
本文将分享如何设计并实现一个支持高并发、可水平扩展的在线直播编辑系统,涵盖服务发现、任务调度、流媒体处理等核心技术。
来源:公众号”流媒体技术”
作者:大师兄悟空
一、业务背景与挑战
1.1 业务场景
在视频直播领域,我们经常面临这样的需求:
- 实时转码:将主播推流实时转换为多种清晰度(720p/1080p)
- 实时截图:定时生成直播封面,用于内容审核和推荐
- HLS 切片:生成适配移动端和Web端的播放流
- 任务调度:合理分配处理任务到多台服务器
1.2 技术挑战
| 挑战 | 说明 |
| 高并发 | 同时处理数百路直播流 |
| 低延迟 | 端到端延迟控制在3-5秒内 |
| 高可用 | 单点故障不影响整体服务 |
| 弹性扩展 | 根据负载动态增减处理节点 |
| 状态同步 | 多节点间任务状态一致性 |
二、系统架构设计
2.1 整体架构
我们采用 Manager-Worker 架构模式,结合 Consul 实现服务发现。


2.2 核心组件选型
| 组件 | 选型 | 理由 |
| 开发语言 | Go 1.21 | 高并发、编译型、部署简单 |
| 服务发现 | Consul | 成熟稳定、健康检查完善 |
| 流媒体服务 | SRS | 开源、性能优秀、社区活跃 |
| 视频处理 | FFmpeg | 行业标准、功能全面 |
| 数据库 | MySQL | 事务支持、运维成熟 |
三、关键设计决策
3.1 为什么采用 Manager-Worker 模式?
传统单体架构的问题:
- 所有功能耦合在一起,维护困难
- 无法针对转码服务单独扩容
- 单点故障导致整体不可用
Manager-Worker 的优势:
// Manager 专注于任务调度
func (m *Manager) DispatchTask(task *Task) (*Worker, error) {
// 1. 从 Consul 获取健康 Worker 列表
workers := m.consul.GetHealthyWorkers()
// 2. 根据负载选择最优 Worker
selected := m.selectByLoad(workers)
// 3. 下发任务
return selected.Assign(task)
}
// Worker 专注于流处理
func (w *Worker) ProcessStream(stream *Stream) error {
// 1. 启动 SRS 接收推流
w.srs.Start(stream.Key)
// 2. 启动 FFmpeg 转码
w.ffmpeg.Transcode(stream)
// 3. 定时截图
w.startSnapshot(stream)
}3.2 服务发现机制设计

Consul 服务注册模型:
// 服务注册信息
type ServiceInfo struct {
Name string `json:"name"` // OLED/manager 或 OLED/worker
Addr string `json:"addr"` // 服务地址
Tags []string `json:"tags"` // ["manager"] 或 ["worker"]
Health struct {
Interval string `json:"interval"` // 健康检查间隔
Timeout string `json:"timeout"` // 超时时间
} `json:"health"`
Update int `json:"update"` // 负载信息更新间隔
}
// Worker 上报的元数据
meta := map[string]string{
"port": "8009",
"das_port": "1935", // RTMP 端口
"das_api": "1985", // SRS API 端口
"das_server": "8080", // HLS 服务端口
"cpu_usage": "45%", // CPU 使用率
"mem_usage": "60%", // 内存使用率
"task_count": "12", // 当前任务数
}3.3 任务调度策略

负载均衡算法:
// 选择最优 Worker
func (m *Manager) selectOptimalWorker(workers []*Worker) *Worker {
var selected *Worker
minScore := math.MaxFloat64
for _, w := range workers {
// 综合评分 = CPU权重 * CPU使用率 + 内存权重 * 内存使用率 + 任务权重 * 任务数
score := 0.4*w.CPUUsage + 0.3*w.MemUsage + 0.3*float64(w.TaskCount)
if score < minScore {
minScore = score
selected = w
}
}
return selected
}四、核心实现细节
4.1 启动流程
func main() {
// 1. 加载配置
config := LoadConfig("./conf/manager.json")
// 2. 初始化日志
InitLogger(config.Logger)
// 3. 连接 Consul(Worker 必须,Manager 可选)
client, err := NewConsulClient(config.Consul)
if err != nil && config.Mode == "worker" {
log.Fatal("Worker 必须连接 Consul")
}
// 4. 注册服务
service := client.RegisterService(config)
// 5. 初始化数据库
db := InitMySQL(config.DB)
// 6. 启动 SRS 流媒体服务
go StartSRS(config.DAS)
// 7. 恢复未完成的任务(故障恢复)
go RecoverUnfinishedTasks(db)
// 8. 启动 HTTP API 服务
StartHTTPServer(config.Port)
}4.2 流媒体处理流水线

HLS 切片流程:
- 推流端(OBS)通过 RTMP 向 SRS 推流
- SRS 触发 on_publish 回调通知 Worker
- SRS 生成 TS 切片,触发 on_hls 回调
- Worker 更新 m3u8 播放列表并保存到存储
// HLS 回调处理
func HLSHandler(w http.ResponseWriter, r *http.Request) {
var hlsInfo struct {
StreamKey string `json:"stream"`
FilePath string `json:"file"`
Duration float64 `json:"duration"`
}
json.NewDecoder(r.Body).Decode(&hlsInfo)
// 1. 更新 m3u8 播放列表
playlist.Update(hlsInfo)
// 2. 记录切片信息到数据库
db.SaveSegment(hlsInfo)
// 3. 触发截图任务(每 N 个切片)
if shouldSnapshot(hlsInfo) {
go ffmpeg.Snapshot(hlsInfo.StreamKey)
}
w.WriteHeader(http.StatusOK)
}4.3 故障恢复机制

场景:Worker 节点宕机
// Manager 检测到 Worker 失联
func (m *Manager) OnWorkerOffline(workerID string) {
// 1. 获取该 Worker 上的所有任务
tasks := m.db.GetTasksByWorker(workerID)
// 2. 重新调度这些任务
for _, task := range tasks {
// 2.1 选择新的 Worker
newWorker := m.selectOptimalWorker(m.getHealthyWorkers())
// 2.2 迁移任务
err := newWorker.MigrateTask(task)
if err != nil {
// 2.3 标记任务失败,等待人工介入
m.db.MarkTaskFailed(task.ID, err)
continue
}
// 2.4 更新数据库
m.db.UpdateTaskWorker(task.ID, newWorker.ID)
}
}五、性能优化实践
5.1 连接池优化
// MySQL 连接池配置
db.SetMaxOpenConns(100) // 最大连接数
db.SetMaxIdleConns(20) // 空闲连接数
db.SetConnMaxLifetime(time.Hour) // 连接最大生命周期
// HTTP 客户端连接池
transport := &http.Transport{
MaxIdleConns: 100,
MaxIdleConnsPerHost: 10,
IdleConnTimeout: 90 * time.Second,
}5.2 异步处理
// 异步启动截图任务
func (w *Worker) startSnapshot(stream *Stream) {
ticker := time.NewTicker(time.Duration(config.SnapInterval) * time.Second)
defer ticker.Stop()
for {
select {
case <-ticker.C:
// 异步执行,不阻塞主流程
go func() {
if err := w.ffmpeg.Snapshot(stream); err != nil {
log.Printf("截图失败: %v", err)
}
}()
case <-stream.Done:
return
}
}
}5.3 内存优化
// 使用对象池复用缓冲区
var bufferPool = sync.Pool{
New: func() interface{} {
return make([]byte, 32*1024) // 32KB
},
}
func processStream(stream io.Reader) {
buf := bufferPool.Get().([]byte)
defer bufferPool.Put(buf)
// 使用缓冲区处理数据
io.CopyBuffer(dst, stream, buf)
}六、监控与运维
6.1 关键指标
| 指标 | 采集方式 | 告警阈值 |
| 在线流数量 | 定时查询数据库 | > 500 |
| Worker 负载 | Consul 元数据 | CPU > 80% |
| HLS 延迟 | 切片时间戳差值 | > 10s |
| 任务失败率 | 失败数/总数 | > 5% |
| API 响应时间 | HTTP 中间件 | P99 > 500ms |
6.2 日志规范
// 结构化日志
logger.Info("task_created",
zap.String("task_id", task.ID),
zap.String("stream_key", task.StreamKey),
zap.String("worker", worker.ID),
zap.Duration("elapsed", time.Since(start)),
)
// 日志轮转配置
{
"rotate": {
"enabled": true,
"daily": true,
"max_days": 7,
"max_files": 7,
"max_lines": 100000
}
}七、开发环境搭建
使用河图大模型开分析架构设计与实现关键点,剩下的就是不断聊天完善了。河图大模型目前可以在cursor和vscode中用起来了。然后用hetu模型开发就可以了,先看一下大概得效果:
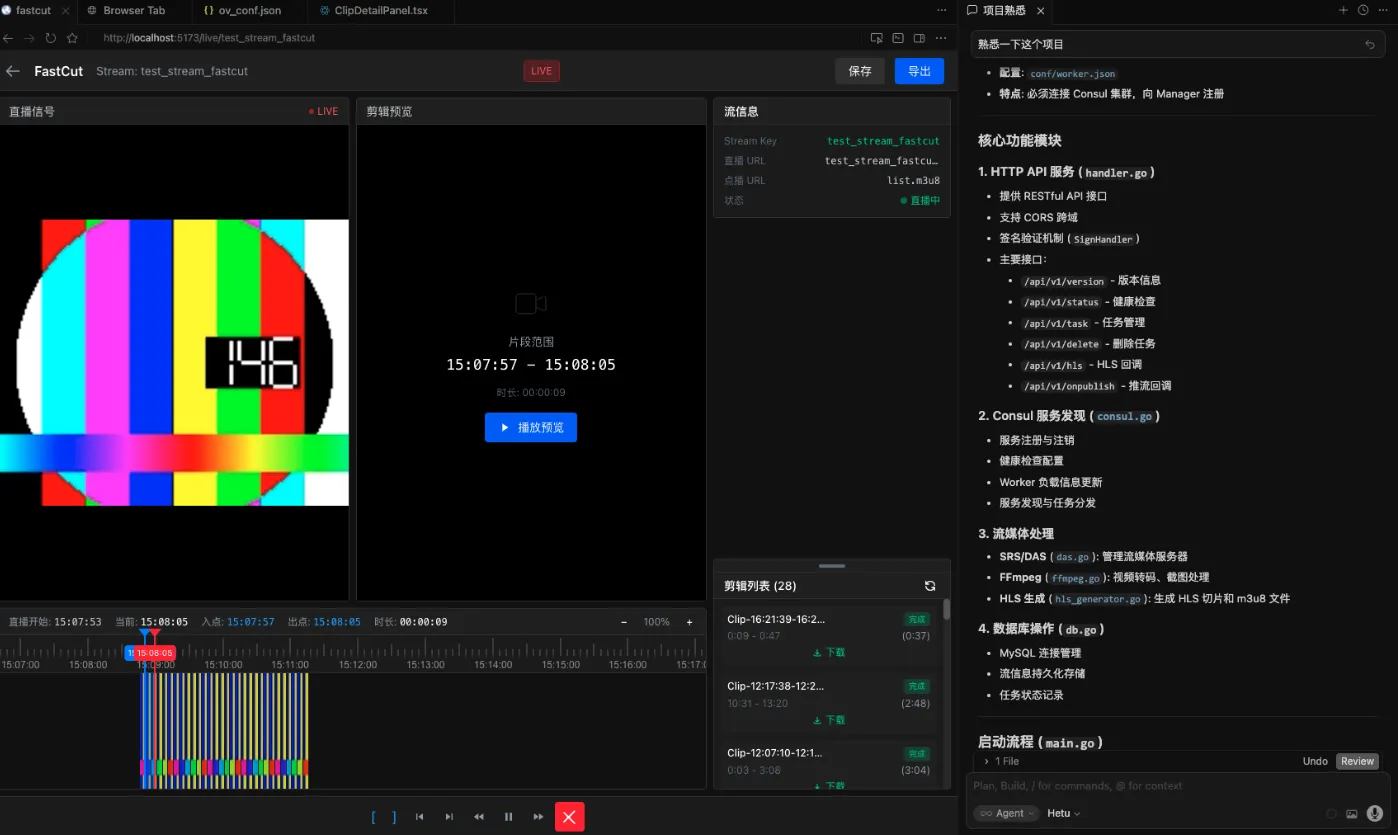
这个功能我自己没有手写一行代码,都是VibeCoding写的,我是基于河图开发的,河图是我们小伙伴们一块搞的一个模型聚合平台,主要是为了使用方便,特别适合个人开发者使用,推荐大伙试一试(https://www.libav.cn)。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。