
本文介绍了将 QUIC 技术进行大规模部署的技术分享,主讲人介绍网络传输中的部分问题,例如负载平衡,黑洞效应导致的用户中断时间长体验不佳,面对高负载发生传染性错误时服务器前端大量崩溃等。主讲人介绍了部署在大规模任务上的 QUIC 如何解决这些问题,并且具备哪些优势。
来源:IETF 115 Technology Deep Dive: QUIC Part 2
主讲人:Ian Swett, Martin Duke
内容整理:陈梓煜
QUIC 负载平衡
下图展示了我们正在讨论的一种情况,有一个任播(Anycast)地址,在这个例子中,使用具有一定智能性且响应和感知非常快的 L4 负载平衡器。我们将其发送到一个 L7 的服务器上,这个服务器可以是一个应用的前端或者是另外一个负载平衡器的某一层。
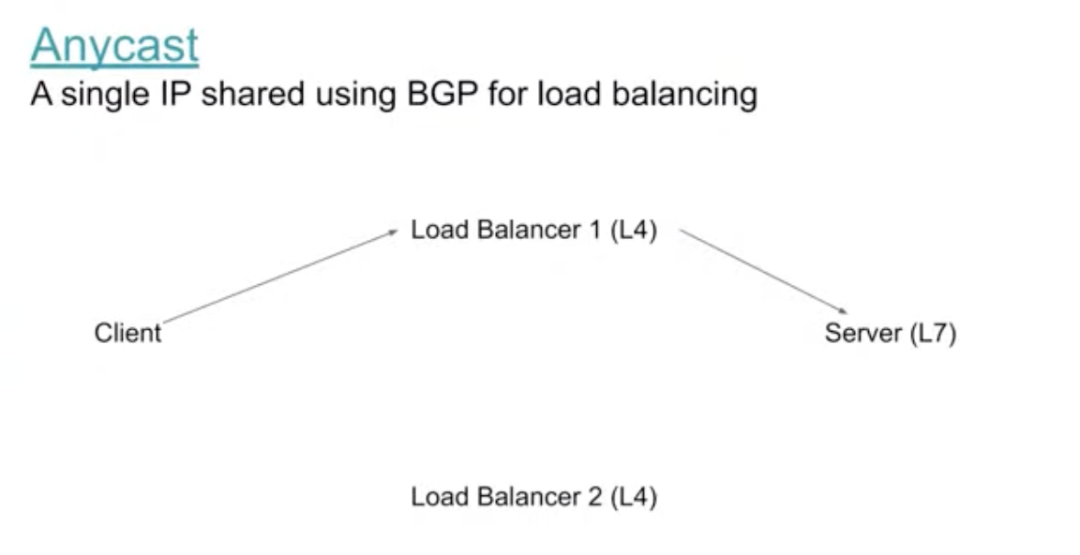

此时如果产生了一个抖动或者发生了网络的切换,会结束于另外一个负载平衡器。在实际情况中,例如用户从蜂窝网络切换到 WIFI,用户潜在地切换了载体,也潜在地切换了观察的视角点。这意味着即使网络切换非常顺畅,在我们的基础架构中,它对 Anycast 的运作方式和对 Unicast 不同。然而,正如大家所知道的,IP 至少与物理位置在相当强烈的意义上相关联。当用户通过建立一个新的数据流到达下一个负载平衡器时,负载均衡器会忽略该数据流之前的所有历史活动,将此数据流作为一个新的数据流,我们有很多服务器,切换到同一个服务器的几率基本上为零。我们非常希望这能奏效,因为某些原因我们希望将更多的流量转移到任点,除此之外,对于部分用户来说这是更流行的选择。
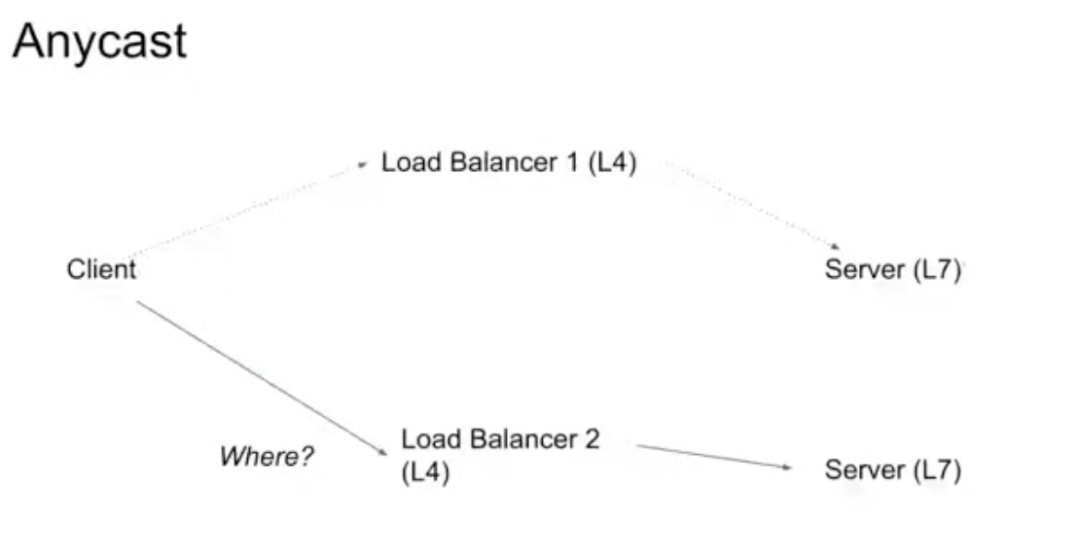
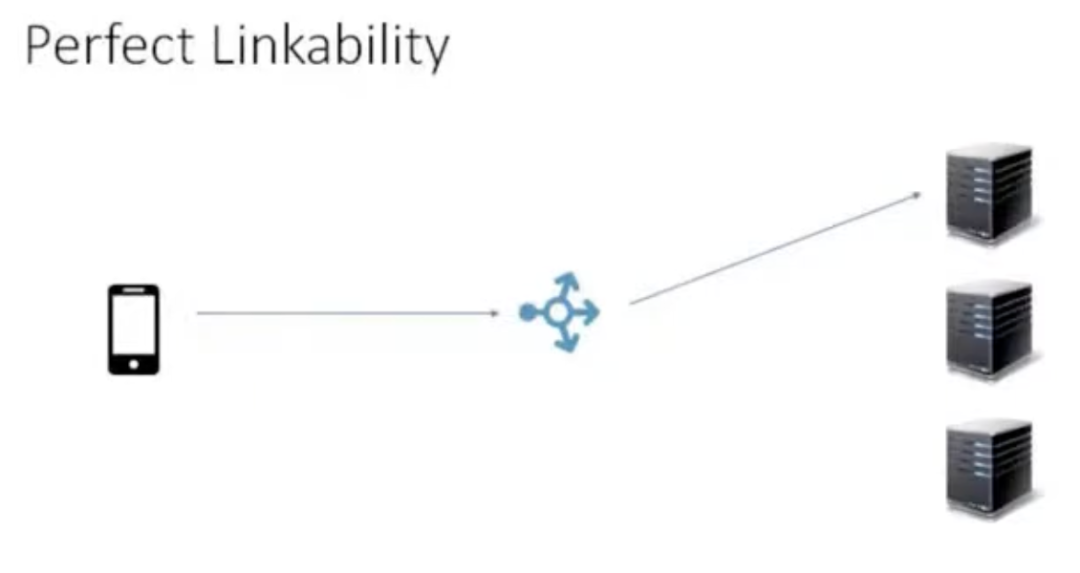
这就是我们做 QUIC-LB 和连接 ID 的重要原因。还有关于完美连接性的讨论,完美连接性就像是任何时间你有一个单独的设备连接到一个单独的机器,无论 QUIC 或任何其他技术是否能参与进来,只要有一个单独的 IP 地址就可以做到一直追踪它。你可以追踪到这个连接因为世界上只有一个连接可以连接到该 IP,这是列举出的最糟糕的应用场景。
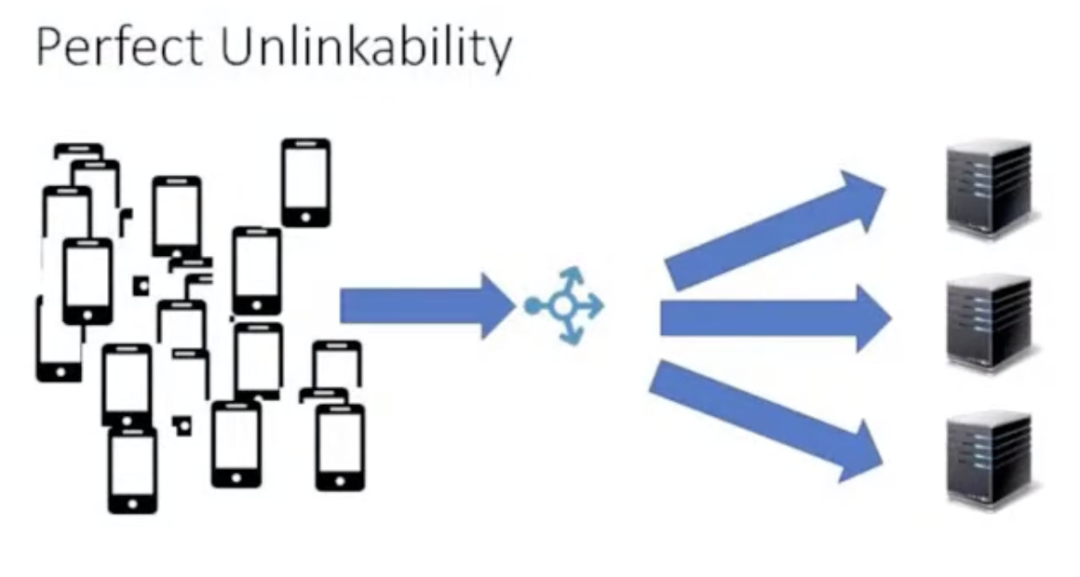
但是更典型的场景是,有相当数量的客户连接到相当数量的服务器上,逐渐地这看起来变成了完美的非连接性,这种情况下,任点就非常有用,因为只存在一个全局 IP,这样就可以将很多服务器整体看成一个服务器。然后上百万甚至更多数量的用户就可以在给定时间连接到那个 IP 地址,可以将这个与 QUIC-LB 加密的连接ID结合。
QUIC-LB 有一个单独的连接 ID 格式,该格式起始于两个比特的 config ID 以便允许 key 的旋转或其他功能,他还有一个被称为服务器 ID 的部分和随机数部分。传统版本即没有列出我们实际部署的加密版本,除了部分字段和总的字长,其他的 ID 都是不透明的。在最初版本里允许使用未加密的 ID,但是不太推荐。做加密 ID 的边际成本并不高,目前最糟糕的部分其实是键值的分布,做加密版本的连接 ID 其实并不太困难。

QUIC 黑洞效应
一个五元组可以在任意一个方向或者所有方向被黑洞效应干扰,但是在一个方向收到干扰的情况更容易出现,这对于观察者来说没有区别,因为观察者无法观察到信号是在用户传输到服务器时被干扰还是从服务器传输到用户时被干扰。另外一个挑战是,对于给定的五个用户,五元组之间存在多条通道,例如从 IBA 到 IPB 的连接是程序化的,两个终端可以一直接触到的情况非常不常见,而是断断续续地连接不上或者不太稳定,最糟糕的情况是当出现一次黑洞效应时,你需要等待的一次宕机的时长至少需要 30s,但是一般需要等到几分钟,这对用户来说是能感知到的而且是非常痛苦的过程,用户可能坐在那儿等待一个页面加载几分钟,因为一个传输流被黑洞效应吸走了。

因此,为了降低尾延迟,现在在我们的部署中,当出现五次连续探测超时时,根据理论,此时系统还能正常运行的概率非常低,因此我们会关闭连接,这样的操作确实会杀掉部分还在正常运行的传输流,但是关闭连接杀掉的传输流主要都是已经失效的传输流。这会导致部分使用正常的用户也感受到令人不适的 10s 到 12s 的重载时间,但是这带来的尾延迟的降低也是非常可观的,因此这样降低尾延迟的方法也存在一些弊端。

但是近期,我们提出了一种更优的方法,一种基于 QUIC 的解决方法,我们观察到改变唯一的端口可以彻底地改变路径,如果你在你的机器上从两个暂时的端口上建立一个追踪路线,我们最终会发现传输流会经过不同的匹配点。因此,当如果连接被黑洞化了,直接在用户端切换到另外一个端口即可。这种修复连接的方式评价非常高,这让我们可以避免依赖五种 RTO 或者 PTO 关闭连接的方法。这引入了两个方向的熵增,而与具体哪个方向无关。该方法被设置为 Chromium 系列的默认设置(Chrome、Cronet 等)

QUIC 中断和传染性错误
我们在去年 11 月份遭遇了一次非常惊恐的停电事故,这场停电事故造成的不良后果比人们想象的还要糟糕,因此在当时关于“死亡”的关键词查询由恢复信息被触发,从 GFE(Google Fornt Ends 谷歌前端)发送到用户,再从用户返回到 GFE,导致了 GFE 宕机,不幸的是这些从新服务器发出的信息导致其他的服务器也宕机,在最严重的时候,约 10% 的谷歌前端宕机,但是导致的影响分布非常不均匀,受到影响的最主要区域是欧洲。

因此,受到此事件影响后,我们想出了一个新的方法叫 Contagion,类似于分布式系统的相互作用,在明显的危害到来之前缓慢推理识别大部分错误,如果这个过程中找到了 bug,我们回溯到之前的状态,但传染性错误不是仅仅通过回溯实现,当然也受到服务器和用户端终端对操作权限的限制,当识别系统认为回溯操作不正确时,回溯操作将无法进行。

版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。