
大规模的文本到图像扩散模型已经取得了惊人的进步。然而,现状是只使用文本输入作为条件,这可能会阻碍可控性。GLIGEN,是一种基于定位语言的图像生成,在现有的预训练文本到图像扩散模型的基础上,增加了对定位输入的支持。为了保留预训练模型中已经学习到的丰富的概念知识,我们冻结了所有的权重,并通过一个门控机制将定位信息注入到一些新的可训练层中。我们的模型实现了开放集的基于定位语言(Grounded Language)的图像生成,可以使用边界框、关键点或图像作为定位输入,并且定位能力可以很好地泛化到新颖的空间配置和概念。GLIGEN在 COCO 和 LVIS 两个数据集上进行了零样本评估,并与现有的有监督布局到图像方法进行了比较。结果表明,GLIGEN在生成质量、准确性、多样性等方面都显著优于有监督方法。
论文题目:GLIGEN: Open-Set Grounded Text-to-Image Generation
来源:CVPR 2023
作者:Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li and Yong Jae Lee
项目主页:https://gligen.github.io/
代码链接:https://github.com/gligen/GLIGEN
内容整理:张育荣
引言
文本到图像生成(Text-to-Image Generation)是指根据输入的文本描述,自动合成与之相符的图像。这是一个具有广泛应用前景的研究领域,例如可以用于创意设计、虚拟现实、教育娱乐等场景。近年来,随着深度学习和自然语言处理的发展,文本到图像生成的技术也取得了令人惊叹的进步。特别是基于扩散模型(Diffusion Model)的方法,能够利用大规模的文本和图像数据进行预训练,从而实现高质量、高分辨率、多样性和零样本的文本到图像生成。
然而,现有的基于扩散模型的文本到图像生成方法,都只使用了文本输入作为条件,这可能会限制生成结果的可控性和准确性。例如,如果输入的文本描述比较模糊或者包含多个概念,那么生成的图像可能会不符合用户的期望或者存在歧义。为了解决这个问题,该文章提出了一种新颖的方法,称为GLIGEN(Grounded-Language-to-Image Generation),即基于定位语言(Grounded Language)的图像生成。该方法能够在现有的预训练好的扩散模型的基础上,增加对定位输入的支持,从而实现开放集的基于定位语言的图像生成。
此外,之前的生成模型,无论是哪种类型的生成模型,通常在特定任务的数据集上进行训练。对比而言,在识别领域,一些长久存在的识别范式都是从大数据集上训练的基础数据集或者图像-文本对开始的。由于扩散模型已经在数以亿计的图像-文本对上训练过,就出现了了一个很自然的问题:可以在现有的预训练扩散模型的基础上赋予它们接受新的条件输入模态的能力吗?和识别范式相似,GLIGEN 在大数据获得的概念知识基础上取得强大的性能,同时还能在现有的文本-图像生成模型的基础上拥有可控性。
这篇文章的主要贡献有:
- 提出了一种新的从文本生成图像的方法,在现有的从文本到图像的扩散模型的基础上加入了新的定位控制能力。
- 通过保护预训练的权重,学习逐渐整合新的定位层,模型可以用边界框得到开放世界定位性的文本到图像的生成,例如,在训练中未曾见过的新的定位概念的生成。
- 在布局到图像任务上的零样本功能显著超过了之前的SOTA,阐明了将大的预训练生成模型应用于下游任务的强大能力。
方法-开集的定位图像生成
定位指示输入
对于定位文本到图像的生成,目前有很多种方式通过额外的条件来定位生成过程。定义定位实体的语义信息为 e,可以通过文本或者样本图像来描述。l 表示定位空间设置,用标注框,一系列关键点,或者边缘图等来描述。注意到在特定情况下,语义和空间信息可以被单独用 l 表示(比如边缘图),在这种情况下一个提示可以同时表达图片中的具体目标和位置。定义定位文本到图像的模型为题目和定位实体的组合:指示:y = (c,e), 其中题目:c = [c1,…,cL]定位:e = [(e1,l1),…,(eN,lN)]其中 L 是题目的长度,N 是定位实体的数目。这项工作中,初步研究了标注框作为 l,文本作为定位实体 e,将题目和定位实体处理都处理为扩散模型的输入符号。
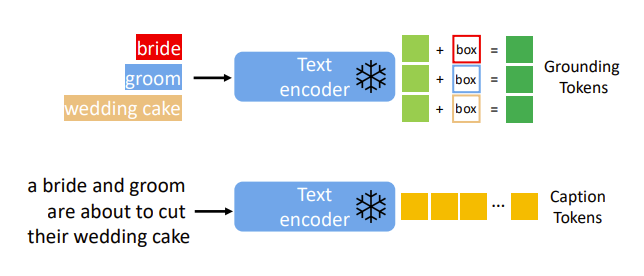


对于定位生成的连续学习
GLIGEN 的目标是赋予现有的大型大的语言到图像生成模型以新的空间定位能力。大的扩散模型已经在网络尺度的图像-文本对上进行了预训练来得到基于复杂多样的文本提示生成图像的知识。由于预训练的高投入和好表现,当扩展新能力时保留预训练模型权重的知识很重要。因此考虑锁住原始的权重,通过微调新的模块来进行模型的适应。
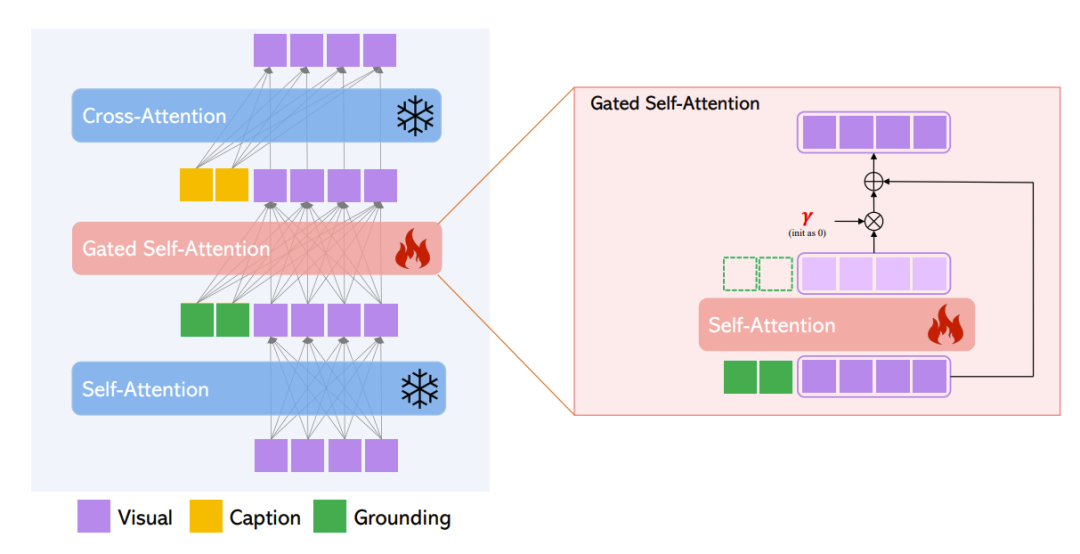
门控自监督
定义 v = [v1,…,vM] 作为图像的视觉特征符号。原始的 LDM 的 Transformer 块包括两层注意力层:视觉符号的自监督,和题目符号的交叉监督。通过考虑残差连接,这两层可以被写为:
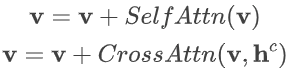
固定这两层的权重,增加一个新的门控自监督层来加入空间定位能力。具体来说,注意力基于视觉和定位符号的拼接[v,he]
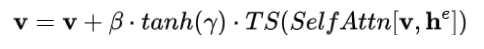
其中 TS 是一个只考虑视觉符号的符号选择操作, γ 是一个初始化为0的可学习标量,β 在整个训练过程中被设为1,只是在推理时会因预定采样过程而发生改变,来提高质量和可控性。直观来讲,门控自注意使得视觉特征利用了条件信息,结果的定位特征被视为残差,门控初始被设为0。这种设置导致了稳定的训练,同样的思路被用在了 Flamingo 中。
GLIGEN 适应了预训练模型导致定位信息可以被注入,原始的组件完好。将所有新参数定位 θ‘,包括所有的门控自注意层和 MLP,为了模型的持续学习使用了原始的去噪目标,基于定位指示输入 y:
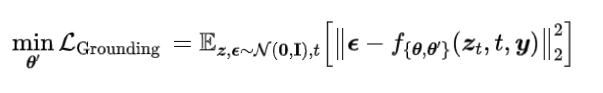
实验结果
GLIGEN 在闭集和开集上都评估了标注框定位的文本到图像的生成,并且表现出其他定位模态的扩展。
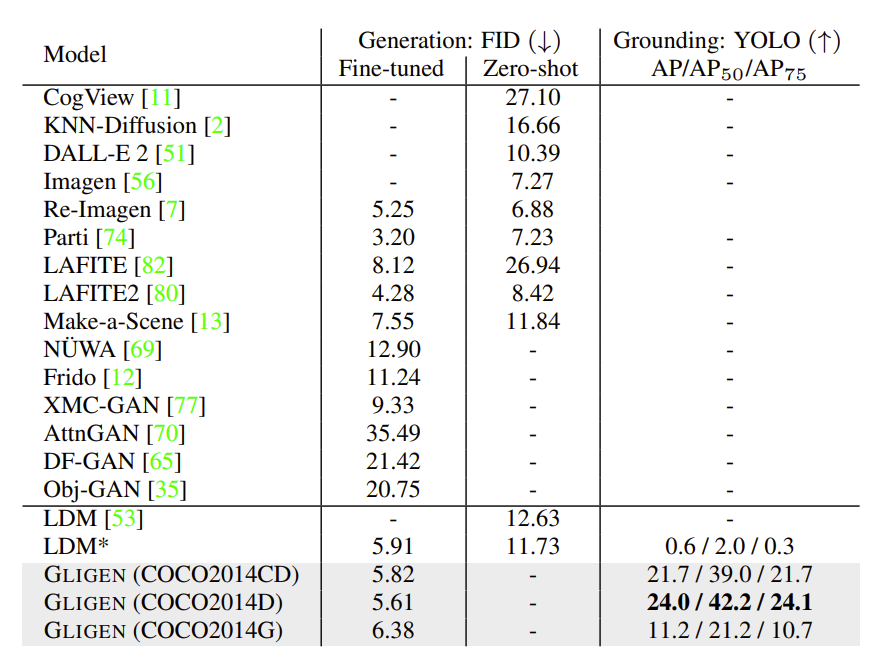
闭集上,在 COCO-2014 验证集上生成的图像质量和定位准确度如下表所示。可以看出,图像生成质量 (用 FID 衡量) 优于大多数 sota 基线方法,这受益于预训练中学到的视觉知识。此外这项实验也显示出 GLIGEN 成功地以标注框为额外条件,在保留图像生成质量的前提下,有效地利用了定位指示。
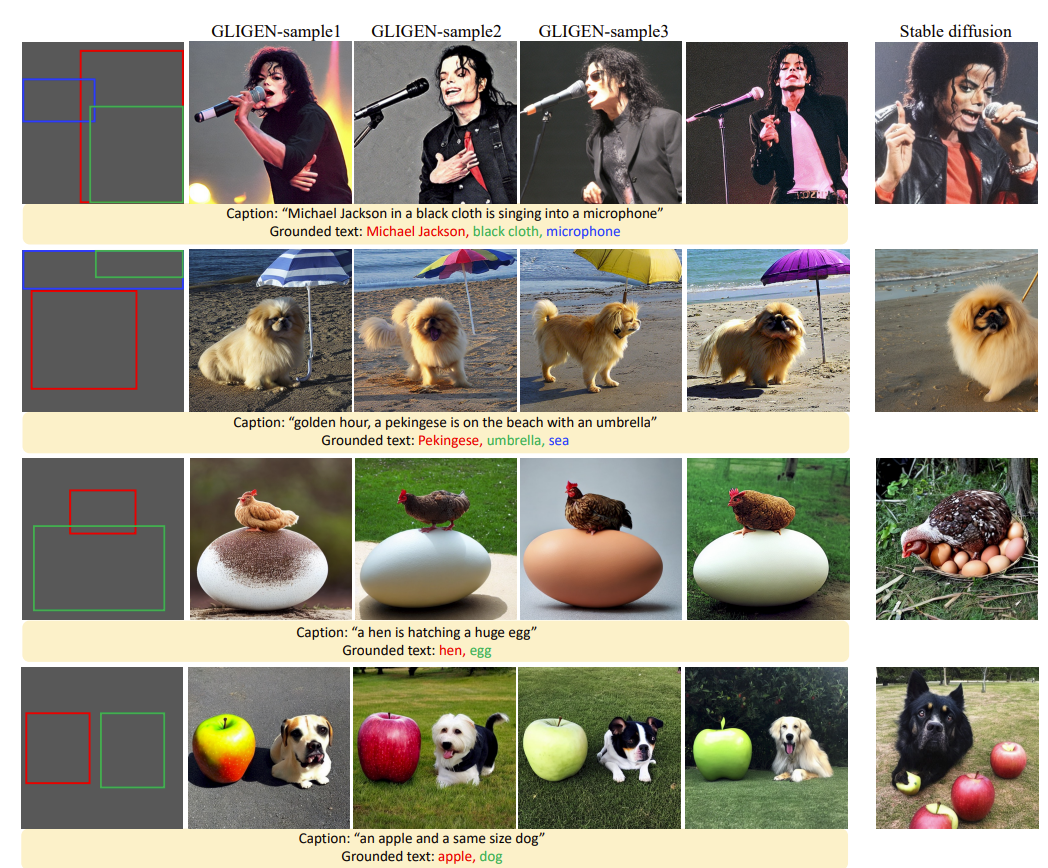
开集上定位文本到图像的生成如下图所示,可以看出 GLIGEN 在定位的引导下生成效果比较经验,成功地利用定位信息进行了自然的生成。
总结
GLIGEN 用定位能力扩展了预训练的文本到图像的扩散模型,阐明 把标注框作为定位条件的开放世界的生成。该方法简洁有效,可以被简单扩展到其他条件比如点,参考图像,空间对齐的其他条件。GLIGEN 的多样性使它成为加速文本到图像生成一个有前景的方向,在多个领域扩展预训练模型的能力。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。