
01 引言
LoRA(Low-rank Adapter)在大模型(如GPT-3,LLama, Qwen等)中,是一种重要的微调技术。该技术通过在不改变预训练模型参数的同时,添加低阶矩阵,学习新的、特定于任务的参数。这种微调方式不仅维持了模型的高效性能,也显著提升了模型训练和部署的效率。然而当对base model进行规模化多任务微调时,相关部署成本可能会显著增加。基于实际应用场景,成本和效率考虑,我们在RTP-LLM框架上实现了两种LoRA方法:静态LoRA和动态LoRA。
- 静态LoRA:在模型加载时将LoRA权重叠加到底层模型中,适用于单LoRA的场景,可以提高模型的运行效率和降低计算开销。
- 动态LoRA:共享基座模型,根据不同的业务场景动态选择适当的LoRA参数。这种方式在保证模型性能的同时,显著节省了显存,提高了模型的适应性和灵活性,使同一种模型服务可以满足多种业务场景的需求。
目前,在阿里集团内部的推理平台-whale已经集成了静态和动态LoRA解决方案,该平台基于RTP-LLM框架,用于部署大型语言模型(LLM)。业务团队可以在whale平台通过一键部署快速将训练好的模型应用到生产环境,从而加速推动创新应用的实施。接下来的内容中深入探讨静态和动态LoRA的工作原理以及它们在现实业务场景中的性能表现,帮助您更好地理解这些技术,并根据实际业务场景选择合适的LoRA方案。
02 静态LoRA:效率之选


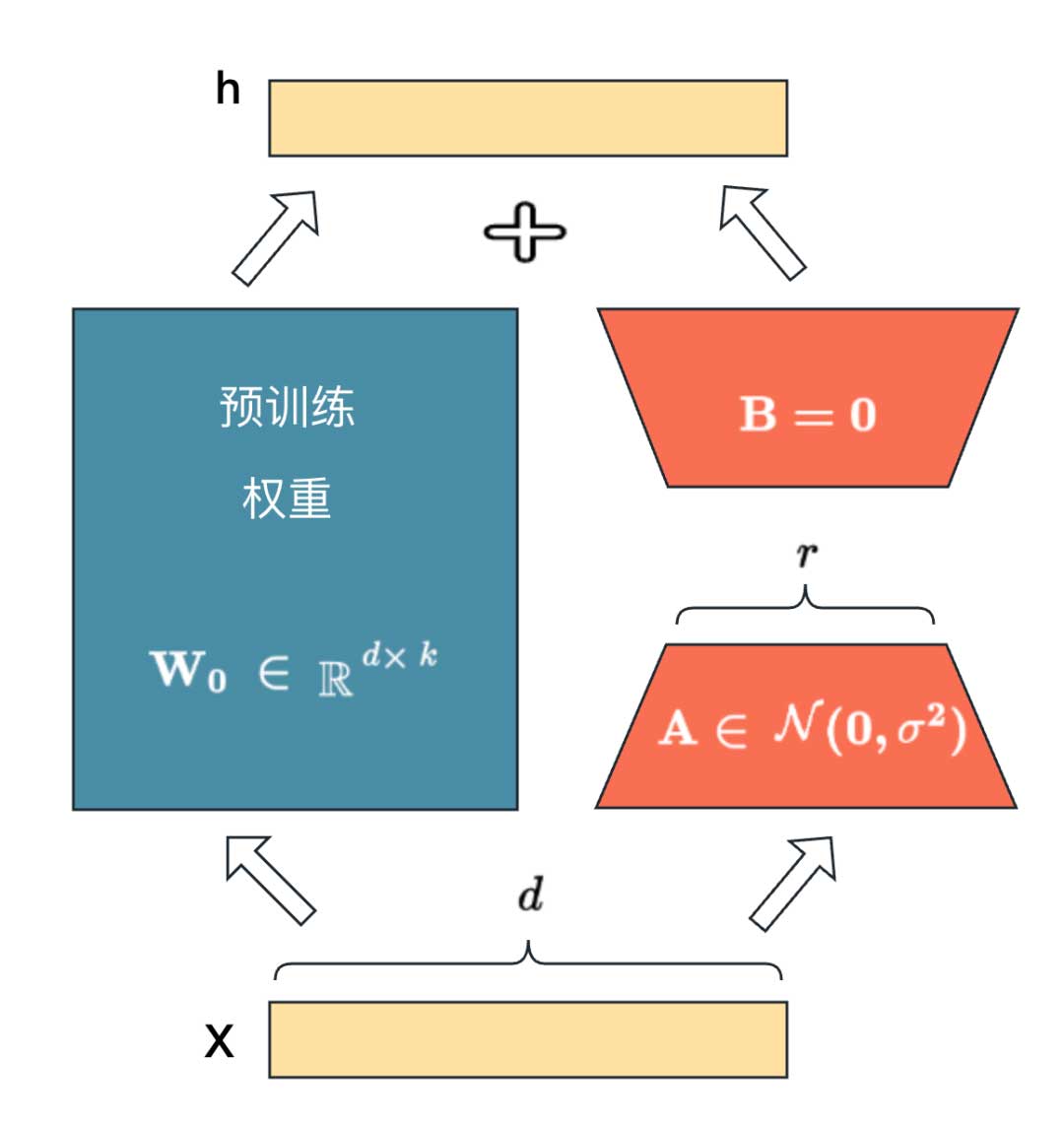
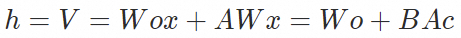
在线部署的时候我们可以将BA加到原参数上,从而在推理时不会产生额外的推理时延。在LLM场景我们可以将LoRA应用于Transformer模型结构中的任何权重矩阵子集,以减少可训练参数的数量。在Transformer模型结构中,Multi-Head Self-Attention模块 (Wq,Wk,Wu,Wo) 中有四个权重矩阵,FFN模块中通常有两到三个,下面以Multi-Head Self-Attention以及 FFN模块的计算逻辑为例,说明LoRA 在Transformer模型预测阶段的计算过程。
基座模型的多头自注意力机制(Multi-Head Self-Attention)计算公式为:
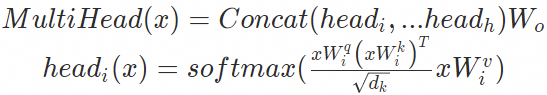
基座模型的(Feed Forward Network, FFN)计算公式为:
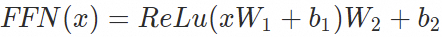
经过LoRA finetune之后模型的attention计算公式为:
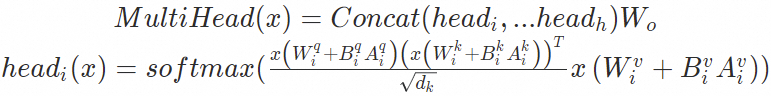
经过LoRA finetune模型的FFN层计算公式为:
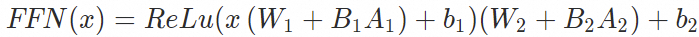
在只有单一LoRA任务的场景中,可以借鉴LoRA finetune之后的计算公式,并在模型加载时将LoRA权重叠加到base model的权重中,这种实现方式被称为静态LoRA。静态LoRA的主要优点是可以显著减少计算量,提高模型的运行效率。目前whale(大模型管控平台)已经支持了静态LoRA的部署,大家可以体验。
03 动态LoRA:灵活性考量
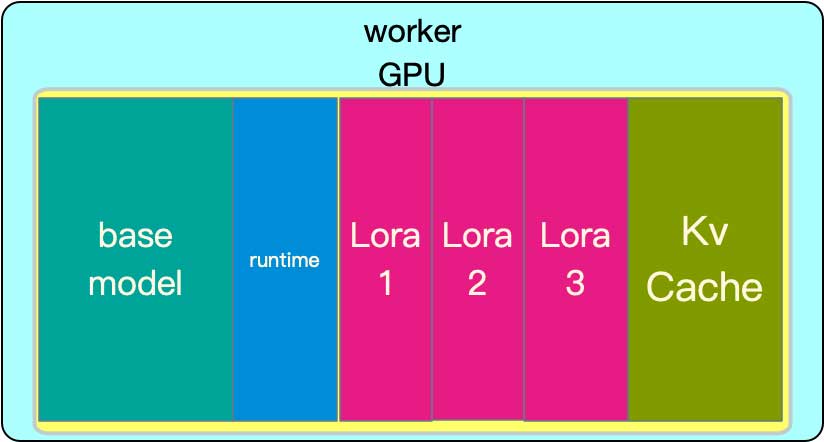
在whale平台部署多个基于相同base model微调的LoRA adapter任务时需每个adapter都作为独立模型实例运行,那么每个实例都需独立分配显存资源(如图2所示)。尤其在LoRA adapter请求比较稀疏的情况下,这种部署方式阻碍了对base model显存的集中管理和优化复用,显存资源以及GPU算力都得不到充分利用,造成了整体GPU的浪费。这种情况下,虽然确保了性能的稳定性,但在资源效率方面存在改进空间。
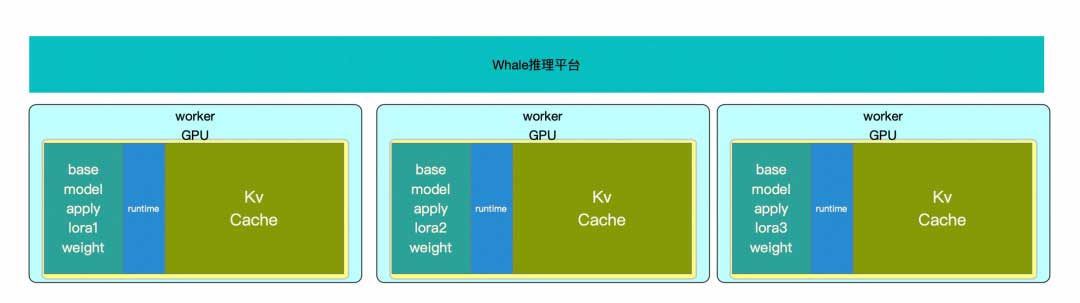
基于以上背景,我们参考S-LORA提出了动态LoRA的方案。如图3所示。动态LoRA采取分离base model权重和LoRA adapter的策略。推理时根据请求的adapter name,选择对应的LoRA adapter和base model结构加和完成推理。这种设计因其允许adapter之间的秩(rank)不同,具有较强的通用性。
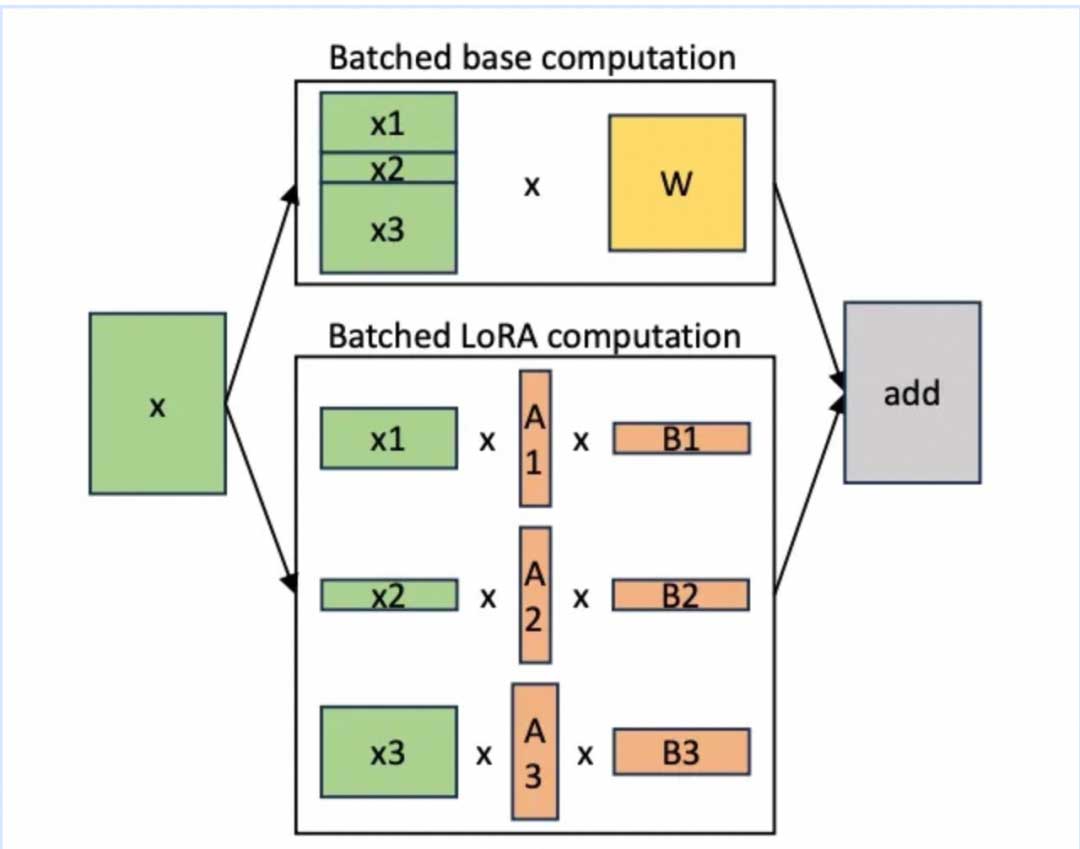
batching策略:针对共享base model的特点,我们对χ AB和χ ω分别采用不同的批处理策略来优化计算效率。对χω的批处理可以直接应用RTP-LLM的原生批处理优化技术:continuous batching。而对于χ AB,尽管其计算成本相对较低且参数少,但处理起来却相对复杂。这是因为输入的序列长度和adapter 的rank都是动态变化的,例如可能同时收到两个不同长度的查询和两个不同rank的adapter请求。为了处理这种情况,如果采用传统的批量GEMM内核,我们需要对某一个维度进行padding,且随着continuous batching rank也会动态变化,还需要动态地进行填充。因此计算χ AB的时候我们不padding,而通过GroupGEMM来实现χ AB batch计算,如图4所示,该方案可以更加高效地适应动态变化的LoRA rank。
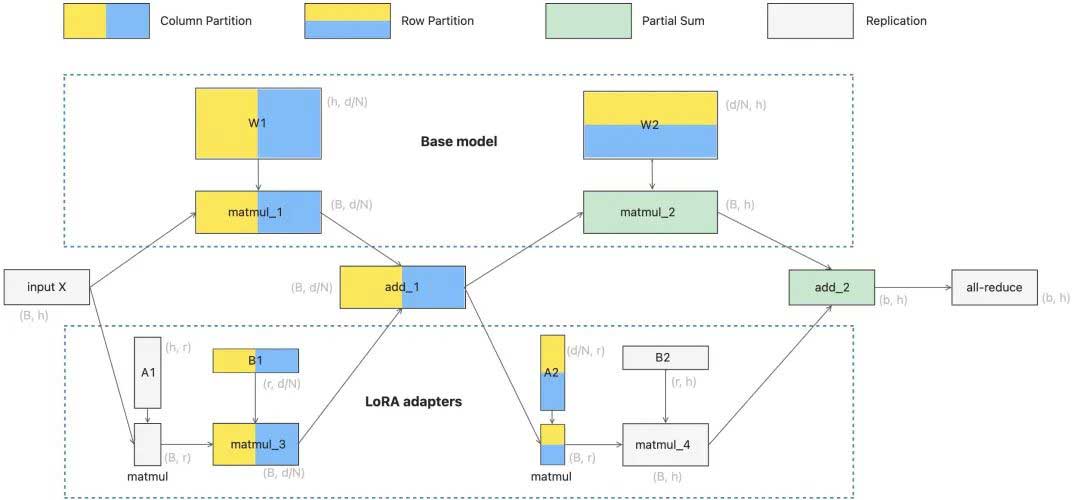
tensor-para: 如果把多adapter单base model部署在多卡环境,那就需要tensor-para。RTP-LLM的tensor-para 方案为:根据base model 的tensor-para切分策略,对tensor A或者B其中一个tensor进行冗余存储,这样不会因为计算x AB增加额外计算的通信需求。如图5所示,展示了一个两层MLP的切分方法,W1和W2两个tensor 分别对应的LoRA tensorA和B的切分策略,MLP的切分策略可以拓展到self-attention层。
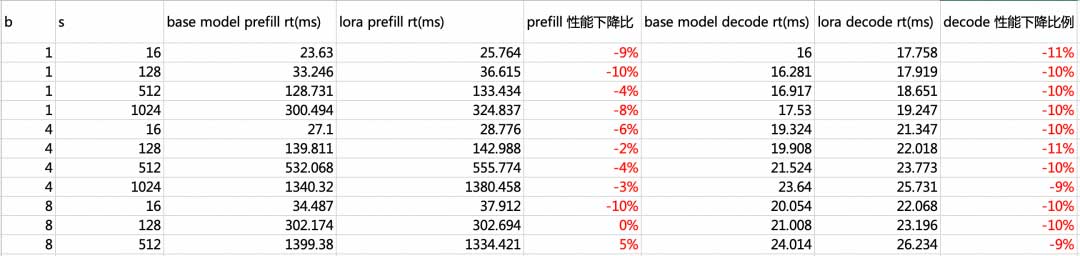
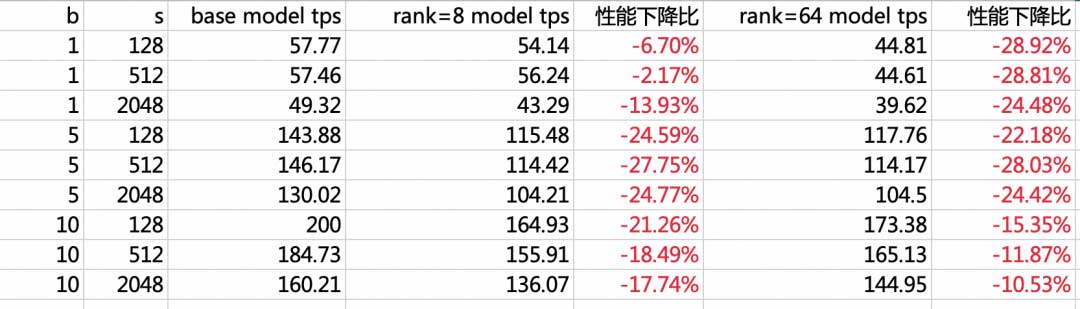
性能评估:
A10单卡机器上测试了qwen_7b lora_rank=8与base model的性能对比结果:
v100-16GB*4卡机器测试 llama2-13B lora_rank=8, 64,tensor-para=4与base model的性能对比结果:
动态LoRA通过分离base model 和 LoRA adapter 实现了多LoRA 任务base model显存共享,同一种模型服务可以满足多种业务场景的需求。云服务团队基于动态LoRA实现的LLM大模型的检索增强生成(Retrieval Agumented Generation,RAG)SAAS产品已发布,大家可以参考OpenSearch-LLM智能问答版使用指南进行试用。
04 动态LoRA的管理
LoRA动态上下线:在云服务场景中,出于成本和资源效率的考虑,业务通常仅部署一个实例来运行多LoRA任务,而不采用多实例部署。这种策略虽然节约了成本,但在LoRA更新时却可能会面临服务连续性和稳定性的挑战。
当需要对LoRA进行变更时,传统流程需要将整个实例下线,然后重启进程,重新加载base_model 以及多份LoRA adapter。这一过程可能导致至少5分钟以上的服务中断,从而降低了单实例的有效服务时间,并影响用户体验。为了缓解这种情况,RTP-LLM引入了LoRA adapter的热更新机制,这使得在实例提供服务的同时,可以快速更新LoRA adapter,显著减少了变更所需的时间并最小化了服务中断时间。
LoRA topo 管理:在云服务环境中,不同LoRA 任务所需的GPU显存大小不一致, 且不同LoRA任务的流量也呈现出不同的特点:一些LoRA为流量密集型任务,而一些LoRA任务则是流量稀疏的任务。不同的LoRA对GPU的显存和算力的要求不一致,单实例的GPU 资源有限,如何从整体资源效率出发,尽可能的让单实例的GPU资源利用率达到最优是我们在云服务场景面临的一个很重要的难题。目前我们采用智能管理方案来优化大语言模型(LLM)任务的执行流程,该方案包括几个关键步骤:
- 任务注册与模型性能评估:LoRA任务以及流量需求注册至quota server,同步评估LoRA任务的显存需求和算力需求
- 选择集群:quota server 综合考量当前集群性能和负载,以及LoRA任务的需求,选取最合适的集群或者新建集群。
- 资源调度与分配:系统将用户LoRA任务部署通过LoRA热更新机制部署到目标集群,确保资源的高效利用和任务的快速启动。
- 提供服务:LoRA 任务生效后,提供推理服务
该方案基于LoRA任务的需求来调配LoRA任务的部署。后续我们会做进一步的优化比如根据实时的流量,实现LoRA部署的动态调整,优化资源分布,从而在负载均衡和资源利用率之间找到最佳平衡。提高整体的资源效率。
05 后续规划
RTP-LLM通过预加载LoRA Adapter到显存中,有效降低了处理延迟,但显存大小也限制了单实例能支持的LoRA Adapter 的数量与大小。后续我们计划通过优化显存分配策略按需动态管理LoRA的显存占用,来扩大单实例支持的LoRA Adapter 数量。
参考链接[01] S-LORA
https://arxiv.org/pdf/2311.03285.pdf
作者:洛离,文央,李栋瑾,隐智
来源:阿里技术
原文:https://mp.weixin.qq.com/s/em-mnps_Oqe1PLLpJ9hB-A
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。