
随着语音处理技术的不断提升,伪造语音的身影在社会生活中出现的更加频繁,一方面语音提醒、语音解锁以及短视频配音等自动化语音技术极大的丰富了人们业余生活,但是随之而来的滥用问题也给生活生产安全带来了严峻挑战。语音伪造技术手段多种多样,主要可以分为以下几类:语音合成、语音转换以及录音重放。
语音合成又称文本到语音的转换,是一种可以将任意输入文本转换成相应语音的技术。是将人类语音用人工的方式所产生,能将任意文字信息实时转换成为 标准流畅的语音朗读出来。其具体的流程如下:首先通过大量数据进行训练,训练出效果较好的 TTS 系统(包括声码器、编码器、解码器等众多模块),然后对目标任务语音数据进行收集、标注以及制作相应的数据集,对该语音合成系统进行微调,最终产生一个和目标人员高度拟合的 TTS 系统。基于此系统合成的语音对鉴伪系统会产生较强的欺骗性。
语音转换主要是将语音模拟到目标人物的特征语音空间,在保持语言内容不变的同时改变说话人的身份。通过采集目标任务的说话的语音片段、提取说话人特征然后进行特征迁移,迁移攻击人员的语音数据到目标人物的特征空间,以使攻击人员身份变成目标说话人,从而达到欺骗鉴伪系统的目的。
录音重放主要针对于固定语句验证的系统,使用录音设备录制目标说话人的固定语句,在验证的时候将录制的语句进行播放,以此来欺骗鉴伪系统。考虑到语音合成和语音转换的攻击方式,它们同时也被称为逻辑访问 (Logical Access, LA),录音重放单独被称为物理访问(Physical Access, PA)。考虑到实际的使用场景,本文重点关注逻辑访问这类伪造手段。
数据集介绍
ASVspoof系列竞赛的目标之一就是寻求鲁棒的攻击检测系统,至今举办了4届,每两年举办一次。竞赛主页如下
https://www.asvspoof.org/
ASVspoof 2019 LA数据集中的训练集、验证集以及测试集均包含了业界最新的攻击算法和手段,其中语音合成(Text-to-Speech, TTS)的算法 10 种,风格转换(VoiceConversion, VC) 主流算法 4 中,TTS 和 VC 的融合算法有 3 种。比较新的算法主要是使用了神经波形模型(Neural Waveform Models)和波形过滤器(Waveform Filtering)或者是这些技术的变种,同时 TTS/VC 的最新算法也借助了如 Merlin, CuRRENT、MaryTTS 等模块进行语音的合成。本文中鉴伪模型的指标也是在该测试集上进行测得。
特征选择
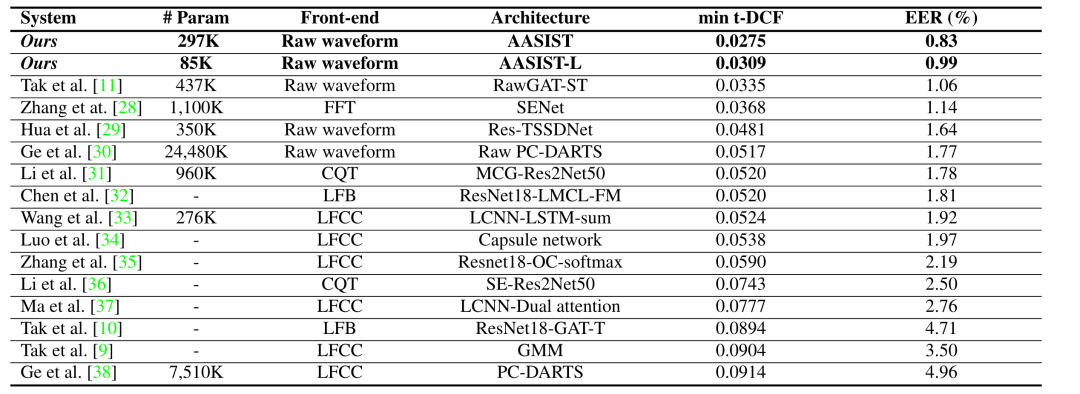
特征对于模型训练的重要性不言而喻,而鉴伪应用中使用的特征多种多样,包括且不限于:波形特征、CQCC(恒Q倒频系数),LFCC(线性频率倒谱系数),FFT(傅里叶变化系数),CQT(常数Q变换)等等。目前就单个鉴伪系统而言,最好的EER是采用波形特征作为输入的AASIST网络,而本文所使用的特征为FFT的0-4k部分。

近年来,攻击检测系统结合说话人识别系统所带来的性能提升也引起了关注,比较简单的结合方式就是说话人识别系统提取出来的声纹嵌入码和攻击检测提取出来的判别特征进行拼接然后送入全连接层得到最后的判决结果。整体的系统架构可以为如下几种形式
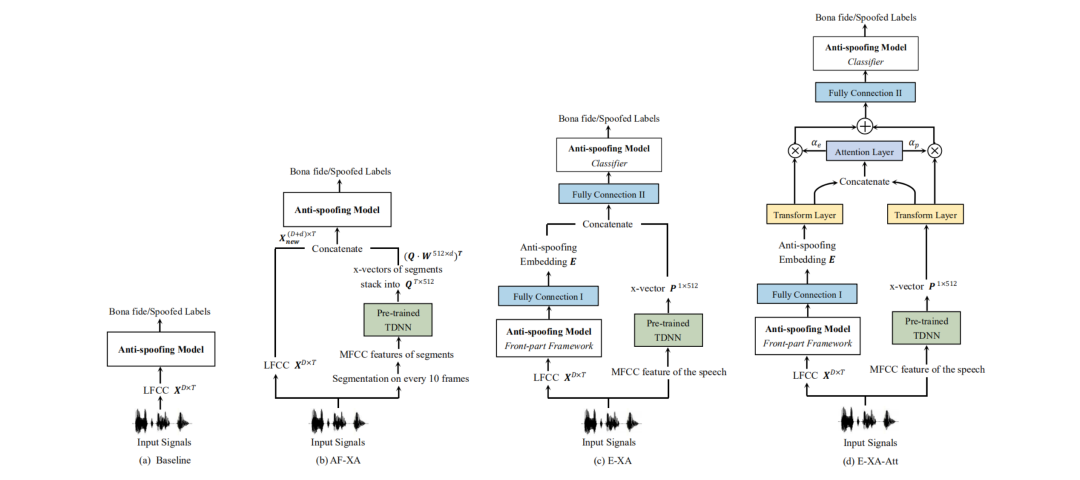
可以根据需求选择合适的拼接方式,本文采用上图的c模式。
模型选择
本文所使用的模型分为两部分,说话人识别系统和攻击检测系统,其中说话人识别系统采用ECAPA-TDNN模型(https://github.com/TaoRuijie/ECAPA-TDNN),并且直接使用预训练模型,训练过程中冻结ECAPA-TDNN模型的权重。攻击检测系统采用SENet。将说话人识别提取出来的192维声纹嵌入码和攻击检测系统提取出来的128维embedding进行拼接,然后送入全连接层得到最后的二分类结果。
结果
本文的训练集除了ASVspoof2019LA的训练集外,还收集了常见主流厂商(腾讯,云知声,讯飞,阿里,标贝等)的TTS系统合成的语音,最后在ASVspoof 2019 LA的测试集上测的EER和min-tDcf。
CM SYSTEM
EER = 0.638849318 % (Equal error rate for countermeasure)
TANDEM
min-tDCF = 0.019244717
BREAKDOWN CM SYSTEM
EER A07 = 0.261438966 % (Equal error rate for A07
EER A08 = 0.162977240 % (Equal error rate for A08
EER A09 = 0.000000000 % (Equal error rate for A09
EER A10 = 0.838657402 % (Equal error rate for A10
EER A11 = 0.179950347 % (Equal error rate for A11
EER A12 = 0.407443099 % (Equal error rate for A12
EER A13 = 0.146004133 % (Equal error rate for A13
EER A14 = 0.261438966 % (Equal error rate for A14
EER A15 = 0.139206037 % (Equal error rate for A15
EER A16 = 0.774141889 % (Equal error rate for A16
EER A17 = 0.994836545 % (Equal error rate for A17
EER A18 = 0.390469993 % (Equal error rate for A18
EER A19 = 1.426050848 % (Equal error rate for A19而AASIST在Asvspoof 2019 LA的指标为

对比可知,本文的系统的EER和min-tDCF均低于AASIST,并且对大多数攻击类型的EER均低于AASIST。当然这种对比并不是很科学,因为本文所使用的系统除了ASVspoof 2019 LA训练集外,还用了其它数据。所以是数据的增加带来的性能提升更明显还是模型架构的改变带来的性能提升更明显,这里就不再分析了,但是可以肯定的是,结合说话人系统的鉴伪模型其性能肯定是有提升的,这一点在Spoof-Aware Speaker Verification 2022竞赛中可以得到体现,有兴趣可以看看Spoof-Aware Speaker Verification 2022的相关论文,特别是通过概率的方式将两个系统进行联合优化,虽然能够带来相当大的性能提升,但是说话人相关的概率计算需要目标说话人的注册语音,与本文的场景不太契合。
总结
本文主要介绍了结合说话人识别系统的鉴伪模型,说话人系统的引入能够提升鉴伪模型的性能。直接将两个系统的Embedding进行拼接是一种比较简单的联合方式,如何将两个系统进行更有效的结合仍然有待发掘。
相应的模型代码可见:https://gitee.com/Wilder_ting/study_-note/tree/master/ASVspoof_senet
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。