
日前,火山语音团队七篇论文成功入选国际顶会Interspeech2022,内容涵盖音频合成、音频理解等多个技术方向的创新突破。Interspeech作为国际语音通信协会ISCA组织的语音研究领域的顶级会议之一,也被称为全球最大的综合性语音信号处理盛会,在世界范围内享有极高声誉,并受到全球各地语言领域人士的广泛关注。下面我们就入选论文进行全面解读,一同了解火山语音技术的重要进展吧!
音频合成方向——
针对语音合成有声书的自动化配乐系统
An Automatic Soundtracking System for Text-to-Speech Audiobooks
通常在有声小说中,适宜的背景音乐可以大幅提升听感,增强用户的沉浸式体验。该论文首创性提出了基于篇章级情节理解的有声小说配乐系统,能够自动化地挑选并组合出贴合文章情节、烘托感情氛围的背景音乐,同时与语音合成的有声小说音频进行精准的时间戳对齐和混音,极大节省了后期配乐的人力投入。
具体来说该系统可以分为情节划分(Plot Partition)、情节分类(Plot Classification) 和 音乐选择(Novel Selection) 三个部分。前两部分主要通过NLP技术实现了篇章级语意理解,能够自动将小说文本进行片段式的情节划分,做到预测多达十二类的情节;第三部分则实现了基于语意及小说音频长度的启发式规则,自动化地从音乐库中选择合适的音乐片段并与小说音频进行自动混音。该系统在与人工配乐的对比实验中,目前的合格率已追平人工水平(均为88.75%);优秀率也高达45%,但对比人工 52.5%的数据指标还略有差距。


有声小说自动化配乐系统框架
在语音合成有声小说的场景和业务中,自动化精配背景音乐的加入不仅能够大幅度提升用户的听觉感受和代入感,还极大降低了音频后期的人力投入成本。目前,自动化精配背景音乐已经在番茄小说等业务中开始应用。
一种借助声学参考特征和对比学习的高品质歌唱转换方法
TOWARDS HIGH-FIDELITY SINGING VOICE CONVERSION WITH ACOUSTIC REFERENCE AND CONTRASTIVE PREDICTIVE CODING
近年来伴随语音后验概率(Phonetic PosteriorGrams,PPG)特征的广泛使用,语音转换效果取得了显著提升,但PPG特征在声学信息上的缺失导致了在风格和自然度方面的转换效果并不尽如人意,尤其对于「歌唱」这种对声学表现力极高要求的场景。
基于上述考量,本篇论文在端到端歌唱转换模型的基础上,一方面尝试使用了梅尔谱、无监督声学表征和语音识别模型中间层表征等多种附加特征来补足歌唱转换模型对声学信息的需求,同时确保音色效果不受影响,最终通过对比明确了无监督声学表征的效果优势。
另一方面,针对转换模型的编码器输出结果,团队选择增加一个对比预测编码(Contrastive Predictive Coding,CPC)模块以提高编码结果的连贯性,增强模型对声学信息的建模能力。通过与基础模型的主观评测对比,团队提出的优化方案获得了明显收益,主观评测MOS分提升了0.18;同时该方法也被证明可以提升语音音色的歌唱能力,音准客观指标提升了6%,达到较好的跨域转换效果。
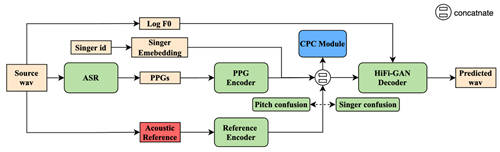
结合附加声学特征和CPC模块的歌唱转换系统框架
如今语音转换和歌唱转换已在视频和歌曲创作方面有相关的应用,而论文提出的方法可以进一步提升直播场景以及视频创作中的语音转换和歌唱转换的自然度,提升用户体验的同时降低创作门槛。
音频理解方向——
结合对话上下文的流式 RNN-T 语音识别
Bring dialogue-context into RNN-T for streaming ASR
日常生活中,人们说出的语音内容通常与所处的上下文(context)相关,而在对话任务中,凭借历史轮次的对话文本所包含的与当前句有关的信息,可以提升语音识别效果。基于此,该论文提出将对话历史作为 context 输入到流式RNN-T模型中,总结出几种不同的引入对话历史的方法和训练策略,最终获得了比单句 ASR 提升5%+的识别效果。
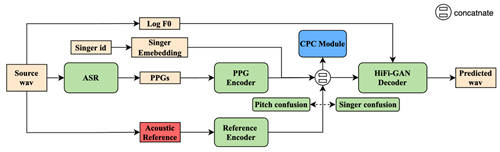
(a)基础 RNN-T 结构 (b)引入对话历史到 predictor 的结构 (c)引入对话历史到 encoder 的结构
首先针对 RNN-T的结构特点,论文提出将对话历史更早地引入到 RNN-T 的 predictor(上图(b)) 和 encoder(上图(c)),从而可以更充分地将对话历史信息融入到 RNN-T 模型中。其次论文提出了两种训练策略:有/无对话历史输入模型的联合训练(joint training)和对话历史添加随机扰动(context perturbation)。Joint training 策略降低了模型在对话历史缺失情况下的性能损失,而 context perturbation 则解决了对话历史含有的识别错误对 context-aware ASR 模型的干扰。最后论文通过在神经网络语言模型(neural network language model,NNLM)中引入对话历史,来获得更好的语言模型,并用于 beam-search 解码,进一步提升识别效果。
在 Switchboard-2000h 的公开数据中,采用论文方法引入对话历史,将基于RNN-T的语音识别系统的性能在两个测试集上相对提升了4.8% / 6.0%(无语言模型的情况下) 和 10.6% / 7.8%(有语言模型的情况下)。
基于连续整合发放机制的融合说话人差异和语音内容的字级别说话人转换点检测
Token-level Speaker Change Detection Using Speaker Difference and SpeechContent via Continuous Integrate-and-fire
说话人转换点检测(Speaker Change Detection, SCD)任务常常作为说话人分聚类子任务或者语音识别(Automatic Speech Recognition,ASR)模型的前端模块被研究者人员所了解。目前该领域提出的大部分解决方案都只应用了说话人特征的差异,而忽略了语音内容可以在SCD任务中发挥作用这一方向。
基于此,火山语音团队提出一种综合考虑“说话人差异”与“语音内容”两条线索的说话人转换点检测方法,主要通过连续整合发放机制(Continuous Integrate-and-fire,CIF)来达成。目前该方式能够获取到字级别的说话人差异和语音内容,在同样的表示粒度上融合了两部分线索之后,就可以在字的声学边界处成功进行说话人转换点的判断。
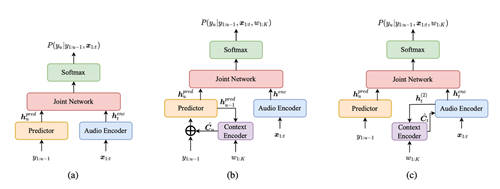
基于 CIF 的融合两条线索的字级别说话人转换点检测方案
在真实录制的会议数据集AISHELL-4上,基于该方法提出的方案相比于目前比较有竞争力的基线方法,获得了绝对2.45%的等纯度覆盖度(Equal Purity Coverage,EPC)提升。
同时也通过实验证明“说话人差异”与“语音内容”都能作为说话人转换点判断的线索使用,而且同时使用两条线索才是目前最优的方案。此外,该方法所提出的在字符的声学边界处进行说话人转换点检测,相比于逐帧进行检测更具优势,做到直接处理多说话人的语音并输出字序列以及说话人转换的位置。应用场景上,适用于多人参与且快速交替对话的场景,例如会议等语音场景。
注意机制编解码器端到端语音识别模型中基于上下文矢量学习的内部语言模型估计
Internal Language Model Estimation Through Explicit Context Vector Learning for Attention-based Encoder-decoder ASR (https://arxiv.org/abs/2201.11627)
目前,端到端语音识别模型建模已经成为语音界主流建模方法,其显著优点在于建模操作简单、所建模型性能突出且致密,即无需对字典、声学模型和语言模型单独建模,而是将三者合而为一。换言之,端到端语音识别模型既具有声学模型功能,又具有语言模型功能。
但这种致密性在一定条件下会给模型的适用性和灵活性带来不利影响。譬如端到端识别模型和语言模型之间的融合不再满足传统的贝叶斯后验概率原理,而是一个后验概率和条件概率的相加。当具备这样的条件,如更多的文本语料以及将模型自适应到某一特定领域识别的时候,传统的端到端识别模型和语言模型的融合只能带来次优的结果,使模型优越性不能得到充分发挥。
对于此,论文基于贝叶斯后验概率原理,将端到端估计的后验概率拆解成似然概率和“内部语言模型”概率乘积形式,目标是更好地估计“内部语言模型”,从而让模型更高效地与外部语言模型融合,进而提出两个“内部语言模型”的估计方法,分别是一次性静态上下文矢量学习方法以及基于轻量级神经网络动态上下文矢量学习方法,两种估计方法无需任何额外假设,在多种语料以及多种环境下验证了提出方法的有效性。在跨域条件下相对传统的语言模型融合方法,我们提出的方法能取得19.05% 相对正向收益; 在域内条件下,新方法也能取得7.4%的正向收益。
使用原始序列流利度特征提升口语流利度打分性能
Using Fluency Representation Learned from Sequential Raw Features for Improving Non-native Fluency Scoring
对于英语口语学习者而言,除了发音标准之外,流利程度也可以在某种程度上反映学习者的英语水平。作为评价学习者英语能力的重要维度之一,口语流利度主要反映了学习者发音语速的快慢以及是否出现异常停顿等发音现象。
对此火山语音团队提出了一种基于原始序列特征的英语口语流利度建模方法,利用原始序列特征来替换传统的手工设计特征,如语速,停顿次数等,即在音素层级提取出音素时长以及声学特征并对其进行建模;此外还将静音作为一种特殊音素,用于表征词和词之间的停顿现象。
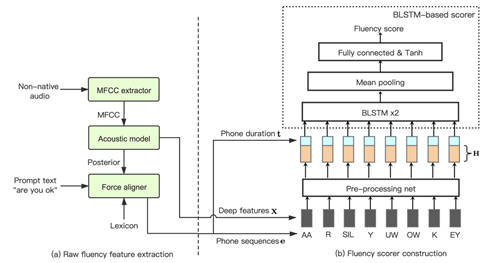
a. 原始序列特征提取 b. 流利度建模
这种基于原始特征序列建模方法超过了领域内其他方案, 在机器预测结果和人类专家打分之间相关性达了0.817,接近专家和专家之间的相关性 0.831。该方案将原始时长、停顿和声学信息融合到一个序列建模框架中,让机器自动去学习和任务相关的流利度特征,更好用于流利度打分。应用场景方面,该方法可被应用于有流利度自动评估的需求场景中,例如口语考试以及各种在线口语练习等。
基于多任务和迁移学习方法的MOS自动打分
A Multi-Task and Transfer Learning based Approach for MOS Prediction
语音质量是反映语音合成(Text-To-Speech, TTS)、语音转换(Voice Conversion, VC)等系统性能的主要指标;而MOS(Mean Opinion Score)则是标注人员对合成音频进行听力测试后,针对该音频的语音质量进行的主观评价分数。在Interspeech 2022语音质量打分挑战(VoiceMOS)中,火山语音团队在主领域赛道斩获第四名。
针对两种领域赛道,火山语音团队提出了一种多任务学习方法,利用较多的主领域数据来协助子领域部分模块训练,同时将自动语音识别(Automatic Speech Recognition, ASR)的知识迁移到MOS打分任务。在wav2vec2.0上构建ASR系统,然后将系统wav2vec2.0部分作为MOS打分模型的编码器,通过两种不同领域的解码器来对不同领域的数据进行MOS评分。
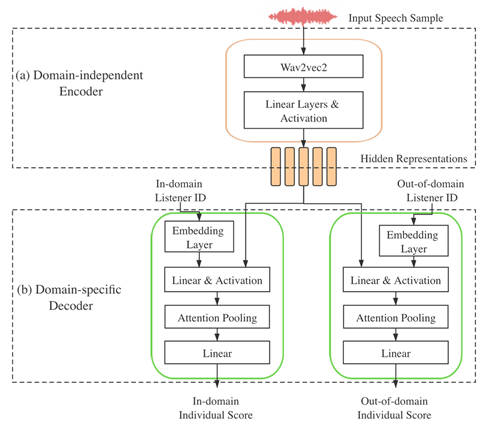
多任务的MOS打分结构
针对不同语音转换(VC)系统的合成音频打分任务,上述方案在主领域测试集上,SRCC指标和该比赛中最好的方案相差0.3%;在子领域测试集上,SRCC指标与该比赛中最好的方案相差0.2%。MOS自动打分的目标是利用机器对合成音频自动打分来替换掉标注人员的人工评分,节约大量人力物力,达到省时省钱的效果,这对于推进语音合成(TTS)和语音转换(VC)的技术发展具有重要意义。
关于火山语音团队
火山语音,字节跳动 AI Lab Speech & Audio 智能语音与音频团队。一直以来面向字节跳动内部各业务线以及火山引擎ToB行业与创新场景,提供全球领先的语音AI技术能力以及卓越的全栈语音产品解决方案。自 2017 年成立以来,团队专注研发行业领先的 AI 智能语音技术,不断探索AI 与业务场景的高效结合,以实现更大的用户价值。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。