
随着耳机、车载等音频平台迅猛发展,各厂商除在ANC, ENC, KWS, SV, ASR, TTS等常规功能开展竞争之外,在音质方面也逐步提高标准。无损音乐经编码、蓝牙传输后,如何在端侧对受损音质进行修复,逐渐成为关心的任务。
一、问题背景
48kHz采样率下单通道无损音乐经某编码格式(如AAC)按低码率(如32kbps)编码后,音质会出现一定程度的损伤。损伤体现在如下几个方面:
(1)在时频图上,会出现高频带宽缺失及低频空洞损伤。(以女高音韩红版的《青藏高原》为例,在最后结尾高潮处的“青藏高原”,32kbps码率AAC编码后的音乐便具有高频缺失及低频空洞现象。)
(2)在听感上,对应(1),金耳朵可听出音乐在音域的带宽缩窄,以及由于空洞的存在破坏了谱在时间方向的连续性,可听到轻微的具有一定颗粒感的“咔咔”声。
(3)在客观指标上,采用对音质评价任务公认的ODG打分[1],输入参考信号为无损音乐,测试信号为编码后音乐,得分常在-3至-4之间(ODG打分的值域为0至-5,越低则音质越差)。
若能对编码后的有损音乐加以修复,且参、算量能运行在耳机、汽车等边缘端侧设备上,则可成为一种噱头和卖点。
二、历史工作
2020年10月,腾讯音乐实验室的Shichao Hu等人[2]在重构音乐高频信号时通过改进Griffin-lim算法和Mel-GAN声码器来解决高频相位的预测问题,取得了主观听感改善的效果。该工作的低分辨率信号是低通滤波所得,与编码造成的损伤不同。
2022年4月,Moliner E和Vlimki V提出BEHM-GAN[3],使用钢琴古典乐训练,盲听测试结果表明该算法对20世纪初的留声机录音修复后,主观听感音质得到有效提升。该工作的低分辨率信号是去噪、去失真之后的低采样率信号,目标是上采样。
2022年11月,Yan Yanqiao等人[4]使用WassersteinGAN网络生成高频幅度谱,该研究认为传统的相位翻转或是Griffin-lim算法对于音乐信号而言,相位预测质量过低且有很多冗余计算,因此使用全连接网络估计高频子带相位。在对数谱失真LSD及段信噪比segSNR指标上均优于相位翻转及Griffin-lim算法。
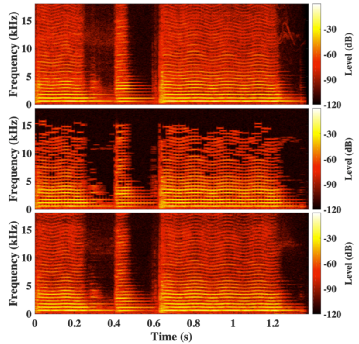

2022年12月,美国杜比实验室的Davidson G等人提出MDCTNet[5],使用RNN同时在时间维及频率维方向,捕捉经修正离散余弦变换后的谱的相关性。该工作的低分辨率信号正是编码后受损的信号,该网络可同时完成填补低频空洞及重构音乐高频成分的任务目标。在10名专业听音人员对多种音乐内容的主观测听中,修复后的音乐,相比于24kbps比特率编码的音乐,主观感受到的比特率相当于48kbps。
三、思考及讨论
(1)音乐修复,其实隶属于音频超分辨(Audio Super Resolution)这一大的研究领域,其下还有语音带宽扩展(Bandwidth Extension, BWE)这一小分支。但相比于语音BWE,音质修复在任务难度上会更加艰巨。这体现在:
- 在缺损成分上,音质修复不仅要重构高频,还需要填补低频处的空洞,语音信号只需重构高频即可。
- 在数据相关性上,语音信号在结构规律上相对简单,浊音的谐波成分在低、高频信号相关性好,清音音节/素在功率谱高频的能量“涂抹”区域及深浅也可预测出来。但音乐信号千变万化,低、高频相关性差,部分乐声如“风铃声”甚至完全没有相关性,基本不可能从残留的、微弱的、编码后损伤的低频成分预测出原本的高频成分。
- 在听感上,语音BWE如做好,可较容易听出音域拓展的收益。但音乐编码后带宽覆盖较宽,如单通道48kHz信号经AAC格式按32kbps码率编码后带宽可达13kHz,已覆盖普通人的敏感听阈带宽。AI音质修复算法有收益,即便是受过专业训练的金耳朵,也需要数次凝神聆听、反复确认才能听出收益,但一旦生成异响或杂音,即便是未经训练的普通人,也可一耳朵听出异常。工业级的、可落地的音乐修复算法,即便收益甚微、聊胜于无,也不能有异响。
(2)对于个别时变性强,且低、高频相关性较差的音乐信号种类,如鼓声、铃声、䃰声,需要运用如DrumGAN的相关工作,才能达到较好的音质修复效果。
参考文献:
[1] Kabal P. An Examination and Interpretation of ITU-R BS.1387: Perceptual Evaluation of Audio Quality.
[2] Hu S, Zhang B, Liang B, et al. Phase-aware music super-resolution using generative adversarial networks[J]. 2020.
[3] Moliner E, Vlimki V. BEHM-GAN: Bandwidth extension of historical music using generative adversarial networks[J]. arXiv e-prints, 2022.
[4] Yan Y, Nguyen B T, Geng Y, Iwai K, Nishiura T. Phase-aware audio super-resolution for music signals using Wasserstein generative adversarial network[C]//Asia-Pacific Signal and Information Processing Association Annual Summit and Conference. Thailand, 2022, 1673-1677.
[5] Davidson G, Vinton M, Ekstrand P, et al. High quality audio coding with MDCTNet[J]. 2022.
作者:王佳杰
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。