
在紧急事件(如人为或自然灾害地区)中,准确、迅速地提供紧急医疗服务(EMS)至关重要。然而,在复杂的医疗场景中快速选择正确的 EMS 协议(规定对患者实施的医疗程序),仍然是紧急医疗技术人员 (EMT) 的一项关键而艰巨的任务。本文介绍了 EMSAssist,这是第一款用于急救医疗服务的端到端边缘移动语音助手。
EMSAssist 由三个主要部分组成,可解决最先进解决方案中存在的技术难题:
1)EMSAssist 首次在医疗语音识别任务中提出并应用了少量样本微调技术,与谷歌云 Speech-toText 相比,该技术在EMS 音频数据集上实现了更快更准确的语音转录;
2)WordPiece 标记器通过从错误转录中检索有用信息,帮助提高端到端 EMS 协议选择的准确性;
3)新颖的数据定制框架使我们的数据驱动 EMSMobileBERT 模型成为 EMS 协议选择的新标准。广泛的边缘端到端评估结果表明,EMSAssist 可以更准确地为急救医生选择急救协议(前五名的准确率超过96%),端到端延迟时间约为 4.2 秒。
1、介绍
紧急医疗服务(EMS)是对包括人员、设备和设施在内的资源进行协调,以应对紧急医疗事件。在各种紧急情况下都需要急救医疗服务,从家庭成员急救到车祸,再到通常会造成大量人员伤亡的灾区,例如 2021 年佛罗里达州 Surfside 的建筑物倒塌事件。作为最重要的院前灾难响应服务,由急救医疗技术员和辅助医务人员(均称为 EMT)提供的专业急救医疗服务可在灾区挽救受害者的生命并降低死亡率。
通过初步评估患者的医疗体征和症状(例如,机动车碰撞后的脑出血、心脏病患者的心电图),急救医生通过选择规定对患者实施适当医疗干预的方案来提供急救服务。良好的方案选择策略有助于就治疗方案做出合格的临床决策。然而,急救医疗方案的选择任务具有挑战性。
一方面,要具备进行症状评估和方案选择的专业资格,需要长期反复地各种急救医疗专题培训(如解剖生理学、心脏病学、药物和医疗程序)。当急救医疗人员从一个急救医疗机构转到另一个急救医疗机构时,还需要接受额外的再培训,因为每个急救医疗机构都会制定一套独特的规程。
另一方面,即使是现场经验丰富的急救医疗人员,在选择适当的规程时也要讲究技巧。病人瞬息万变的医疗状况、护理标准以及同时选择的规程之间的矛盾,共同导致了突发决策的复杂性。为了应对这些挑战,最先进的解决方案(即 SOTA)提出了虚拟助手(VA)来协助急救医生。急救医生向虚拟助手口头描述他们对病人症状的评估,然后虚拟助手处理语音,并将急救协议和医疗干预措施返回给急救医生。


b) 紧急医疗救护人员正在接受培训,使用可穿戴设备;
2、背景与挑战
2.1 面临的挑战
尽管此前已开展了建立急救医疗虚拟助理的工作,但挑战仍未得到解决:
挑战 1:开发端到端低延迟移动 EMS VA。在实际应用场景中,急救医生的双手忙于执行急救程序,大部分注意力则放在了解病人和周围环境的医疗状况变化上。端到端(即从急救医生的语音输入到医疗服务输出)的边缘移动 VA 可以为急救医生带来重要的免提便利,并通过协助急救协议选择减轻急救医生的工作量。
然而,SOTA VA非部署在边缘。它的协议选择服务部署在带有图形用户界面的 Linux 计算机上,需要人工交互和连接到云端进行语音到文本的转录。非常需要一种在边缘端到端延迟较低、服务水平目标(SLO)为 5 秒的虚拟局域网。在一般的紧急医疗服务场景中,需要这种低延迟来进行即时急救药物管理。例如,一旦发现过敏性休克或怀疑即将发生过敏性休克,即使患者不符合诊断标准,也应尽快注射肾上腺素。延迟给药可能导致死亡。
挑战 2:在边缘建立准确可靠的语音转文本服务。语音转文本服务的准确性和可靠性对紧急医疗服务协议的选择有重大影响。SOTA EMS助手依靠稳定的无线网络接入和谷歌云提供准确可靠的语音转文本服务。然而,时延变化很大的无线互联网接入往往不可靠,给急救服务的最终交付带来了更多不确定性。要保证可靠的语音到文本服务,一种切实可行的方法是将其作为边缘服务部署,而不需要互联网接入。此外,除了延迟和准确性问题,由于隐私和法律问题日益严重,收集大型医疗音频数据集比收集计算机视觉和自然语言处理数据集要难得多。
挑战 3:在边缘构建准确的 EMS 协议选择服务。准确性是量化协议选择服务性能的最重要指标。在 SOTA中,采用了一种传统的模型驱动方法来选择适当的协议,这种方法基于以下强有力的基本假设:a) 特定患者的症状总是与目标协议的症状相似;b) 相似性可通过直接应用余弦运算来建模。这些假设削弱了 SOTA 解决方案的泛化能力,当应用于新的不同数据集时,会导致显著的精度损失。
挑战 4:为特定急救医疗机构定制 VA。由于每个地方 EMS 机构都有自己独特的协议集,因此必须为特定/地方 EMS 机构定制虚拟助手。事实上,数据稀缺是急救医疗领域长期存在的一个臭名昭著的问题,而数据稀缺的原因则是当地紧急事件的发生频率较低。因此,需要一个数据定制框架,以便在当地急救医疗机构以最低的标注成本获得大型标注数据集。
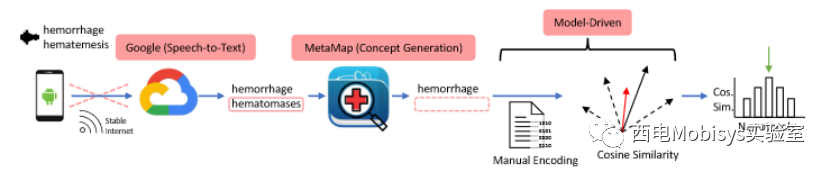
2.2 解决办法
上述所有研究挑战都是缺乏有效解决方案的通用挑战:准确、快速的边缘人工智能服务,有限的标记定制数据等。在本文中,聚焦于这些通用问题,提出了 EMSAssist 的设计与实现,它是首个端到端移动虚拟应用程序,可在现实世界中协助急救医生选择急救协议。
(1)在边缘设计并部署了 EMSAssist,这是首个端到端低延迟移动虚拟系统。端到端准确性和延迟评估表明:a) EMSAssist 的准确性远远高于 SOTA;b) EMSAssist 是唯一满足 5 秒延迟 SLO 的 EMS 服务系统。
(2) 提出并在医疗语音识别任务中应用了一种新颖有效的少样本微调整(few-sample fine-tuning)技术。与谷歌云语音转文本相比,该技术使EMSConformer 能够在 EMS 音频数据集上实现更快、更准确的语音转录。
(3) 本文提出了数据驱动的 EMS 协议选择模型 EMSMobileBERT,该模型克服了传统模型驱动解决方案的局限性,从而实现了更高的准确性。
(4) 本文提出了一种新颖的数据定制框架,用于为当地急救医疗机构获取大型标签数据集,从而解决急救医疗领域长期存在的数据稀缺问题。
3、系统设计
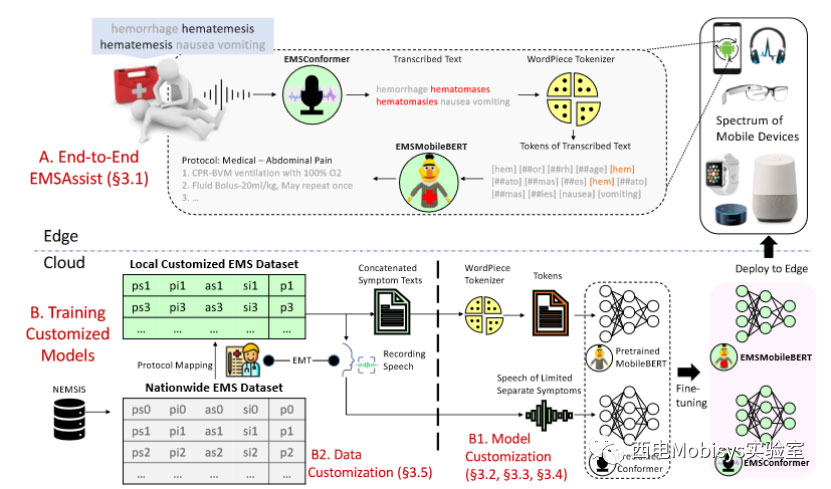
如图所示,EMSAssist 的设计由两个主要部分组成。组件 A 端到端 EMSAssist 包含 EMSAssist 在边缘部署后的端到端工作。B 部分 在云中部署的定制模型训练,包含在 GPU 服务器上训练定制的语音到文本和协议选择模型的步骤,以便 EMSAssist 部署。
B1 描述了我们如何使用定制文本和有限音频数据集来调整 EMSMobileBERT 和 EMSConformer 的工作。B2 描述了我们的数据定制框架的工作原理,其中 EMT 是完成协议映射技术的本地领域专家。值得注意的是,由于每个地方急救医疗机构的协议集都是独一无二的,因此模型和数据定制是必须的。我们的设计解决了第 2 节中指出的所有三个问题。
首先,EMSAssist 使用 EMSConformer 准确转录急救人员的语音,边缘延迟低,因此不依赖于不稳定的无线网络接入。其次,EMSAssist 利用经过实验验证的 WordPirce 标记符号化器从错误转录文本中检索有用信息的能力,减轻了使用 MetaMap 生成词级概念所造成的信息损失。第三,数据驱动的 EMSMobilerBERT 可捕捉输入文本中的关键信息,而这些信息在使用模型驱动方法时会被忽略。
3.1 The End-to-End EMSAssist
图 3 中的组件 A 举例说明了 EMSAssist 在边缘的端到端工作。EMSAssist 部署到各种移动设备(包括可穿戴设备和智能家居助手)后,可在边缘为急救医生提供语音到文本转录和 EMS 协议选择帮助。
如特定示例所示,急救医生正在口头描述他/她对病人的医疗评估。急救医生的讲话被麦克风捕获(例如通过人体摄像头等),然后由我们的 EMSConformer 转录为文本句子。虽然 EMSConformer 错误地将 “hematemesis 吐血 “转录成了 “hematomases 血瘤”,但 WordPiece 标记器从错误的转录中检索出了 2 个正确且有用的标记”[hem]”,从而帮助减轻了信息损失。之后,EMSMobileBERT 会提取转录文本句子中的所有标记,并将正确的 Top-1 协议 “医疗-腹痛 “和相应的医疗干预措施返回给急救医生。鉴于急救医生的双手忙于执行急救程序,其注意力主要集中在了解病人和周围环境的医疗状况变化上,端到端 EMSAssist 能够通过协助选择急救协议来减轻急救医生的工作量。EMSAssist 可能会更广泛地应用于志愿者和接受过足够急救培训的急救人员。集成 EMSAssist 后,智能家居设备可以为家中的家庭成员提供同样的急救服务。另一个好处是,EMSAssist 只在本地提供 EMS 援助,不会将任何用户数据上传到云端,从而保证了用户隐私。
3.2 EMSConformer
EMSConfomer 负责识别 EMT 在 EMSAssist 中的讲话。为了构建准确的语音到文本模型,需要一个包含 EMT 患者评估口头报告的大型 EMS 音频数据集。然而,由于国家和地方的安全和隐私原因,获得如此大的数据集并不容易。
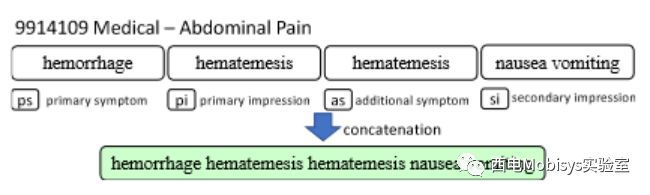
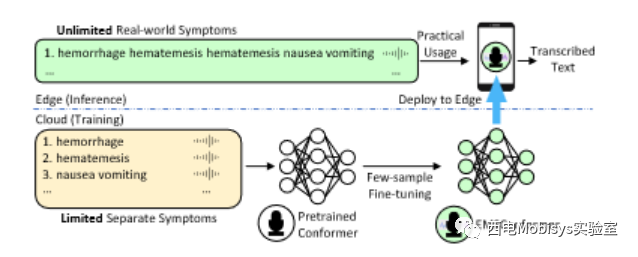
为了解决上述挑战,本文提出了一种新颖的少样本微调方法。它基于在 EMS 领域的两个见解:a) 对患者的真实症状评估通常是单独的症状短语/单词的串联,如图 4 所示;b) 独特的单独 EMS 症状的总数相当有限(EMS 领域中大约有数千个)。在这里,鉴于 Speech-to-Text 模型擅长识别有限的单独症状文本的语音,可以将其推广到准确识别无限的现实世界 EMS 症状文本,这些文本是单独症状文本的串联。
通过这一观察,如图 5所示,没有考虑从头开始直接尝试在 EMS 症状报告的稀缺音频记录上直接训练 Speech-toText 模型。相反,在有限的单独独特症状音频记录上对通常预先训练的最先进的语音到文本一致性模型进行了微调。重新调整的 EMSConformer 将进一步部署在边缘, EMSConformer 会转录现实世界中急救人员的讲话,并在实践中使用不同症状的串联。本文使用nnt 损失作为网络调整的损失函数。
3.3 WordPiece Tokenizer
EMSAssist 通过将来自 EMSConformer 的转录文本转换为 WordPiece 标记,在子词级别对其进行处理。与使用 MetaMap 的字级处理相比,WordPiece 分词器通过子字级处理提供了细粒度的信息检索能力。为了更好地理解这一微妙之处,通过在 SOTA 工作流程中仅用 WordPiece 分词器替换 MetaMap 来进行消融研究。
图 6a 比较了 MetaMap 和 WordPiece 分词器的端到端协议选择准确性100 条录音。在转录文本和原始真实文本(即图 6a 中的 Truth)上表现出更好的 Top-1/3/5 准确性表明了标记器的优势。当将WordPiece Tokenizer 与 MetaMap 进行比较时,可以看到我们的解决方案弹性地保持了较低的准确度下降,从而表明从错误转录中检索信息的能力更强。

3.4 EMSMobileBERT
EMSMobileBERT 负责在 EMSAssist 中准确选择 EMS 协议。在设计协议选择组件时,我们考虑以下3个原则。
首先,协议选择需要数据驱动。如上所述,先前的模型驱动方法丢失了输入症状文本中的语义和序列信息。
其次,在本文中,我们将协议选择任务视为医学文本分类任务。因此,协议选择模型需要设计为擅长文本分类。
第三,考虑到 WordPiece 分词器的信息检索优势,最好能更好地适应 WordPiece 分词器的模型。考虑到上述一般原则,BERT 及其(医学)变体是有前途的选择,因为它们在 NLP 领域已被证明具有强大的语言建模能力。
首先,BERT 是数据驱动的,专门用于捕获文本数据中的语义和序列信息。其次,BERT 在一般文本分类任务中取得了进化分数。第三,BERT 与多个分词器选项配合良好,其中之一是所需的 WordPiece 分词器。
现实世界的 EMS 症状句子是 4 个类别的单独症状的串联。因此它具有独特的特征:EMS 文本中的语义和序列信息大部分位于每个单独的症状内,而不是驻留在单独的症状之间。
此外,与一般文本句子相比,单独的症状文本之间存在分类特征信息。图 7 对此进行了演示,该图显示,当应用 BERT 模型时,不同的串联顺序会暴露出相当有限的 top-k 精度差异。这意味着在串联过程中生成的单独症状之间的语义和序列信息非常少。与 BERT 相比,CNN 和 ANN 模型通常用于捕获分类特征。凭借 BERT 的主干架构以及额外的 CNN 和堆叠的 ANN 层,MobileBERT 有望捕获:a) 语义和序列信息;b) EMS 症状文本中的分类特征信息。
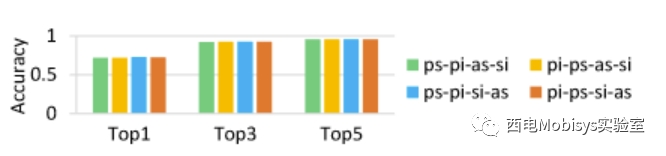
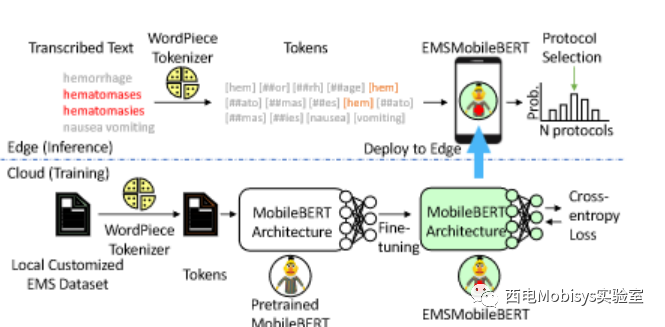
图 8 展示了我们的 EMSMobileBERT 训练工作流程。在云端进行微调期间,真正的 EMS 症状文本是输入数据,而来自上游语音识别的转录文本是边缘的输入数据。在这两种情况下,WordPiece 标记器都会将每个文本样本拆分为子词标记。然后将令牌输入到预先训练的 MobileBERT 中。在 MobileBERT 输出层(512 个神经元)之后添加了一个全连接(FC)层用于选择 EMS 协议。由于我们有46个本地定制的EMS协议,因此FC层是512×46。如果本地协议发生更改,则需要对 EMSMobileBERT 进行相应的重新调整。
3.5 Data Customization Framework
在本节中将介绍新颖的数据定制框架,为 EMSAssist 准备定制数据。数据定制框架旨在轻松推广到任何本地 EMS 机构,从而使该机构能够获得大型本地定制 EMS 数据集。
为了构建值得信赖的定制 EMS 助手,需要在大型标记本地数据集上实现高精度。然而,由于当地 EMS 机构事件发生频率较低,这一需求很难满足。此外,标记大量数据需要巨大的 EMT 劳动力成本。因此,非常需要具有最小标记成本的大型标记本地数据集。
通过一个例子来说明应对这一挑战的解决方案。两个不同的当地 EMS 机构,德克萨斯州大学城 (CS) 和德克萨斯州奥斯汀建立了自己的 EMS 协议集。奥斯汀的“呼吸窘迫”治疗方案和 CS 的“会厌炎”治疗方案有很多重叠的症状:“呼吸短促、喘鸣、发烧、说话能力下降”。鉴于受害者有这些症状,人们预计 CS 的 EMT 会选择“会厌炎”方案,而奥斯汀的 EMT 则选择“呼吸窘迫”。从更高层次来看,这些症状都属于“气道”类别,分为“呼吸窘迫”和“会厌炎”。利用这种高水平的观察来实现机构间数据共享,从而允许CS EMS机构合理地使用来自奥斯汀EMS的带有“呼吸窘迫”标签的数据作为CS带有“会厌炎”标签的本地数据。这个想法是使用最小的标签成本从另一个 EMS 机构获取本地 EMS 数据集的基础,而实现广泛的机构间数据共享。
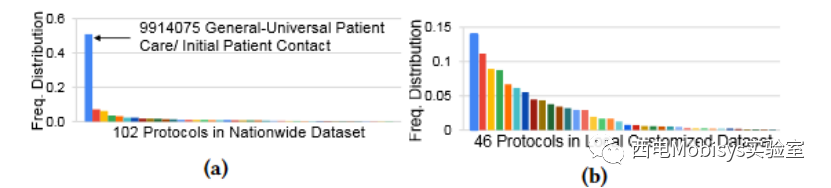
数据定制框架从表格全国数据集开始。在丢弃缺少单独症状组件中任何一个的记录、删除数据样本过少(少于 10 个)的协议以及重复数据删除之后,我们最终获得了 677,262 条全国性的 NEMSIS 记录,其中包含 102 个不同的 EMS 协议标签。数据集分布极不平衡,如图 9a 所示。主要协议是#9914075。
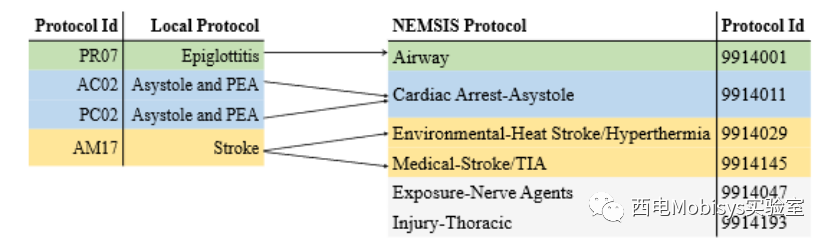
为了利用 NEMSIS 父协议实现的机构间数据共享,本文种如图 10 所示的协议映射方法。对于 107 个本地 EMS(匿名 EMS 机构)协议中的每一个,经验丰富的专业本地 EMT 将其映射到 102 个协议中的至少一个NEMSIS 协议。在此映射过程中,EMT 根据他/她过去在当地 EMS 机构的工作经验,确定本地协议最有可能相似的父 NEMSIS 协议。多个本地协议可以映射到同一个NEMSIS协议,一个协议也可以映射到多个NEMSIS协议。
最终,获得了 46 个协议的 174,178 个本地定制的 NEMSIS 数据样本。如图 9b 所示,与全国数据集相比,定制的本地数据集分布更加平衡。由于任何本地 EMS 机构都可以轻松获得本地 EMS 协议和 NEMSIS 协议,因此数据框架完全概括了其他本地 EMS 机构对大型本地定制数据集的需求。
4、系统实现
将 EMSAssist 实现为 Android 应用程序(大约 2,000 行 Java 代码),如图 11(a) 所示。目前它允许急救人员记录他们对体征和症状的口头评估,在内部, EMSConformer 首先将急救人员的录音转录成文本。然后,WordPiece 标记器将转录的文本转换为标记。EMSMobileBERT 获取所有协议的令牌和输出概率。
最终,EMSAssist 应用程序会推荐前 5 个协议,并将其及其概率(即置信度)显示在设备屏幕上
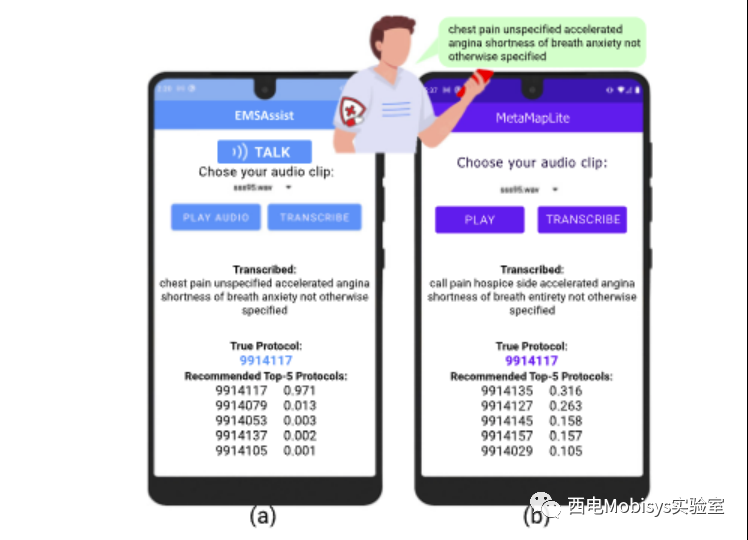
图 11:a) EMSAssist 应用程序允许记录体征和症状,并向 EMT 呈现/推荐一套要遵循的方案以及他们的置信度;b) 我们在边缘实施最先进的 EMS VA,使用 Google Cloud 提供语音转文本服务,并使用 MetaMapLite 进行概念匹配
5、系统评估
5.1 EMSConformer Accuracy
在本节中将 EMSConformer 与其他 SOTA Speech-to-Text 模型进行比较:Google Cloud Speech-to-Text API、RNNT和ContextNet。使用常用的字错误率 (WER) 和字符错误率 (CER) 来衡量所有语音转文本模型的准确性。错误率越低表明语音转文本的准确性越高。
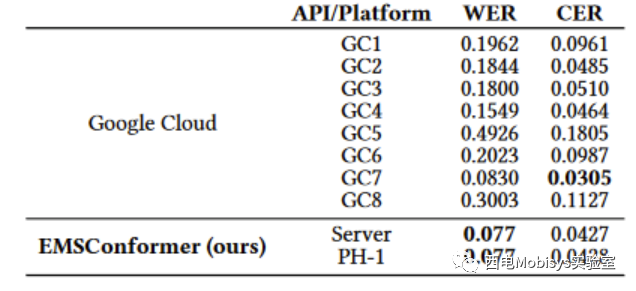
比较 EMSConformer 与 Google Cloud Speech-to-Text API。如表1所示,EMSConformer 的 WER 为 0.077,CER 为 0.0427。与所有 8 个 Google Cloud Speech-to-Text API 相比,它具有最低的 WER 和相对较低的 CER。
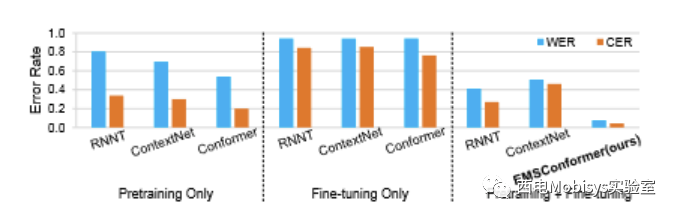
将少样本网络调整策略与其他两种不同的训练策略进行比较:仅预训练和仅微调整。
将所有 3 种训练策略应用于另外 2 个 SOTA 模型:RNNT和 ContextNet 。仅在预训练中,仅在标准通用 Librispeech 数据集上从头开始(1,000 小时)训练 3 个模型。仅在微淘中,即从头开始在单独的症状音频上训练 3 个模型。图 12 所示的结果表明,在 3 种不同的训练策略中,少样本微调策略(即“预训练 + 微调”)通常为所有 3 个模型产生最低的错误率。
在图12中,与RNNT和ContextNet相比,基于conformer的模型由于其混合卷积+变压器架构而具有明显较低的错误率。在所有训练策略和模型架构组合中,本文的EMSConformer 模型实现了最低的错误率。
5.2 EMSMobileBERT Accuracy
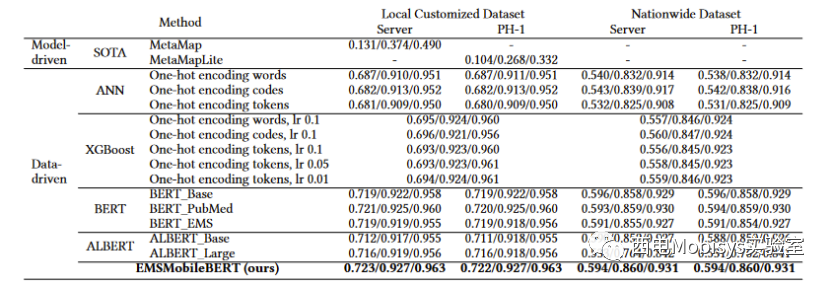
将 EMSMobileBERT 与所有基线模型(表 2)进行比较时,本文解决方案在本地定制数据集和全国数据集上均实现了最高的 Top-k 准确率。更准确地说,本文解决方案 EMSMobileBERT 在本地数据集上获得了高达 0.963 Top-5 的准确率。这意味着,考虑到前 5 个推荐协议,正确协议位于 5 个协议中的可能性高达 96.3%。
如表 2 所示,与所有数据驱动模型(即 EMSMobileBERT 和所有其他基线模型)相比,数据驱动 SOTA 解决方案在本地数据集上的 Top-k 精度最低。例如,使用 MetaMap 在服务器上达到了最高的 Top-5 准确率 0.49,但仍低于 0.5。相比之下,EMSMobileBERT 在服务器上获得了 0.963 Top-5 准确率,大幅优于 SOTA 解决方案。
5.3 E2E Protocol Selection Accuracy
如表3所示,Truth 指的是 EMSAssist 中的 EMSMobileBERT 和 SOTA 中的模型驱动方法都选择使用真实听写文本的协议,而 E2E 指的是使用转录文本。EMSAssist 依赖 EMSConformer 提供转录服务,而 SOTA 解决方案使用 8 个可用的 Google Cloud Speech-to-Text API。用于训练 EMSConformer 的数据集是短症状音频数据集。总体而言, EMSAssist 在边缘实现了 0.95 Top-5 端到端协议选择精度,远高于使用任何 Google Cloud API 甚至使用真实文本的 SOTA 解决方案。
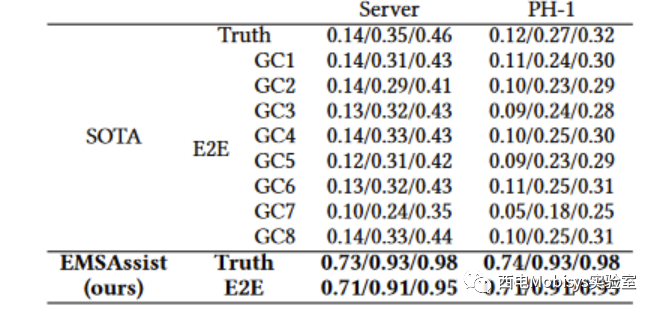
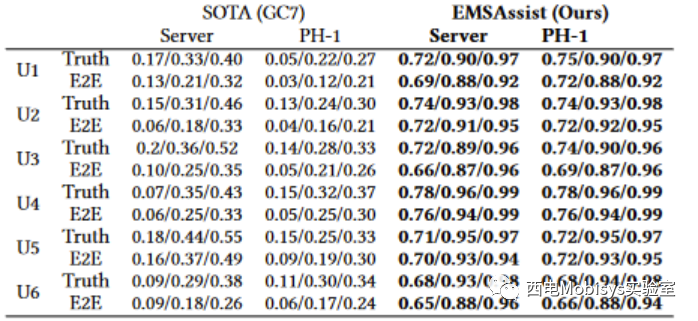
为了研究 EMSAssist 的泛化能力,进一步评估了不同口音和语音内容的个人用户的 EMS 录音上的 EMSAssist 和 SOTA。仅使用该特定用户的录音为每个用户重新调整了 EMSConformer。表 4 显示了各个端到端协议选择精度的结果。如图所示,EMSAssist 可以很好地推广到不同的用户,与表 3 中所示的 EMSAssist 端到端精度保持相似的精度。EMSAssist 还通过在所有用户的个人音频记录上表现出更高的 Top-k 精度来优于 SOTA。
本文还进行了消融研究,以更好地了解 EMSAssist 两个主要设计组件的性能。用另外两个 Speechto-Text 模型替换 EMSConformer,用三个协议选择模型替换 EMSMobileBERT。表5总结了端到端协议选择精度。总体而言,我们的“EMSConformer+EMSMobileBERT”实现了最高的Top-1/3/5端到端协议选择精度,分别为0.71、0.91和0.95 ,显示了 2 个设计组件的重要性。

本文评估了 SOTA 和 EMSAssist 边缘的运行时端到端延迟。结果如表 6 所示,EMSAssist 实现了 4.2 秒的低推理延迟,从而满足了 5 秒的预期 SLO 延迟。SOTA 的延迟要长得多,为 23.1 秒。

6、结论
本文介绍了 EMSAssist 的设计、开发和评估,这是第一个 EMS 边缘端对端移动语音助手。作为 EMSAssist 的核心,EMSConformer 凭借新颖的少样本微调方法,性能优于 Google Cloud Speech-to-Text API。EMSAssist 的数据驱动组件,即 EMSMobileBERT,凭借其 0.95 的端到端 Top-5 准确率,成为 EMS 协议选择任务中最先进的新产品。通过实现 EMS 机构间数据共享,EMSAssist 的新颖数据定制框架解决了 EMS 领域长期存在的问题,即缺乏定制 EMS VA 所需的大型本地数据集。
来源:西电Mobisys实验室
作者:邝龙静,杜军朝
参考文献
[1] BBC. Florida building collapse: Report from 2018 warned of “major damage”. https://www.bbc.com/news/world-us-canada-57621774, 2021. [Online; accessed 31-March-2022].
[2] Wikipedia. Surfside condominium collapse. https://en.wikipedia.org/wiki/ Surfside_condominium_collapse, 2022. [Online; accessed 31-March-2022].
[3] Joan Brunkard, Gonza Namulanda, and Raoult Ratard. Hurricane Katrina Deaths, Louisiana, 2005. Disaster Medicine and Public Health Preparedness, 2(4):215–223, 2008.
[4] Roberto Aringhieri, Maria Elena Bruni, Sara Khodaparasti, and Theresia van Essen. Emergency medical services and beyond: Addressing new challenges through a wide literature review. Computers & Operations Research, 78:349–368, 2017.
[5] Sarah Preum, Sile Shu, Jonathan Ting, Vincent Lin, Ron Williams, John Stankovic, and Homa Alemzadeh. Towards a cognitive assistant system for emergency response. In 2018 ACM/IEEE 9th International Conference on Cyber-Physical Systems (ICCPS), pages 347–348, April 2018.
[6] Sarah Preum, Sile Shu, Mustafa Hotaki, Ronald Williams, John Stankovic, and Homa Alemzadeh. CognitiveEMS: A cognitive assistant system for emergency medical services. SIGBED Rev., 16(2):51–60, August 2019.
[7] Sile Shu, Sarah Preum, Haydon Pitchford, Ronald Williams, John Stankovic, and Homa Alemzadeh. A behavior tree cognitive assistant system for emergency medical services. 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 6188–6195, 2019.
[8] UpToDate. Anaphylaxis: Emergency treatment. https://www.uptodate.com/ contents/anaphylaxis-emergency-treatment, 2023. [Online; accessed 21-March2023].
[9] Qin Ning, Chien-An Chen, Radu Stoleru, and Congcong Chen. Mobile Storm: Distributed real-time stream processing for mobile clouds. In 2015 IEEE 4th International Conference on Cloud Networking (CloudNet), pages 139–145, 2015.
[10] Mengyuan Chao, Chen Yang, Yukun Zeng, and Radu Stoleru. F-MStorm: Feedbackbased online distributed mobile stream processing. In 2018 IEEE/ACM Symposium on Edge Computing (SEC), pages 273–285, 2018.
[11] Mengyuan Chao and Radu Stoleru. R-MStorm: A resilient mobile stream processing system for dynamic edge networks. In 2020 IEEE International Conference on Fog Computing (ICFC), pages 64–72, 2020.
[12] Shimaa Ahmed, Amrita Roy Chowdhury, Kassem Fawaz, and Parmesh Ramanathan. Preech: A system for Privacy-Preserving speech transcription. In 29th USENIX Security Symposium (USENIX Security 20), pages 2703–2720. USENIX Association, August 2020.
[13] Antonio Torralba and Alexei Efros. Unbiased look at dataset bias. In 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1521–1528, Los Alamitos, CA, USA, June 2011. IEEE Computer Society.
[14] Aida Sharif Rohani. Bias measurement in small datasets. PhD thesis, Northeastern University, Boston, Massachusetts, 2021.
[15] Daniel Berrar, Ian Bradbury, and Werner Dubitzky. Avoiding model selection bias in small-sample genomic datasets. Bioinformatics, 22(10):1245–1250, Feb 2006.
[16] Huan Luo and Stephanie German Paal. Reducing the effect of sample bias for small data sets with double-weighted support vector transfer regression. Computer-Aided Civil and Infrastructure Engineering, 36(3):248–263, Feb 2021.
[17] Daniel Park, William Chan, Yu Zhang, Chung-Cheng Chiu, Barret Zoph, Ekin Cubuk, and Quoc Le. SpecAugment: A simple data augmentation method for automatic speech recognition. In Interspeech 2019. ISCA, Sep 2019.
[18] Anmol Gulati, James Qin, Chung-Cheng Chiu, Niki Parmar, Yu Zhang, Jiahui Yu, Wei Han, Shibo Wang, Zhengdong Zhang, Yonghui Wu, and Ruoming Pang. Conformer: Convolution-augmented transformer for speech recognition. In Interspeech 2020. ISCA, Oct 2020.
[19] Google. Cloud Speech-to-Text. https://cloud.google.com/speech-to-text/, 2022. [Online; accessed 30-Nov-2022].
[20] Jinyu Li. Recent advances in end-to-end automatic speech recognition. ArXiv, 2111.01690, 2022.
[21] Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: An ASR corpus based on public domain audio books. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5206–5210, 2015.
[22] Theodoros Panagiotakopoulos, Pier Luigi Dovesi, Linus Härenstam-Nielsen, and Matteo Poggi. Online domain adaptation for semantic segmentation in everchanging conditions. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXIV, pages 128–146. Springer, 2022.
[23] Ke Mei, Chuang Zhu, Lei Jiang, Jun Liu, and Yuanyuan Qiao. Cross-stained segmentation from renal biopsy images using multi-level adversarial learning. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1424–1428. IEEE, 2020.
[24] Jiahua Dong, Yang Cong, Gan Sun, Bineng Zhong, and Xiaowei Xu. What can be transferred: Unsupervised domain adaptation for endoscopic lesions segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
[25] Jiahua Dong, Yang Cong, Gan Sun, and Dongdong Hou. Semantic-transferable weakly-supervised endoscopic lesions segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (CVPR), pages 10712–10721, 2019.
[26] George Michalopoulos, Yuanxin Wang, Hussam Kaka, Helen Chen, and Alexander Wong. UmlsBERT: Clinical domain knowledge augmentation of contextual embeddings using the Unied Medical Language System Metathesaurus. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1744–1753, Online, June 2021. Association for Computational Linguistics.
[27] Yu Gu, Robert Tinn, Hao Cheng, Michael Lucas, Naoto Usuyama, Xiaodong Liu, Tristan Naumann, Jianfeng Gao, and Hoifung Poon. Domain-specic language model pretraining for biomedical natural language processing. ACM Transactions on Computing for Healthcare, 3(1):1–23, Oct 2021.
[28] Fangyu Liu, Ivan Vulic, Anna Korhonen, and Nigel Collier. Learning domainspecialised representations for cross-lingual biomedical entity linking. In Annual Meeting of the Association for Computational Linguistics, 2021.
[29] Statista. Number of voice assistants in use worldwide 2019-2023. https://www. statista.com/statistics/973815/worldwide-digital-voice-assistant-in-use, 2022. [Online; accessed 01-Feb-2022].
[30] Department of Homeland Security. Snapshot: Public safety agencies pilot articial intelligence to aid in rst response. https://www.dhs.gov/science-andtechnology/news/2018/10/16/snapshot- public- safety- agencies- pilot- articialintelligence, 2018. [Online; accessed 01-Feb-2022].
[31] Department of Homeland Security. Snapshot: S&T, canadian counterparts evaluate audrey in use case. https://www.dhs.gov/science-and-technology/news/ 2019/08/13/snapshot-st-canadian-counterparts-evaluate-audrey-use-case, 2019. [Online; accessed 01-Feb-2022].
[32] Sarah Preum, Sile Shu, Homa Alemzadeh, and John Stankovic. EMSContExt: EMS protocol-driven concept extraction for cognitive assistance in emergency response. In AAAI Conference on Articial Intelligence, 2020.
[33] Sion Kim, Weishi Guo, Ronald Williams, John Stankovic, and Homa Alemzadeh. Information extraction from patient care reports for intelligent emergency medical services. In 2021 IEEE/ACM Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE), pages 58–69, 2021.
[34] Clay Mann, Lauren Kane, Mengtao Dai, and Karen Jacobson. Description of the 2012 NEMSIS Public-Release Research Dataset. Prehospital Emergency Care, 19(2):232–240, April 2015.
[35] Kevin Munjal, Hugh Chapin, Taylor Miller, Christopher Kahn, Lynne Richardson, and James Dunford on behalf of the Promoting Innovation in EMS Steering Committee. Promoting innovation in emergency medical services. https: //emsinnovations.org/, 2018. [Online; accessed 31-March-2022].
[36] Alan Aronson. Effective mapping of biomedical text to the UMLS Metathesaurus: the MetaMap program. Proceedings. AMIA Symposium, pages 17–21, 2001.
[37] Alex Graves, Abdel-rahman Mohamed, and Geoffrey Hinton. Speech recognition with deep recurrent neural networks. In 2013 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 6645–6649. IEEE, 2013.
[38] Wei Han, Zhengdong Zhang, Yu Zhang, Jiahui Yu, Chung-Cheng Chiu, James Qin, Anmol Gulati, Ruoming Pang, and Yonghui Wu. Contextnet: Improving convolutional neural networks for automatic speech recognition with global context. ArXiv, abs/2005.03191, 2020.
[39] Yonghui Wu, Mike Schuster, Z. Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Lukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason R. Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, Gregory S. Corrado, Macduff Hughes, and Jeffrey Dean. Google’s neural machine translation system: Bridging the gap between human and machine translation. ArXiv, abs/1609.08144, 2016.
[40] Xinying Song, Alex Salcianu, Yang Song, Dave Dopson, and Denny Zhou. Fast WordPiece tokenization. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2089–2103, Online and Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics.
[41] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pretraining of deep bidirectional transformers for language understanding. ArXiv, 1810.04805, 2018.
[42] Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou. MobileBERT: a compact task-agnostic bert for resource-limited devices. ArXiv, 2004.02984, 2020.
[43] RadioReference.com LLC. Radioreference.com: Your complete reference source. https://www.radioreference.com/, 2022. [Online; accessed 30-March-2022].
[44] Huy Le Nguyen. TensorFlowASR: Almost state-of-the-art automatic speech recognition in tensorflow 2. https://github.com/TensorSpeech/TensorFlowASR, 2022. [Online; accessed 30-March-2022].
[45] Alex Graves. Sequence transduction with recurrent neural networks. ArXiv, 1211.3711, 2012.
[46] Google Research. BERT. https://github.com/google-research/bert, 2018. [Online; accessed 30-Nov-2022].
[47] Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4):1234–1240, Sep 2019.
[48] Kexin Huang, Jaan Altosaar, and Rajesh Ranganath. ClinicalBERT: Modeling clinical notes and predicting hospital readmission. ArXiv, 1904.05342, 2019.
[49] Yun He, Ziwei Zhu, Yin Zhang, Qin Chen, and James Caverlee. Infusing Disease Knowledge into BERT for Health Question Answering, Medical Inference and Disease Name Recognition. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4604–4614, Online, November 2020. Association for Computational Linguistics.
[50] Yifan Peng, Shankai Yan, and Zhiyong Lu. Transfer learning in biomedical natural language processing: An evaluation of BERT and ELMo on ten benchmarking datasets. In Proceedings of the 18th BioNLP Workshop and Shared Task, pages 58–65, Florence, Italy, August 2019. Association for Computational Linguistics.
[51] Sercan Ö. Arik and Tomas Pster. Tabnet: Attentive interpretable tabular learning. Proceedings of the AAAI Conference on Articial Intelligence, 35(8):6679–6687, May 2021.
[52] Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. Revisiting deep learning models for tabular data. Advances in Neural Information Processing Systems, 34:18932–18943, 2021.
[53] Zhilu Zhang and Mert R. Sabuncu. Generalized cross entropy loss for training deep neural networks with noisy labels. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, NIPS’18, page 8792–8802, Red Hook, NY, USA, 2018. Curran Associates Inc.
[54] Austin EMS. Master cog document effective 03.11.22. https://www.austintexas. gov/sites/default/les/les/OCMO/COGMasterDocument2022.pdf, 2022. [Online; accessed 05-November-2022].
[55] Dina Demner-Fushman, Willie J Rogers, and Alan Aronson. MetaMap Lite: an evaluation of a new Java implementation of MetaMap. Journal of the American Medical Informatics Association, 24(4):841–844, 01 2017.
[56] Tensorow Hub. MobileBERT_en_uncased_l-24_h-128_b-512_a-4_f-4_opt. https://tf hub.dev/tensorow/mobilebert_en_uncased_L- 24_H- 128_B- 512_A4_F-4_OPT/1, 2022. [Online; accessed 30-March-2022].
[57] Rich Caruana, Steve Lawrence, and Lee Giles. Overtting in neural nets: Backpropagation, conjugate gradient, and early stopping. In Proceedings of the 13th International Conference on Neural Information Processing Systems, NIPS’00, page 381–387, Cambridge, MA, USA, 2000. MIT Press.
[58] Yingbin Bai, Erkun Yang, Bo Han, Yanhua Yang, Jiatong Li, Yinian Mao, Gang Niu, and Tongliang Liu. Understanding and improving early stopping for learning with noisy labels. Advances in Neural Information Processing Systems, 34:24392–24403, 2021.
[59] Google TensorFlow Lite. Deploy machine learning models on mobile and iot devices. https://www.tensorow.org/lite, 2022. [Online; accessed 31-March-2022].
[60] Google TensorFlow Lite. Model optimization. https://www.tensorow.org/lite/ performance/model_optimization, 2022. [Online; accessed 31-March-2022].
[61] Tianqi Chen and Carlos Guestrin. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, page 785–794, New York, NY, USA, 2016. Association for Computing Machinery.
[62] Tensorflow Hub. bert_en_uncased_l-12_h-768_a-12. https://tfhub.dev/ tensorow/bert_en_uncased_L-12_H-768_A-12/4, 2022. [Online; accessed 30March-2022].
[63]TensorflowHub.experts/bert/pubmed.https://tfhub.dev/google/experts/bert/ pubmed/2, 2022. [Online; accessed 30-March-2022].
[64] Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. ALBERT: A lite BERT for self-supervised learning of language representations. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net, 2020.
[65]TensorflowHub.ALBERT_base.https://tfhub.dev/google/albert_base/2, 2022. [Online; accessed 30-March-2022]
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。