
WebRTC信令:一个类似于 “即时聊天 “的用例
作为我们在Lumen的Mesh交付技术的开发工作的一部分,我们需要设计和实现一个有弹性和可扩展的后端架构,能够解决WebRTC信令的问题,作为我们WebRTC工作流程实现的一部分。不要担心,你不需要对WebRTC熟悉或有任何先决条件,就可以阅读和学习这篇文章。以下是你唯一需要知道的两件事:
- WebRTC是一套开放的网络标准,使客户端(特别是网络浏览器)之间以点对点的方式建立直接通信和交换数据成为可能。
- WebRTC信令是WebRTC协议的一个初步步骤,有助于在客户端之间建立直接连接。它依赖于一个信令服务器,其职责是在希望建立WebRTC连接的客户端之间转发协商信息。
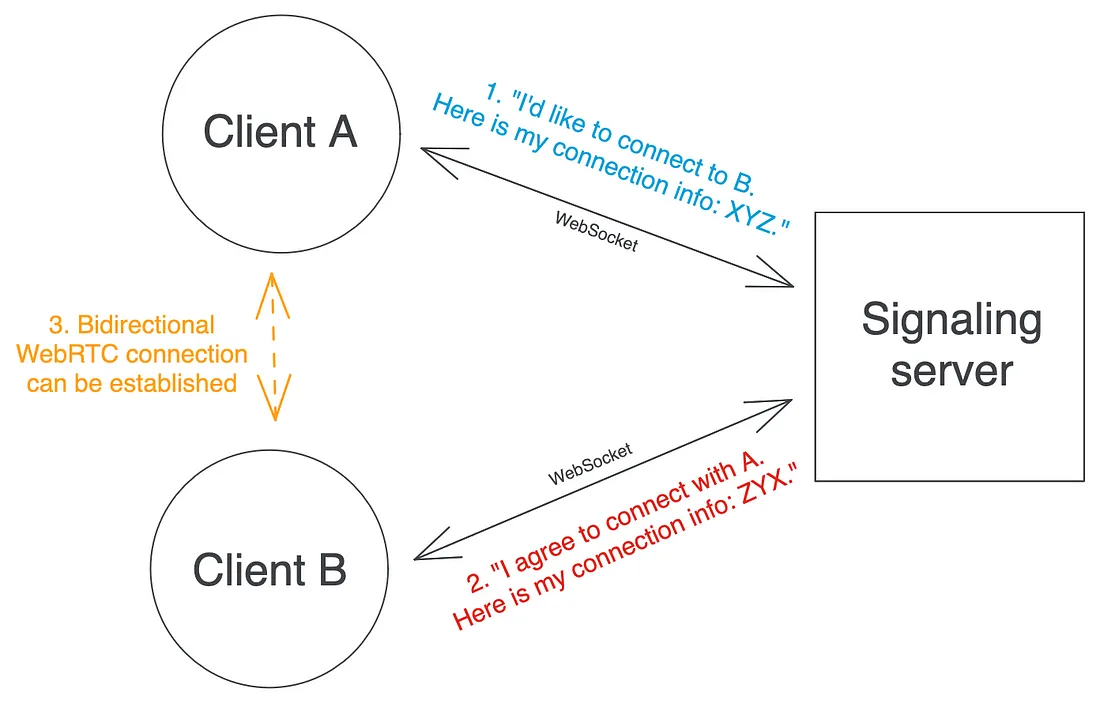

信令服务器不需要知道或理解正在交换的消息的内容(如果你好奇的话,这些消息通常包含SDP格式的连接信息):它只需要知道每个消息的接收者是谁,并将其转发给他们。客户端和信令服务器之间使用的连接类型通常是WebSockets,因为它们的双向性非常适用于这种使用情况。正如你所看到的,这种后端用例在所有方面都与即时聊天服务几乎相同,用户可以向对方发送任意的消息。
为什么WebSocket服务器比普通HTTP服务器更难扩展
单一实例用例:像ABC一样简单
在上面的模式中,只有一个信号服务器实例,这使得任务的推理相对简单明了。你在 “如何创建即时聊天WebSocket服务器 “在线文章中看到的任何基本实现都应该有效。它通常可归结为以下内容:
- 使用选择的语言和 HTTP 库启动一个基本的 WebSocket 服务器,该服务器在给定路由上侦听来自希望注册到信令服务的客户端的请求。通过注册,我们的意思是“打开一个持久的 WebSocket,以后可以用来与其他客户端交换消息”。
- 在内存关联结构(例如哈希图/字典)中保留从每个注册客户端的唯一标识符(我们将在
clientId此处命名)到他们的 WebSocket 的映射。 clientId每当从客户端的 WebSocket收到一条消息(当然,必须指定收件人的)时,在已注册客户端的映射中查找收件人,并通过他们自己的 WebSocket 将消息转发给他们。
一个伪代码的实现可以是这样的:
// Global variable that maps each clientId to its associated Websocket.
clientIdToWebsocketMap = new Map()
function main() {
// Start the server and listen to registration requests.
server = new WebsocketServer()
server.listen("/register", registerHandler)
}
function registerHandler(request) {
// For example, the client can send their clientId as a query parameter.
clientId = request.queryParams.get("clientId")
websocket = request.acceptAndConvertToWebsocket()
websocket.onReceiveMessage = onReceiveMessageHandler
clientIdToWebsocketMap.insert(clientId, websocket)
}
function onReceiveMessageHandler(message) {
// We assume the message parsing logic to extract the recipientId from the message is defined elsewhere.
recipientId, body = parseMessage(message)
clientIdToWebsocketMap.get(recipientId).send(body)
}自动缩放多个实例:自找麻烦
正如我们刚刚看到的具有单个服务器实例的 Websocket 服务器架构没什么大不了的。然而,当您需要处理大量且高度可变的传入流量时,单个实例将不再足够,也不是资源的最佳使用方式:在我们的实际用例中,我们有时会经历负载快速变化的情况几千条消息/秒到几十甚至几十万条消息/秒仅需几分钟。这就是Kubernetes 的POD水平自动伸缩 (HPA)等功能派上用场的地方:Kubernetes 检测传入流量的变化并根据需要添加或删除实例。
当有多个实例时,第一个问题是给定消息的发件人和收件人不一定都在同一实例上注册,在这种情况下,需要找到一种方法将消息从发件人的实例转发到收件人的实例。
另一个问题是缩放本身。水平自动缩放旨在与常规 HTTP 服务很好地配合使用:如果流量增加并且自动缩放器确定应该创建一个新实例,它可以简单地这样做,通知任何负载均衡器(无论是 Kubernetes 服务,入口控制器还是任何外部 HTTP 负载balancer) 位于创建新实例的实例之前,负载均衡器将开始在所有实例(包括新实例)之间平均分配新传入的 HTTP 请求。
但问题是:Websockets 是持久连接。想象一下,您有 2 个 Websocket 服务器实例服务于每个连接 100 个客户端的流量,并且自动缩放器确定负载足够高以创建第三个实例:它创建该新实例(称为扩展事件),通知负载它的平衡器,并且负载平衡器开始在所有实例之间平均分配新的 Websocket 连接请求。你能看出问题吗?如果 30 个新的 Websocket 连接请求分布在您的 3 个实例中,则较旧的两个将分别有 110 个连接的客户端,而新的只有 10 个!使用 HPA 时,不均匀负载是 Kubernetes 中的一个大禁忌:自动缩放希望各实例的资源使用均衡。
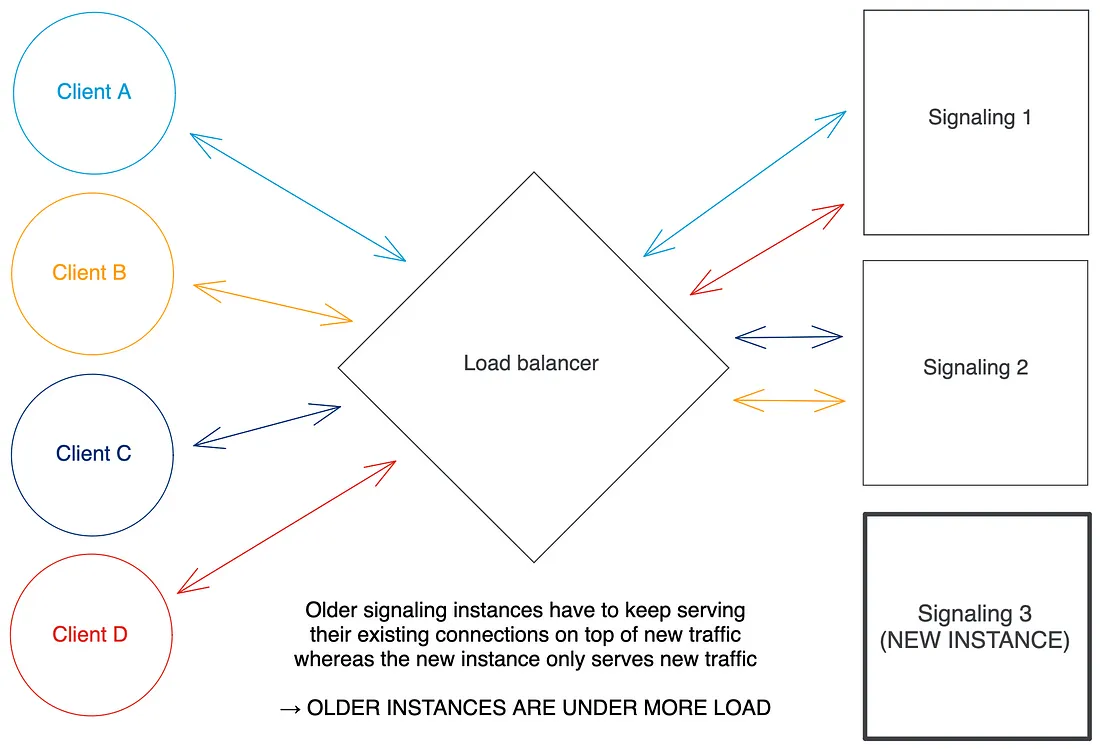
请注意,这个问题并不是什么新鲜事:负载平衡和扩展持久连接是Kubernetes 中众所周知的难题。
可扩展分布式信令服务的要求
在解释可能的解决方案并详细说明我们选择的解决方案之前,让我们回顾一下我们试图解决的问题的限制条件:
- 分布式(这是一个实际的词)约束:系统必须保证客户端发送的消息将被正确转发给它的预期接收者, 即使他们没有注册到与发送者相同的实例。
- 平衡约束:为了使系统能够自动扩展,系统实例之间的负载(即活动连接数)必须保持平衡,包括当实例通过 Kubernetes 的 HPA 从分布式服务中动态添加或删除时。
具有重大局限性的 “典型 “解决方案
使用Pub/Sub代理来解决分布式约束问题
如果你在网上搜索 “如何扩展Websocket服务器”,你会在一些相关文章中,有一个反复出现的解决方案系列,以各种形式出现,需要使用Pub/Sub消息代理来实现实例间的通信,这就解决了分布式约束,也就是上面列出的要求1。
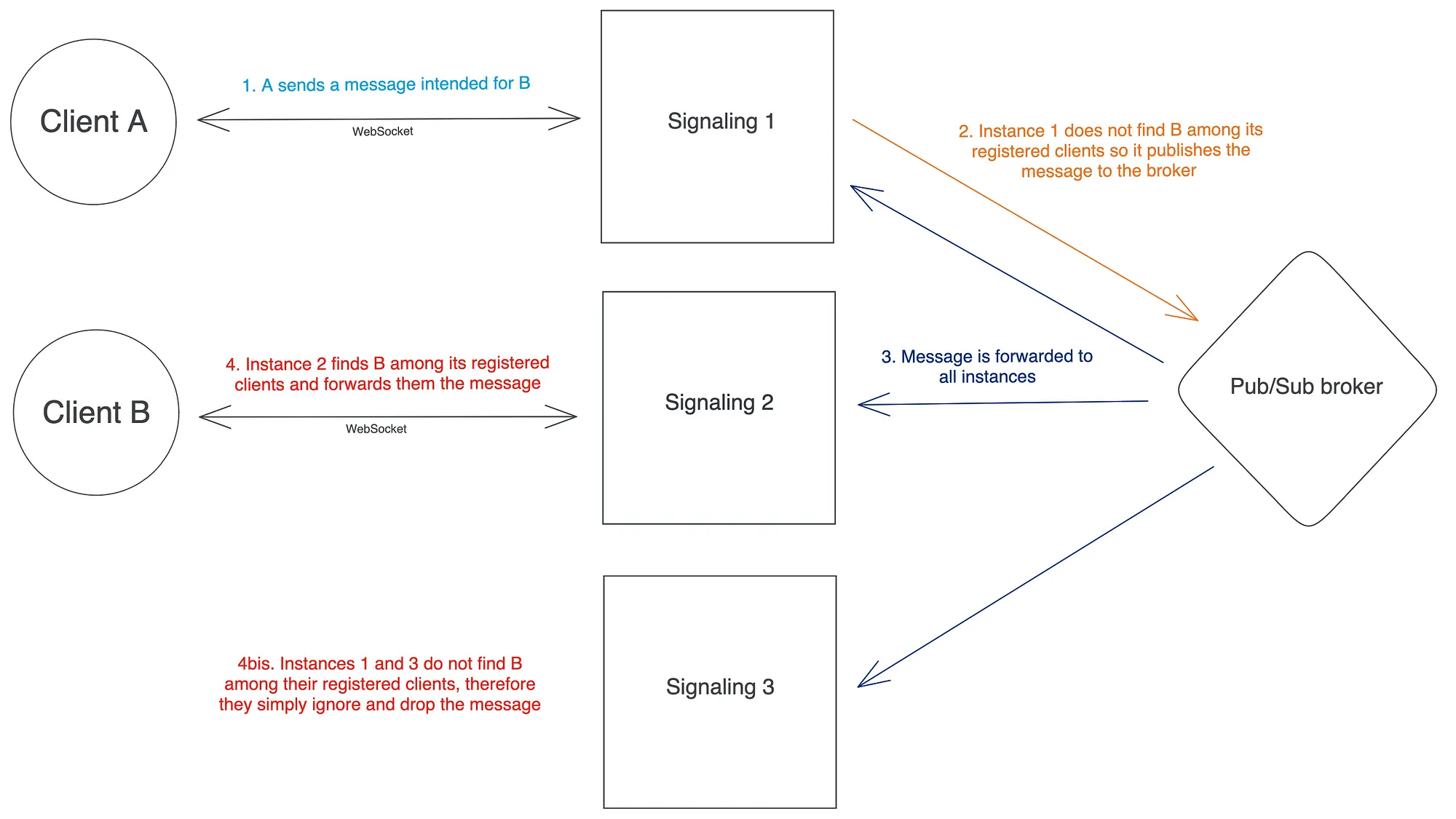
这个提议的解决方案在纸面上看起来很有前途,因为它为分布式约束提供了一个优雅的解耦解决方案。然而,在团队内部进一步讨论之后,当我们试图估算此类解决方案的预期成本时,我们意识到它存在两个关键限制:
- 每个信号实例都订阅了代理,因此读取每个其他实例发布的每条消息。这意味着读取的数量与实例的数量呈二次方关系。这是特别低效的,因为当一个实例从代理读取消息时,接收者注册到该实例的概率平均只有1/N (其中 N 是实例数):大多数从代理人那里读取的消息将被放弃。
- 这可能会非常昂贵。如果你的流量模式足够多变——如果首先需要实施自动缩放,则可能是这种情况,你将需要对 Pub/Sub 代理本身进行自动缩放或使用托管解决方案(如果你是使用 GCP,例如 Google Pub/Sub)。前一种选择是一项非常复杂的任务(甚至可能根本无法完成),而后者很快就会变得非常昂贵:我们意识到我们的信号系统中平均每秒传输几千条消息的流量——这是重要但无论如何都算不上例外——如果我们选择 Google Pub/Sub,最终每个月要花费数十万美元。
解决平衡约束:好的和丑的
现在对于要求 2,平衡约束: Jo Stichbury 的 文章涉及负载平衡方法,并提到了一些可以证明对我们的用例感兴趣的算法。大多数负载均衡器中的默认负载均衡算法是循环法,正如我们在本文前面解释的那样,它非常适合常规 HTTP 用例,但在自动缩放 Websocket 服务器时无法保持负载均衡。诸如最小连接算法之类的替代方案对我们来说更有趣:它们允许将新的 Websocket 连接请求分发到具有最少活动连接的服务器实例,这保证负载最终会在扩展事件之后在实例之间进行平衡。在大多数情况下,最终的平衡就足够了,并且不应妨碍 Kubernetes 的 HPA 正常工作。
这种Balance 约束解决方案的局限性在于,并非所有负载均衡器都支持最少连接负载均衡算法:例如,Nginx 支持它,但GCP 的 HTTP(S) 负载均衡器不支持。在这种情况下,可能需要使用稍微丑陋的技巧,例如利用 Kubernetes 的 readiness probes:你可以让最过载的信号实例暂时出现Unready,以防止负载均衡器向它们发送新的连接请求。这会将所有新流量重定向到其他实例,这应该有助于它们赶上并均衡跨实例的负载。它不是很漂亮,但效果很好(我们是根据这里的经验谈论的)!
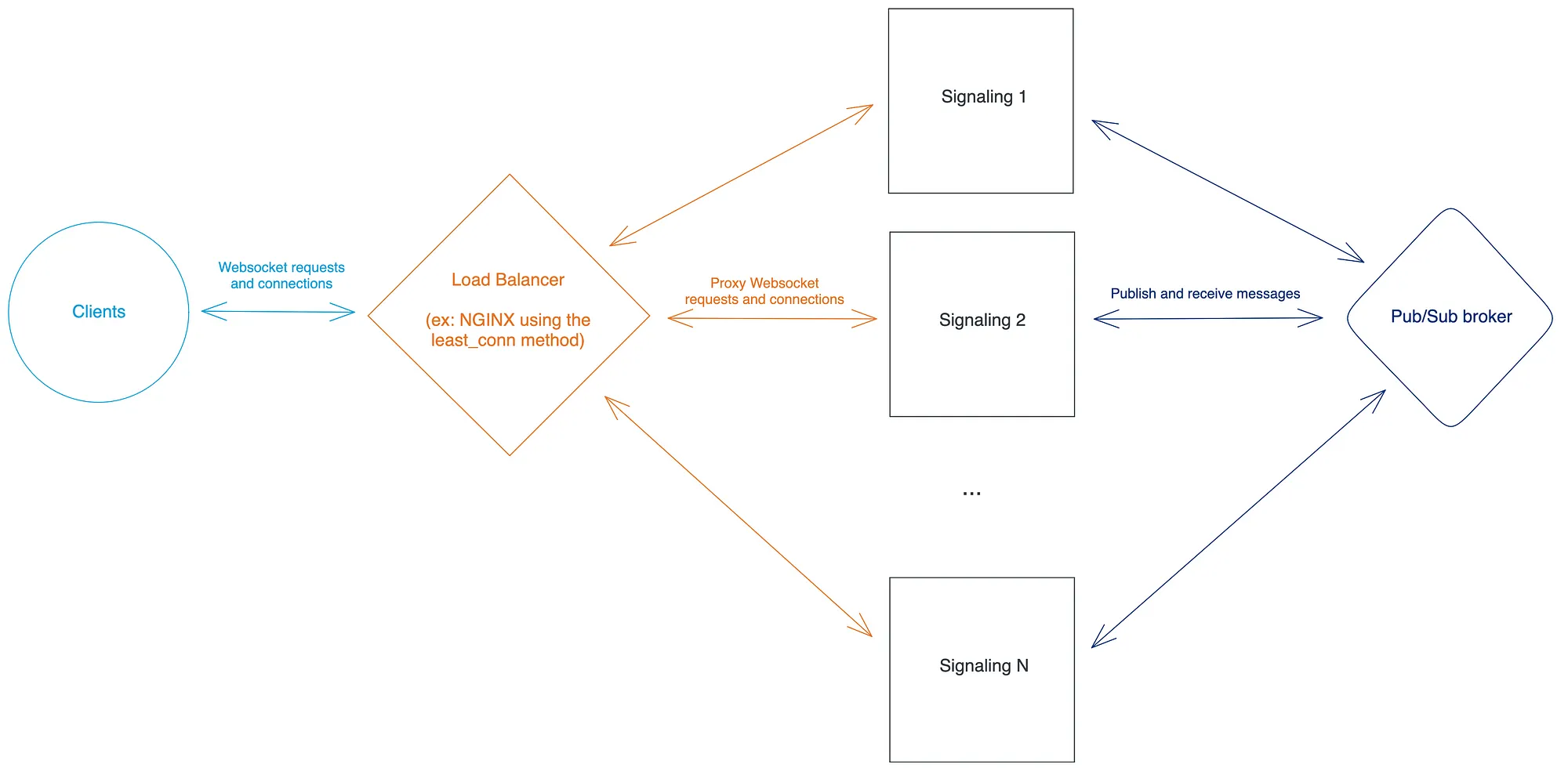
简而言之,一个可扩展的分布式信令系统的可能解决方案是使用一个Pub/Sub代理来实现实例间的通信,并使用最小连接的方法进行负载平衡。然而,这种解决方案只有在你能负担得起使用Pub/Sub代理的潜在高成本和你的负载平衡器支持最小连接算法的情况下才是可行的。由于这些条件对我们来说并不符合,我们决定设计另一种解决方案,现在我们就来介绍一下。
我们的解决方案:利用基于哈希的负载均衡算法的魔力
使用(rendezvous hashing)哈希解决分布式约束问题
基于哈希的负载均衡算法是平衡流量的确定性方法,它从客户的请求中的一个值(可能是一个头值、一个查询或路径参数、客户的IP地址……)计算出一个哈希值,并使用这个哈希值将请求路由到一个给定的后端实例。两个最著名的基于散列的算法是一致散列和交会散列。两者都非常相似,但我们最终选择了交会散列,因为它更简单–无论是理解还是实现–而且它倾向于比 consistent hashing 更均匀地平衡各实例的负载。然而,值得一提的是,大多数流行的负载均衡器,如NGINX只提供一致散列。
你可以把这些算法看作是数学函数,把要散列的值和一组后端实例作为输入,并输出其中一个后端实例。以这些参数的相同值运行该函数,将始终返回相同的输出值,这与大多数其他负载平衡方法(包括轮循和最小连接)相比,是一个显著的区别。
H(val, I) = I_i
- H is the hash-based algorithm
- val is the value (extracted from the request) from which the hash is computed
- I = {I_1, I_2, ..., I_N} is the set of all backend instances
- I_i is the backend instance that was "selected" by the algorithm你能看到我们要去哪里吗?如果我们使用客户端clientId作为参数val,我们现在有一个负载平衡算法,它明确地将每个客户端与一个特定的信令实例相关联;最重要的是,任何知道他们clientId和后端实例集的人都可以随时自己运行该函数以了解该客户端在哪个实例上。这意味着,如果一个信令实例收到一条发给给定收件人的消息,但在本地找不到它,它可以运行基于哈希的算法,并立即知道收件人应该在哪个其他实例上注册!
现在让我们看看如何将所有内容放在一起:
- 我们指示我们的负载均衡器使用集合点哈希作为其负载均衡方法,使用
clientId在每个新的 Websocket 连接请求的查询参数中传递的 作为要哈希的值。 - 我们需要让每个信令实例都知道系统中的其他实例:这在 Kubernetes 中很容易完成,方法是声明一个与我们的信令部署相关联的Headless Service,然后在信令服务器的代码中调用Kubernetes Endpoints API来检索信令集实例及其 IP 地址。
- 当信令实例 I₁ 从其注册客户端之一接收到 Websocket 消息时,它会读取预期的接收者
clientId并在本地查找它们。如果在本地找到它们,实例会通过它们的 Websocket 将消息转发给它们。如果没有找到,该实例运行集合点散列算法,使用作为clientId参数val和一组信令实例 IP 作为参数I,并确定接收者应该在哪个实例 I2 上注册。如果 I₂ = I₁,这可能意味着收件人已经断开连接或者根本就没有注册过;否则 I₁ 将消息转发给 I₂。 - I₁ 可以通过多种方式将消息转发给 I₂:我们选择在专为实例间通信专门创建的路由上使用常规 HTTP 请求。我们选择批量发送这些实例间消息,以避免发送过多的单个 HTTP 请求(这会导致大量性能开销)。
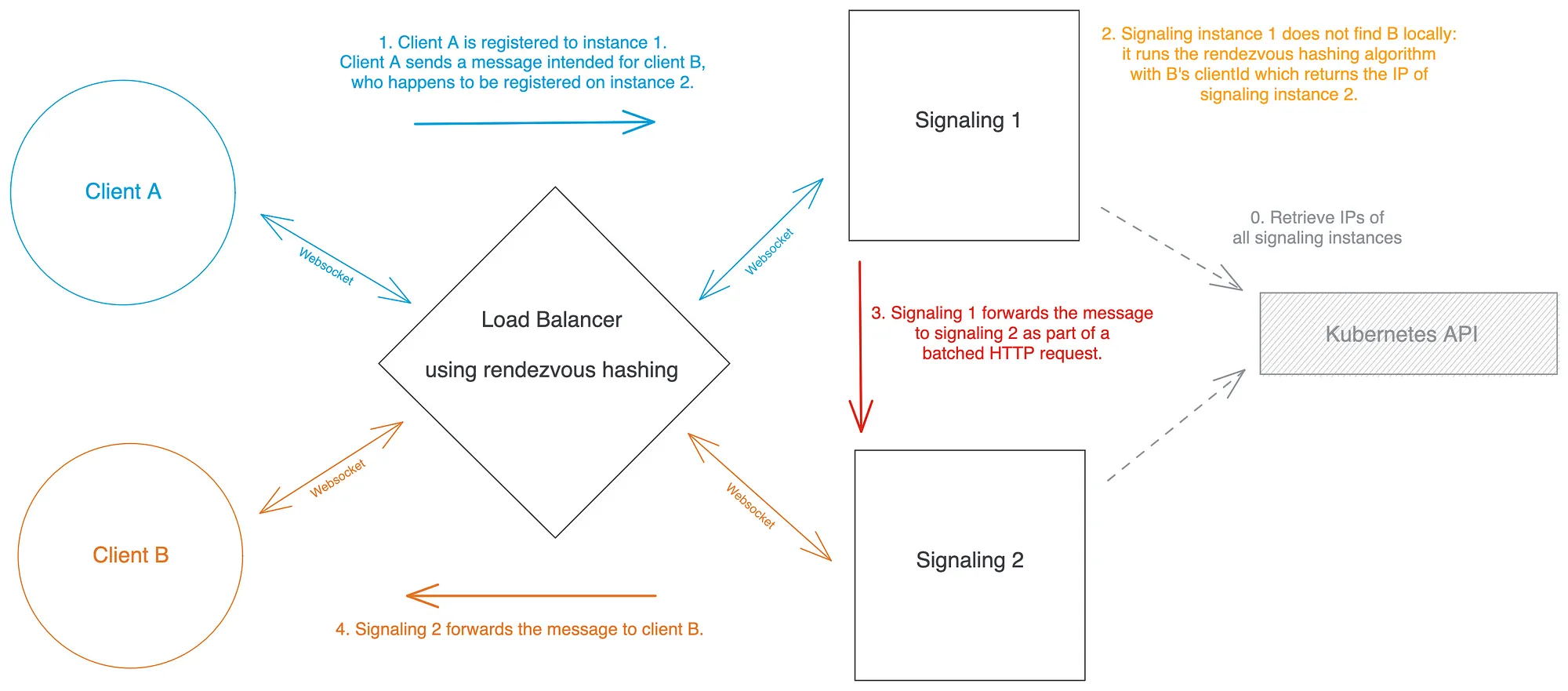
解决平衡约束
使用基于(hash-based)散列的负载平衡算法为分布式约束提供了一个优雅的解决方案,但你可能想知道它如何与自动缩放一起使用,自动缩放会在系统运行时在信号实例集中引入更改(实例的创建或删除)。我们显然必须做的一件初步事情是确保我们观察或至少定期轮询信令服务器代码中的 Kubernetes 端点 API,以查看何时发生重新缩放:这是我们之前迭代的一个简单增强。
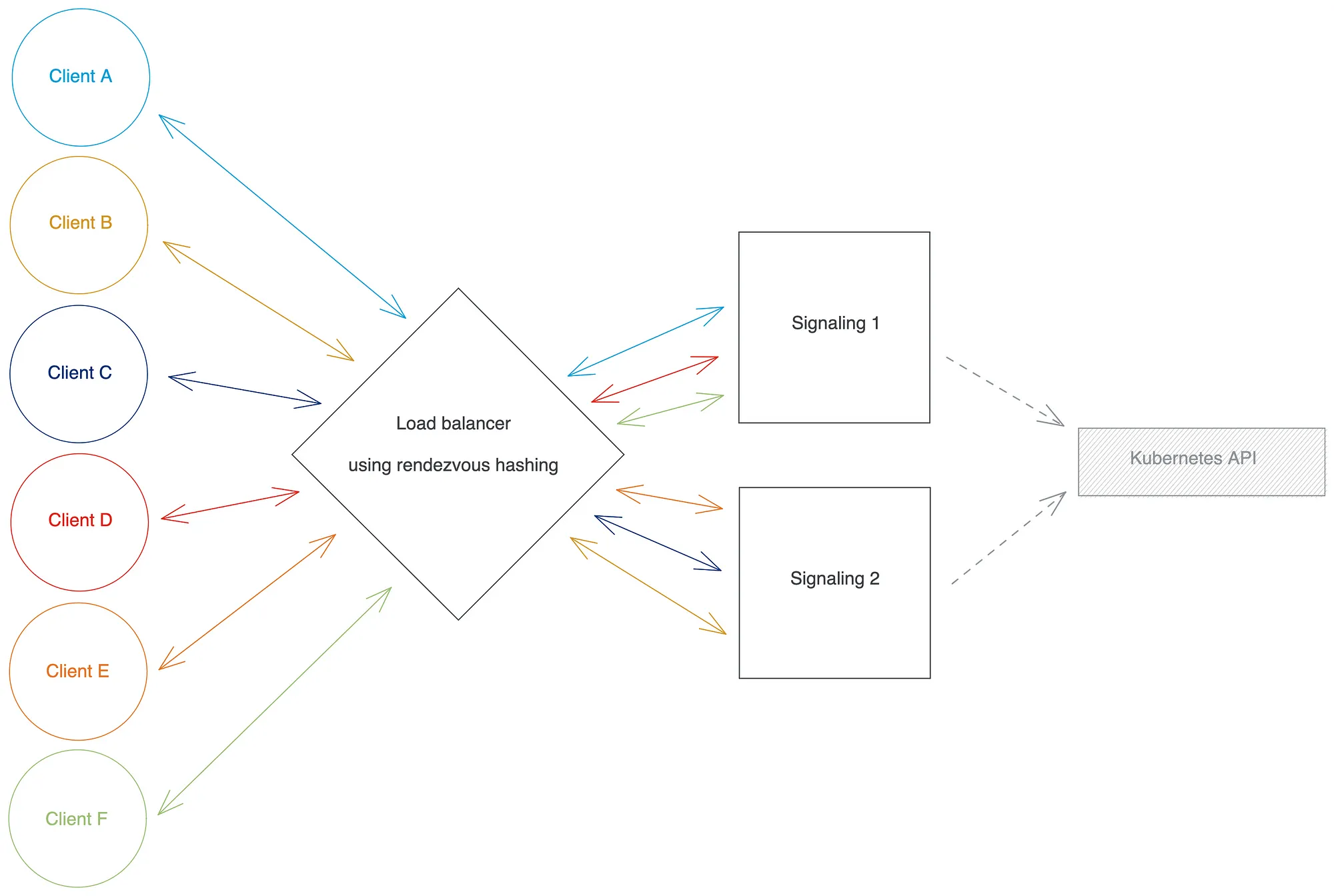
rendezvous hashing(和consistent hashing)的一个非常有趣的特性是,当添加或删除后端实例时,这会更改函数的参数I,函数的返回值只会修改一小部分(如果系统从 N 扩展-1 到 N 个实例,这个分数平均是 的可能输入值的 1/N)val。这意味着当信令服务重新缩放时,只有一小部分现有注册客户端被重新分配到不同的实例——刚好足以在重新缩放后在所有实例之间再次平衡负载。
这听起来是个好消息,但既然我们已经确定在每次重新缩放后应该为一些客户端重新分配一个新实例,那么谁将真正进行重新分配过程?如果实际上没有人将这些 Websocket 连接从旧实例“移动”到新实例,相关客户端将无法正确接收转发的消息。事实上,我们的整个系统依赖于这样一个事实,即每个客户端都必须注册到集合哈希算法分配给它的实例!我们最初的希望是支持 Websockets 和基于哈希的负载平衡方法的负载平衡器足够聪明,可以为我们完成重新映射工作,但……我们错了。据我们所知并根据我们的实验,没有现成可用的负载均衡器(无论是 Nginx、HAProxy、Envoy ……)会自动为您执行此操作。
我们找到了两种可能的解决方案来解决最后一个障碍:
1. 强制客户端重新连接
clientId当信号实例 Iᵢ 通过 Kubernetes Endpoints API 检测到重新缩放事件时,它可以遍历所有注册到它的客户端,并使用更新的实例集重新计算每个客户端的集合哈希算法的结果。从逻辑上讲,这些客户端中的一小部分应该返回一个不是 Iᵢ 的新结果。然后实例 Iᵢ 可以继续关闭这些客户端的 Websocket:如果客户端代码中有重新连接机制,客户端将向信号系统发送一个重新连接请求,该请求将再次通过负载均衡器——现在应该也有更新的信令实例集。因此,负载平衡器会将这些客户端连接到它们适当的新实例。
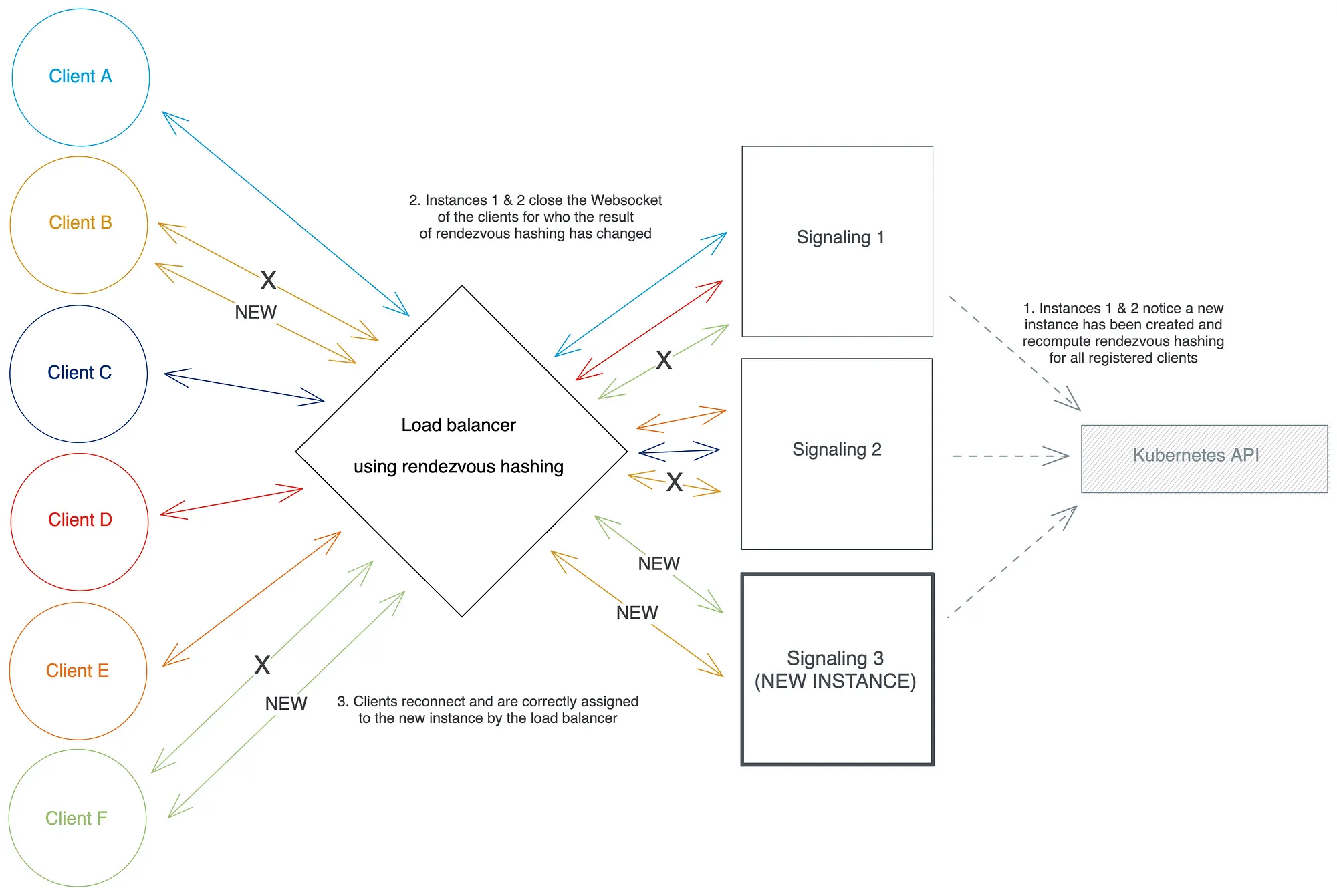
这个解决方案在概念上很简单,但存在一些缺点,这些缺点可能很重要,具体取决于您的用例:
- 它需要在客户端代码中使用重新连接机制。
- 它将通过关闭他们的 Websocket 暂时中断客户端会话。
- 它进一步将您的信令服务器实现代码耦合到周围架构的约束。
- 每次重新缩放时,它都会在您的信号系统上引起重新连接请求峰值。这可以通过让相关客户端在给定的时间窗口内逐步重新连接而不是同时重新连接来缓解,但代价是在它们重新连接到正确的实例之前无法正确地将消息路由到它们。
对于我们的用例,这些缺点太明显了,所以我们最终选择了以下不依赖于任何客户端行为的解决方案。
2. 在负载均衡器中重新映射 Websockets
正如我们之前所说,理想情况下,我们希望负载均衡器本身在重新缩放时重新映射 Websockets,但似乎没有现成的负载均衡器提供这种功能。因此,我们只是决定……编写我们自己的负载均衡器代码。
现在稍等,暂时不要关闭选项卡!我知道你一定在想“你疯了吗?像 Nginx 或 HAProxy 这样的负载均衡器是非常复杂且经过精细优化的软件,需要多年的时间才能开发出来。你正在尝试重新发明整辆车,而不仅仅是车轮!”. 但请记住,我们不需要在这里实现像 Nginx 或 HAProxy 这样功能齐全且用途广泛的负载均衡器:我们只需要能够代理 Websocket 请求和消息,我们确切地知道我们必须使用什么样的客户端和上游服务器兼容,我们知道我们将在什么环境中运行(Kubernetes 集群),我们知道我们将监听的特定路由,我们知道我们将使用什么特定的负载平衡算法。还值得一提的是,在我们的基础架构中,我们在 Kubernetes 集群前面有第一层负载平衡/反向代理,这意味着我们不必在自定义负载平衡器中处理 TLS 或 ALPN。
在那些条件下,编写我们自己的负载均衡器实际上相当简单。这基本上是我们需要实施的所有内容:
- 通过 Kubernetes API 和集合点哈希逻辑发现信令实例:我们只是重复使用了与之前步骤中已经在信令服务器中实现的完全相同的代码。
- 设置一个基本的 Websocket 服务器监听特定路由上的连接请求。该路由的处理程序与客户端运行会合散列算法
clietnId,将请求转发到选定的后端信令实例,然后将响应转发回客户端。如果响应是肯定的,则为该客户端建立两个 Websocket 连接:一个从客户端到负载均衡器,另一个从负载均衡器到信令实例。 - 当负载均衡器在客户端到负载均衡器的 Websocket 上收到一条消息时,它会将该消息转发到该客户端的负载均衡器到信令的 Websocket,反之亦然。
最后,我们只需要在重新缩放的情况下实现我们的 Websocket 重新映射逻辑:当负载均衡器注意到 Kubernetes API 返回的信号实例集发生变化时,它会遍历所有客户端及其当前所针对的客户clientId端代理 Websocket,并使用新更新的一组后端实例为每个重新运行集合点哈希算法。如果这返回一个与客户端当前注册到的实例不同的实例,则负载均衡器仅关闭负载均衡器到信号的 Websocket对于该客户端(保持客户端到负载均衡器的 Websocket 不变)并打开一个新的负载均衡器到信令 Websocket 到新的信令实例。然后它可以使用这个新的 Websocket 恢复从客户端到信令系统的代理消息。
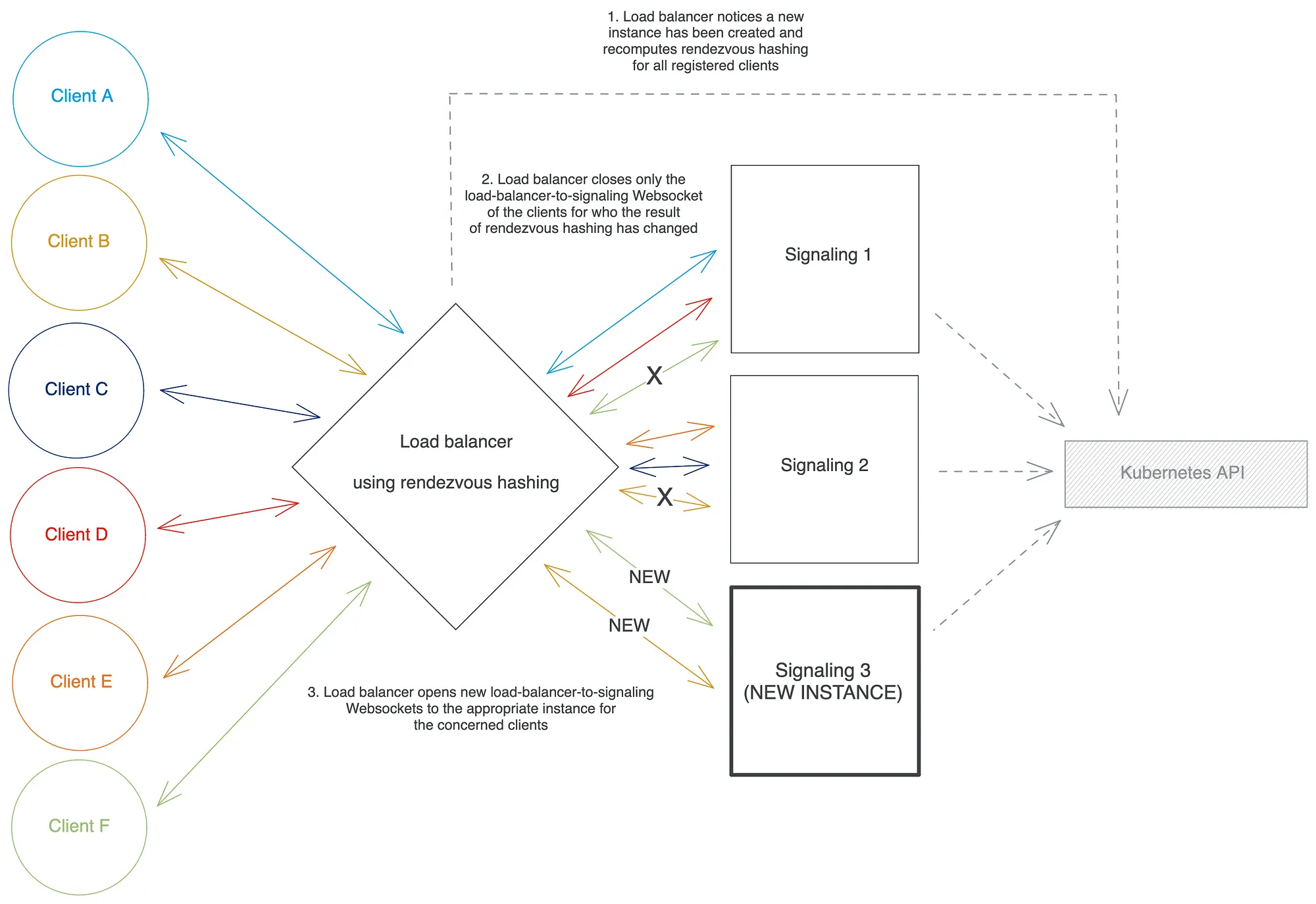
我们使用hyper和tokio-tungstenite库在 Rust 中实现了我们的 Websocket 负载均衡器:我们花了几周的时间来实现它并达到非常接近 Websocket标准的生产就绪状态,代码库总计约 2k 行代码包括测试、日志记录、指标报告和正确的错误处理。我们的生产读数显示,与 Nginx 相比,它在吞吐量性能方面“仅”短 10-30%,而没有进行任何高级优化或使用任何或unsafe高度专业化的代码。
现在如果你想自动缩放负载均衡器本身怎么办?您可能会注意到Balance 约束再次出现——如何在负载均衡器实例重新缩放时保持偶数个 Websockets?— 但这次没有分布式约束 ,将消息传递给接收者的任务已经由信令实例解决了。因此,我们之前针对Balance constraint提到的解决方案,包括在您的前端代理/负载均衡器中使用最少连接的方法,应该在这里起作用。在我们的例子中,我们的前端代理不允许最少连接的负载平衡,所以我们不得不使用我们之前详述的“Readiness probe trick”。
结论
我们希望您发现这篇文章有趣且有启发性,并希望它能帮助您找到想法或解决您自己涉及大规模服务 Websockets 的问题。在我们这边,自2022 年 3 月正式部署到生产环境以来,我们对新的 WebRTC 信令系统非常满意。它已经为数十亿个 Websocket 连接提供服务,并使客户能够在去年交换近万亿(即 10^12)条消息,而无需发出任何操作警报或需要任何手动维护,这让我们的随叫随到的团队大大松了一口气.
我要特别感谢 Charles-Edouard LATOUR 和 Thomas MEDIONI,他们在 2021 年 5 月到 2022 年 3 月的近一年时间里为我的这个项目提供了巨大的帮助。我还要感谢 Reda BENZAIR、Valentin TJONCKE 和 Igor MUKAM,感谢他们宝贵的帮助、反馈和建议。
注意:本文档仅供参考,可能需要最终用户进行额外的研究和证实。此外,信息按“原样”提供,没有任何明示或暗示的保证或条件。使用此信息的风险由最终用户自行承担。Lumen 不保证该信息将满足最终用户的要求,也不保证该信息的实施或使用将导致最终用户期望的结果。© 2023 Lumen Technologies 版权所有。
作者:Erwan de Lépinau
原文:https://medium.com/lumen-engineering-blog/how-to-implement-a-distributed-and-auto-scalable-websocket-server-architecture-on-kubernetes-4cc32e1dfa45
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/im/27160.html