
背景
随着互联网技术以及网络基建的快速发展和普及,视频直播已经成为了一种越来越普遍的娱乐和社交方式。无论是个人还是企业,都可以通过视频直播平台进行直播活动,向观众展示自己的生活、工作或者产品。同时,视频直播也成为了一种新型的社交媒体,让人们可以在虚拟空间中进行互动交流。
RTM(Real Time Media,低延时直播)是近期逐步兴起的一种以提升客户交互体验为目标的直播解决方案,它的特点是较传统的直播解决方案,端到端延时更小达到 1 秒级别,卡顿无明显负向,RTM 的网络传输层是基于 WebRTC 技术的(RTP/RTCP 协议)。
RTM 推流相比于传统的 RTMP 推流,在网络变化响应灵敏度、弱网对抗、带宽利用率等方面都有明显优势。在抖音的 AB 实验中主播人均被看播时长/被关注/被评论显著正向,拉流音频/视频卡顿 -22.2%/-7.8%,端到端延迟 -1.6%。目前 RTM 推流在抖音秀场完成了 10% 左右的常规放量。
技术架构
CDN 技术架构
目前 CDN 厂商对 RTM 的支持主要有两种技术架构,一种是基于传统的 RTMP/FLV 架构,在推拉流边缘节点增加 RTM 接入协议的支持,CDN 集群内部复用传统架构,另一种是 CDN 内部集群也采用 RTP/RTCP 协议和架构。CDN 的技术架构如下图所示:
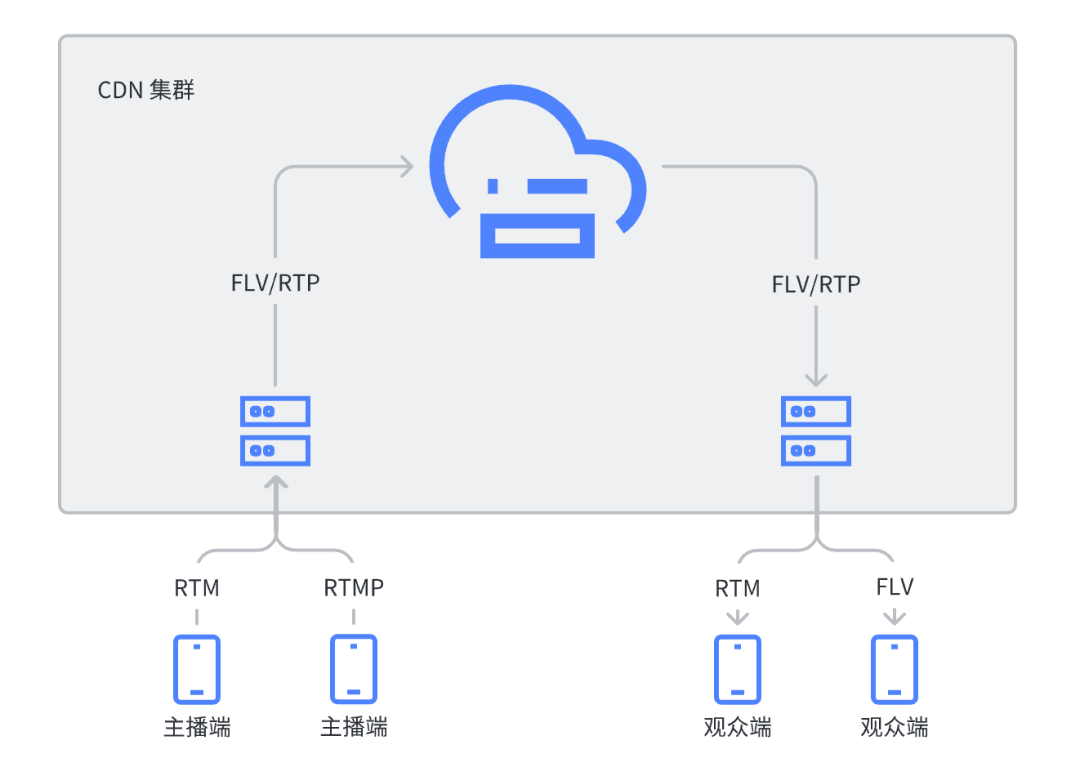

客户端技术架构
在推流客户端,RTM 推流网络传输层使用了火山引擎自研 RTC SDK(VolcEngineRTC),在设计之初,为了支持业务无缝接入,以及最大化复用已有能力、避免重复造轮子,RTM 推流在客户端采用了 LiveCore(火山引擎自研直播推流 SDK)编码音视频 + VolcEngineRTC 传输的技术架构,如下图所示:
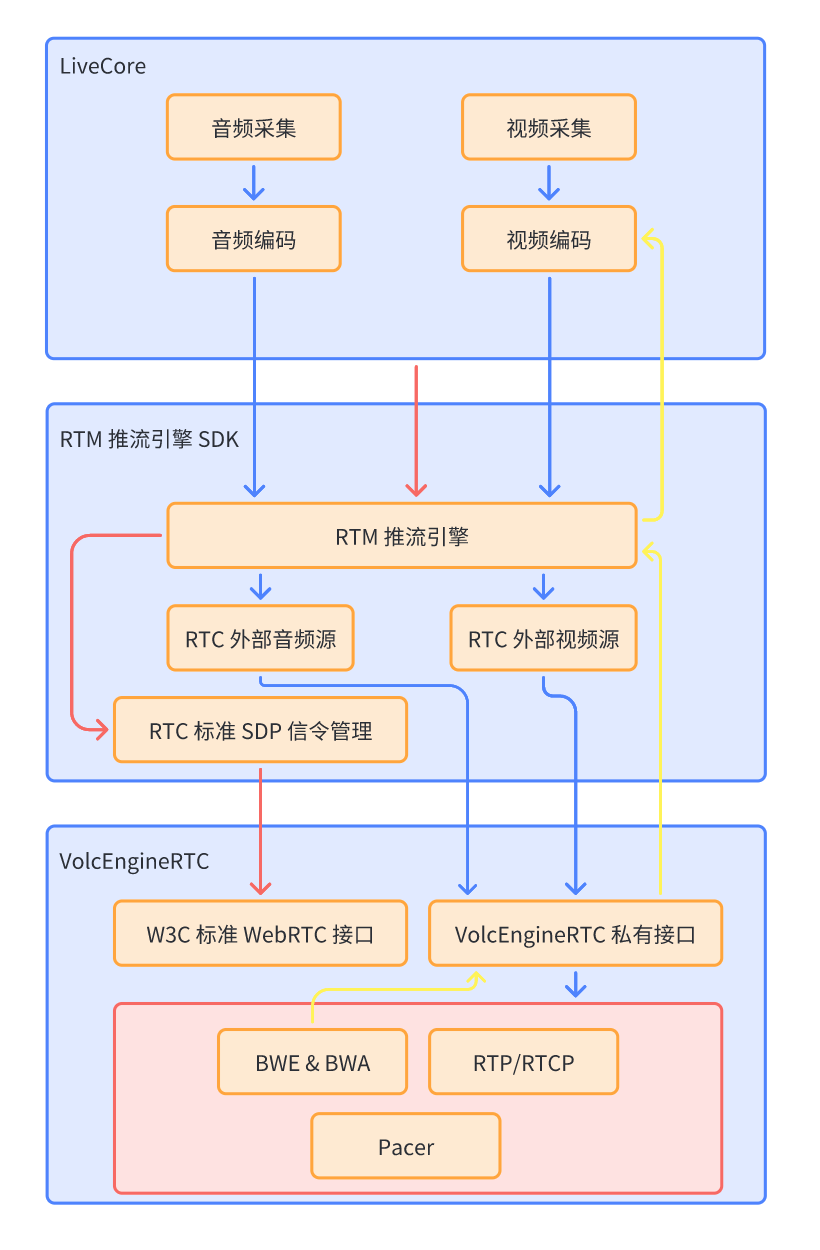
主要包括三部分:
-
推流建立连接时,LiveCore 调用 RTM 推流引擎的接口,RTM SDK 内部的 RTC 标准 SDP 信令管理模块,通过 VolcEngineRTC 的 W3C 标准 WebRTC 接口,和 CDN 服务端完成信令协商,信令交换使用的是 HTTP/HTTPS 协议(图中的红色箭头) -
推流过程中,LiveCore 完成音视频采集、编码,把编码后的 AAC 和 H.264/H.265 码流,送入 RTM 推流引擎,RTM 推流引擎再通过 VolcEngineRTC 的外部音视频源私有接口,把音视频码流送入 VolcEngineRTC,进而封装为 RTP/SRTP 包,发送到 CDN 服务端(图中的蓝色箭头) -
推流过程中,VolcEngineRTC 内部的网络传输引擎,对网络状态进行追踪,预估出网络可用带宽,并进行编码器带宽分配,再通过 VolcEngineRTC 私有接口回调到 RTM 推流引擎,最后再反馈到 LiveCore 的视频编码模块,进行视频编码码率调节(图中的黄色箭头)
技术优化
功能补齐和稳定性打磨
因为 RTM 是近期逐步兴起的直播解决方案,无论是在 CDN 服务端,还是客户端 SDK,都处于发展早期,功能仍有诸多欠缺,比如最初只有两家 CDN 支持 RTM 推流,音视频编码格式的兼容性也有欠缺,HE AAC、H.265 和视频 B 帧在前期联调阶段都是不支持的,而且稳定性也有待打磨,在联调和灰度放量过程中,多次遇到过花屏问题。
关于功能和稳定性,这里我们分享两个案例:支持视频 B 帧,解决花屏问题。
支持视频 B 帧
WebRTC 标准本身是不支持视频 B 帧的,因为 WebRTC 的设计初衷就是实时通话(RTC)场景,而视频编码开启 B 帧会引入额外的延迟,影响通话体验。但在直播场景,对延迟的要求比 RTC 要宽松很多,而开启 B 帧能提高视频压缩效率,可以提升画质或者节省带宽成本,所以在直播场景开启 B 帧是很普遍的做法。
下面是互娱-评测实验室同学针对开 B 帧进行的画质测评结论:
【互娱-评测实验室】抖音直播 Android 软编开 B 帧降码率画质评测报告
结合主客观表现,Android 设置软编 + B 帧后,静态清晰度与硬编无明显差异,但马赛克明显增多,劣化幅度较大, 软编各个降码率点之间马赛克差距不大(0.9、0.88、0.85、0.82)
主观画质:
马赛克表现: 秀场场景,相较于硬编软编动态场景下均存在明显马赛克;PK 场景:软编动态场景存在轻微马赛克,稍差于硬编 清晰度 表现: 软编面部纹理细节表现略优于硬编,各个降码率档位清晰度与不降码率差异主观感知不明显 客观画质:
VMAF : 硬编切软编后,指标下降较明显,软编各个降码率点之间指标下降不明显 Acutance(图卡清晰度指标):硬编切软编后,指标下降较明显,软编各个降码率点之间指标下降不明显
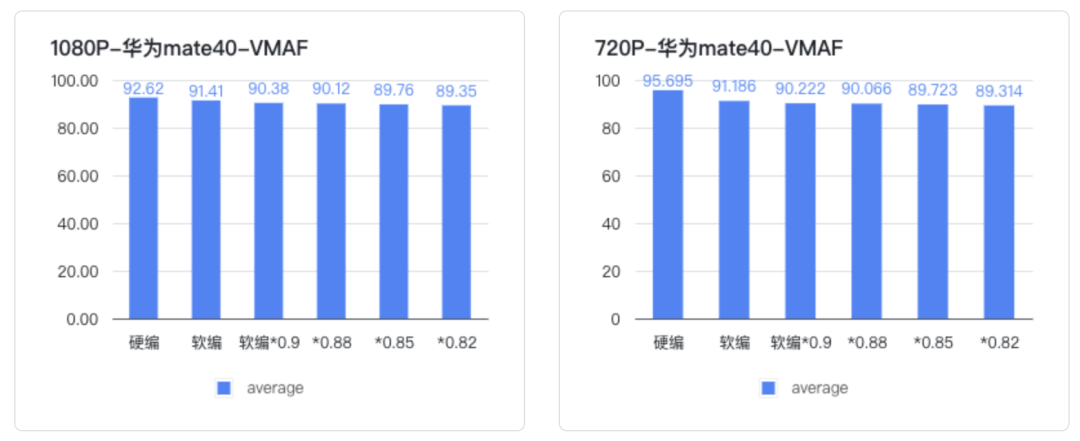
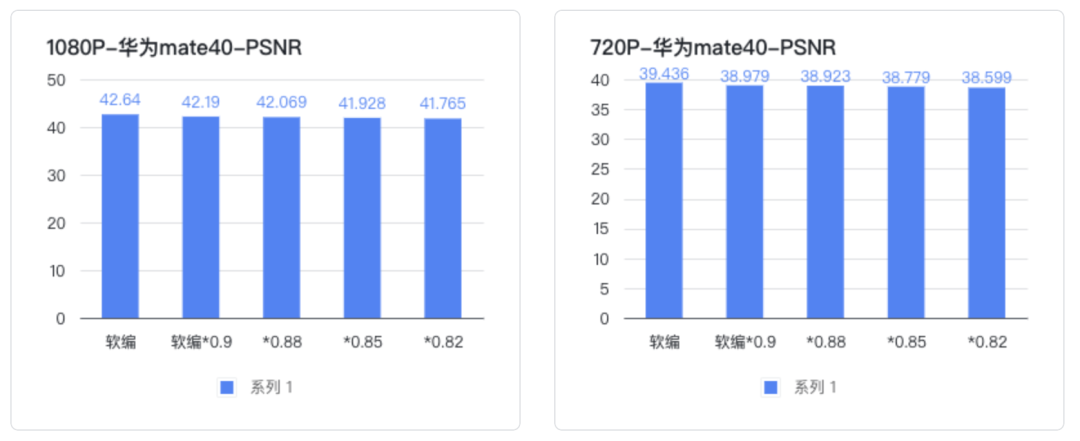
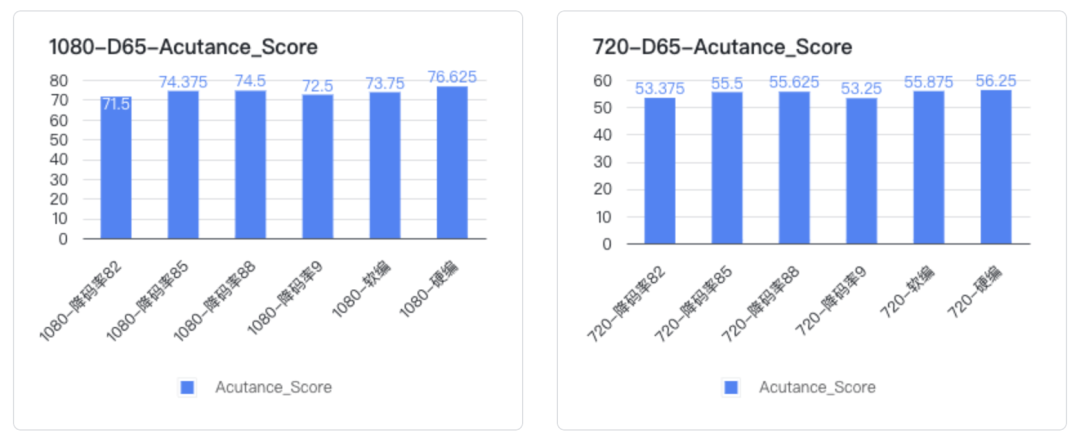
测评发现虽然软编和硬编的主客观清晰度有比较明显的差异,但是在软编的情况下(都开了 B 帧),降低编码码率主客观清晰度都没有明显的差异。
为了支持 B 帧,我们需要对 WebRTC 进行媒体能力协商的 SDP 标准进行扩展,下面是《超低延时直播技术白皮书》(https://www.volcengine.com/docs/6469/103017#%E8%A7%86%E9%A2%91-b-%E5%B8%A7%E6%94%AF%E6%8C%81)中关于视频 B 帧支持的相关扩展定义:
SDP 视频 B 帧协商
客户端需要在 Offer SDP 中添加 B 帧相关信息,实现 B 帧 timestamp 非单调递增的处理逻辑,后台则需要实现相应 B 帧 timestamp 封装逻辑。SDP B 帧协商示例如下所示。
... a=rtpmap:96 H264/90000 a=fmtp:96 BFrame-enabled=1;level-asymmetry-allowed=1;packetization-mode=1;profile-level-id=42e01f ...SDP 中的 BFrame-enabled 代表客户端是否支持解码 B 帧。不代表服务端是否支持发送 B 帧。
OfferSDP中BFrame-enabled=0,源流带 B 帧,则服务器把源流B帧去除后再转发客户端。 OfferSDP中BFrame-enabled=0,源流不带 B 帧,则服务器把源流直接转发客户端。 OfferSDP中BFrame-enabled=1,源流带 B 帧,则服务器把源流直接转发客户端。 OfferSDP中BFrame-enabled=1,源流不带 B 帧,则服务器把源流直接转发客户端。 视频 B 帧时间戳计算
视频 B 帧时间戳计算方式有 2 种。
建议规范 1: 每个 RTP 包的 rtp timestamp 携带当前帧数据的采样时间即 PTS,解码顺序附着于 SequenceNumber 顺序, 客户端不能直接计算出 DTS 的值,此种规范下在有 B 帧的时候不便于快速解码和出帧。 建议规范 2:使用 RTP 私有扩展头携带 CTS 值,每个 RTP 包的 RTP timestamp 携带当前帧数据的采样时间即 PTS, 每一帧首个 RTP 包和 VPS/SPS/PPS 包通过 RFC5285-Header-Extension 扩展头携带该帧的 CTS 值,通过 DTS = PTS – CTS * 90 公式计算出当前帧的解码时间戳。SDP extmap 示例如下所示。 ... a=rtpmap:96 H264/90000 a=fmtp:96 BFrame-enabled=1; a=extmap:7 rtp-hrdext:video:CompistionTime ...
以上两种方式可以兼容,当 offer sdp 有相应 extmap rtp-hrdext 字段时采用规范 2,否则采用规范 1。
在 RTM 推流立项之初,VolcEngineRTC 对推流视频 B 帧的支持也是欠缺的,我们也对 VolcEngineRTC 的代码仓库提交了相关修改的 MR,并推动 CDN 服务端进行开发、联调,最终通过灰度放量,验证了功能和稳定性问题,完成了对视频 B 帧的支持。
解决花屏问题
花屏的可能原因很多,从主播端到观众端的整个链路中,任何一个环节都可能出错导致花屏,下面是典型的视频全链路涉及到的环节:
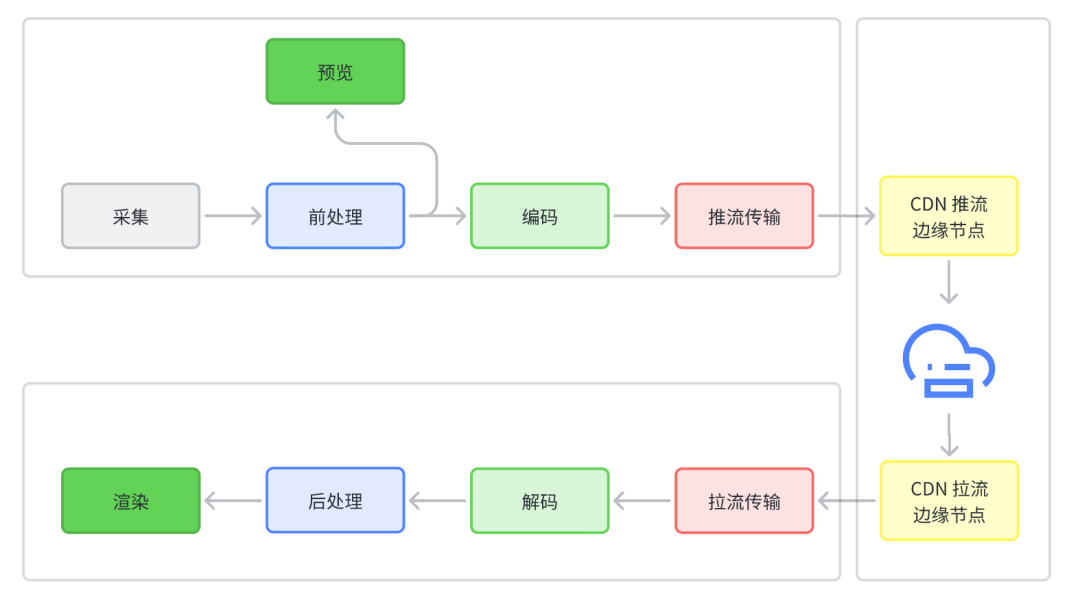
用户有两个环节会观察到花屏现象:主播的预览和观众的渲染。但问题不一定出在这两个环节,尤其是观众看到花屏时,就可能是编码器有 bug,推流传输过程丢失了视频参考帧,CDN 下发给观众端的数据出现了错误,解码器有 bug,或者渲染模块有 bug。
排查花屏问题最常用、也是最有效的手段,就是在一些关键环节的位置,保存视频码流数据,用可信的程序(比如 ffmpeg)验证到这个环节的数据是否正常,比如在推流端把编码器输出的数据写入到本地,抓取发送的数据包,或者在服务端抓包。
除了直接用 ffplay 播放观察是否花屏(或者 ffplay 控制台是否打印了错误日志),我们还可以用下面的 ffmpeg 命令,把视频的每一帧都导出为图片:
ffmpeg -i test.flv frames/$filename%03d.bmp
比如我们某次排查花屏问题时,就发现是从第 30 帧开始出现花屏:
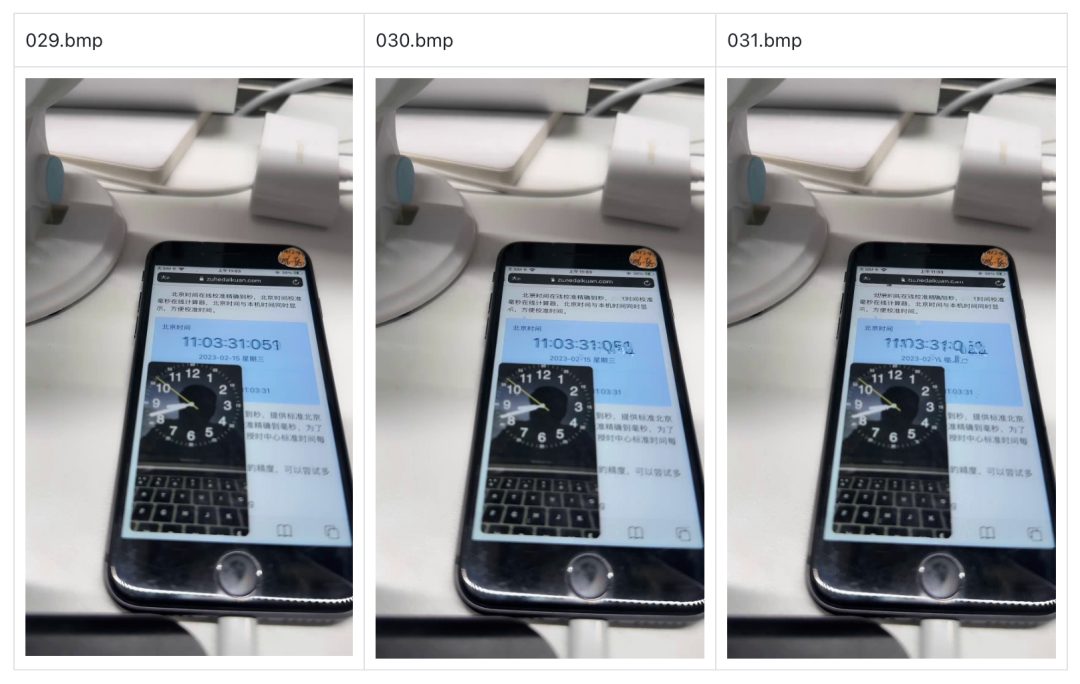
而这个 flv 文件是 QA 同学在测试过程中使用 wget 命令保存的拉流 url 的数据,并且推流端的抓包码流播放并不会花屏,所以就实锤是 CDN 的问题了。
在 RTM 推流的联调和灰度放量过程中,多次遇到过花屏问题,每次出问题的环节都不一样,可以说基本上把坑都趟了个遍,这里就不一一展开介绍了,感兴趣的同学欢迎线下交流。
卡顿优化
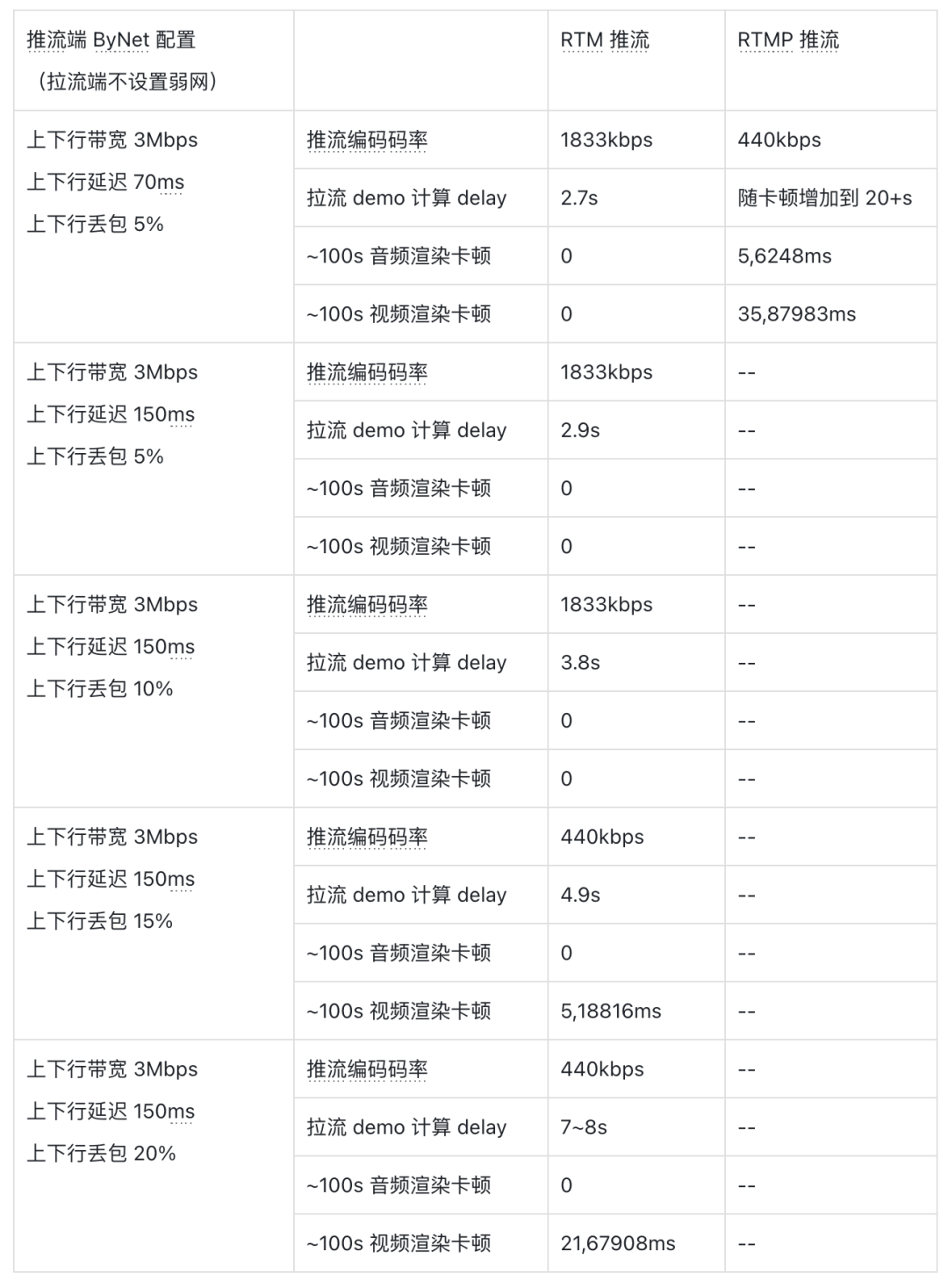
功能和稳定性问题解决之后,我们在线下使用公司内部的 ByNet 弱网模拟工具测试发现,RTM 推流在弱网下的表现很差(测试基于 iOS 系统,视频编码格式为 H.265,分辨率 720p,码率自适应范围为 440kbps~1833kbps):
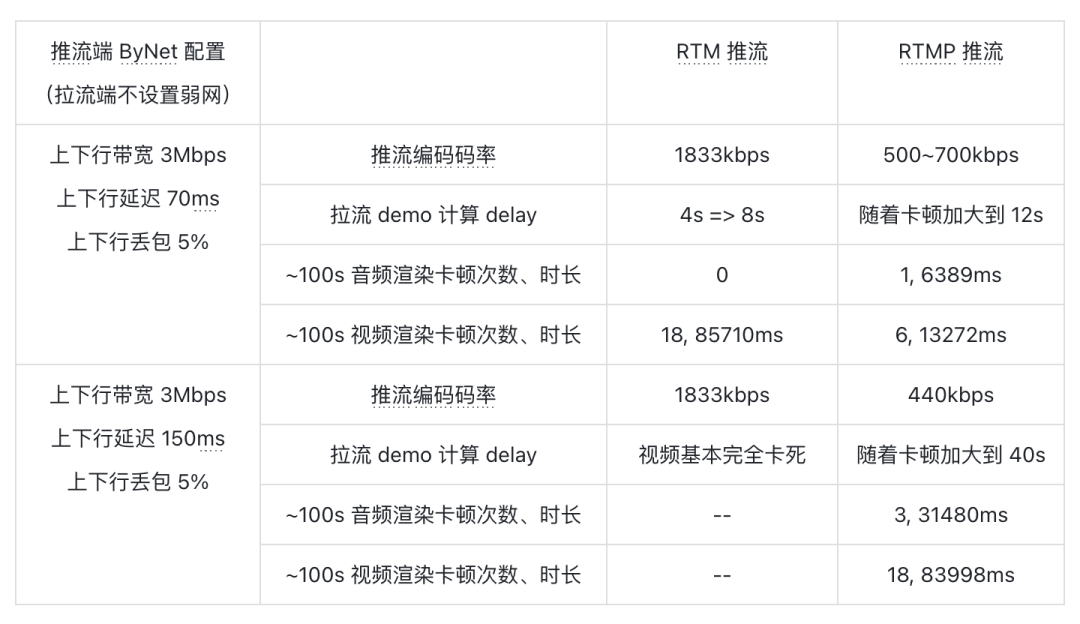
5% 丢包 150ms rtt 的情况,RTM 推流就已经卡得无法播放了(表格中的 — 表示基本无法播放,数据无法统计)。
经过和各家 CDN 服务端的联合分析,我们发现了几个问题:
-
某云 CDN 发送的音频 NACK 包没有携带正确的 sender ssrc,导致丢失的音频包没有重传; -
VolcEngineRTC 发送 RTCP XR 报文时 DLRR block 有问题,导致 CDN 无法正常估算网络 rtt,视频重传次数很快用完,进而导致视频重传也基本无效; -
CDN 推流边缘节点视频组帧之前的 buffer 过小,导致客户端重传的视频包也基本没有生效; -
CDN 没有启用 TCC 算法(之前用的 REMB 算法),推流端对网络状态的适应能力差;
在技术架构上,火山引擎直播 CDN 采用的是上文介绍的第一种技术架构,即边缘的收流节点会把 RTP 包组帧,转换成 RTMP/FLV 流推到源站,这里我们展开介绍火山引擎直播 CDN 在组帧环节做的两个优化。
组帧 jitter buffer:针对抖动、乱序、丢包重传场景,如果 CDN 接收组帧 buffer 设置得太小,就会导致帧丢失和 GOP 丢失,从而影响用户观看直播的流畅度并引起卡顿感;如果 CDN 接收组帧 buffer 设置太大,则由于组帧引入的延迟就很大,降低直播的交互性。为了解决这个问题,我们参考 WebRTC 的 NetEQ,引入了网络自适应的 buffer,即通过估算推流侧的网络抖动设置接收组帧 buffer 大小。对于大部分网络较好的推流,组帧 buffer 引入的延时极小;对于抖动、乱序、丢包重传的推流,又可以保障流畅性同时尽可能少引入延时。
组帧交织:UDP 数据包不保证到达顺序、视频组帧抖动等因素,会引起转换出 RTMP/FLV 流中的音视频不严格交织,有的视频连续 3~4s 都没有音频(或反过来)。在拉流端到端延时低至 2~3s 的背景下,播放端会因为音画同步机制引入卡顿,影响用户看播体验。对于这个问题,我们在 CDN 接收组帧的 jitter buffer 出帧时,结合音视频 jitter buffer 的长度,做了音视频交织,确保音视频帧尽量均匀,dts 差距不能过大。经过线上验证,不交织引起的播放卡顿显著下降。
上述问题都解决之后,再次进行模拟弱网测试,结果有了很大的改善:
可以看到在 10% 丢包 150ms rtt 时,推流仍保持在自适应的最高码率进行推流,并且拉流也没有任何卡顿。不过在丢包率增加到 15% 甚至 20% 时,RTM 推流的效果也基本就不行了,但我们分析线上数据发现,丢包率超过 10% 的情况占比很少,所以就没有继续优化了。
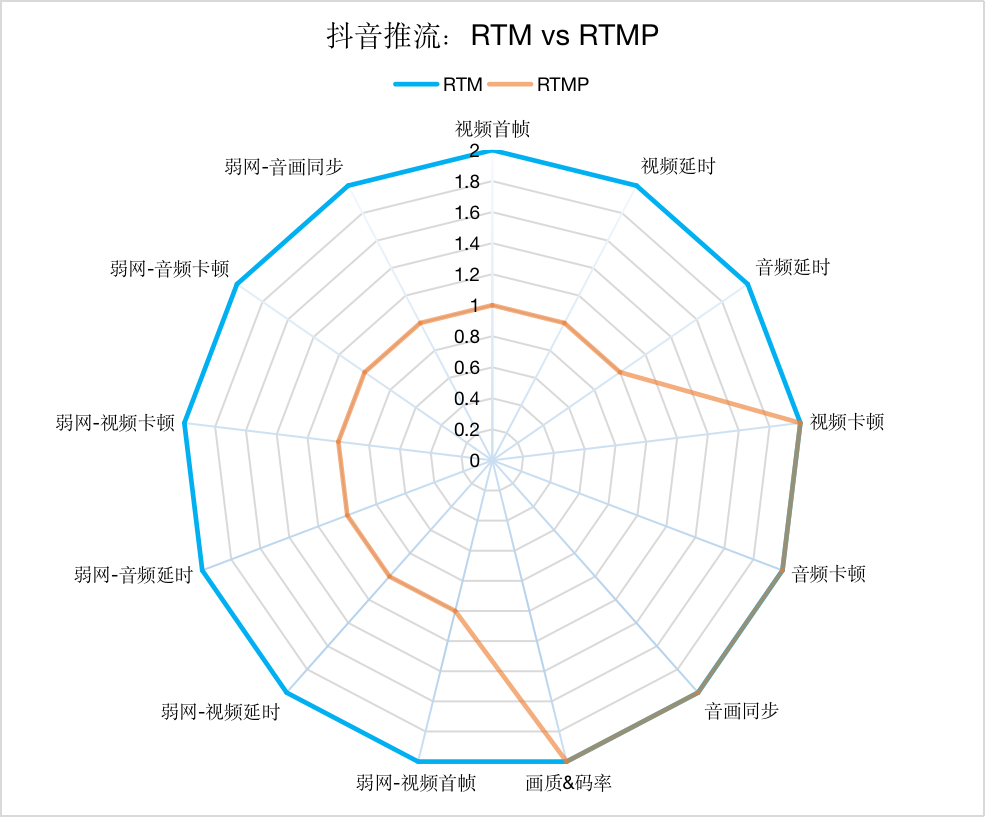
最后我们请视频云团队的音视频实验室对 RTM 推流和 RTMP 推流在抖音上进行了权威的测评,测评结果为:
「抖音推流」RTM vs RTMP 评测报告
弱网下:各指标均优于 RTMP 正常网络下:视频首帧、视频延时、音频延时优于 RTMP,视频卡顿、音频卡顿、音画同步和画质基本持平 RTMP
算法优化
经过上述一系列工程优化,最后开启线上 AB 实验,相比基线算法 RTMP,结果却不如预期:QoE 开播场次无明显趋势,开播时长稳定偏负,被看播指标无明显趋势,QoS 音频渲染百秒卡顿时长/次数 -3.641%/-4.649%,视频渲染百秒卡顿时长/次数 -2.926%/-8.044%。
直观的疑问是:为什么 QoS 卡顿有收益了却没有 QoE 收益,甚至 QoE 还是负向?
为了探寻原因和更好的进行下一步迭代优化,我们开始深入到 RTM 算法部分进行研究。
问题分析
黑盒测评分析
基于抖音 app 测试推流,拉流影响则使用了拉流 demo
无网损场景、相同直播推流内容下,测试发现,RTM 比 RTMP 目标码率更加保守。e.g.
| RTM(TCC 开启) | RTMP(TCP) | |
|---|---|---|
| 1080p(1088×1920) |
|
|
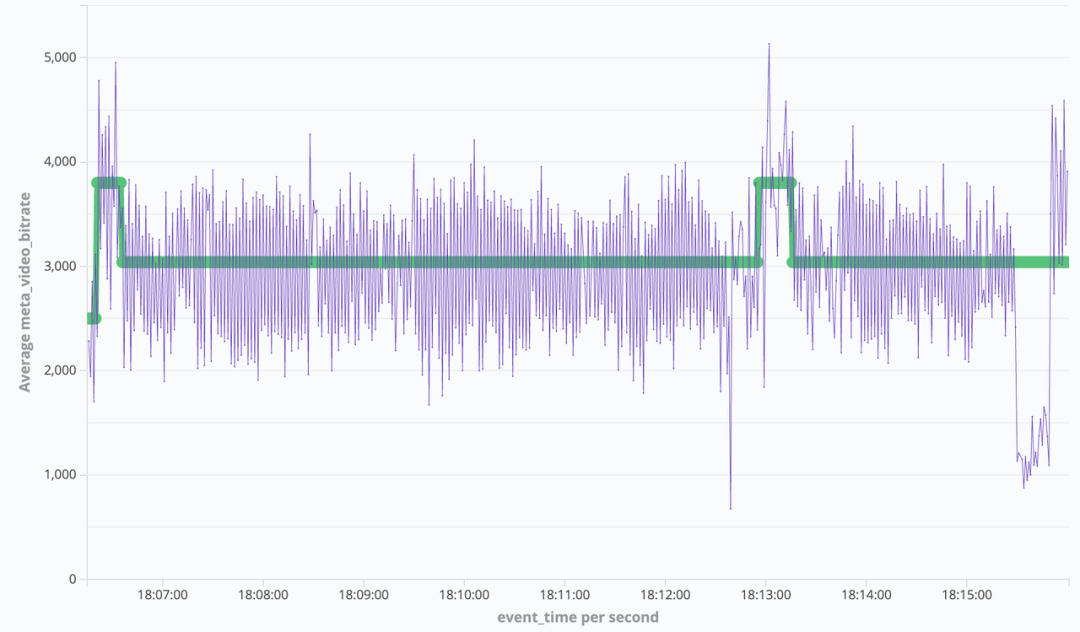
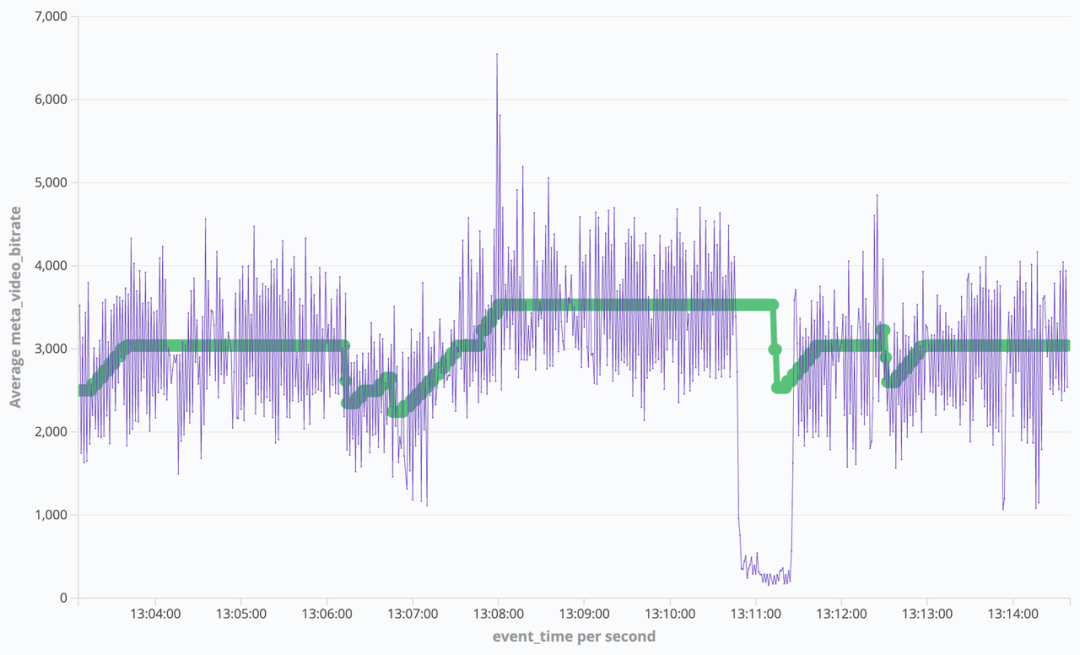
2Mbps 网损下,RTM 带宽利用率仅 50%,对于拉流侧的影响则是画质损伤严重,e.g.
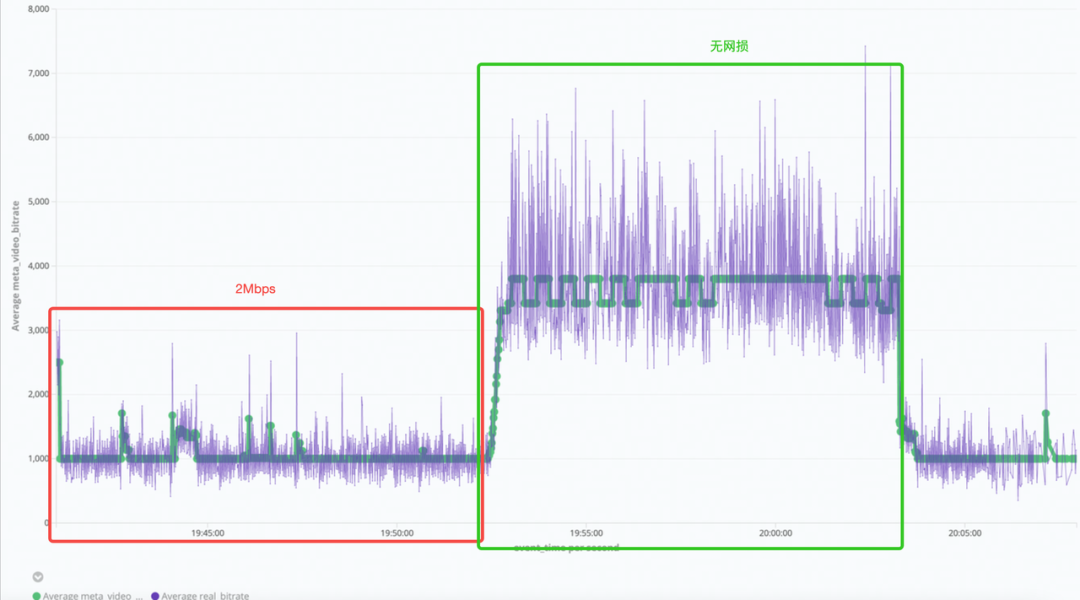
RTM(TCC 开启)的 2Mbps 网损下画面质量(左)无网损画面质量(右)
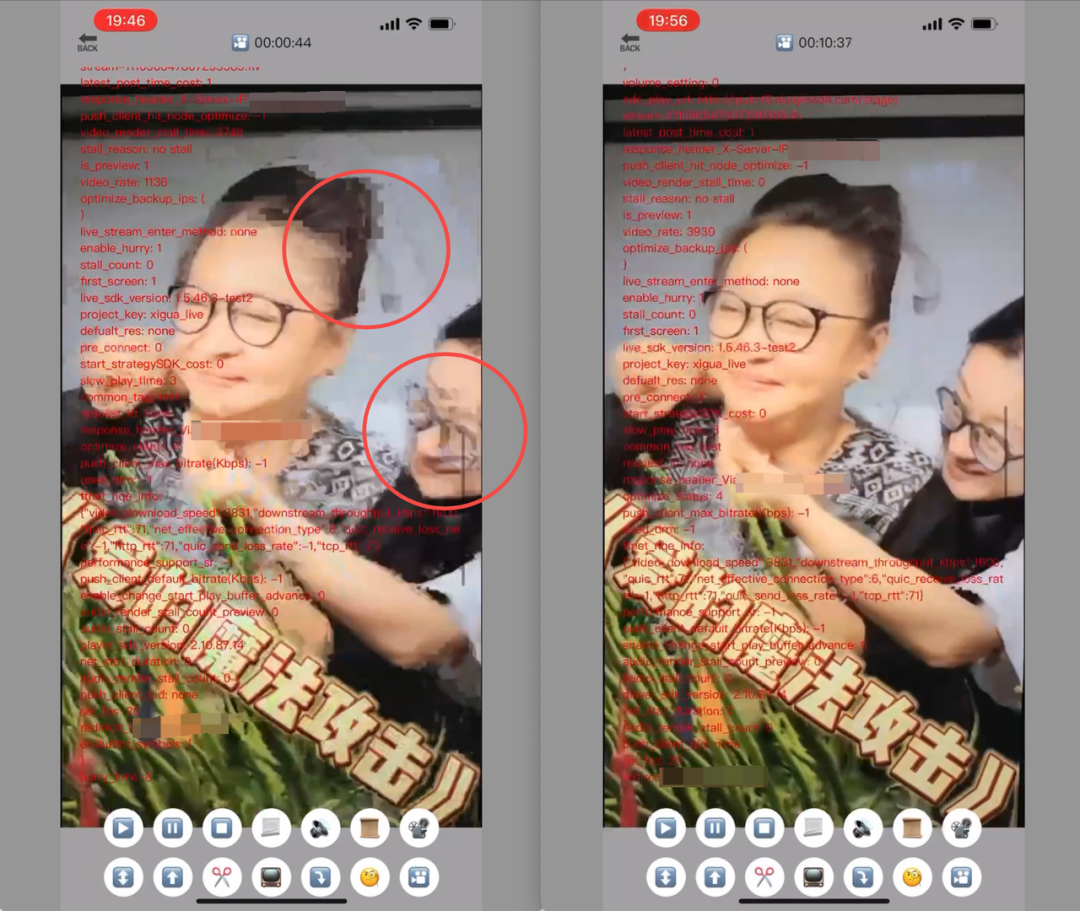
这意味着 RTM 在部分场景下通过牺牲画质体验置换来了卡顿收益。
基于线上大规模数据分析
我们基于抖音的数据集,分析出了以下 3 类关键问题:
1、bwe 周期性震荡问题
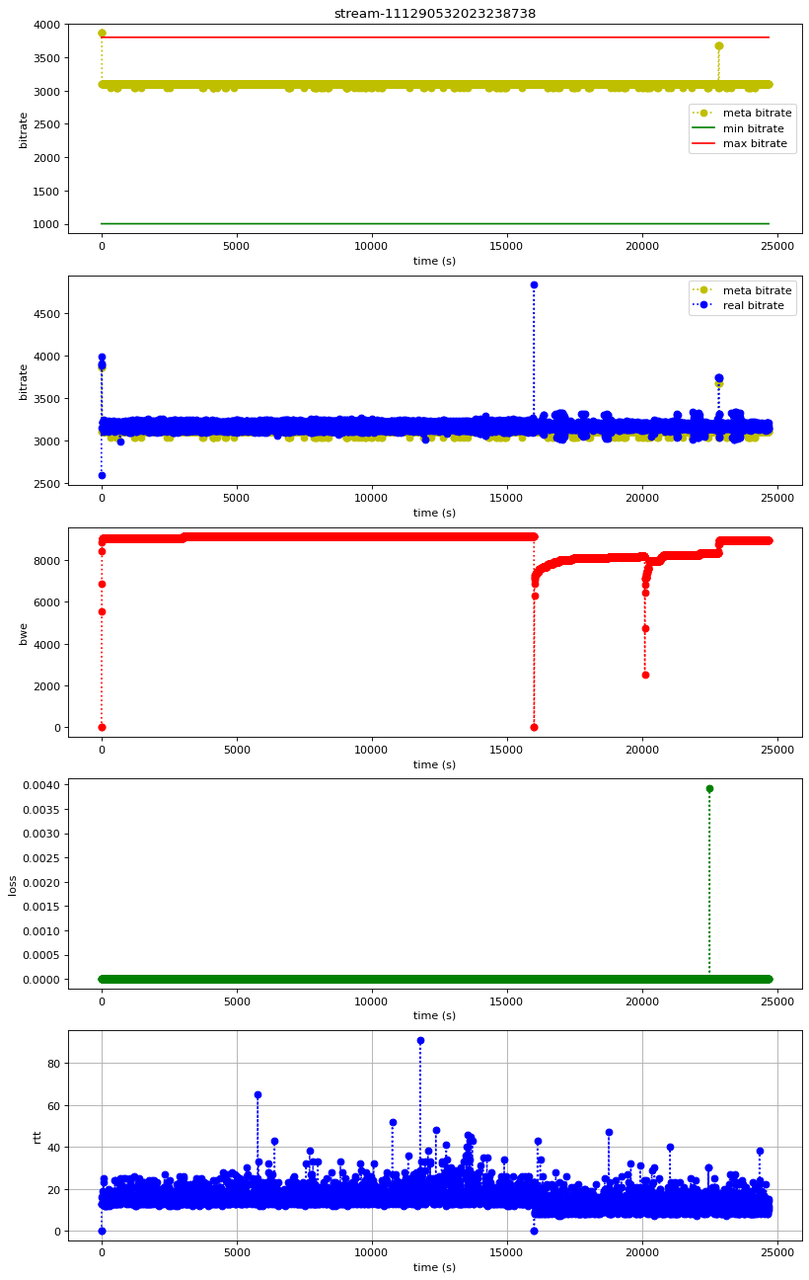
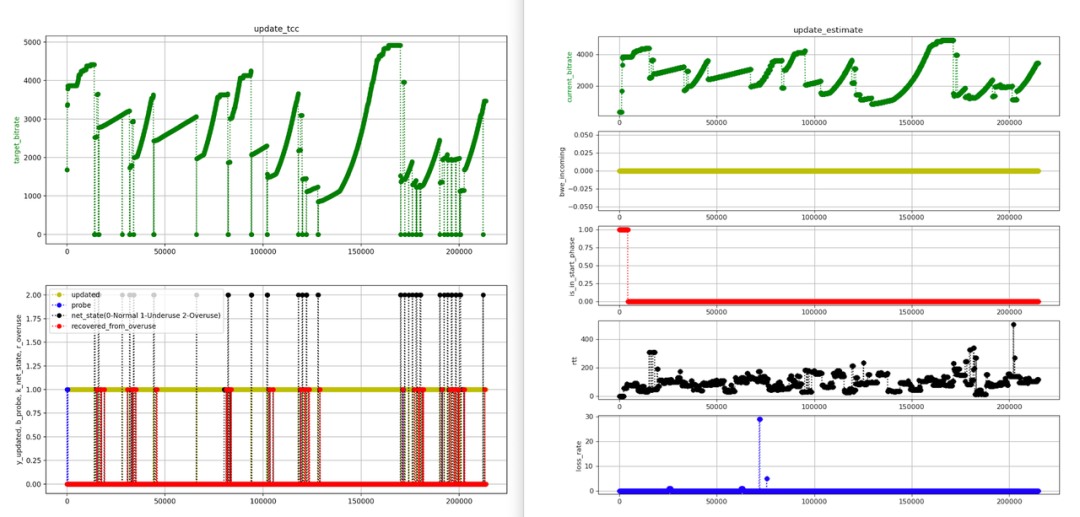
红色线 bwe 震荡波动,大概率会导致黄色线目标码率震荡波动;bwe 的波动不是因为高丢包率,rtt 也是在绝对值较小(100ms 以内)范围内波动。
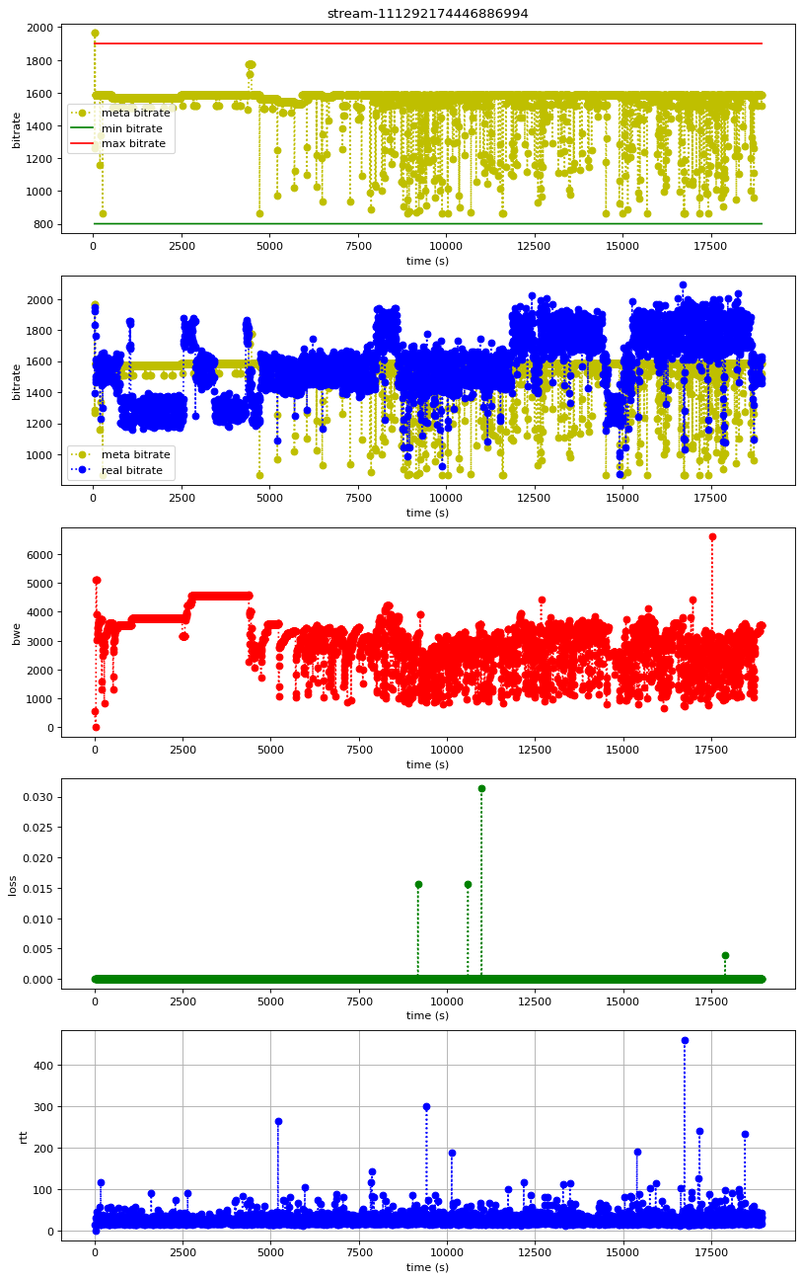
2、目标码率周期性震荡问题
目标码率自身震荡波动,不是受 bwe 影响的(bwe 是稳态的)
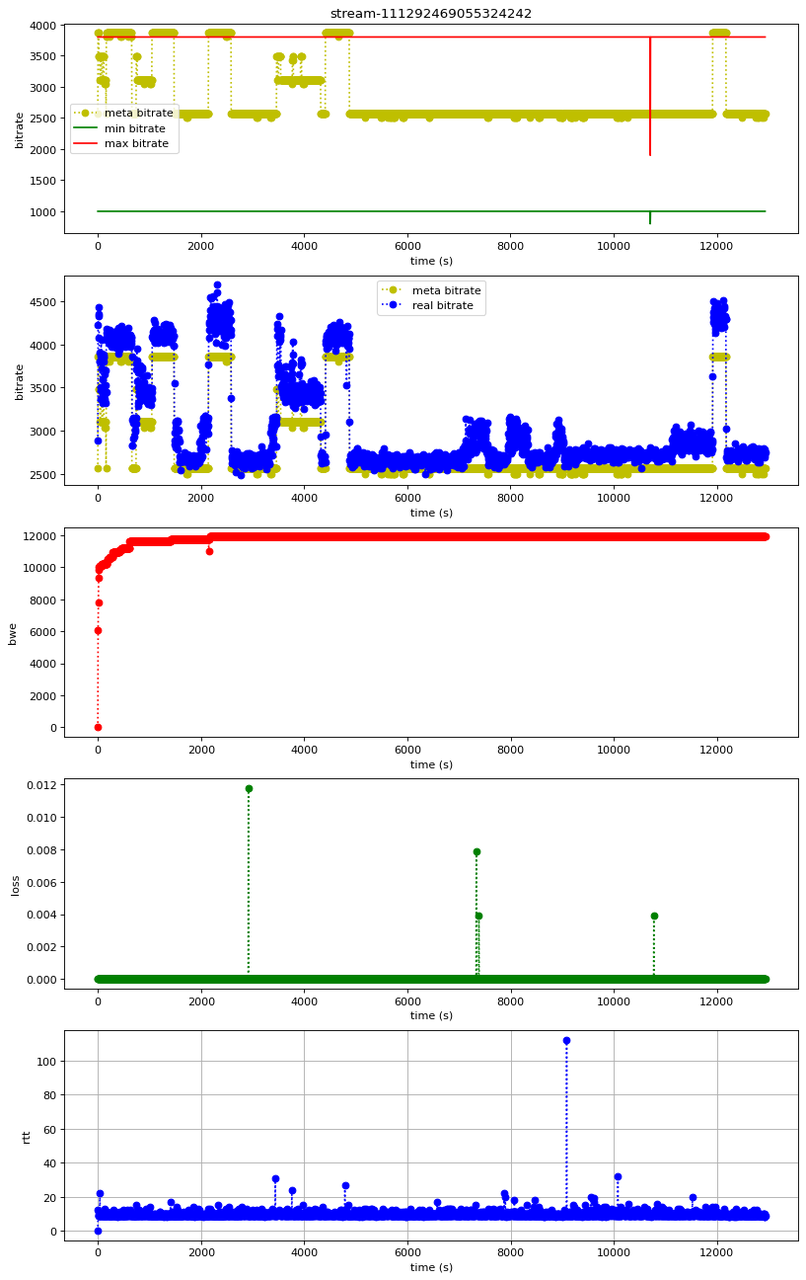
3、传输能力足够,固定式码表限制了画质提升
bwe 高达 8Mbps 以上,而 max bitrate 才3Mbps 左右
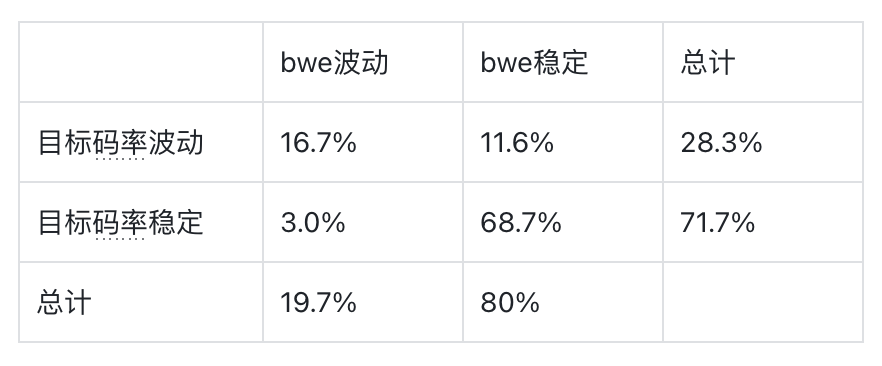
我们还量化识别了问题类型在全部数据集中的重要程度情况:
-
bwe 波动较普遍(19.7%),且 bwe 波动几乎都会引起目标码率波动
-
目标码率波动更普遍(28.3%),但不一定是由 bwe 波动引起的
-
在低带宽场景下更容易产生 bwe 波动
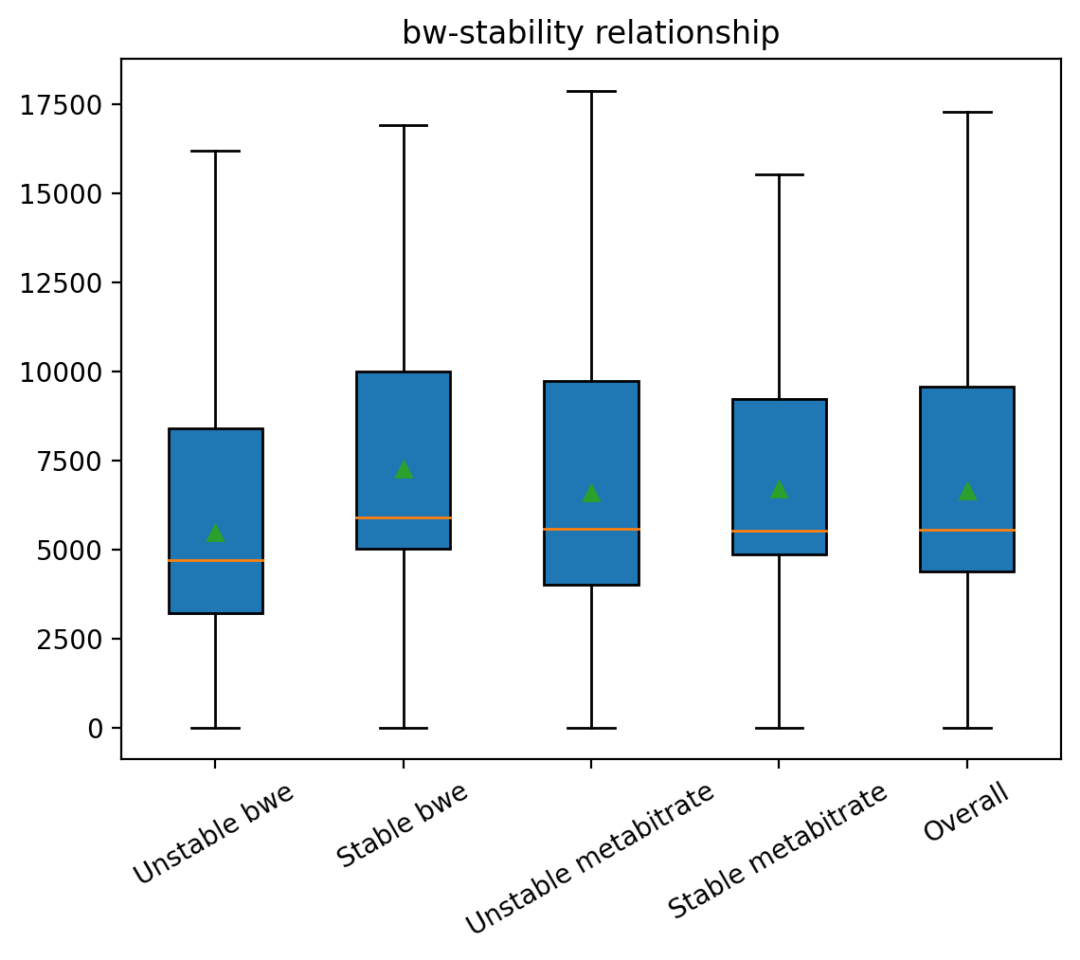
白盒测试复现问题及根因分析
我们选取了 典型的非稳态网络场景进行上述问题复现实验,并对算法内部原理进行分析,发现:
在非弱网比如只是 rtt 较小范围(150 以内)抖动的网络场景下,VolcEngineRTC TCC 带宽估计算法中,delay_based_bwe 部分,trendline estimator 对时延信号太过敏感,经常误判弱网,导致周期性下调估计的带宽值,从而降低了带宽利用率。
具体分析过程如下:
首先是复现问题场景,这里举例2个场景来说明。4Mbps 带宽+时延波动场景(左图)的实验表现和前面线上埋点(5 秒级别)的波动现象吻合,当bwe波动在码表范围内,该测试场景复现了线上 bwe 波动的问题场景;带宽泊松波动场景(右图)周期性波动问题复现更加明显。
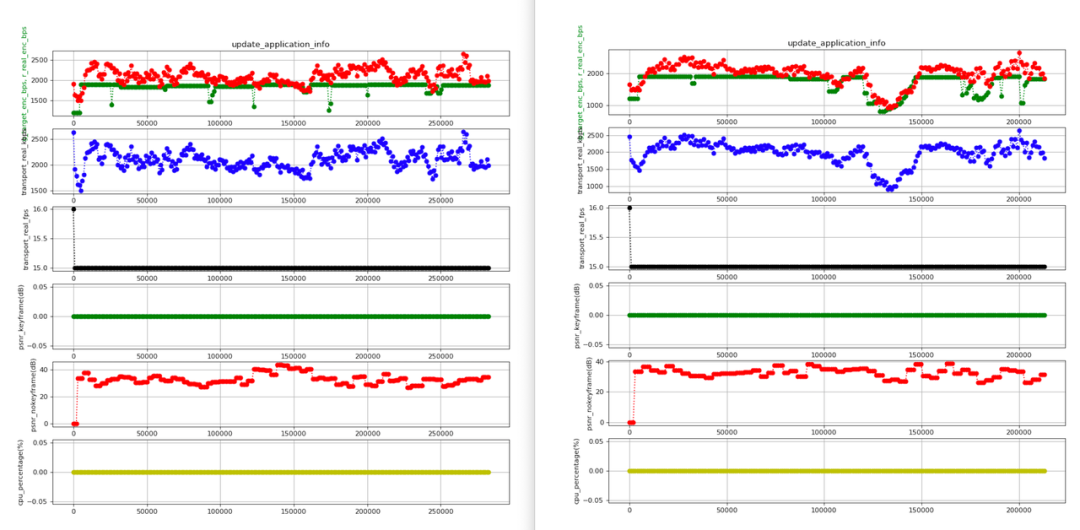
其次,进行问题根因定位。bwe 波动的根因在于算法频繁置位 overuse (左图)来降低所估计的带宽,而 overuse 的判别逻辑在 delay_based_bwe 部分,trendline estimator(基于趋势线的时延估计器)这里把时延抖动误判成了弱网(注:误判是指实际的rtt和丢包情况均不表现为弱网特征,如右图的子图4和子5)。
解决方案
带宽估计算法
1、调优已有 VolcEngineRTC bwe 算法模型参数
无须写代码、等待发版周期,以最快速度缓解问题
我们梳理了 VolcEngineRTC 代码逻辑以及 bwe 算法参数。好处是可以很方便的通过线上配置直接修改做实验,但是缺点是参数太多、调参太耗费精力且很大可能是收益非常有限(理论上参数的默认值应该就是一个推荐的最优值了),最终我们决定先凭借经验挑选了几个关键参数作为一期方案优化,离线验证调参的收益后就开展一期方案线上 AB 实验,期间也为我们留下了相对充足的时间去做后期优化。

2、Beyond VolcEngineRTC bwe 算法,进行线上问题模式检测与 bwe 模型纠正
最小化对 VolcEngineRTC 代码/bwe 算法模型的入侵修改,同时达到解决问题的目的
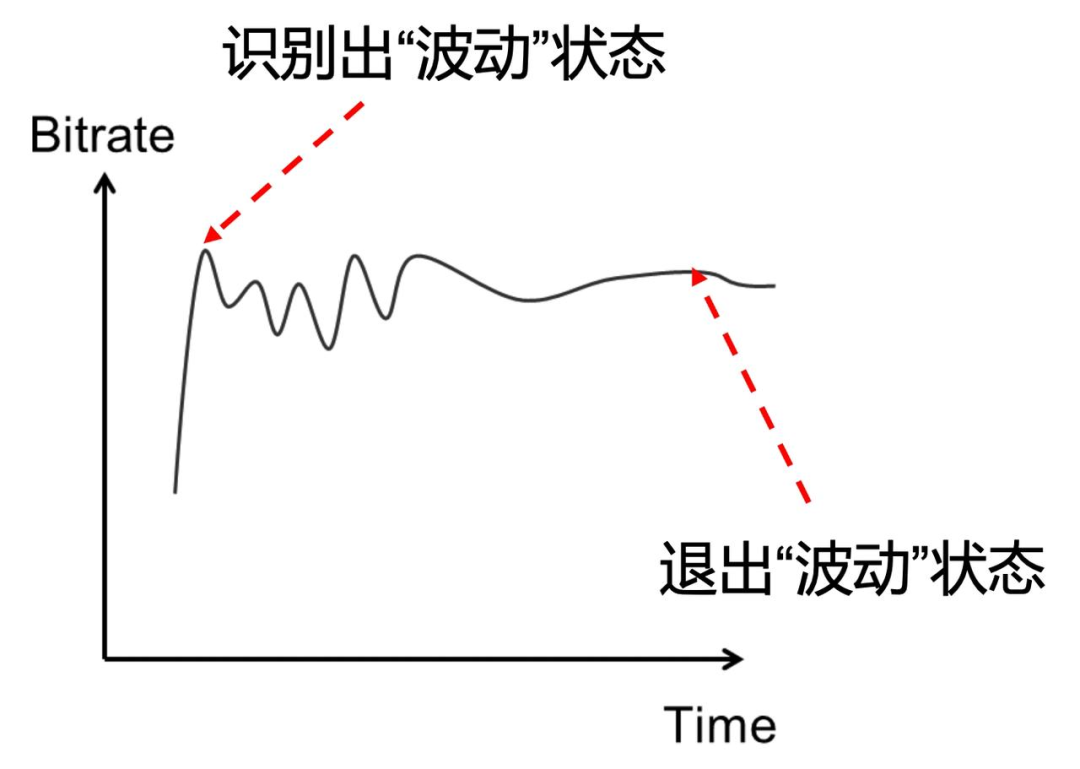
我们在 bwe 算法之上,引入周期性震荡场景识别及平滑策略,以改善带宽估计的准确性、提升带宽利用率,进而提升视频画质。
码控算法
1、解耦码控算法与带宽估计算法
在原来 RTM 推流的架构下,没有单独的码率控制算法,码控的上下界由 LiveCore 的码表决定,在上下界之间如何变化则完全是由 VolcEngineRTC bwe 算法决定。
上述架构存在以下 2 个问题:
A. bwe 算法的问题会直接体现在码控层面,e.g. 前面的问题类型(bwe 震荡波动几乎一定会引起码率震荡波动,进而导致画质问题,e.g. 业务方反馈的推流码率突降导致画面模糊的问题)
B. 码控算法很好地利用了 VolcEngineRTC 弱网感知优势,却忘记了利用 VolcEngineRTC 的强网感知优势,e.g. 当带宽估计值超过码表码率上界时,还可以超越码表上界再进一步提升码率(非中国区码表上界比中国区低很多),从而提升画质。
因此,我们将传输层的 bwe 算法和应用层的码控算法进行了解耦。在 RTM SDK 层面设计实现单独的码控算法,可以更加灵活的根据业务场景/需求设计码控策略。
2、目标码率波动在线识别和平滑策略
与 bwe 算法的震荡波动识别和平滑思路类似,设计在线检测算法识别码率周期性波动并进行码率平滑。码控算法不一定要听从 bwe 算法,因为 bwe 算法也可能误判,此外,非实时通讯的直播场景下,秒级的端到端延时、推流拉流均有buffer情况下,不一定要立即响应带宽的波动,码控算法可以选择性的在清晰度和流畅度(卡顿)之间平衡,根据线上实验用户体验偏好进行迭代。
算法优化离线效果评估
在有限的测试场景下
-
弱网场景
-
bwe 波动识别与平滑方案开启 vs 该方案关闭
bwe 波动识别与平滑方案对 bw、rtt 抖动场景的 bwe 进行了有效的平滑,特别是 rtt jitter 场景下有效去除了部分不必要的码率下调,有约 10% 的码率收益; -
码控码率波动识别与平滑开启 vs 该方案关闭 码控优化点 2 即使在 bwe 波动识别与平滑方案关闭的情况下也可平滑一定的网络震荡(特别是 bwe 波动场景下);码控优化方案整体在强网下 PSNR 有约 6% 的收益(720p); -
bwe 波动识别与平滑方案叠加码率波动识别与平滑效果
-
两者无冲突,在带宽剧烈波动场景下叠加生效有带宽利用收益;
-
强网场景 -
相比对照组无负向效果,以上实验中拉流侧均未出现卡顿。
-
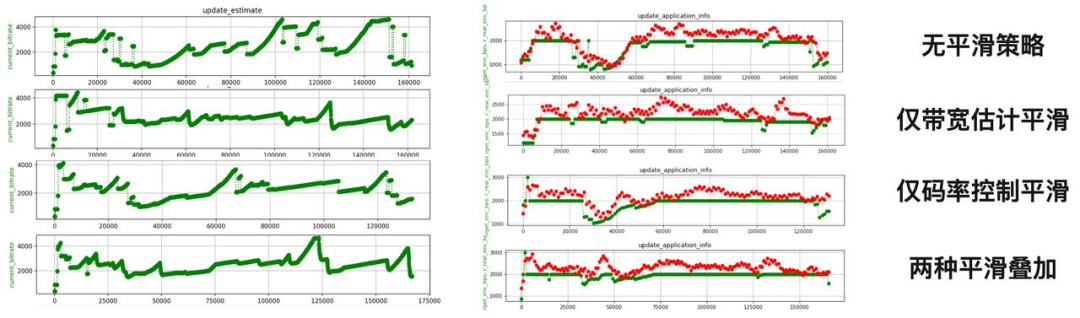
综上,在有限测试场景下,bwe 波动识别与平滑方案在 rtt jitter 场景有更明显的码率收益,而码率波动识别与平滑方案在 bwe jitter 场景有明显的画质收益,两者叠加在两种场景下均有较好的码率收益。
优化结果
目前为止,我们的 RTM 方案在抖音已经落地以及完成放量,在抖音的指标收益主要在主播人均被看播时长/被关注/被评论显著正向,拉流音频/视频卡顿 -22.2%/-7.8%,端到端延迟 -1.6%。
未来展望
目前 RTM 推流在抖音秀场完成了 10% 左右的常规放量,但 RTM 推流的效果远远没有达到最佳状态,仍有很多优化工作需要推进。
从工程优化角度,下一步工作考虑以下几方面:
-
更多家 CDN 的支持,目前只有三家 CDN 完成了接入和灰度放量,覆盖率还需要提高; -
目前 RTM 推流和 CDN 服务端交换 SDP 使用的是 HTTP/HTTPS 信令,在网络较差的情况下有一定的失败率,使用数据压缩、基于 UDP 的 MiniSDP 信令,可以提升推流建立连接的成功率; -
在 RTT 很高、丢包率较低的弱网场景,使用 FEC 的效率要比重传更高,预期可以进一步提升弱网抗性; -
目前 RTM 推流的 CPU 占用是比 RTMP 要高一点的,而且 RTMP 推流本身功耗也是比较高的,所以性能功耗方面也需要做一些优化,改进主播的开播耗电和发热体验;
从算法优化和创新角度,我们考虑以下几点:
-
虽然通过这次优化我们解决了 VolcEngineRTC 的 bwe 算法在一些场景下的问题,但是在另一些场景下相比 RTMP over TCP 方案,RTM 并不拥有绝对优势。未来还要继续努力针对这些场景进行优化,进一步提高网络带宽的利用率以及弱网抗性,从而提升 bwe 算法的核心竞争力; -
RTM 码控算法方面,颠覆现有/传统的只以码率为锚的控制方式,面向最小化码率最大化画质体验做策略控制,向体验和成本极致优化方向演进; -
目前看到工业界宣传文章中有类似 RTM 推流的技术在应用,但在多媒体和网络领域的顶级会议上较少看到相关创新算法的文献,未来考虑将我们的更多创新技术转化成论文的形式,弥补学术界空白,提升公司在多媒体和网络领域的影响力; -
RTM 的码控算法优化思路,在 RTMP over QUIC 的场景也是适用的,后续我们会把码控算法和传输协议代码进行解耦,以便码控算法的优化也能在 RTMP over QUIC 场景落地,并通过 AB 实验探索不同传输协议各自更适用的场景。
作者:林可、刘静
来源:字节跳动技术团队
原文:https://mp.weixin.qq.com/s/-dwJfBiBC5R9zJNK0xiBUw
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。