
近日,“AI孙燕姿”翻唱歌曲在各大网络平台上走红。5月22日晚,歌手孙燕姿在社交平台发文回应称,人类无法超越AI技术已指日可待,凡事皆有可能,凡事皆无所谓,“我认为思想纯净、做自己,已然足够”。AI歌手是指通过计算机程序模拟出来的声音,可以进行唱歌表演的虚拟歌手。四月份开始,“AI孙燕姿”成为了网络上最热门的歌手,其翻唱的《发如雪》《爱在西元前》《半岛铁盒》等作品广受好评。现在,除了AI孙燕姿,还有AI周杰伦、AI王菲,甚至出现了AI特朗普、AI孙笑川。这一次AI的表现惊艳了许多听众,比如“AI孙燕姿”的音色与孙燕姿原声几乎一样、高产、唱歌着调、唱功优秀、情感表现上稍有不足。随着人工智能技术的不断发展,AI歌手已经具备了相当高的音乐表现力和艺术性。

一、AI歌手的技术原理
AI孙燕姿是利用名为 SoVitsSvc (SoftVC VITS Singing Voice Conversion) 的开源项目(目前更新到4.1版本),生成了孙燕姿音色的歌曲。SoVitsSvc是一个歌声音色转换模型,通过SoftVC内容编码器提取源音频语音特征,与F0同时输入VITS替换原本的文本输入达到歌声转换的效果。同时,更换声码器为 NSF HiFiGAN解决断音问题。
具体来说,生成一个“AI歌手”主要分为四个步骤:
- 数据收集:收集大量的音频数据和歌词数据,用于训练模型。
- 特征提取:从收集到的音频数据中提取特征,例如频率、振幅、时域特征等。
- 模型训练:使用深度学习算法,对收集到的数据进行训练,从而生成新的音乐作品或者模拟人类歌唱的声音和表现力。
- 歌曲生成:根据训练好的模型,生成新的音乐作品或者模拟人类歌唱的声音和表现力。
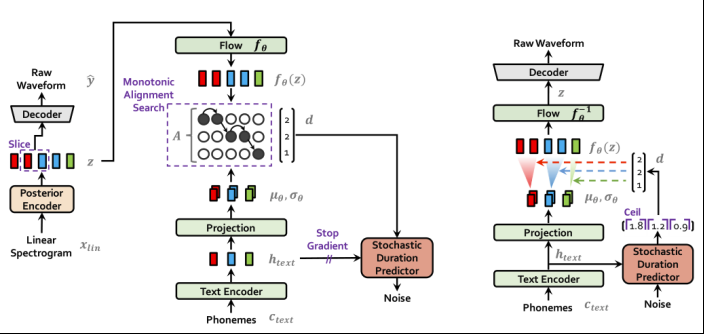
Kim[1]提出了一种新的端到端文本到语音(TTS)模型,这个模型采用了变分推断(variational inference)和对抗训练(adversarial training)等技术,以提高生成建模的表现力。此外,它还引入了随机持续时间预测器(stochastic duration predictor),以从输入文本中合成具有不同节奏的语音。下图分别展示了该模型的培训程序及推理过程。
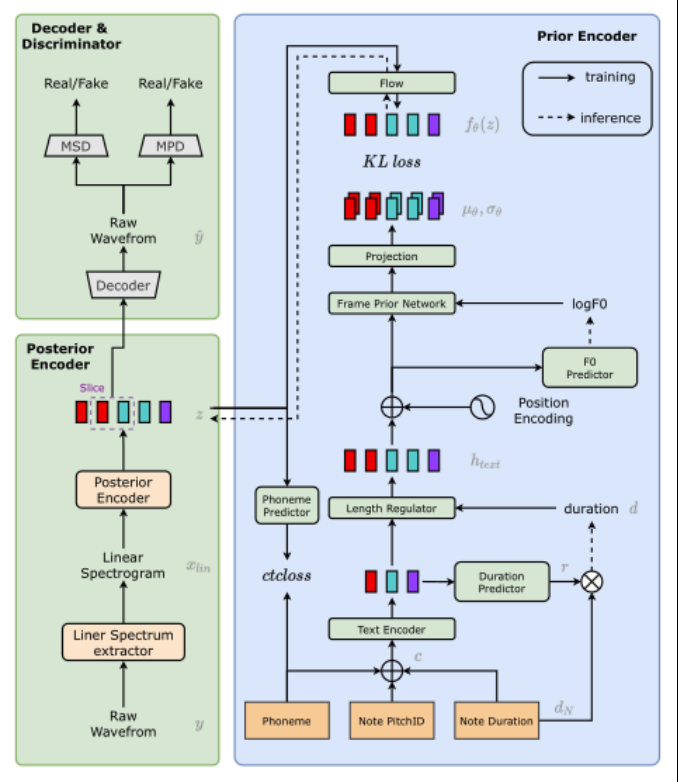
2021年,西北工业大学的Zhang Yongmao教授[2]提出了一种名为VISinger的高质量歌声合成系统,该系统可以直接从歌词和乐谱中生成音频波形。VISinger的技术架构主要由三个部分组成:后验编码器、先验编码器和解码器。其中,后验编码器采用了变分自编码器(VAE)的结构,先验编码器采用了基于正则化流(NF)的结构,解码器采用了对抗生成网络(GAN)的结构。这三个部分共同协作,实现了从歌词和乐谱到音频波形的端到端歌声合成。VISinger的技术架构如下图所示:
二、AI歌手未来的应用
AI歌手的应用场景非常广泛,包括音乐制作、电影配乐、广告音乐、游戏音乐等。此外,AI歌手还可以用于音乐教育、语言学习和文化交流等领域。
随着人工智能技术的不断发展,AI歌手的前景也越来越广阔。未来,它将成为音乐产业中不可或缺的一部分,为音乐创作和表演带来更多可能性。虽然由于技术上的限制以及版权等问题,目前AI歌手还无法完全替代真人歌手。但随着技术的进步以及法律的完善,AI歌手会有更惊艳的表现和更规范的创作形式。
作者:宋则豪、徐晨阳
来源: 21dB声学人
原文:https://mp.weixin.qq.com/s/Vz4UfqTtuHMP-YBlDPOWDQ
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。