
本文针对传统视频编码器的前处理问题,提出一种有效的训练策略和轻量化前处理模型,经测试,在H.264、H.265、H.266上都能获得一定的增益效果。
论文标题:Rate-Perception Optimized Preprocessing for Video Coding
作者:Chengqian Ma, Zhiqiang Wu, Chunlei Cai, etc. Bilibili Inc.
论文链接:https://arxiv.org/pdf/2301.10455v1.pdf
内容整理:陈予诺
引言
在过去几十年中,视频压缩领域取得了许多进展,包括传统的视频编解码器和基于深度学习的视频编解码器。然而,很少有研究专注于使用前处理技术来提高码率-失真性能。在本文中,我们提出了一种码率-感知优化的前处理(RPP)方法。我们首先引入了一种自适应离散余弦变换损失函数,它可以节省比特率并保持必要的高频分量。此外,我们还将低级视觉领域的几种最新技术结合到我们的方法中,例如高阶退化模型、高效轻量级网络设计和图像质量评估模型。通过共同使用这些强大的技术,我们的RPP方法可以作用于AVC、HEVC和VVC等不同视频编码器,与这些传统编码器相比,平均节省16.27%的码率。在部署阶段,我们的RPP方法非常简单高效,不需要对视频编码、流媒体和解码的设置进行任何更改。每个输入帧在进入视频编码器之前只需经过一次RPP处理。此外,在我们的主观视觉质量测试中,87%的用户认为使用RPP的视频比仅使用编解码器进行压缩的视频更好或相等,而这些使用RPP的视频平均节省了约12%的比特率。我们的RPP框架已经集成到我们的视频转码服务的生产环境中,每天为数百万用户提供服务。我们的代码和模型将在论文被接受后发布。
方法
整体框架


上图中左侧为本文前处理器的工作流程:对输入帧进行单帧处理,适用于所有标准视频编解码器。右图:H.265与RPP + H.265的在相同的MS-SSIM下的码率差异。
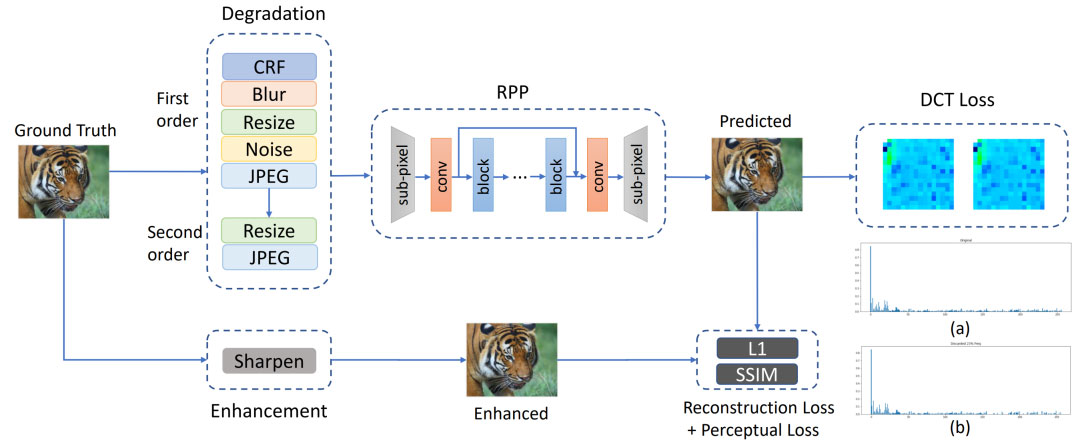
我们的前处理模型的目标是通过可学习的前处理神经网络提供一个同时在码率和感知方面进行优化的输入帧。具体而言,为了在码率和失真之间实现模型的优化平衡,我们设计了一种自适应的DCT损失,可以减少空间冗余并保留感知中的关键高频成分。另一方面,对于感知优化部分,我们旨在通过使用MultiScale-SSIM来感知地增强我们的前处理输入帧。我们将其用作训练过程中的损失函数。此外,我们还结合了高阶退化建模过程来模拟真实世界的复杂退化。通过使用这种高阶退化方法生成训练数据对,我们的前处理网络可以训练来处理真实世界中的一些复杂退化,从而提高网络输出的感知质量。此外,为了性能和效率,我们构建了一个轻量级的全卷积神经网络,其中包含通道注意力机制。在部署框架中,对于给定的视频帧fi,它只需通过RPP网络进行一次前向传递。然后,RPP网络的处理帧 f0 可以由标准视频编解码器(如AVC、HEVC、VVC或AV1编码器)进行编码。
二阶 Degradation
训练数据的退化建模方式对于提高网络训练过程中的视觉质量非常重要。我们将一些常见的退化方法包含在我们的退化模型中,例如模糊、噪声、调整大小和JPEG压缩。对于模糊,我们使用各向同性和各向异性高斯滤波器来建模模糊退化。我们选择了两种常用的噪声类型,即高斯噪声和泊松噪声。对于调整大小,我们使用了上采样和下采样,包括区域、双线性和双三次插值。由于在实际应用中,我们框架的输入帧大多是从压缩视频解码而来,因此我们添加了视频压缩退化,这可能会引入空间和时间域的块状和振铃伪影。正如我们之前提到的,高阶退化建模已经被提出能更好地模拟复杂的真实世界退化。我们也在图像退化模型中使用了这个思想。通过使用这些退化模型生成训练对,我们的目标是使模型具有去除常见噪声和压缩噪声的能力,这也可以优化码率,因为视频编解码器不能很好地编码噪声。
DCT Loss
尽管距离DCT在图像/视频压缩算法中首次引入已经过去了很多年,但由于其高效性和易用性,类似DCT的变换仍然是主流变换。一般来说,二维DCT的基函数可以表示为:
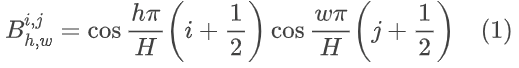
二维DCT变换可以写为:
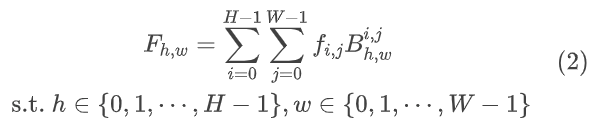
在图像中,大部分能量将集中在较低的频率上,因此在传统的压缩算法中,它们简单地丢弃了较高频率的系数以减少空间冗余。然而,一些高频分量在整个帧的视觉质量中也起着非常重要的作用。我们引入了自适应DCT损失用于视频预处理。我们使用DCT将帧转换到频域后,我们通过使用ZigZag顺序遍历选择属于高频分量的频率系数I。公式可以写为:
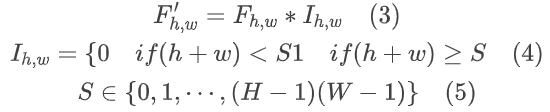
在DCT频域中,频率系数的值表示整个帧中该频率分量的能量大小。如果一个频率分量的能量较小,意味着该频率分量在重构帧时相对不太重要。因此,我们希望丢弃一些具有相对较小系数值的高频分量。在这种情况下,我们对这些选定系数的绝对值进行平均,得到一个阈值T,可以表示为:

实验
对传统编码器的性能提升
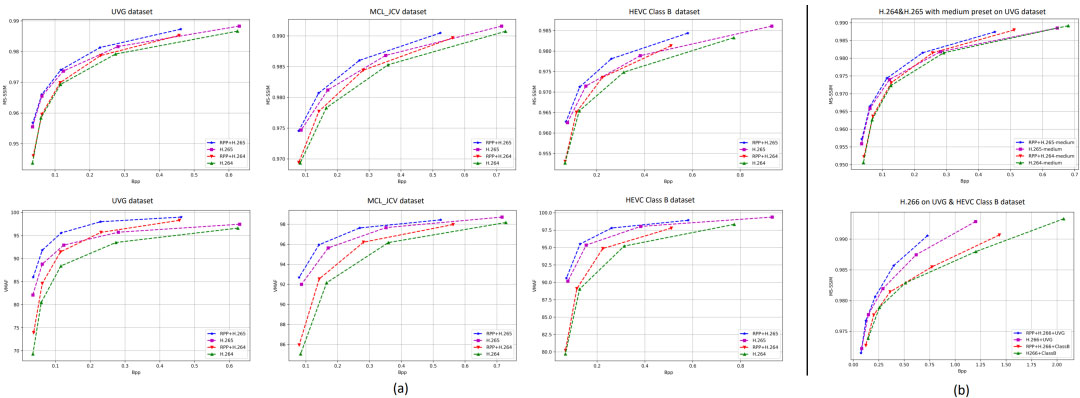
上图和以下三个表的结果显示,我们提出的方法可以明显提升三个数据集上标准编解码器的VMAF和MS-SSIM两个指标的BD-rate。在VMAF下,RPP + H.264平均节省18.21%的码率。在MS-SSIM下节省8.73%的码率。在VMAF下,RPP + H.265平均节省24.62%的码率,在MS-SSIM下节省13.51%的码率。一些基于学习的视频编码器只有在“very fast”预设下才能超越传统标准编解码器。为了证明我们方法的通用性,我们还使用“medium”预设测试了我们的RPP方法。如图中(b)的顶部图所示,我们的方法仍然优于标准编解码器,这与(a)中的“very fast”预设结果一致。此外,我们还在UVG数据集和HEVC B类数据集上使用H.266测试了我们的RPP方法。如图中(b)的底部图所示,在这两个数据集上,RPP + H.266的平均码率节省率在MS-SSIM下为8.42%。正如我们预期的那样,当与所有主流标准编解码器联合使用时,我们的方法都可以获得显著的提升。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。