
本文提出了一种通过文本来编辑 NeRF 场景的方法。给定一个 NeRF 场景及用于重建它的多视角图像,本方法利用图像条件扩散模型InstructPix2Pix对输入图像进行迭代编辑,并同时优化底层场景,从而得到一个符合编辑指令的优化 3D 场景。相比之前的方法,本方法能够编辑大规模的现实世界场景,并实现比较真实、有针对性的编辑效果。
来源:arxiv
论文链接:https://arxiv.org/abs/2303.12789
项目链接:https://instruct-nerf2nerf.github.io/
作者:Ayaan Haque et al.
内容整理:陈梓煜
简介


随着神经渲染技术的出现,重建真实世界三维场景的逼真数字表示变得简单:从不同视角拍摄场景的图像集合,估计相机参数,并利用这些图像来优化神经辐射场(Neural Radiance Field)。尽管将真实场景转化为三维表示的流程相对成熟且易于操作,但用于创建三维资产(例如用于对三维场景进行编辑的工具)的其他必要工具仍处于不完善状态。
传统的3D模型编辑过程需要3D艺术家使用专门的工具,手动雕刻、挤压和重新贴图一个给定的物体。随着神经表示的出现,这个过程变得更加复杂,因为神经表示是隐式表示,没有明确的表面。这进一步促使我们隐式表征编辑的需求。
因此,我们提出Instruct-NeRF2NeRF,用于编辑3D NeRF场景,它只需要一个文本指令作为输入。我们的方法基于预先拍摄3D场景进行操作,并确保编辑的结果以一种3D一致的方式呈现。例如,给定一个人的3D场景,如图1(左),我们可以使用灵活的文本指令(例如“给他戴一个牛仔帽”或“把他变成阿尔伯特·爱因斯坦”)进行各种编辑。我们的方法使得3D场景编辑对于日常用户来说更加易于操作。
现有的3D生成模型在规模上训练这些模型所需的数据源仍然有限。因此,我们选择从2D扩散模型中提取形状和外观先验。具体而言,我们采用了最近的图像条件扩散模型——InstructPix2Pix,它可以实现基于指令的2D图像编辑。然而,将该模型应用于从重建的NeRF生成的各个视角时,图像会出现3D不一致的编辑效果。我们设计了一种类似于DreamFusion的方法,即迭代数据集更新(Iterative Dataset Update,简称Iterative DU),它在编辑NeRF输入图像集和更新底层3D表示以融入编辑图像之间进行交替操作。
我们在多个NeRF场景上对我们的方法进行评估,本方法可以在人物、物体和大规模场景上完成各种各样的编辑。
方法
我们的方法以重建的 NeRF 场景及其对应的源数据作为输入:一组捕捉图像、它们对应的相机内外参数。我们的方法还接受自然语言的编辑指令作为输入,例如“把他变成阿尔伯特·爱因斯坦”。作为输出,我们的方法会生成根据提供的编辑指令编辑过的 NeRF 场景,以及输入图像编辑后的版本。我们的方法通过使用扩散模型来迭代地更新多视角图像内容,并通过NeRF训练将这些编辑结果在3D中加以整合,从而完成这个任务。
先验知识
NeRF
NeRF(神经辐射场)是一种紧凑且方便的表示方法,用于重建和渲染体积化的 3D 场景。

InstructPix2Pix

Instruct-NeRF2NeRF
编辑渲染结果
在给定重建的NeRF场景、对应的图像和相机参数、和文本指令的情况下,我们通过对重建模型进行微调,朝着编辑指令的方向生成一个编辑后的NeRF版本。图2提供了一个概述。
我们的方法使用迭代式数据集更新,其中训练数据集图像使用扩散模型进行迭代更新,然后通过在这些更新后的图像上训练NeRF,将其整合到全局一致的3D表示中。这个迭代过程允许扩散先验逐渐渗透到3D场景中。虽然这个过程可以实现对场景的全局编辑,但我们使用基于图像的扩散模型(InstructPix2Pix)有助于保持原始场景的结构和特征。
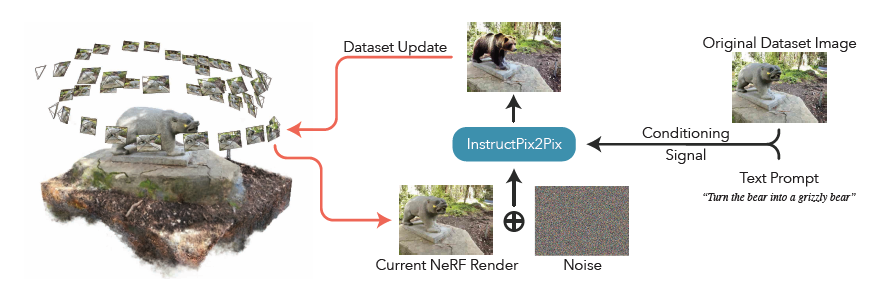
迭代式数据集更新
我们方法的核心是一个交替过程,其中图像从NeRF中渲染出来,经过扩散模型的更新,并随后用于监督NeRF的重建。我们将这个过程称为迭代式数据集更新。

编辑过程导致原始数据集图像在编辑后被改变。在早期迭代中,这些图像可能会执行不一致的编辑,因为InstructPix2Pix通常在不同视角上不执行一致的编辑。随着时间的推移,图像用于更新NeRF并逐渐重新渲染和更新,它们开始收敛到对编辑场景的全局一致描述。图3展示了这个演化过程的示例。
这个迭代DU过程可以被解释为DreamFusion中得分蒸馏采样损失(SDS)的一种变体,不同的是在每个步骤中不是更新一组离散的图像,而是每次梯度更新时都采样许多视角上的随机混合射线,沿着这些射线计算的梯度既包含上一次被更新的NeRF区域,也包含上一次没有更新的NeRF区域。采用迭代DU的目的是在每次迭代中最大限度地提高训练射线视角的多样性,我们发现这样的选择极大地提高了训练的稳定性和效率

实验
场景编辑

我们的定性结果显示在图1和图4中。对于每个编辑,我们展示了多个视角以说明3D的一致性。在图1中的肖像场景中,我们能够实现全局的编辑,从全局范围的“Turn him into a Modigliani painting”到“Turn his face into a skull”。尽管添加一个全新的对象和DreamFusion的任务一样具有挑战性,但我们的方法能够添加上下文元素,如“Give him a cowboy hat”和“mustache”。
此外,我们的方法能够在一定程度上给人物穿衣服,如图4中的全身肖像,第三行所示。它可以实现材料的变化,如作为青铜半身像和使他成为大理石雕像。在青铜的情况下,还捕捉到了微妙的视角相关变化。
我们的方法还能将肖像变成着名人物,如爱因斯坦,以及虚构角色如蝙蝠侠。这些编辑也适用于人以外的主题,比如将熊雕塑变成真正的北极熊、熊猫和灰熊(图4最后一行)。值得注意的是,这些编辑也适用于大规模场景,图5底部),并支持修改白天时间、季节和其他条件(如雪和沙漠)的指令。

和NeRF-Art对比
我们与NeRF-Art进行了比较,我们使用他们提供的自定义多视场景,使用我们的方法进行类似的编辑。他们提供的场景比较结果如图6所示。请注意,他们的文本输入不是指令,这使得模型在编辑方面存在歧义。例如,在他们的“Van Gogh”示例中,不清楚模型应该创建一幅梵高风格的绘画,还是让脸看起来像梵高的脸。

版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。