
在日常生活中,噪声是影响语音通话质量的重要因素之一。语音降噪技术通过消除噪声并提取干净语音,从而提高语音质量和可懂度,在移动通信、耳机、会议系统、语音交互等应用中具有巨大价值。近年来,以深度学习为代表的AI降噪技术无需像传统语音增强算法一样对信号特性进行假设,在非平稳噪声上的表现取得了显著提升,面向通信场景的智能降噪技术是其中的研究重点之一。
面向通信的AI降噪技术要求算法能够对带噪语音进行实时处理,一方面,模型不能获得未来信息,只能利用当前帧及历史信息,这要求模型满足因果性;另一方面,模型的处理延迟不能超过人的容忍程度,因此模型在设备上的推理时间也应该符合实时处理的要求。

引用自:https://spectrum.ieee.org/deep-learning-reinvents-the-hearing-aid
因果语音降噪模型按对信号进行操作的域可以分为时频域和时域两大类。
时频域因果语音降噪的估计目标
时频域方法的输入特征最早主要关注幅度信息,包括幅度谱、对数幅度谱及一些滤波器组的子带分解等,利用神经网络估计时频掩蔽(mask)或直接映射为对应的谱。尽管基于掩蔽估计的神经网络模型,最初是以支持向量机(SVM)为代表的监督式语音增强方法的深度学习化[1],只是利用神经网络代替SVM的特征提取步骤。然而随着后续的发展,人们更倾向将其与传统语音增强维纳滤波类方法相对应,这类方法将估计的掩蔽与带噪信号的谱特征相乘,从而约束增强信号的重构过程,理想二值掩蔽(IBM)、理想比值掩蔽(IRM)等表征各时频点(bin)上语音和噪声能量关系的训练目标也被相继提出并应用。此外,如基于掩蔽模型的损失计算是直接针对掩膜还是针对增强的目标信号(signal approximation)[2]、掩蔽估计是否有必要采用有界的激活函数(如sigmoid)等细节也逐步被丰富。
相对于基于掩蔽方法的信号重构约束,基于谱估计的方法直接学习带噪谱到纯净谱的映射关系。互补特征集的选择、训练目标的选取以及模型对于未见噪声、未见说话人等情况的泛化问题成为这一时期研究的重点[2]。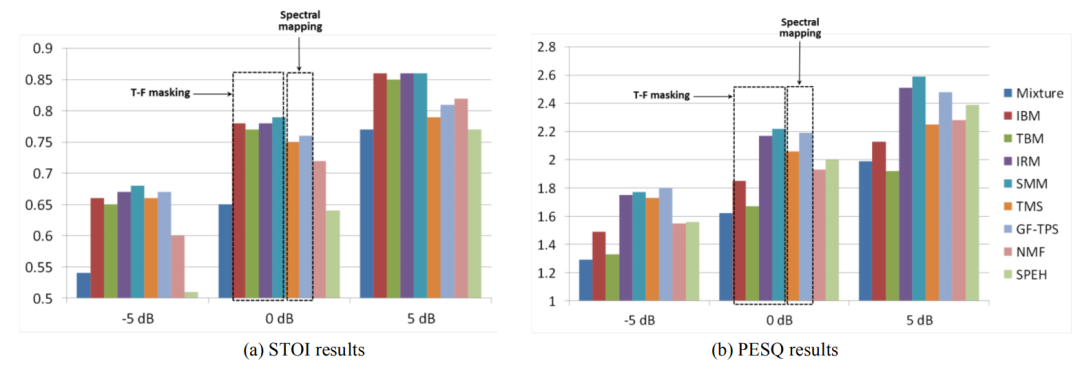 引用自:Supervised Speech Separation Based on Deep Learning
引用自:Supervised Speech Separation Based on Deep Learning
时频域因果语音降噪的模型架构
基于掩蔽估计或基于谱映射的方式将语音增强问题定义为监督学习问题,与图像分割问题的相似性促使在计算机视觉领域取得成功的模型大多成功迁移到了语音增强任务上,全连接网络、循环神经网络(RNN)、卷积神经网络(CNN)、生成对抗网络(GAN)以及各种编解码器结构等网络架构被成功应用。
迁移的方便性使得语音增强的研究更快地进入与传统语音增强方法的结合以及针对语音信号本身特性的研究。由于耳机、手机等端侧设备内存和计算资源的限制,将深度学习与传统语音增强结合的混合式(hybrid)语音增强模型成为从传统方法到深度学习方法的过渡。
以RNNoise[3]为代表的基于谱减类算法的思想将降噪过程解耦为VAD估计、噪声特性估计和降噪三个部分,这种对噪声建模的思想成为后来对语音增强任务进行解耦的众多方法之一[4]。此外估计先验信噪比的统计模型(如MMSE)[5]以及估计线性滤波系数的卡尔曼滤波[6]等混合式语音增强模型也相继被提出。
语音信号复数谱的估计
针对语音信号特性的研究相比混合式模型的发展更具连续性,其中一个主要问题是针对语音信号谱域复数表征这一区别于图像RGB通道的特性的研究。
传统语音增强就曾对低信噪比下相位估计的重要性进行过讨论,随着幅度估计准确性的大幅提升,相位问题再次受到了关注,对于相位估计问题的研究反映了对复数表征解决方式的思考。
从目标角度,主要有将复数分解为实虚部并估计对应的掩蔽或谱和将复数分解为幅度和相位两种方式。由于相位本身不具有清晰的模式,后者采用双流模式通过幅度信息的交互帮助相位进行恢复[6]。而前者通过估计模式结构相对清晰的实虚部以达到复数谱优化的目的,延续幅度谱中基于掩蔽和基于谱映射的两大类方法,基于笛卡尔坐标系[7]和基于极坐标系的复数掩蔽[8]以及直接估计实虚部谱的方法[9]相继被提出。
除目标之外,如何约束网络对实虚部的操作也展现了语音信号处理的自身特色,一方面,对编解码器的参数共享方式被研究,通过对比四种编解码器的组合,一种名为GCRN[9]的多任务学习网络被提出并取得了显著的性能优势。此外,复数网络自DC-UNet[7]起被应用到语音增强任务,根据复数运算法则的约束,复值的CNN、RNN以及Transformer先后被提出,与GCRN对应的复值网络,DCCRN[10],在在第一届Deep Noise suppression (DNS) Challenge中取得了优异的表现。然而,只针对实部和虚部进行优化似乎是不够的,在[7]和[11]等文献中都展现了在复数谱优化过程中带来的幅度估计误差问题,并展现了对幅度估计进行某种约束将带来更高的性能收益。TSCN-PP[12]展示了一种新的对幅度估计进行约束的方式,通过多阶段优化的方式将复数谱估计解耦为幅度和复数谱残差优化,从而在复数谱优化的同时减小了幅度谱估计的误差,并在第二届DNS Challenge中展现了这种解耦带来的优势。

引用自:Phase-aware speech enhancement with deep complex u-net
时域及其他特征和目标
时域方法尝试以一种端到端的方式避开语音信号的复数表征问题,通过网络提取语音信号的高维特征并进行降噪,这类方法尽管在语音分离任务中广泛应用,在增强任务中却相对较少,DEMUCS[13]在DNS Challenge中展现了时域方法在降噪任务上的性能。
除此之外,时域与频域联合的方法通过输入特征融合、多阶段融合[14]和双流融合[15]等方式利用模型对特定类型噪声时域和频域表征处理上的互补特性提升降噪性能。
AI语音增强模型的损失函数和评价指标
对于优化问题,损失函数的定义对于降噪的性能同样重要。时域和时频域的MAE、MSE准则以及对应的压缩形式和加权形式以及基于能量的SNR,SDR和SI-SDR损失最为常用,时频域、幅度和复数谱以及多尺度的互补损失函数也相继被应用。同时,一系列以听觉感知准则(如PESQ,STOI)为目标的模型也发展为语音增强模型的一类方法,然而这些方法大多只在一个指标上表现优异而在其他指标上没有突出的表现。这些客观评价指标与人类主观听感的相关性目前尚不能令人满意,这类算法的性能依赖于基于深度学习的语音质量评价指标的建立。
尽管基于监督式学习的AI降噪近年来涌现出大量研究,然而还有许多问题仍需研究。深度学习算法的鲁棒性问题、引入的非线性失真问题、噪声抑制量与语音失真量的控制问题以及无监督和自监督的语音增强问题也许需要投入更多的关注。
参考文献:
[1] Y. Wang and D.L. Wang, “Towards scaling up classification based speech separation,” IEEE Trans. Audio Speech Lang. Proc., vol. 21, pp. 1381-1390, 2013.
[2] D. Wang and J. Chen, “Supervised Speech Separation Based on Deep Learning: An Overview,” in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 26, no. 10, pp. 1702-1726, Oct. 2018.
[3] J. Valin, “A Hybrid DSP/Deep Learning Approach to Real-Time Full-Band Speech Enhancement,” 2018 IEEE 20th International Workshop on Multimedia Signal Processing (MMSP), 2018, pp. 1-5.
[4] R. Xu, R. Wu, Y. Ishiwaka, C. Vondrick and C. Zheng. “Listening to sounds of silence for speech denoising. ” arXiv preprint arXiv:2010.12013.
[5] A. Nicolson and K. K. Paliwal, “Deep Xi as a Front-End for Robust Automatic Speech Recognition,” 2020 IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE), 2020, pp. 1-6.
[6] H. Yu, W. Zhu, B. Champagne, ‘‘Speech enhancement using a DNN-augmented colored-noise Kalman filter,’‘ Speech Communication, Vol. 125, pp. 142-151, 2020.
[7] H. S. Choi, J. H. Kim, J. Huh, A. Kim, J. Ha and K. Lee, “Phase-aware speech enhancement with deep complex u-net.,” In International Conference on Learning Representations, 2018.
[8] D. S. Williamson, Y. Wang, and D. Wang, “Complex ratio masking for monaural speech separation,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 24, no. 3, pp. 483–492, 2015.
[9] K. Tan and D. Wang, “Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 28, pp. 380–390, 2020.
[10] Y. Hu, Y. Liu, S. Lv, M. Xing, S. Zhang, Y. Fu, J. Wu, B. Zhang, and L. Xie, “DCCRN: Deep complex convolution recurrent network for phase-aware speech enhancement,” in Proc. of Interspeech 2020, 2020, pp. 2472–2476.
[11] Z.Q. Wang, G. Wichern, and J. Le Roux, “On The Compensation Between Magnitude and Phase in Speech Separation”, in IEEE SPL, 2021.
[12] A. Li, W. Liu, X. Luo, C. Zheng, and X. Li, “ICASSP 2021 Deep Noise Suppression Challenge: Decoupling Magnitude and Phase Optimization with a Two-Stage Deep Network,” 2021, arXiv:2102.04198.
[13] A. Defossez, G. Synnaeve and Y. Adi, “Real time speech enhancement in the waveform domain,” 2020, arXiv preprint arXiv:2006.12847.
[14] N.L. Westhausen, B.T. Meyer, “Dual-Signal Transformation LSTM Network for Real-Time Noise Suppression, “ in Proc. of Interspeech 2020, pp. 2477-2481.
[15] K. Zhang, S. He, H. Li and X. Zhang, “DBNet: A Dual-branch Network Architecture Processing on Spectrum and Waveform for Single-channel Speech Enhancement.” 2021, arXiv preprint arXiv:2105.02436.
作者:21dB声学人——中国科学院声学研究所苏州电声产业化基地旗下科技媒体,专注于声学新技术、音频测试与分析、声学市场调研、声学学习社群建设等。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。