
通过改变3D场景制作流程复杂、成本高、门槛高、流动性差的现状,让商家像玩转2D一样去玩转3D,让普通消费者也能参与到3D内容创作和消费中,真正实现内容生产模式从PGC/UGC过渡到AIGC,是我们3D场景智能创作引擎一直追求的目标。
前言
随着元宇宙的大火,国内外各大厂纷纷下场开始为下一代互联网技术布局,旨在为用户提供更好的体验。体验包括方方面面,比如更好的游戏体验、更好的社交体验、更高效的办公体验当然也包括更好的消费体验。作为国内最大的电商平台,我们团队也在持续思考如何基于元宇宙的技术,给消费者带来更好的购物体验以及给商家带来更好的营商体验。
回归到电商“人、货、场”三要素上,通过虚拟人技术以及商品三维重建技术,“人”和“货”在3D化上已经迈出了重要的一步,而“场”作为连接“人”和“货”的重要载体,目前还严重依赖于专业人员通过专业的DCC软件进行创作,门槛高、耗时长、成本高、效率低,这就导致了中小商家以及C端用户在现阶段难以大规模参与,即使是头部大品牌商家制作的3D场景内容也很有限。然而,大规模的虚拟世界需要有大规模的虚拟内容作为支撑进行构建,基于AIGC的能力加速“场”的自动化构建从而降低3D场景制作门槛就显得非常有必要。
3D场景制作流程概述
3D场景制作在游戏行业已经形成了一套非常成熟的工业化、流水线生产的解决方案。下面通过游戏行业场景制作方式来简单介绍一下3D场景制作的整体流程。游戏中一个完整的场景制作流量一般可以分成如下六个步骤:
- 游戏策划提需求
- 原画师承接,并绘制出对应的原画
- 建模师制作对应的三维模型和材质贴图
- 绑定师架设骨骼、蒙皮、绑定控制器进行角色驱动
- 动画师会采用动作捕捉,或者手动设定关键帧的方式制作动画资源
- 场景编辑师在游戏引擎中搭建游戏场景


当然,构建一个电商场景的3D内容其复杂度远低于一个庞大的游戏场景,但相关的流程基本是一致的,比如商家想要在虚拟世界中构建一个店铺进行商业活动,那么整个店铺的搭建也大体需要遵循上面的流程。
电商3D场景拆解
电商域的3D场景由小到大一般可以分成展示单品的3D场景、展示店铺的3D场景、商业街区场景、虚拟城市场景,如下图所示:

由于街区是店铺的集合而城市是街区的集合,因此只要做好单品展示场景和店铺展示场景便能基于这两个基础能力跟搭积木一样的实现街区或者城市的构建。
下面以店铺为例,对虚拟店铺场景的构造进行拆解:
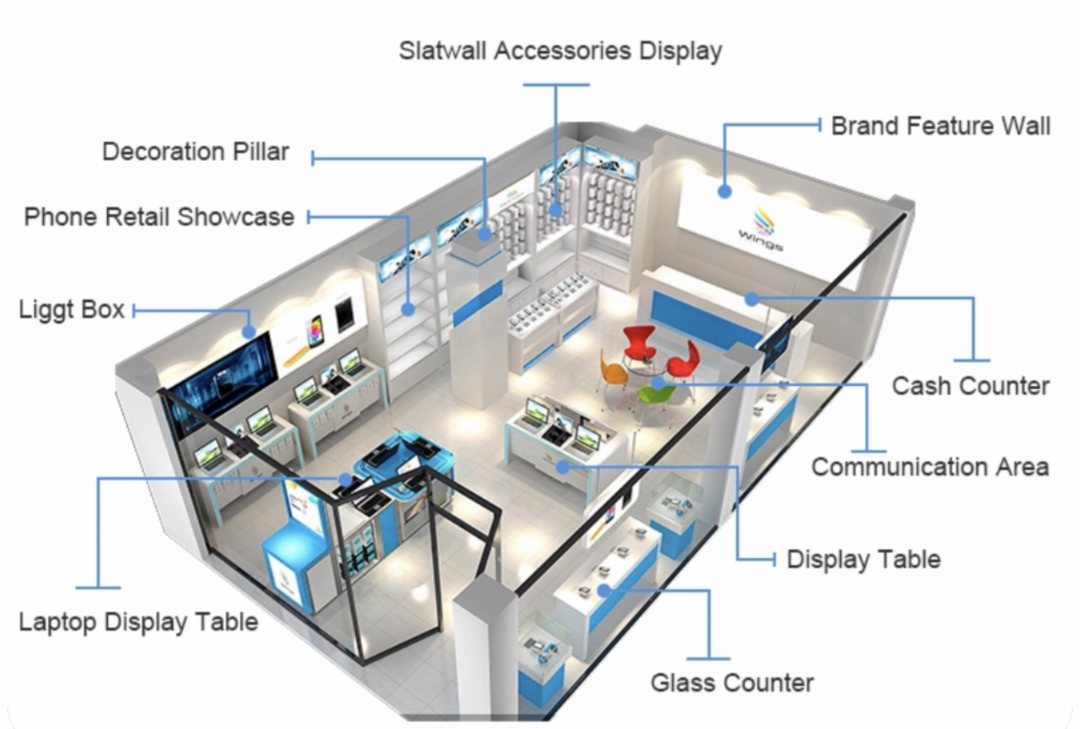
上图标识了构建一个虚拟店铺需要用到的所有元素,跟实体店铺类似,一个虚拟店铺的构建也包含了店铺装修所有的环节:硬装、软装、软装布局、布光、商品摆放等,如果是单品场景展示,还需要额外考虑商品运镜。
3D场景生成技术介绍
3D场景智能创作引擎技术架构
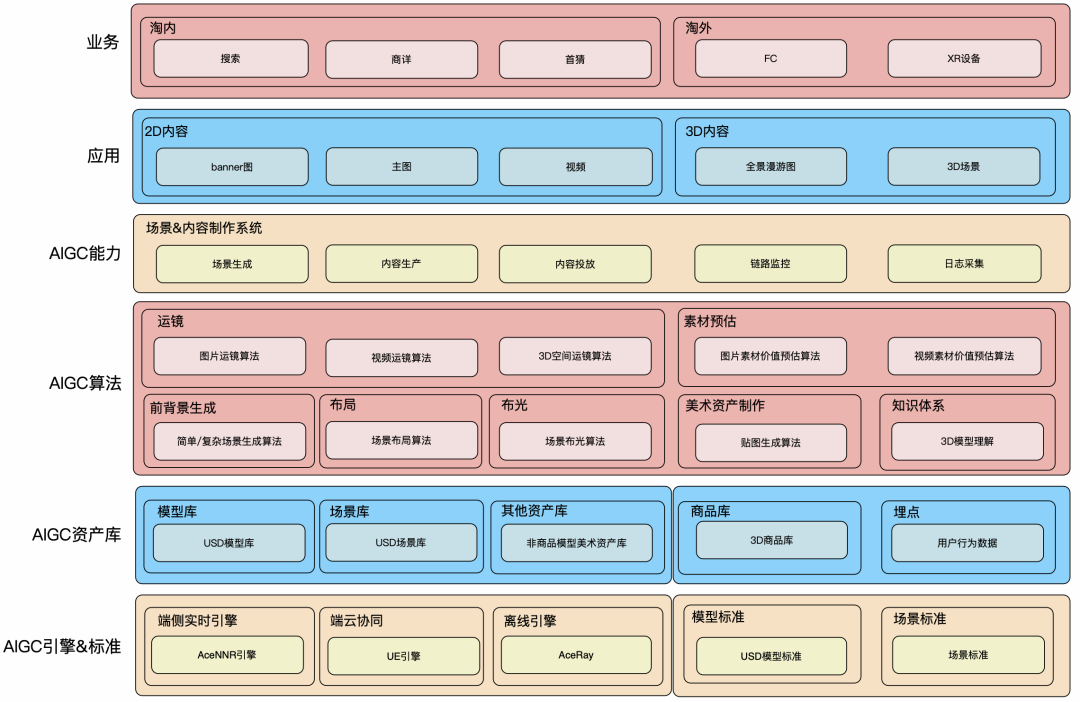
上述为AIGC 3D场景智能创作引擎技术架构,下面介绍一下创作引擎核心的几个算法。
前背景生成技术
前背景生成技术核心解决构建的3D场景与待展示的商品或者店铺相匹配问题。即给定一款商品生成与之匹配的3D场景对该商品进行展示或者给定一个店铺的商品生成与这批商品调性相符的店铺场景。
对于不同品类的商品,所需场景复杂度是完全不一样的。以手机和沙发为例,一般展示手机的3D场景以抽象的风格为主,比如星空、天空、或者一些抽象艺术风类似于手机内置的壁纸其主要目的是配合手机的外观以及屏幕壁纸颜色进行展示,整体场景相对简单,而展示沙发一般以实景场景为主并且需要在一个非常好看的客厅空间进展展示,为了营造温馨或者奢华的视觉效果还需额外大量的辅搭物品,如下图所示:

为了解决不同复杂度场景生成问题,我们构建了两套场景生成技术,以下简称单场景生成技术和复杂场景生成技术,下面分别介绍这两种技术方案
- 简单场景生成技术
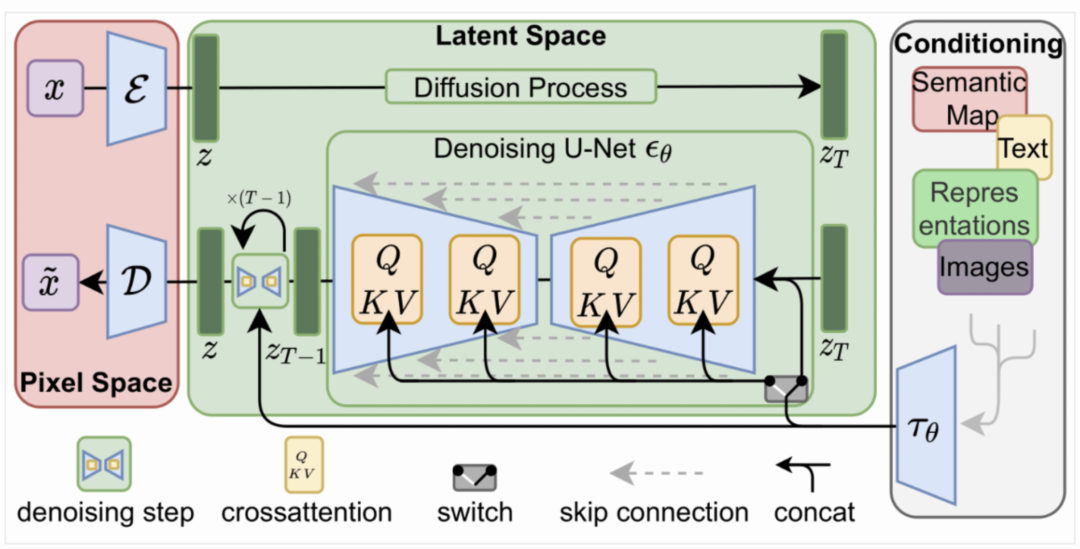
简单场景生成技术核心解决场景内贴图生成问题,根据不同的商品生成与之匹配的场景贴图,并用生成的贴图根据一定的场景构建方式构建出新的场景,从而完成简单3D场景创作。我们采用的技术方案是基于Diffusion Model进行贴图生成,模型结构如下图所示:
给手机生成的星空背景贴图如下图所示:
同时,我们基于手机屏幕壁纸也做了一些创意的贴图生成,效果如下图所示:
直接根据手机壁纸进行场景贴图生成,构造与手机相符的3D场景。同时也可以基于该技术进行AI创意输出,设计师在搭建场景时给到设计师更多的灵感输入。另外,基于AIGC生成贴图的好处在于不受图片版权限制。
- 复杂场景生成技术
如上述沙发的例子,在构建复杂场景时仅仅考虑场景贴图是远远不够的,需要围绕该商品构建整个客厅场景,硬装上包括背景墙、地板、灯具、窗帘等等、软装上包括辅搭家具、辅搭配饰、地毯等等。
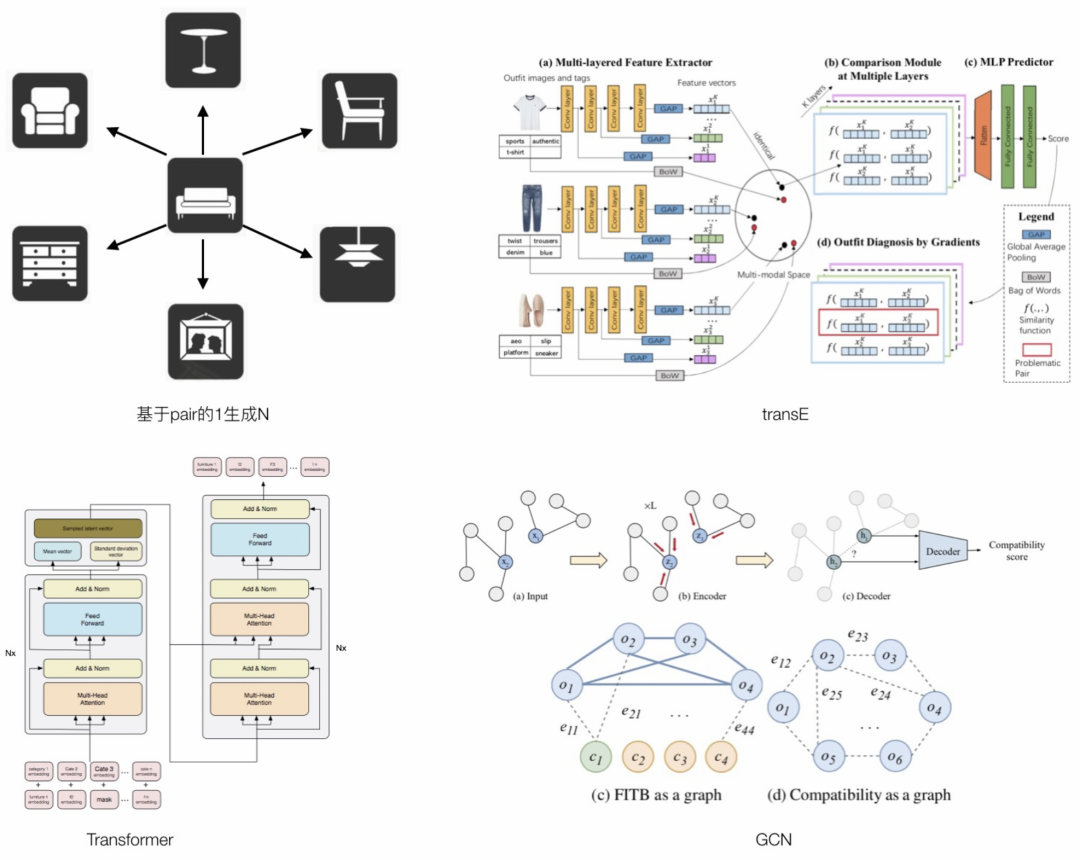
如上图所示,我们先后尝试过四种生成方案,均未取得理想的效果,原因如下:
- 基于pair 1生成N方案:该方法直接将1->N的问题当成多个1->1的问题来处理,缺点是,搭配不存在递推关系,即A与B搭,A与C搭,不能得出结论说B与C搭,所以,一旦生成的序列过长,基本没有审美可言,基于我们提出的BLEU n-gram的评测方法效果最差;
- TransE方案:主要研究如何在更高位空间内解决递推关系,缺点是在有限规模的数据集下,不能找到一个高维空间可以对所有的家具进行表达,进而导致递推关系不成立;
- transformer方案:需要大规模的数据集进行训练,由于设计域的数据集都比较小导致训练不充分,匹配关系基本都学得不够好,其向量内聚性也不够好;
- GCN方案:该方法的优点是节点的度越大,表征得越充分,度越少,表征得越不充分,极端情况是度为0,表征能力就很差。很适合解类似于完形填空的N生成1问题,针对1生成N问题,初始情况下度为0,很难稳定生成比较好的场景;
设计领域存在一个明显的设计特点,物理空间上越接近的物体其相关性要求越高,还是以沙发为例,比如客厅的主沙发和副沙发,往往要求其在款式、颜色、风格上要保持一致,物理空间距离越远设计上的自由度就会越大,比如客厅的沙发和卧室的床或者餐厅的餐桌之间设计自由度就会很高,没有明显的限制。
根据设计与物理空间远近强相关这一关系,我们对原有的transformer进行了部分改进,在复杂场景中将待生成的辅搭物品根据空间距离划分成多个组,从而将一次性生成一整个长序列分解成生成多个强相关的短序列组合,同时每个短序列又作为先验知识,用于生成下一个短序列,这样做的好处是能够保证局部空间的强相关性以及当前空间与其他空间的相容性,而且实验发现能大大降低对样本的消耗量。通过实践我们发现该方案不仅适用于单商品的场景生成,也适用于店铺维度的场景生成,整体的网络结构如下图所示:
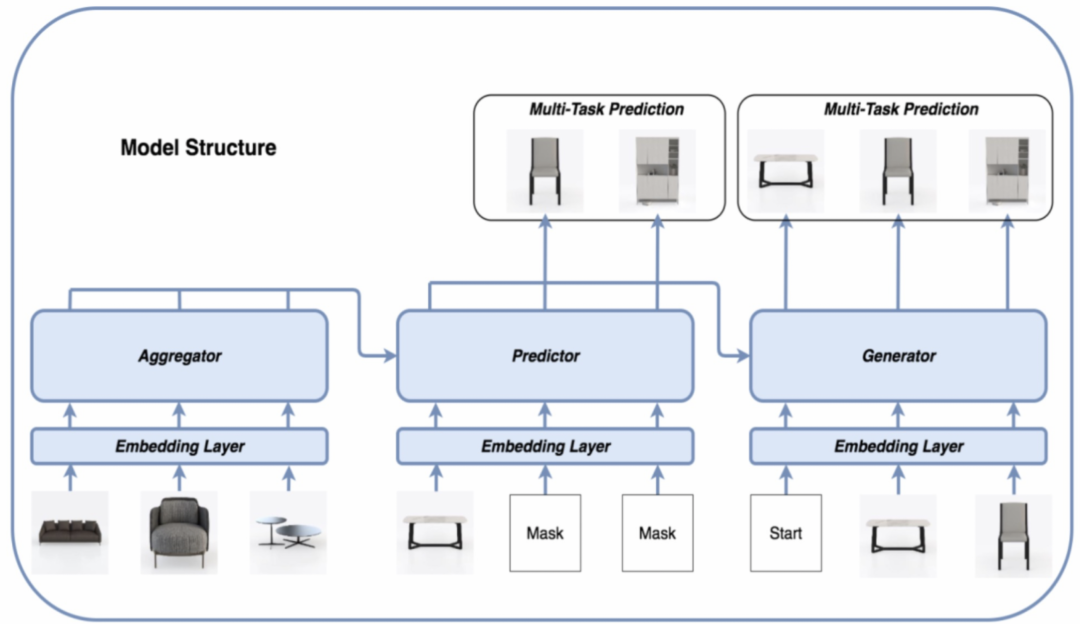
运镜技术
构建纯3D场景不会涉及到运镜相关的技术,然而一旦需要把3D场景转成内容进行分发,比如基于3D场景生成图片用于制作宝贝的商品主图,或者基于3D场景制作短视频在各大短视频平台进行分发,或者基于3D场景制作全景图进行3D展示,或者在虚拟世界的虚拟屏幕上进行广告投放时,智能运镜技术就显得非常有必要。智能运镜技术可以类比成一个虚拟摄影师,通过这个虚拟摄影师可以在已经生成的3D场景里拍摄出非常好看的图片、视频、全景图等优质素材供给各渠道进行分发。
运镜技术最大的难点是相机参数标注难度过大,成本过高,无法开展批量化标注。相机标注要有专业的摄影师与3D设计师一起参与,每一个机位的标注都需要设计师与摄影师协同配合,成本非常高,如果找非专业人士标注直接进行标注,效果非常不理想,为了解决无法进行批量化标注的问题,我们先后迭代了两个大的版本,我们称之为基于摄影构图的运镜技术和基于现有构图的逆向运镜技术,下面分别介绍这两种运镜技术。
- 基于摄影构图的运镜技术
顾名思义就是将摄影构图的技术参数化,并将其应用于3D场景的拍摄中,比如最常见的构图技巧为“井”字构图法,如下所示:

将待拍摄的画面通过两条横线和两条竖线分隔成九个象限,产出四个焦点,这四个焦点称之为黄金分割点,只要把待展示的物体放到这4个焦点的上,就能产出一幅比较不错的图片,还是以沙发为例,通过运用“井”字构图法,分别将焦点置于(2,1)和(1,2)处,就能拍摄出不错的图片,如下图所示:

另外一种常用的构图技巧“井”字构图法的另外一种构图方法,简称“三分”构图法,将待拍摄的画面通过两条横线分隔成三个象限,并把在3D场景中待拍摄的物体放置在下面一条线上,也能拍出比较好的图片:

基于摄影构图技术算法已经能够拍摄出与普通摄影师相媲美的图片或者短视频,它的缺点在于摄影构图千变万化,通过调整相机高度、相机相对物体的距离,俯仰角、FOV等参数同样的构图技巧能拍摄出非常不一样效果,而且不同品类的商品虽然构图理论是同一套,但最终呈现的效果也可以完全不一样。因此,需要根据不同的类目需要去调节不同的参数,工作量巨大,该方法适用于项目冷启动阶段且急需产出素材的时候,无法大规模推广。
- 基于现有构图的逆向运镜技术
逆向指的是逆向商家的运镜,商家经过多年的摸索,已经把最优质的拍摄方法都沉淀在了商品主图中,因此,最直接的方式就是从商品主图中逆向摄影师拍摄时的相机参数。但直接从商品主图中还原摄影师拍摄时候的相机参数难度巨大,两者之间缺少直接的联系。
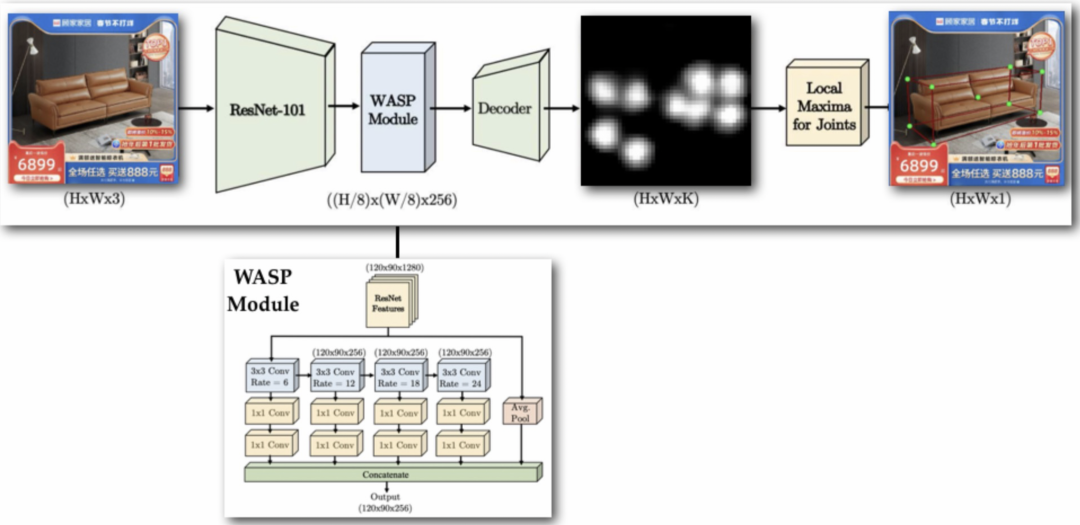
由于物体在3D空间中的坐标是已知的,如果我们能预估出物体在图像中的3D bounding box从而得到其8个顶点的坐标,那么就可以将其转换成图形学中的Perspective-n-Point(pnp)问题,该问题可以通过Direct Linear Transformation (DLT)方法进行求解,得到相机参数,并将其迁移到3D场景中,就能实现机位生成。
我们通过UniPose对商品主图进行预测得到物体的3D bounding box以及对应的8个顶点坐标,为了提高模型效果,同时加入了物体姿态估计、热图估计。训练数据则是来自于随机角度渲染出的2D图以及部分人工标注数据,模型框架如下所示:
有了主物体在2D空间下的8个顶点的坐标,以及在3D空间下的对应的坐标,通过DLT算法就能求解出对应的相机参数:
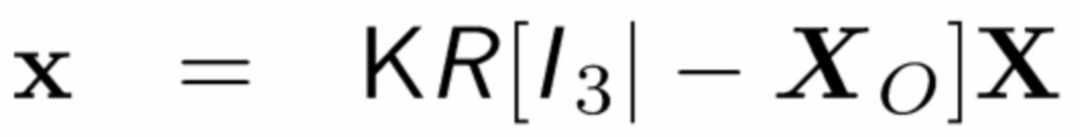
其中x是物体2D图像坐标,X是3D世界坐标,K是相机内参矩阵,R是相机外参矩阵,Xo为相机位置坐标。
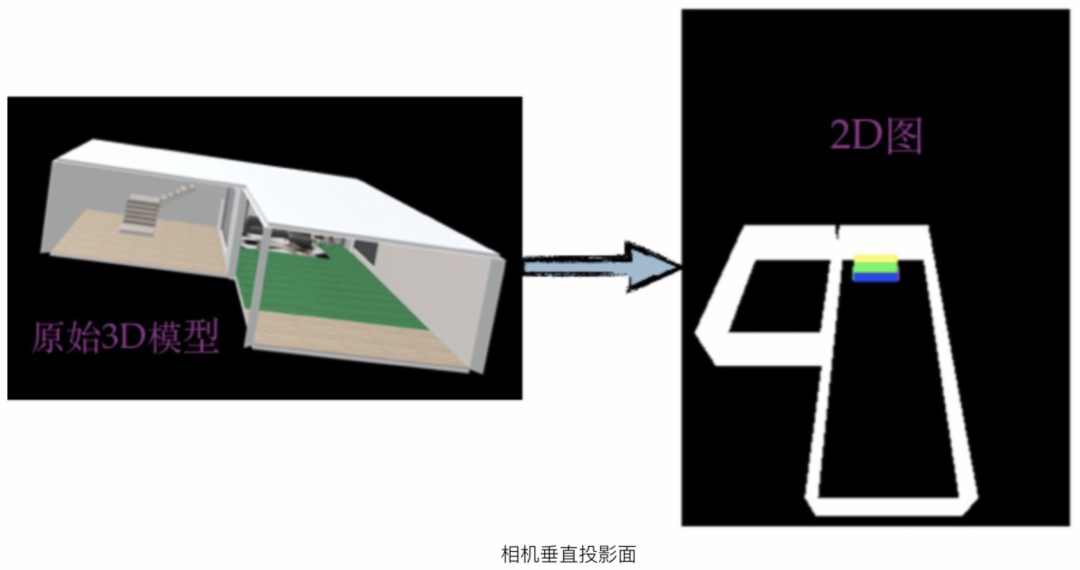
迁移到3D场景中时,由于3D场景内物体在尺寸上与商品主图不一定完全一致,为了保证主物体在画面中的占比,需要进行机位微调,如下图所示是微调的过程,微调的目标就是主物体在画面中的占比
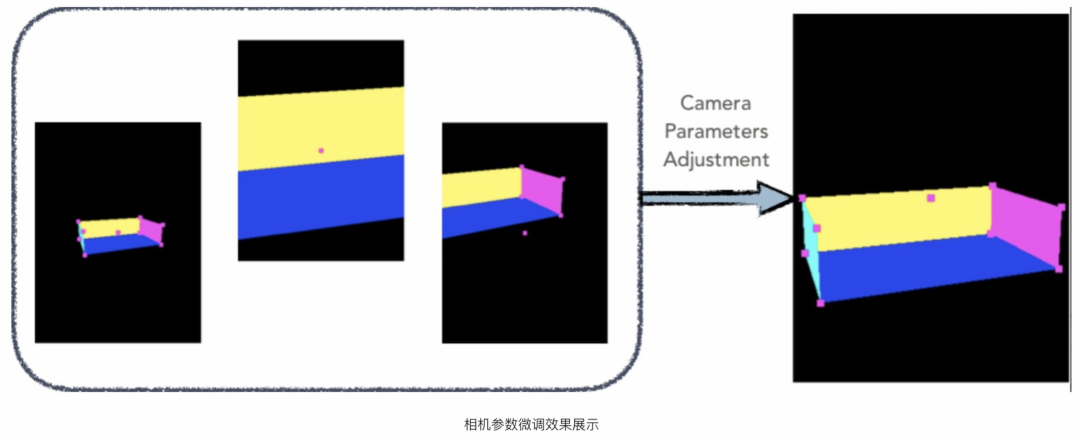
有了逆向运镜技术,不仅可以直接获取商家的运镜方法,也极大降低了标注成本不再需要专业的摄影师和3D设计师协同进行标注,同时也为运镜技术进行规模化推广到所有品类奠定了技术基础。
算法基于3D场景生成技术+智能运镜技术制作的效果图如下所示,同样是针对沙发场景,我们可以生成几十种运镜效果:

场景素材价值预估技术
有了3D场景生成技术和运镜技术后机器已经可以批量化、规模化、低成本的进行场景制造,据我们统计目前沙发类目下单品展示的3D场景平均一个模型已经可以构建出超过500个场景,再加上运镜技术每个场景至少能生产5张优质图,也就意味着针对一个3D模型,我们可以生产出1500张优质图,这么多优质素材如何投放能够效率最大化,这一问题随着场景制造能力逐步提升所面临的挑战也在逐渐增大。此处我们的解法是进行素材价值优选,优选最有效的素材进行投放,比如搜索场景我们以CTR为目标优选出CTR最高的素材进行投放。
我们以目前跟搜索合作在搜索侧透出机器产出的3D场景素材为例,简单阐述一下场景素材价值预估与传统CTR预估的区别:
- 只负责供给素材,不干预排序:在这种情况下,一个素材CTR高,并不一定能代表我们生成的素材好,需要考虑该素材透出的坑位,以及商品本身的CTR;
- 传统CTR预估针对item维度对全局item进行预估,而我们是素材维度对同一个item机器产出的不同素材进行预估;
- 由于我们只做离线的素材供给,因此仅有图像本身的特征以及投放后的统计类特征;
- 给不同商家供给的素材、给同一个商家不同商品供给的素材,所用的3D场景需要有足够的多样性,否则在搜素展现时,同质化会非常严重;
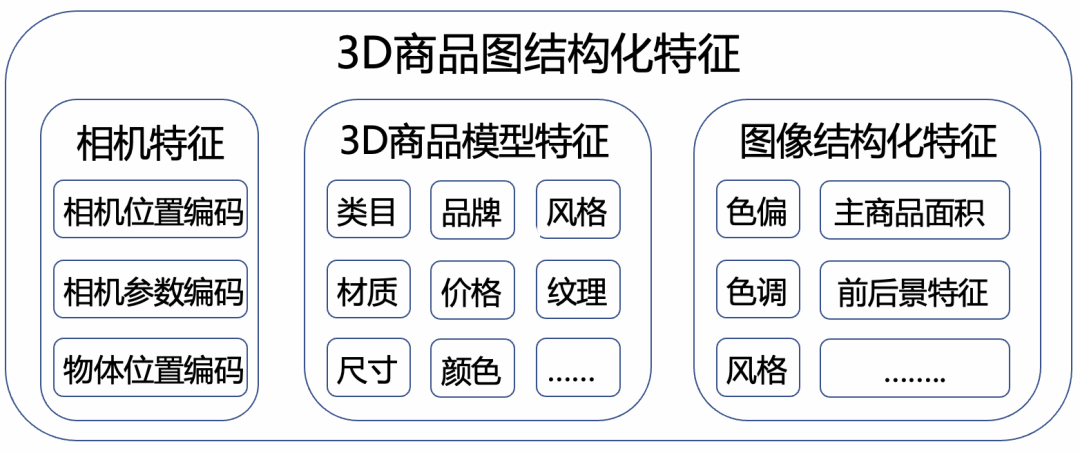
在没有大流量训练的前提下,仅仅从图像层面进行粗粒度特征提取,模型效果远不如汤普森采样。为此,我们对图片的信息进行了细粒度的解构做了大量的特征工程,同时基于逆向运镜技术从图片中解构出了相机参数作为2D图片独有的3D特征,从而将商家拍摄的图片与3D场景下生成的图片在特征维度进行了统一,如下为我们抽取的部分特征:
通过投放以及对日志数据的分析,我们发现了一些有趣的现象,如下图所示:
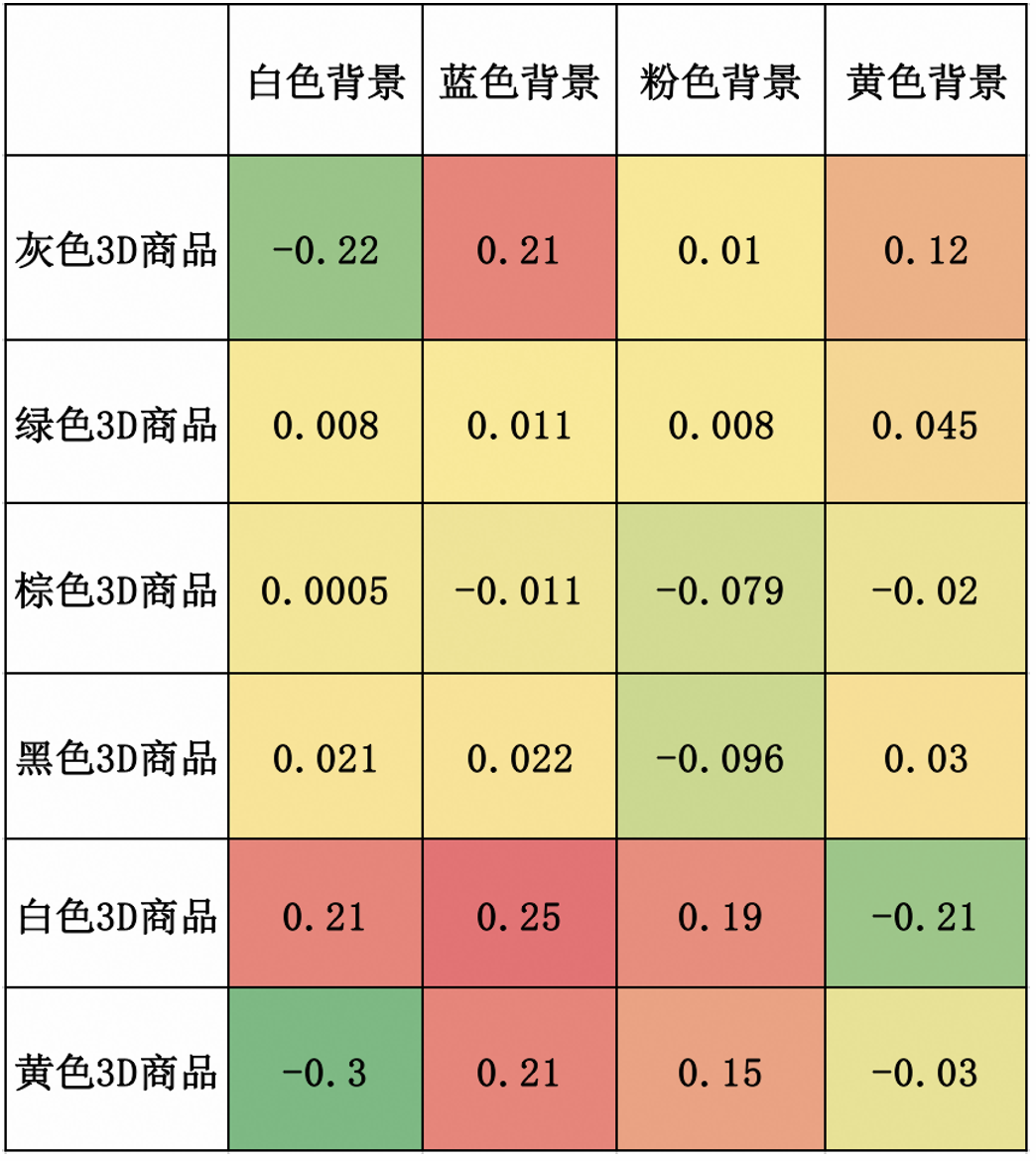
我们通过大量的投放实验发现合理的前背景搭配以及合理的机位选择能对商品CTR带来显著的影响。住宅家具类目的实验表明,更合理的前背景搭配以及有效的运镜CTR差异能够超过15%。
另外,基于当前的工作,我们也在探索设计的白盒化,即可以从前背景搭配、运镜、主物体占比画面面积等维度出发对一张图的点击率进行分析,或者给到商家一些指导,帮助商家进一步优化主图的点击率,进而提升运营效率。
模型生成技术
在进行游戏创作时最缺的是美术资产,比如要搭建一个中世界风的游戏,前期需要创作大量的美术资产,如下图所示,如今游戏产业针对美术资产的创作已经形成了一个比较完善的工业化解决方案。
电商行业也类似,为了对万物进行场景构建,我们同样需要丰富多样的3D美术资产。而与游戏厂商可以针对每款游戏进行重金投入花费巨额成本进行资产创作不同,我们不可能要求所有商家都进行重资产投入,特别是中小商家或者C端用户。面对电商特有的多样、高频的营销场景以及海量不同的商品特质,都要求我们必须要有低成本、高质量的美术资产创作方案来适配海量场景构建需求。
目前我们的解法是通过AIGC技术进行纹理创作,下图所示是基于AI进行模型生成效果:

应用介绍
通过上面的介绍可知,将AI构建的3D场景通过运镜技术内容化后,分别可以输出图片、视频、3D空间等相关内容,结合淘宝APP、手机天猫APP相关场景,我们分别做了一些实践。
3D场景图片化
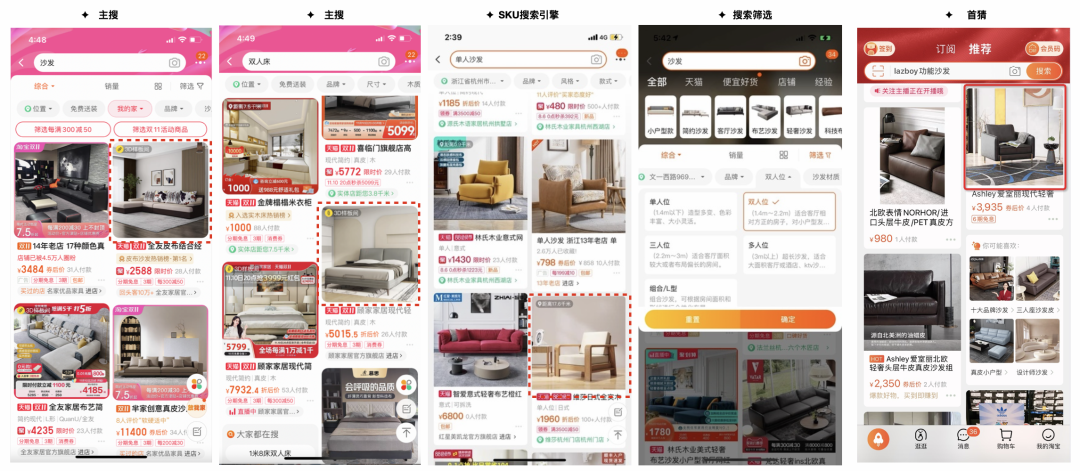
图片是目前淘宝APP各渠道分发最多的素材,不管是商品详情页、搜索、首猜还是其他导购场都需要用到图片进行分发。因此图片也是商家花重金建设的最核心资产,甚至有些商家戏称自己是一家图片制作公司。据我们跟一些头部家装大商家的调研,如果是实拍图,一套主图的成本就在2000~5000元不等。
如今,3D场景的自动生成能力结合运镜技术,AI已经具备了批量化造图的能力,我们将AI制作的图片搜索以及首页猜你喜欢,在公域非付费流量替换商品主图进行透出,我们希望借助AI的能力让商家能够得到额外的收益。目前淘宝搜索、SKU搜索引擎、搜索筛选项、首页猜你喜欢的部分类目已经接入我们的能力日均曝光千万级,CTR有明显提升并且获得了头部大商家的认可。AI的持续造图能力,不仅能够给商家带来优质的图片素材,同时也可以防止用户的浏览疲劳,始终能够给消费者提供更新更好的素材供其消费。
通过这个项目,我们跟家装头部大商家建立了很好的合作,包括林氏木业、全友家居、芝华士、顾家、喜临门、慕思等等帮助他们持续提升在公域透出的效率,目前已经有3000+店铺授权我们使用公域自然流量。
可以想象未来商家基于AI能力进行素材创作并进行分发的巨大空间,其制作效率与传统实景拍摄相比,将会有一个多么大的提升,特别是后疫情时代,AI为商家提供了另一种可替代的造图能力,甚至可以想象,未来商家只要有一个3D模型,AI就能完成商家所需素材的创作需求。
3D场景视频化
短视频化的时代,我们通过3D技术也为短视频的生成持续助力。在3D场景中拍摄视频与拍摄图片相似,单一视角拍摄变成了序列视角拍摄。目前,我们生成的短视频已经在淘宝APP、手机天猫部分类目的商详落地,帮助商家降低视频创作的成本,提升视频创作的效率。
3D空间展示
3D空间展示依赖3D场景的构建, 目前我们生成的3D场景以3D样板间的形式在极有家相关频道进行了透出,极大降低了商家搭建3D样板间的成本。
总结与展望
作为下一代互联网虽然元宇宙仍处在非常早期的阶段,我们也在持续探索元宇宙电商场景的表现形式,不过我们始终坚信低成本、高质量、低门槛、大规模的3D场景构建技术必然是未来构建元宇宙的基础设施。通过改变3D场景制作流程复杂、成本高、门槛高、流动性差的现状,让商家像玩转2D一样去玩转3D,让普通消费者也能参与到3D内容创作和消费中,真正实现内容生产模式从PGC/UGC过渡到AIGC是我们3D场景智能创作引擎一直追求的目标。
仰望星空的同时也要脚踏实地,未来很长一段时间手机仍然电商最重要的媒介,因此图片和视频仍然是商家重资产投入的环节以及消费者消费规模最大的内容,希望我们的3D场景智能创作引擎在目前的2D分发时代能够给更多的商家以及业务在素材上降本增效,丰富消费者个性多元的消费需求。
团队介绍
大淘宝技术Meta团队,目前负责面向消费场景的3D/XR基础技术建设和创新应用探索,创造以手机及XR 新设备为载体的消费购物新体验。团队在端智能、端云协同、商品三维重建、3D引擎、XR引擎等方面有着深厚的技术积累,先后发布深度学习引擎MNN、端侧实时视觉算法库PixelAI、商品三维重建工具Object Drawer、端云协同系统Walle等。团队在OSDI、MLSys、CVPR、ICCV、NeurIPS、TPAMI等顶级学术会议和期刊上发表多篇论文。欢迎视觉算法、3D/XR引擎、深度学习引擎研发、终端研发、AIGC等领域的优秀人才加入,共同走进3D数字新时代。简历请投递至: chengfei.lcf@alibaba-inc.com
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。