
本文提出了一种基于运动感知神经体素的快速三维头像重建方法 ManVata。ManVata是第一个将表情动作与标准外观解耦的头部模型,并用神经体素对表情动作进行建模。在给定单目视频的情况下,该方法可以在5分钟内恢复出照片级真实感的头像。受先前动态 NeRF 重建方法的启发,将基于NeRF的头部化身重建中的复杂表情相关运动与规范外观解耦。对于外观和运动场,进一步采用了有效的基于体素的表示,同时解耦运动和外观。利用 3DMM 表达式库提供的先验信息来建模与表达式相关的运动,从而可以使用小型 MLP 和体素网格来重建详细的运动。
来源:Arxiv
论文链接:https://arxiv.org/abs/2211.13206
项目链接:https://www.liuyebin.com/manvatar/ manvatar.html
作者:Yuelang Xu, Lizhen Wang, Xiaochen Zhao, Hongwen Zhang, Yebin Liu
内容整理:王睿妍
引入
人脸再现和基于单目视频的头像重建是近年来的研究热点,在 VR/AR、数字人体、全息通信、网络直播等领域有着非常广阔的应用前景,但目前的方法不能在几分钟内重建出3D头像,这已经成为限制其应用的主要因素。
人像视频合成
近来人们提出了大量的人像视频合成方法。最早的方法跟踪重建带有表情的纹理脸部网格,然后将其重新渲染为具有所需表情的合成肖像图像。嘴巴、头发和背景等区域需要稍后混合,这些方法依赖于精确的跟踪方法、高质量的重建网格模型和真实感绘制技术等,严重限制了其广泛的应用。基于 Warping 的方法将 2D 运动流图建模为表情传递的常用表示,但无法处理极端的头部姿势或表情。最近的一些方法将 2D 运动流图提升到 3D 空间,在一定程度上克服此类问题的伪影。
单目三维头像重建
从单目视频中重建三维头部形象是一项具有挑战性的任务。一方面,现有的跟踪方法难以准确捕捉与表情相关的复杂动态运动。另一方面,头发和皱纹的详细几何形状不能完全恢复。
挑战
首先,现有的方法无法在几分钟内重建三维头部虚拟形象,成为应用的主要限制。其次由于人脸的运动比较复杂,通常不可避免地需要一个深度 MLP 来模拟复杂的运动。因此在模型训练过程中, MLP 需要更长的时间才能收敛。
贡献
- 第一种基于 NeRF 的将复杂的表情条件运动与静态外观解耦的头部重建方法。
- 建模表情相关运动的运动感知神经体素表示。
- 使用单眼肖像视频实现5分钟 3D 头部化身重建。
具体实现
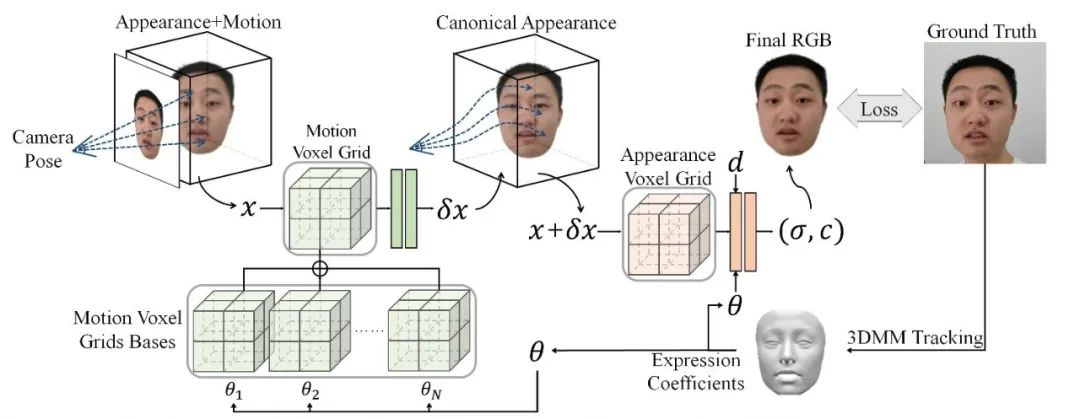

如上图所示,ManVatar 可以从单眼肖像视频重建出头部化身模型。在数据预处理阶段先执行 3DMM 跟踪,从肖像视频中获得表情系数和头部姿态并将其用作输入。在表情相关的训练阶段,我们首先建立运动体素网格(MVG)和2层 MLP 来表示表情相关的 3D 运动,MVG 的基与 3DMM 表达式的基共用相同的维度,且相同的表达式系数可以用作连接 MVG 基的权重。在外观重建的训练阶段引入外观体素网格和另一个2层 MLP 来表示目标基本外观。具体而言,给定输入坐标x,然后通过 MVG 将其转换为 x+δx ,并在外观体素网格中使用 MLP 和查询点 x+δx ,以获得其密度和颜色,最后在渲染的肖像图像和相应的地面真实帧之间施加一致性约束。
模型表示
将 Φ(·) 定义为与表情无关的NeRF,并另外引入了与表达式相关的变形 Ω(·),其可公式化为:
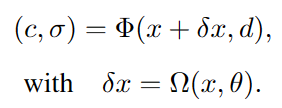
其中,Φ(·) 表示静态 NeRF,其参数中不包含 θ。由于参数的自由度大大降低,训练速度可以显著提高。
表情运动
为了充分利用 3DMM 的表达先验性和神经体素的表达能力,我们以表达系数为权值,将多个运动体素网格(Motion Voxel Grid, MVG)基串联成一个完整的MVG来表示表情运动。具体来说,MVG 基的每个维数都使用相同的表达式系数 θ∈RN作为相应的 3DMM 表达式基,其中 N 为 3DMM 表达式基的维数。从另一个角度来看,MVG 基可以被认为是头部运动的“神经”表达基,它能够在更广泛的范围内(包括耳朵和头发区域)呈现更详细的运动。该过程可以表述为:

规范外观
由于我们将外观Φ(·)建模为静态 NeRF,因此我们仅使用单个外观体素网格Va和两层MLP(Fa)直接表示规范外观,显式外观体素网格Va包含每个体素特征中的外观信息,而两层 MLP 网络 Fa将采样特征转换为颜色和密度。具体而言,对于每个查询点 x,其对应的特征向量va首先通过多距离插值从外观体素网格Va采样,然后将该特征向量与视图方向d一起输入到2层MLP Fa中,以预测颜色和密度:![]()
![]() 下图是将学习到的规范静态外观和表情运动可视化:
下图是将学习到的规范静态外观和表情运动可视化:

损失函数
![]()
![]()
其中 R 表示批次中的采样射线,Igt 表示预处理的地面真实图像,T(r) 表示射线 r 上采样点的距离,λ 表示正则项的权重。
实验
渲染结果比较
文中定性比较了 ManVatar 和其他两种基于 NeRF 的方法的训练速度:NeRFBlendShape 和 NeRFace。ManVatar训练每个模型可以在在5秒、15秒、30秒、1分钟、2分钟渲染相应的图像,在前2分钟内几乎达到了完全收敛。NeRFBlendshape 的方法需要20分钟收敛,在实验中发现 NeRFace 实际上需要几个小时才能收敛。具体比较结果如下:
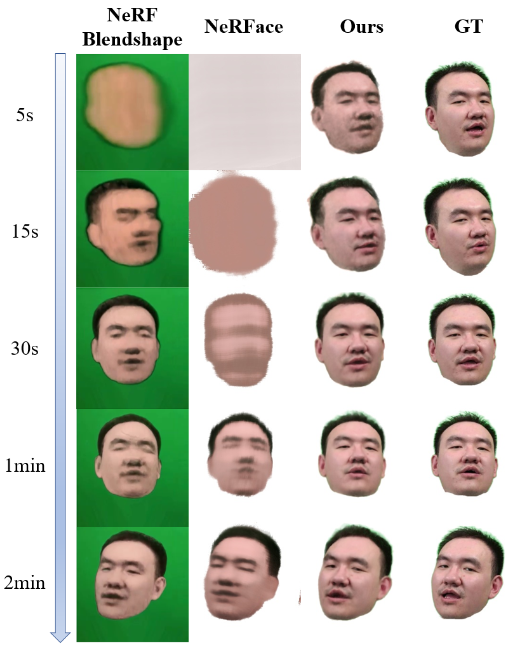
自动画任务的定性比较如下图所示。实验结果表明,ManVatar在训练时间较其他方法短的情况下获得了最高的渲染质量。

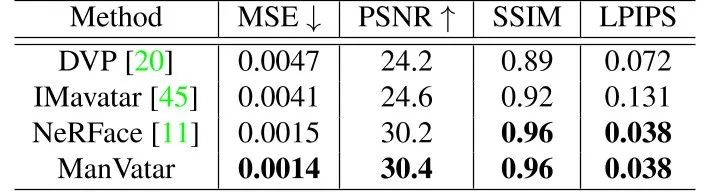
ManVatar 的量化评价结果如下表所示。我们评估四个指标:MSE,PSNR,SSIM和LPIPS。从表中结果可以看出:ManVatar 在 MSE 和 PSNR 指标上取得了最好的结果,在 SSIM 和 LPIPS 指标上的结果与 NeRFace 相当。
限制
文中指出虽然 ManVatar 将基于 NeRF 头部头像的训练速度加速到瞬间,但渲染质量并没有显著提高,通过分析认为这一问题是由于数据预处理中的拟合误差造成的,即通过拟合人脸模板得到的相机姿态和表情系数不够准确。此外 ManVatar 只能处理人类头部,无法重建颈部、上半身和长发等其他区域。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。