
视口预测在实时360°视频流媒体中扮演着至关重要的角色,它决定了应预先获取哪些高质量的 tile ,从而影响用户体验。
来源:EMS ’23
题目:LiveAE: Attention-based and Edge-assisted Viewport Prediction for Live 360° Video Streaming
作者:Zipeng Pan,Yuan Zhang,Tao Lin,Jinyao Yan
原文链接:https://dl.acm.org/doi/10.1145/3609395.3610597
内容整理:李雨航
现有的针对 VP 问题的大量研究工作都是在360°视频点播场景下,这些方法依赖于多个用户的历史头部移动轨迹来进行预测,即假设用户通常在视频帧内拥有相同的 ROI。然而这些方法不适用于实时360°视频,原因在于直播的实时性,上述多用户轨迹信息通常无法获得。
在实时360°视频领域,当前 VP 问题的研究趋势是将两类特征——视觉特征和头部移动轨迹整合起来,以实现更准确、稳定的预测。然而,这类方法面临在预测准确性和计算复杂度之间取得平衡的挑战。本文提出了一种名为 LiveAE 的新型基于注意力和边缘辅助的实时360°视频流媒体视口预测框架。使用名为 Vision Transformer (ViT)的预训练视频编码器进行通用视觉特征提取,并采用了交叉注意机制进行用户特定兴趣跟踪。为了解决计算复杂度问题,将前述的内容级的计算负载卸载到边缘服务器上,同时在客户端保留与轨迹相关的功能。
本文主要贡献总结如下:
- 在实时360°视频流媒体环境中提出了一种新颖的基于注意力和边缘辅助的视口预测框架,命名为LiveAE。
- 开发了一个预训练的 ViT 用于提取一般的视觉模式,并使用交叉注意力机制来捕捉用户特定的视觉兴趣。
- 大量实验证明,LiveAE在预测性能方面至少比表现最好的算法提高了12.8%,同时确保满足实时处理需求。
方法
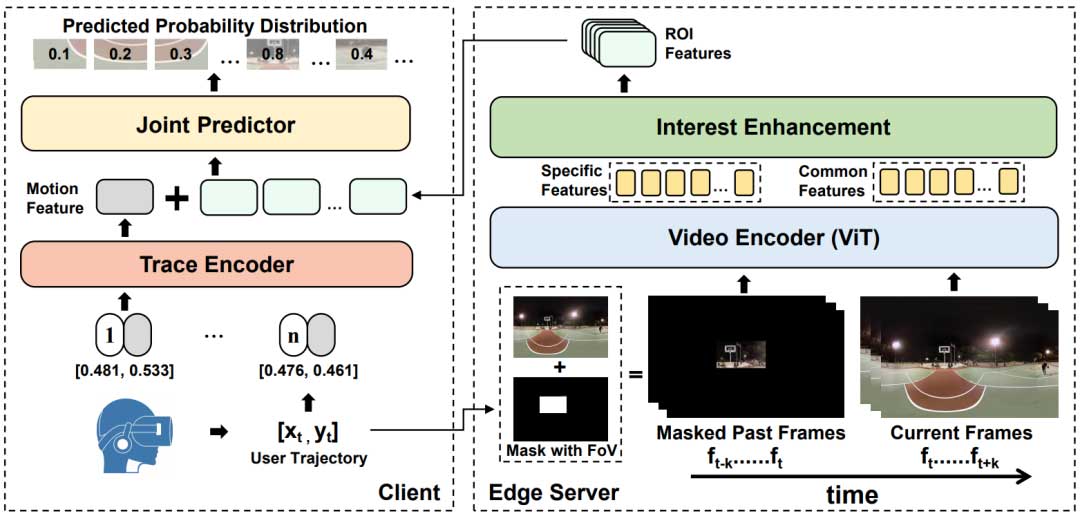

系统架构
图 1 展示了LiveAE的系统框架,VP 过程在边缘服务器和客户端之间进行联合处理。在边缘服务器端,从最近的 segment 和当前 segment(预先传输到边缘服务器中)中对视频帧进行子采样。为了获取用户个性化的兴趣,从客户端实时反馈回来的轨迹数据被用来截取出过去帧的 FoV 区域。然后将当前帧和截取后的过去帧输入到预训练的视频编码器中,以提取大多数用户的一般观看特征和当前用户的兴趣特征。这两组特征随后通过基于交叉注意力的兴趣增强模块进行处理,以获取适合当前用户的 ROI 特征。在客户端,轨迹数据通过基于轻量级 Transformer 的轨迹编码器进行处理,以提取时间运动特征。最后,运动特征和由边缘服务器提供的 ROI 特征被输入到联合预测器中,生成作为预测结果的 tile 概率分布矩阵。
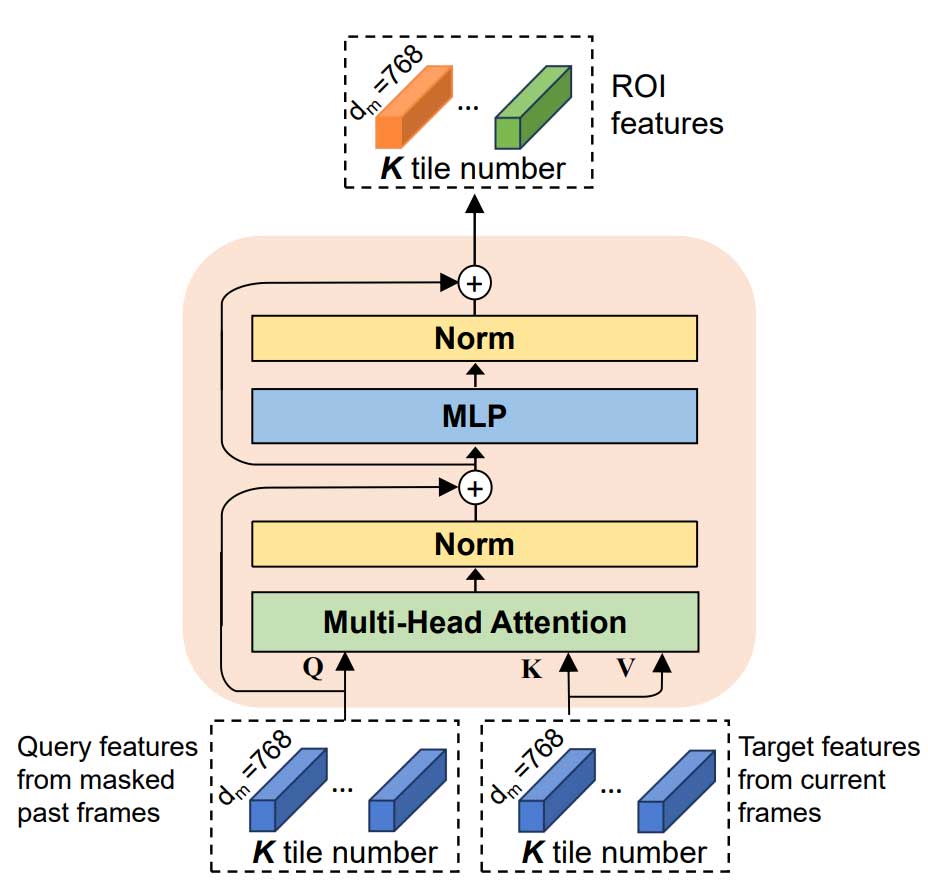
预训练的视频编码器
本文使用 ViT(VisionTransformer)作为预训练视频编码器,以获取 360°视频的视觉表示。它是一种应用了 Transformer 模型的神经网络结构,在各种计算机视觉任务中都显示出了良好的结果,如图像分类、物体检测和图像分割等。
尽管现有的基于视觉的模型在识别一般用户的 RoI 方面表现出色,但这些区域可能无法完全代表当前用户的偏好。为了克服这点不足,本文提出如图 2 所示的视频编码器,输入两种类型的帧序列来捕捉用户兴趣特征。首先,使用均匀子采样从当前 segment 中选择 𝑘 帧的子集。一方面可以减少处理时延以及相邻帧之间的相似性。另一方面,从过去 segment 中提取最后 𝑘 帧,有助于消除过时的用户兴趣,增强预测准确性。通过结合这些策略,能够获取普遍的和个体的用户偏好,以实现更准确的视口预测。
需要注意的是,ViT 将视频帧分割为不重叠的图像块,并利用Transformer 模型来捕捉这些块之间的相互作用,以获得最终的表示。为了增强其在特定任务中的适用性,本文保留了与每个图块对应的特征,从而生成了一个以图块为粒度的特征图。这种方法有效地保留了每个图块的空间位置信息,有助于创建空间对齐的概率分布矩阵。在特征提取过程之后,该视频编码器生成了两组图像特征:普遍偏好和个体偏好,每组特征的形状为 k x tilenumber x dm,其中 dm 表示嵌入张量的维度。这种设计选择使我们能够在图块级别捕捉详细信息,并利用丰富的空间特征进行准确的视口预测。
兴趣增强
如图 1 所示,在得到截选好的过去帧和当前帧的嵌入向量之后,我们使用交叉注意力 Transformer 来整合这些嵌入向量,以获得增强用户兴趣的图像特征。这是一种改进的 Transformer 模型,它融合了交叉注意力机制来处理多个输入序列。通过有效地建模它们之间的关联来更好地捕捉不同序列之间的语义关系。
图 2 给出了兴趣增强模块的架构。其中,注意力权重通过计算 query 矩阵 𝑄 和 key 矩阵 𝐾 的点积来确定,然后,得到的注意力权重被应用于值矩阵 𝑉。定义为:
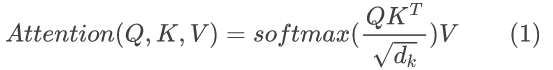
在该方法中,从过去帧提取的嵌入向量被投影到 query 矩阵 𝑄 上,而 key 矩阵 𝐾 和 value 矩阵 𝑉 则包含来自当前帧的特征。这种方法使得模型能够在图块级别进行键值查找,从而能够对用户更感兴趣的特定图块分配更高的注意力。这样,ROI(感兴趣区域)特征的尺寸为 tilenumber x dm,可以表示为 zh = {z1,… ,zp}。
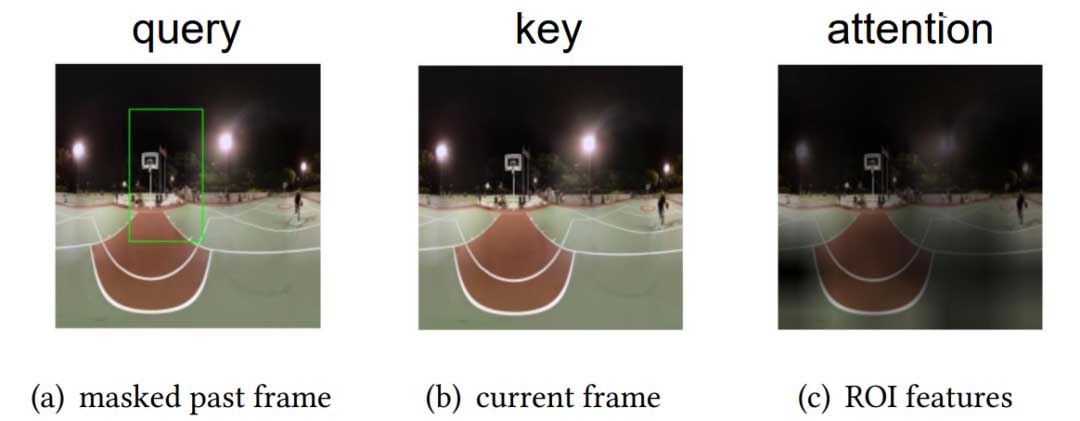
图 3 展示了交叉注意力机制的一个示例。图 3( a ) 显示了被标记为绿色框的掩盖图像区域。图 3( b ) 表示完整的当前帧,而图 3( c ) 展示了注意力可视化结果,明亮的区域表示模型分配更多的注意力。值得注意的是,模型不仅能够关注代表用户特定兴趣的查询区域,还能够关注捕捉到一般兴趣的其他潜在区域。正如图 3( c ) 中右侧的玩家所示,注意力被适当分配到了该区域。
轨迹编码器
本文采用一个标准的 Transformer 块,从过去的 𝐻 秒观看历史中提取用户的运动特征。为了表示用户的头部方向,使用相对坐标,它由一个 1×2 向量表示𝑋、𝑌轴。为了保证与不同传感器频率的兼容性,每秒采样 𝑛 个时间戳,形成一个形状为 H x n x 2 的输入特征。然后使用线性层对该特征进行嵌入,得到一个形状为 H x n x dm 的输入嵌入。考虑到计算负载,使用单层宽为 dm 且带有 8 个注意力头的模型,来编码这些特征,以获得形状为 dm x 1 的运动特征向量 wj。
联合预测器
在提取了 ROI 特征zh = {z1,… ,zp}和运动特征 wj 之后,为了处理两个不同模态的输入,本文采用类型编码的 Transformer 作为融合网络。首先将两个特征表示 zh和wj 连接起来。这些连接的特征 Ui可以表示为 Ui = {wj,z1,… ,zp},作为融合网络的输入,促进视频和轨迹信息之间的多模态交互。为了获得每个片段的概率矩阵𝐹,本文采用三层线性映射层进行解码。整个预测器的网络架构如下所示:
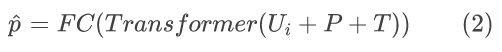
其中,𝑃 是位置编码,𝑇 是类型编码,其中包含两个不同的嵌入向量,分别用于视频帧和轨迹。
实现细节
本文的实验配置包括将片段持续时间设置为 1 秒,采样频率 𝑘 设置为5。参考主流 HMD 设备,FoV 大小定义为 100°。
为了生成标签,利用每个片段中每帧的头部方向来生成每个切片的观看比例。为了获得时间平滑的最终训练标签,对同一片段中的所有帧的概率图进行平均。
在训练过程中,本文使用 AdamW 优化器来优化参数,并结合余弦学习率衰减进行热身。对于 ViT 参数,将最大学习率设置为 1e-7,而对于其他部分,最大学习率为 1e-5。由于模型输出概率矩阵,采用二元交叉熵作为损失函数。
为了匹配预训练模型的输入大小并适应不同分辨率的视频,本文使用 openCV 将分辨率调整为 224×224。为了用 2𝑘×3×224×224 的形状对视频特征进行编码,本文采用了 ViT,并使用 32 作为 patch 的大小。
为了最小化计算要求,在客户端对转换器的层数和序列长度进行了控制。本文在追踪编码器和联合预测器中分别使用一个和四个转换器块的层。
由于多头注意力层代表了转换器网络的主要计算负载,其复杂度为 O(N2),其中 𝑁 是输入序列的长度。本模型在客户端实现了平均序列长度为 44,产生了 1.2G 浮点运算(FLOPs)的可接受计算复杂度。
实验
baseline 与实验设置
为了满足 ViT 的数据需求,本文从一个大型开放数据集中选择了107个视频,包括对齐的观看轨迹。训练集包含这些视频的 90%,剩余的 10% 用作测试集。使用 PyTorch 在两个设备上实现模型:一台工作站(搭载 Intel 10700 CPU 和一张 32G RAM的RTX3080 显卡)作为边缘服务器,以及一台个人笔记本电脑(搭载 AMD R5 5800H CPU 和 16G RAM)作为客户端。
我们选择了四种基线 VP 算法用于比较:
- Salnet360 :一种利用 CNN 生成显著性地图的方法。本文选择具有高显著性得分的 tile 作为预测视口。它可以归类为一种基于视觉的方法。
- Flare :一种利用岭回归(RR)模型基于历史数据估计视口的方法,使其成为一种基于历史的方法。
- Livedeep :一种融合了 CNN 和 LSTM 的方法,用于生成预测。
- MFVP :一种混合方法,将显著性地图和过去的运动轨迹与 ConvLSTM 相结合。
为了评估 LiveAE 的性能,我们选择以下广泛使用的指标:准确率、精确率、召回率、F1 分数和联合交集(IoU)。
- 准确率是正确预测的 tile 占所有 tile 的百分比。每个片段的准确率定义为:
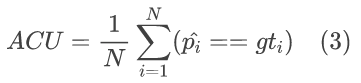

- 精确率衡量了预测视口中实际被查看的 tile 的比例。较低的精确率表明所选的 tile 被浪费的可能性更高。
- 召回率通过测量正确预测的 tile 在所有查看的 tile 中所占的比例来评估模型识别视口的能力。
- IoU度量衡量了预测的FoV和实际FoV之间重叠 tile 的百分比。它可以通过以下公式计算得到:

结果
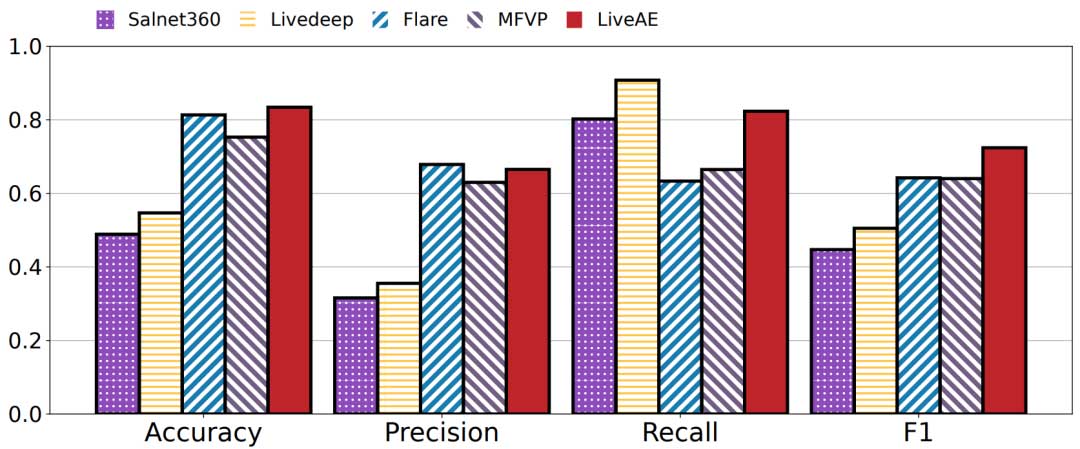
预测性能
图 4 展示了当预测窗口为 2 秒时,五种方法的综合比较结果。LiveAE 实现了最高的预测准确率(83.4%)和 F1 值(0.724),并且相对于表现最好的 baseline 提高了12.8%的 F1 值。
Livedeep 由于决策使用 CNN 和 LSTM 预测结果的融合,实现了最高的召回率。然而,剩下的三个指标,尤其是精确率,显示出较低的数值,表明可能存在带宽的浪费。同时,Flare利用 RR 保守地预测靠近预测视口的 tile 。这种保守的方法增强了其精确度和准确度,但也导致了最低的召回率,因为很难预测在片段中所包含的所有 tile 。我们后续的实验证明,虽然 Flare 在短期预测窗口下表现良好,但在进一步预测时无法保持这种优势。
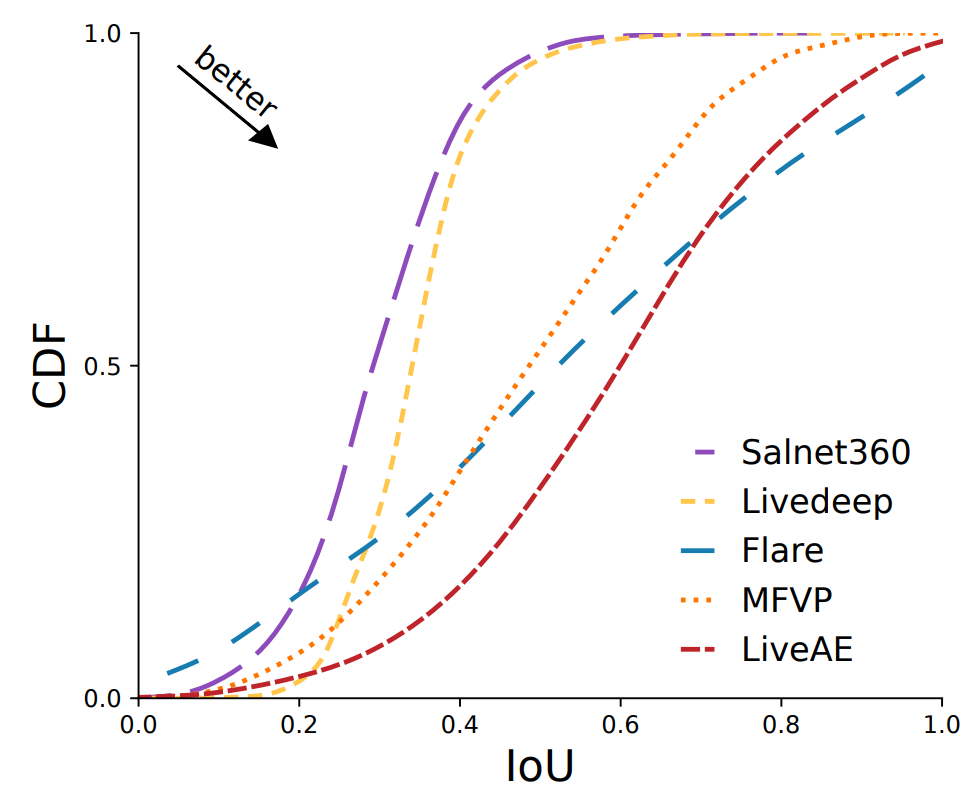
图 5 展示了 IoU 的分布情况,LiveAE 通过显著减少 IoU 小于 0.7 的极端情况的发生,展现了卓越的性能。相比之下,Salnet360 和 Livedeep 的大部分 IoU 都小于 0.4,这是因为它们选择了更多的 tile 。此外,Flare 呈近似线性分布,并且无法有效缓解预测不准确(即IoU<0.3)的情况,表明其处理复杂情况的能力有限。
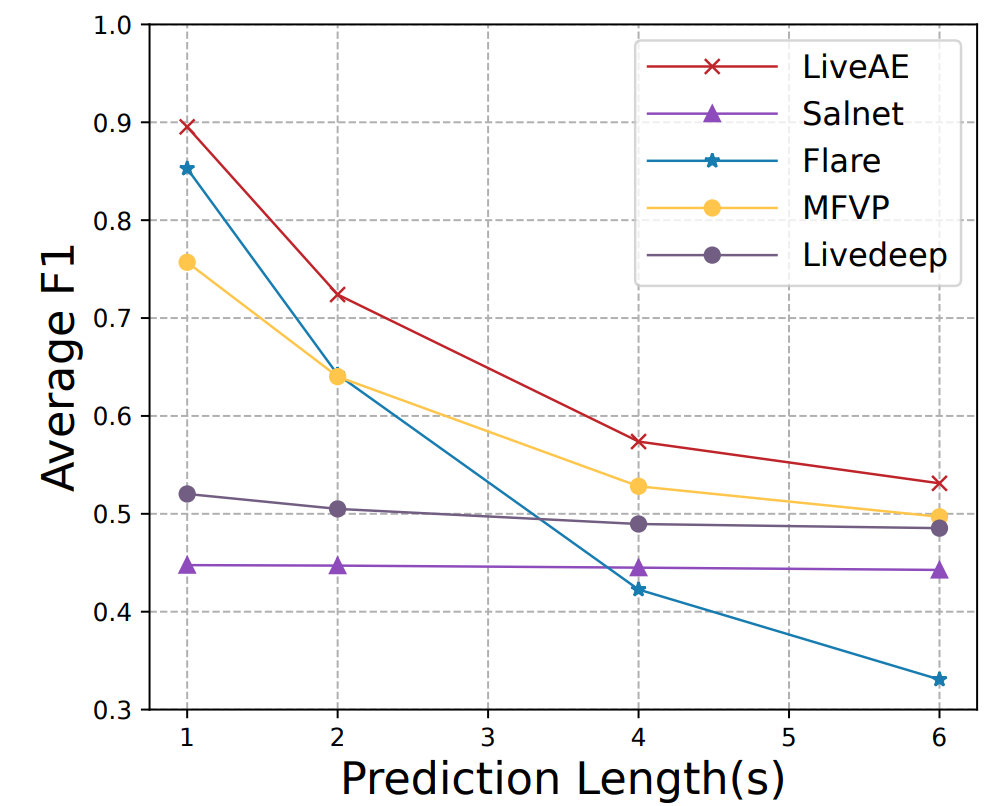
图 6 展示了不同预测窗口下的 F1 得分。LiveAE 在所有情况下都具有最高的 F1 得分。具体而言,相对于表现最好的基准方法 MFVP,LiveAE 将F1提高了 6.8%-18.2%。
消融实验
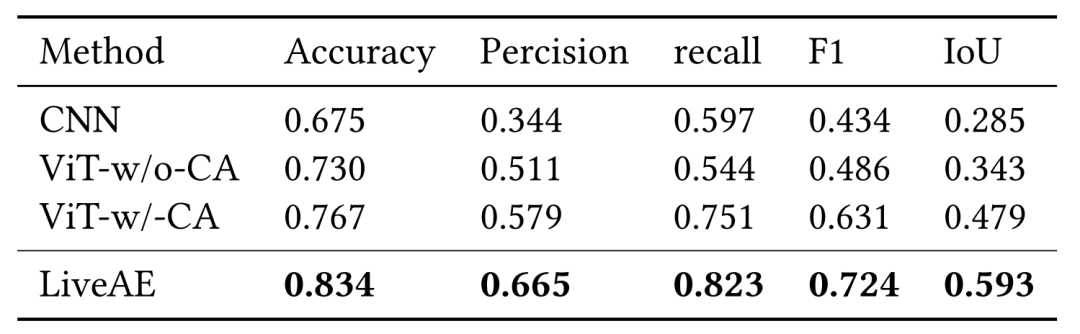
为了验证 LiveAE 的有效性,本文将 LiveAE 与基于视觉的基准算法以及 LiveAE 的两个变体进行比较。我们使用 CNN,这是一个基于Livedeep的VGG 骨干网络适应的模型,变种 ViT-w/o-CA 以及另一个变种 ViT-w/-CA。ViT-w/o-CA 包含本算法中预训练的视觉编码器,而 ViT-w/-CA 包含带有交叉注意力模块的预训练视觉编码器。将 LiveAE 与仅基于视觉的方法进行比较,可以观察到性能有了显著提升。如表 1 所示,相比 CNN,ViT-w/o-CA 的准确性提高了 8.1%,而 ViT-w/-CA 相比 ViT-w/o-CA 提高了 5.1% 的总准确性,验证了基于 CA 的 ViT 预测能够合理化预测。此外,相比 ViT-w/-CA,LiveAE 的准确性提高了8.7%。这是由于 LiveAE 结合了用户的过去视野范围,注意力更集中于用户先前探索过的区域,而不是整个屏幕散布。
处理成本
考虑到 360° 视频直播的实时要求,算法的运算时间必须小于片段的持续时间,以确保流畅的用户体验。为了验证这一点,本文评估了 LiveAE 的计算负载。为了彻底评估算法的可行性,在CPU上部署了客户端模型。为了确保准确可靠的结果,使用了 CpuFrequtil 工具将 CPU 频率限制在 2.2GHz,结果是一个跨平台性能测试 GeekBench5 分数约为 1400 分。这个性能与三星 S22 在同样的测试中获得的结果非常接近。
图 7 显示了我们模型在测试集上的处理成本。LiveAE 只产生了 30-40 毫秒的处理成本,远低于 1 秒的片段持续时间。需要注意的是,这里的处理成本是一次预测的完整持续时间,它是边缘服务器开销和用户端开销之和。实验结果证明该模型支持客户端实时流媒体。这可以归因于Transformer 框架相比于 RNN 模型具有很高的并行性,以及利用了更短的输入序列长度。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。