电脑 B 上的 TCP Demo 程序全部成功接收。实验结论:在上述场景中,无论过去多长时间,在没有任何心跳包的情况下,TCP 长连接会一直健康存在。通过这个小实验,也对 TCP 连接有了更本质的理解:所谓建立了 TCP 连接,实质上是客户端和服务端之间,相互为对方敞开了一个端口,只要是我这个端口发送给你的端口的数据,你一定会接受,反之亦然;只要客户端和服务端的进程一直存在,那么连接就会一直存在。
如此,在分层架构的 IM 系统中,Entry 为什么还需要心跳来维护与客户端的长连接呢?
因为 IM 系统是部署在了互联网中,而非简单的两台电脑直连的场景。在互联网中,TCP 长连接是非常不稳定的,根本的原因在于网络运营商的网络传输中间设备(比如大型的路由器);这些设备会在内存中记录一个四元组(src_ip, src_port, dest_ip, dest_port),该四元组描述了从源端口到目标端口的一条 TCP 连接;为了节省设备内存资源,每一条四元组记录会设置一个有效期,有效期内的 TCP 数据包可以正常通过,并延长有效期;有效期内若无数据包通过,则该四元组记录会被删除,此时客户端与服务端之间的长连接就被切断了。
现在对【心跳】做一下总结:一是保活连接,告诉中间的网络设备,不能切断它; 二是检测连接活性,对于已经断开的连接或客户端进程已经被杀掉的情况,服务端需要及时释放资源。
明白了心跳背后的原理,那么有哪些常用的心跳算法呢?
一、遍历扫描算法
遍历扫描是最常见也是最简单的一种心跳算法,见下图。
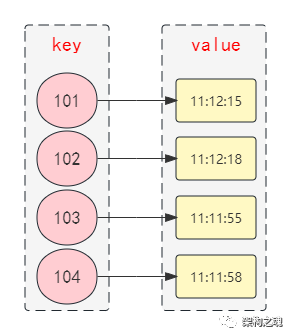
遍历扫描算法的核心是一个 Map<uid, time> 结构,该映射的 key 是客户端的 uid, 该映射的 value 是客户端最近的一次心跳时间。
客户端每次发送心跳包到 Entry 时,Entry 获取当前时间,然后写入到该Map结构中,这个过程的时间复杂度是 O(1)。Entry 单独起一个独立的扫描线程,周期性的对该 Map 进行遍历扫描,每获取一个元素,判断 value 中的心跳时间,如果与当前时间的差超过了一个限度(通常是 2 倍的心跳周期时间),那么 key 中的 uid 所代表的客户端则视为心跳超时,Entry 直接将其连接切断即可;这个扫描过程的时间复杂度是 O(n)。
遍历扫描算法适合客户端数量较少的场景,比如同时在线人数在几千级别。
二、链表扫描算法
在上面的遍历扫描算法中,时间复杂度是 O(n),随着在线客户端数量的增多,每一次遍历扫描的耗时会增加;在很多 IM 系统中,随着 5G 的普及,网络质量的提升,客户端在线状态会持续良好,每一次扫描可能只会扫出不到 1% 连接失活的客户端。
链表扫描算法是对上面遍历扫描算法的优化,见下图。
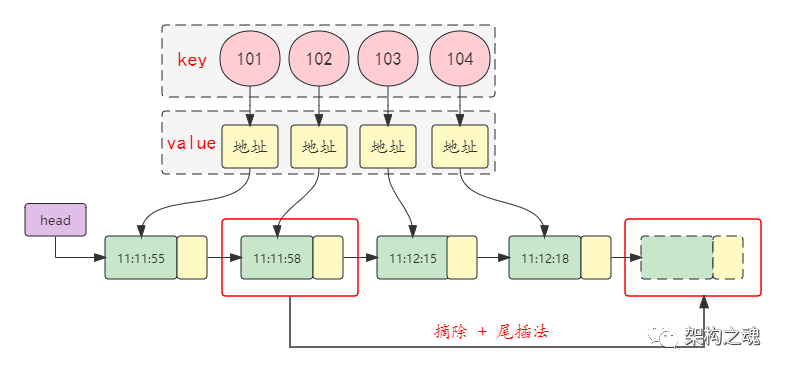
链表扫描算法的核心是两个数据结构,一个是 Map<uid, 地址>,一个是链表。Map映射结构的 key 是客户端的 uid, value 是单链表中每一个元素节点的地址;链表中,每一个元素节点由数据区和地址区组成,数据区中存储客户端最近一次的心跳时间,地址区存储下一个节点的地址。
当客户端发送心跳到 Entry 时,首先通过 Map 快速定位到链表中节点,获取当前时间,写入到链表元素的数据区,这个过程的时间复杂度是 O(1);同时,对于刚发送心跳的链表元素节点,将其从链表中摘除,然后通过尾插法写入到链表的尾部;运行一段时间后,很明显,这条链表中的所有元素会按心跳时间从前到后升序排列。
同样的,Entry 会单独起一个独立的扫描线程,周期性对单链表进行扫描;链表扫描算法的优势,这个时候就体现出来了:扫描线程从前到后扫描链表,心跳超时的节点会集中在链表的前面,当扫描到第一个没有超时的节点时,即可停止;对于每次扫描只有不到 1% 心跳超时的场景,其时间复杂度是 O(n/100)。
三、动态分组算法
在上述的遍历扫描算法和链表扫描算法中,Entry 启动的独立的扫描线程在扫描时,需要给数据结构加一把大锁,这在一定程度上降低了整个心跳算法的性能;动态分组算法除了能集中扫描出心跳超时的客户端以外,能通过加小锁的方式避免扫描线程与客户端发心跳时的冲突。 动态分组算法见下图。
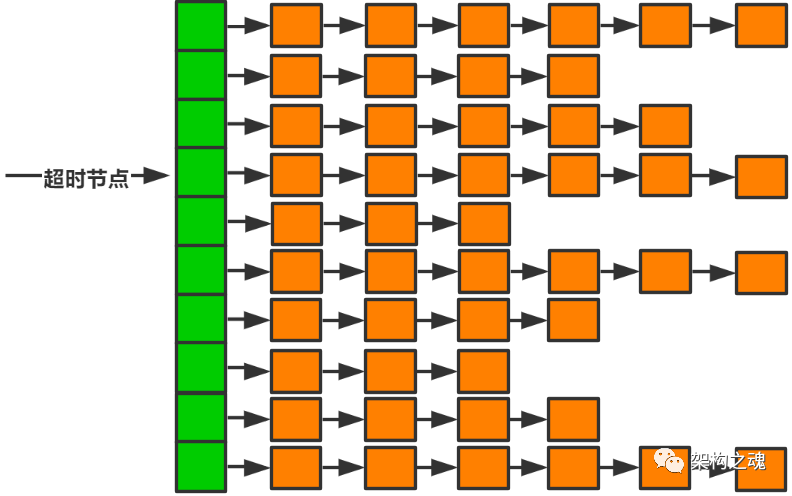
图中绿色的部分是一个数组,数组的每个元素我们可以形象地称为 “桶”;每个桶指向一个链表,链表的每个元素表示发送心跳包的客户端。我们举例描述心跳算法的流程:
假定心跳超时时间是 40 秒,即客户端在 40 秒内没有发送心跳包到 Entry 时,Entry 可以判断该客户端心跳超时,中断其连接。
- 客户端 101 在 11:15:18 时发送心跳包到 Entry,我们在这个时间的基础上加上 40 秒的心跳超时时间,也就是客户端 101 的 expire_time 是 11:15:58,我们把 101 客户端的链表节点放入到计算公式是 expire_time % bucket_size 的桶中,然后将 expire_time 这个参数放入到心跳回复包中,带给客户端;
- 客户端 101 在 11:15:38 时又发送心跳包到 Entry,此时 Entry 需要做两件事:首先找到客户端 101 在哪个桶里,怎么找呢? 通过客户端携带上次返回的参数即可,即 old_expire_time % bucket_size,找到该节点,从桶中移除; 第二件事,计算新的超时时间,new_expire_time = 11:16:18, 通过 new_expire_time % bucket_size 将客户端 101 再放入新的桶中。
简单总结就是:所有的客户端每一次发心跳包时,Entry 都要先从老的桶中移除该节点数据,然后再放入到新的桶中。可以想象这样一幅画面:假设数组的长度是无限长,所有客户端都在争先恐后的向前赶,只要是在正常发心跳的,都处于前进中。没有正常发心跳的客户端,会怎么样呢?这个时候就只能被扫荡部队消灭了!
这里的扫荡部队就是独立的扫描线程,扫描线程获取当前时间,即 curr_time,然后从 curr_time % bucket_size 所计算的桶开始扫描,每秒钟扫描一个桶,若该桶非空,则该桶中所有的节点就都是心跳超时的客户端列表。
描述到这里,大家可能会感觉很巧妙,也可能会感觉有些许疑惑。
我们从另一个视角描述一下: 扫描线程扫描的桶是根据当前时间 curr_time 所计算的桶,即 curr_time % bucket_size; 客户端心跳时所入住的桶是 (curr_time + 40秒) % buceke_size 所计算的桶。正常心跳的客户端所在的桶,会超出扫描线程所扫描的桶40个距离,只有不按时发心跳的客户端会被扫描到。另外,需要注意,桶数组的长度需要大于心跳超时时间所描述的桶距离。
动态分组算法,在加锁时只需要对每一个桶加锁即可,加锁的粒度大大缩小了,性能自然提升了!
最后,总结文中关键:
1、TCP 连接的本质是客户端和服务端互相为对方敞开了一个可以收发数据的端口;
2、心跳背后的原理有二:一是保活连接,防止被网络中间设备切断;二是检测连接,发现连接失活或客户端失活时,及时释放服务器资源;
3、遍历扫描算法,客户端发送心跳时间复杂度是O(1),服务端线程扫描时间复杂度是O(n);
4、链表扫描算法,客户端发送心跳时间复杂度是O(1),服务端线程扫描时间复杂度是O(n/100);
5、遍历扫描算法和链表扫描算法,在服务端线程扫描时需要加大锁,动态分组算法除了能集中扫描出心跳超时的客户端以外,能通过加小锁的方式避免扫描线程与客户端发心跳时的冲突。
作者:棕生 | 来源:公众号——架构之魂
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。