
在日常生活的对话中,人们会提及他人不熟悉的主题内容。在Zoom等在线会议中,即时的字幕可以帮助人们理解他人所说的话语。在这些场景下,该工作提出使用视觉图像进行辅助传达信息。具体来说,该工作设计了一个基于在线会议平台的AI辅助插件 [1],在用户的对话交流中进行多种方式的视觉图像推荐。用户可以通过Visual Caption所推荐的视觉图像进一步阐明自身的观点和内容。


图1展示了该工作中三个主要贡献。首先,作者通过众包完成了一个涵盖超过1500个用户意图的数据集。该数据集被用于微调语言模型。其次,作者通过微调语言模型进行视觉字幕的预测。该模型根据用户前置的语音文字产生结构化的输出。最后,作者设计了一个视觉字幕的界面。用户可以浏览备选的视觉图像并且自由的选择将其公开展示。
作者首先通过一个形成性研究探索了视觉说明的设计空间。如图2中所展示,作者总结了8个设计的维度。本工作主要聚焦于视觉字幕的即时性(1),视觉图像的内容(3)和AI推荐的自动化程度(7)。该工作所涉及的插件具备实时生成视觉字幕的能力。
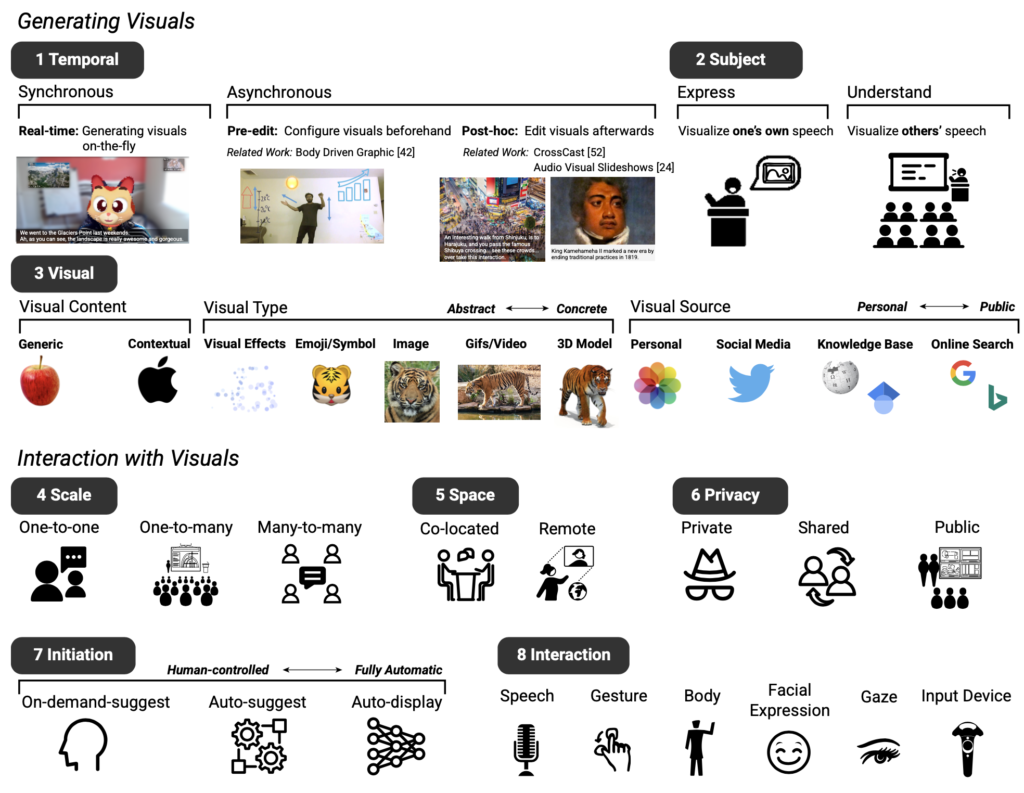
根据不同的内容推荐来源不同的基于该设计空间,作者设计了三种交互模式,即根据用户请求(On-demand-suggest)、根据AI推荐(Auto-suggest)和AI全自动(Auto-display)。根据用户请求模式下只有当用户单击空格键时才会推荐视觉字幕。在AI推荐模式下,系统会自动向用户推荐视觉说明,但用户可以选择性的筛选进行显示。在AI全自动模式下,系统将自动生成并且展示视觉说明,用户不需要任何操作。
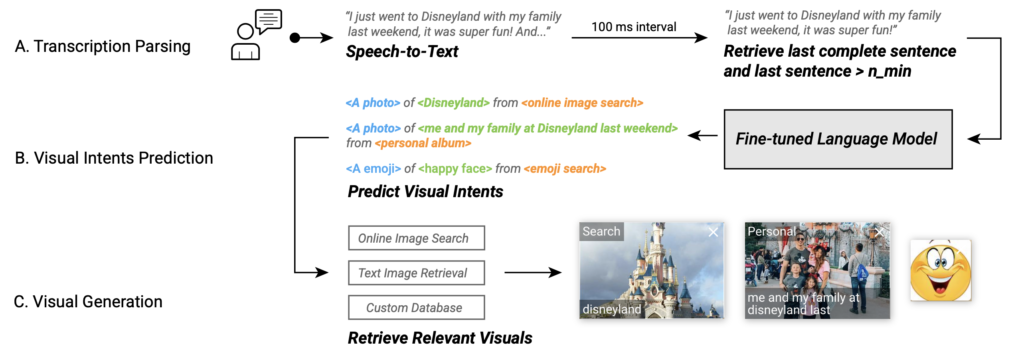
该工作生成视觉说明的方式如图3所示。首先将讲者的语音转为文字,并且储存符合规定的两条完整话语。这两条话语作为prompt输入到语言模型中,该模型在VC1.5K数据集上微调并将会输出结构化的语句。这些语句蕴含了三个属性信息,即“视觉内容”(visual content),“视觉形式” (visual type)和“视觉来源” (visual source)。接着,该工作根据该结构解析模型所输出的语句,并且通过对应的“视觉来源”进行图像的搜索。最后通过CLIP模型筛选出最符合语句描述的视觉图像作为输出。
为了确保模型能够输出满足要求的结构化语句,该工作通过众包的方式构建了微调数据集VC1.5K。原始数据源于42个Youtube视频字幕和DailyDialog对话文本。众包工人将判断每一条对话所对应的“视觉来源”、“视觉内容”和“视觉形式”,从而形成一个用户意图的数据。该数据集总共包含了1595个用户意图。
最后,该工作进行了多个用户实验,试图发掘用户使用视觉说明的习惯,视觉说明对用户交流的影响。除此之外,用户实验希望获取用户对于该AI系统在交互方面的偏好。该工作召集了20位参与者,两两分为10组。每一组将进行4个预先准备好对话稿和10分钟的自由对话。之后,获取用户对系统和交互方面的意见。通过该用户试验可以发现,视觉说明可以帮助用户理解不熟悉的概念、减少语言中的模糊性、使已知的知识更符合直觉、领对话更加有趣,并且不会让用户在对话中分心。在用户与AI系统交互方面,该工作发现不同人在不同场景下对于三种交互模式的偏好具备很大差别。
[1] Liu, Xingyu” Bruce, et al. “Visual Captions: Augmenting Verbal Communication With On-the-Fly Visuals.” Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 2023.
作者: Mei, Xiyao
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。