
本文是上下文自适应二进制算术编码的内容,主要包括算术编码器基础、二进制算术编码器介绍及算术编码过程的流程图。
标题:Context-adaptive binary arithmetic coding
链接:https://www.elecard.com/page/context_adaptive_binary_arithmetic_coding
作者:Oleg Ponomarev
内容整理:王妍、刘潮磊;原标题:[强基固本-视频压缩] 第六~七章: 上下文自适应二进制算术编码
算术编码器基础
让我们回顾一下使用 H.265/HEVC 系统编码视频帧的主要步骤(图1)。第一步,通常称为“块分割”,将帧分割成称为 CUs (编码单元)的块。第二步涉及使用空间(帧内)或时间(帧间)预测来预测每个块内的图像。当执行时间预测时,CU 块可以被分割成称为 PUs (预测单元)的子块,每个子块都有自己的运动向量。然后,预测的样本值从正在编码的图像的样本值中减去。结果,每个 CU 形成一个二维(2D)差异信号,或称为残差信号。第三步,2D 残差信号样本的数组被分割成所谓的 TUs (变换单元),每个 TU 都会经历离散的 2D 余弦傅里叶变换(对于包含帧内预测强度样本的 4×4 大小的 TUs 除外,这些 TUs 使用离散正弦傅里叶变换)。
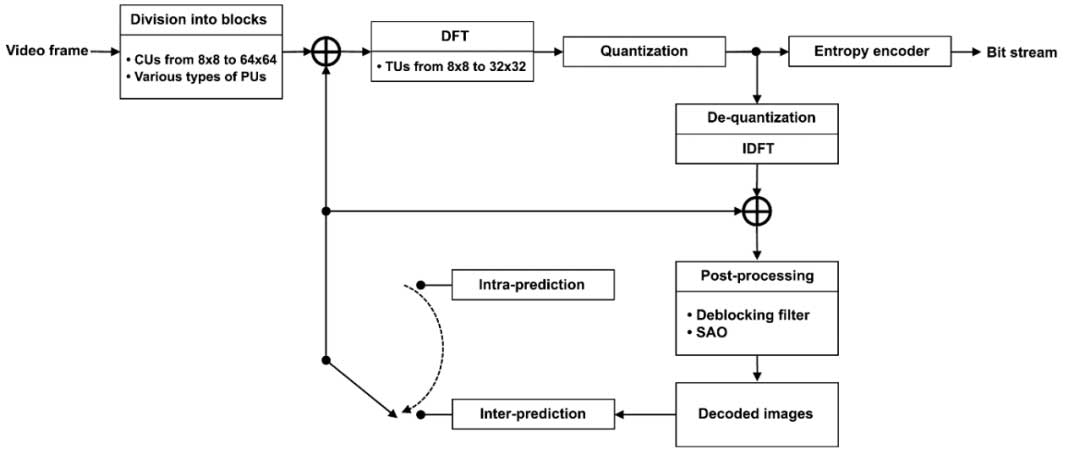

在下一步,得到的频谱傅里叶系数按级别进行量化。在四个步骤中执行的所有操作的数据被发送到熵编码器的输入端;这些数据稍后可以用来恢复编码后的图像。这是最后一步。传入的数据使用上下文自适应二进制算术编码(CABAC)算法进行额外的无损压缩。
二进制算术编码器介绍
让我们从“算术编码”开始探索这五个词(上下文自适应二进制算术编码)的实际含义。为了说明算术编码的概念,考虑一个简单的例子:压缩一个由 20 个字符组成的信息。我们只使用三个可能的字符:“a”,“b”,以及表示信息结束的 “EOF” 字符。信息本身看起来像这样:{b, a, b, b, b, b, b, b, b, b, a, b, b, b, b, b, b, b, b, b, EOF}。压缩过程将递归地分割当前区间。我们将[0, 1) 作为初始区间,并根据信息中的字符频率按比例分割成更小的区间。在 20 个可能的字符中,“b”出现了 17 次,“a”出现了 2 次,“EOF”只出现了 1 次。这次分割将产生三个区间:[0, 2/20), [2/20, 19/20), 和 [19/20, 1)。信息的第一个字符是“b”。现在我们选择长度与字符“b”频率成比例的区间,即[2/20, 19/20),作为当前区间。然后我们像上面一样分割当前区间,并选择长度与下一个字符频率成比例的区间作为下一个当前区间。这个过程一直重复直到信息结束。让我们以表格的形式展示我们的编码工作流程。
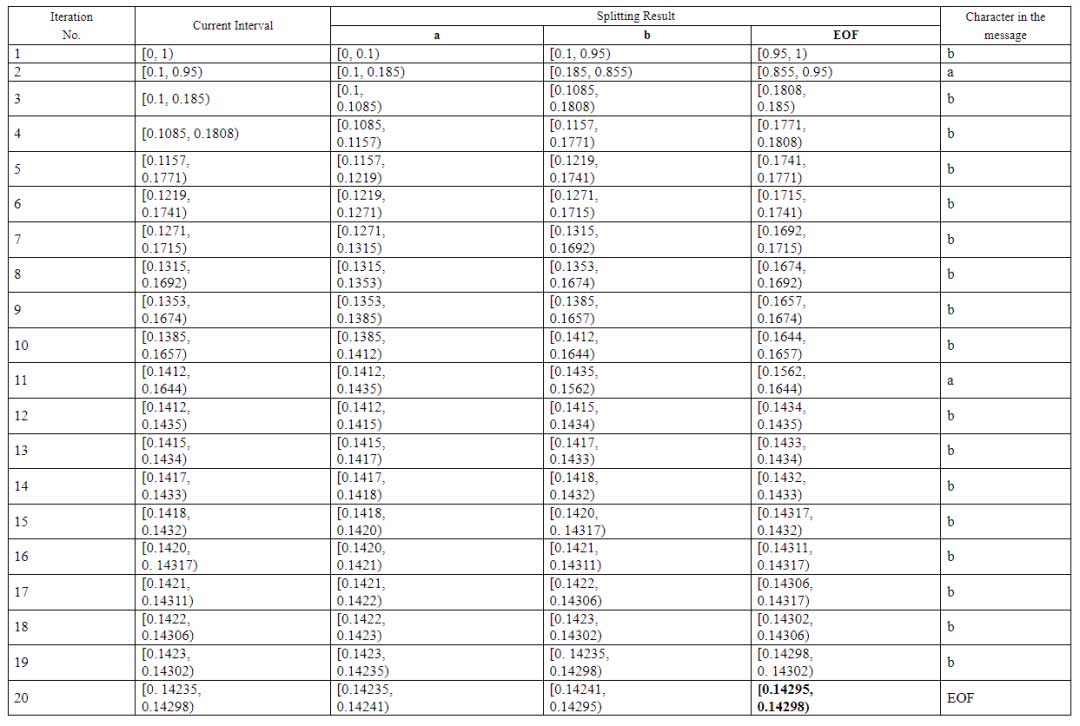
当前区间的递归分割导致了表格中加粗的区间,我们将在这里以未四舍五入的形式展示:[0.142948471255693, 0.142980027967343)。在二进制表示中,这个区间表示为[0.001 001 001 001 100 00100010101100001000011100111000000010, 0.001 001 001 001 101 00101011010000000110011101010011101)。对应的十进制数 0.142959594726563,包含在结果区间内,是编码后的信息。这是一个 16 位值。因此,一个 20 个字符长的字符串已经被转换成了一个 16 位的代码。我们压缩了我们的信息!
现在让我们尝试解码它。再次,我们将[0, 1)作为初始区间,并根据信息中的字符频率进行分割。显然,包含数 0.142959594726563 的区间是中间的区间[0.1, 0.95),因此第一个解码的字符是“b”(这在第一行的第五列中反映出来)。[0.1, 0.95)现在成为当前区间,我们再次根据信息中的字符频率将其分割成三部分。结果在表格的第一行的第二行中显示。数 0.142959594726563 属于结果区间的第一个区间[0.1, 0.185)。这个区间的长度与字符“a”的频率成比例,因此“a”是下一个解码的字符。从上面的描述中可以明显看出,整个解码过程已经在表格1中描述。当前区间的迭代分割将继续,直到解码字符 “EOF”,表示信息结束。
尽管这些迭代分割当前区间的程序实际上实现了消息的算术编码和解码,但它们与使用 CABAC 算法进行编码/解码的方式几乎没有相似之处。这主要是由于上述编码和解码程序的两个显著的实际缺点。首先,我们只有在处理完整个消息后才得到编码结果。在那之前,结果的任何一位都不知道。同样,为了开始解码,我们需要知道表示编码消息的整个比特序列。第二个缺点也从我们的例子中很明显。当当前区间被迭代分割时,每次迭代都需要更高的精度来表示区间端点。因此,消息越长,编码器和解码器处理它所需的时间(延迟)就越长,实现算术编码算法所需的精度(处理比特宽度)就越高。
让我们指出与编码程序相关的几个相当明显的考虑因素。显然,如果当前区间完全包含在 0 和 ½ 之间,编码结果的当前比特将是零。同样,如果当前区间完全包含在 ½ 和 1 之间,编码结果的当前比特将有一个值 1。然而,如果当前区间的左端点小于 ½,右端点大于 ½,但两者与 ½ 的差异不超过 ¼,当前结果比特将是未知的。另一方面,可以肯定的是,下一个结果比特将与当前比特的值相反。当我们为这次迭代获得每个当前结果比特后,我们可以将区间长度加倍。所有这些都使得引入一种克服算术编码上述缺点的当前区间长度加倍程序成为可能。
这个程序在标准中被称为重新归一化。通过重新归一化,编码结果比特在编码过程中立即输出(在完成之前),并且当前区间长度加倍。每次选择新的当前区间时,都会迭代执行重新归一化。迭代继续进行,直到当前区间完全包含在以下三个区间之一:[0, 0.5), [0.25, 0.75), [0.5, 1)。如果当前区间没有完全包含在这些区间中的任何一个,迭代就停止。否则,如果当前区间在这三个区间中的一个内,就会执行三个处理序列中的一个,每个序列对应一个特定的区间。
如果整个当前区间包含在区间[0, 0.5)内,输出结果比特为 0,然后输出与处理前一个字符时累积的 1 值比特数量相同的 1 值比特。(输出到结果比特流的 1 值比特数量等于标准中名为 bitsOutstanding 的计数器的值。在输出 1 值比特后,计数器重置为 0)。当前区间的端点值加倍。(结果,区间的长度也加倍;为了简洁,让我们称这种加倍为“向右扩展区间”。)
如果整个当前区间包含在区间[0.5, 1)内,输出结果比特为 1,然后输出与处理前一个字符时累积的 0 值比特数量相同的 0 值比特。(同样,零的数量等于 bitsOutstanding 计数器的值,该计数器在此操作后重置为 0。)区间端点向左移动,以便将它们与点 1 的距离加倍。(我们将称这种区间加倍为“向左扩展区间”。)
如果当前区间完全包含在区间[0.25, 0.75)内,这个事实需要被记住以便于后续结果比特的输出(将bitsOutstanding计数器增加 1)。左区间端点向左移动,以便将其与 0.5 的距离加倍。右区间端点向右移动,与 0.5 的距离也加倍。(我们将称这种区间加倍为“向两侧扩展区间”。)
此外,让我们形式化选择编码消息的最后两位比特的程序,这些比特决定了从迭代分割得到的区间中选择特定二进制值。这个程序非常简单:如果结果区间的左端点小于 0.25,那么最后两位消息比特就是{0, 1},否则它们就是{1, 0}。
为了说明重新归一化程序的工作原理,我们将使用编码相同 20 个字符的消息的例子:{b, a, b, b, b, b, b, b, b, b, a, b, b, b, b, b, b, b, b, EOF}。
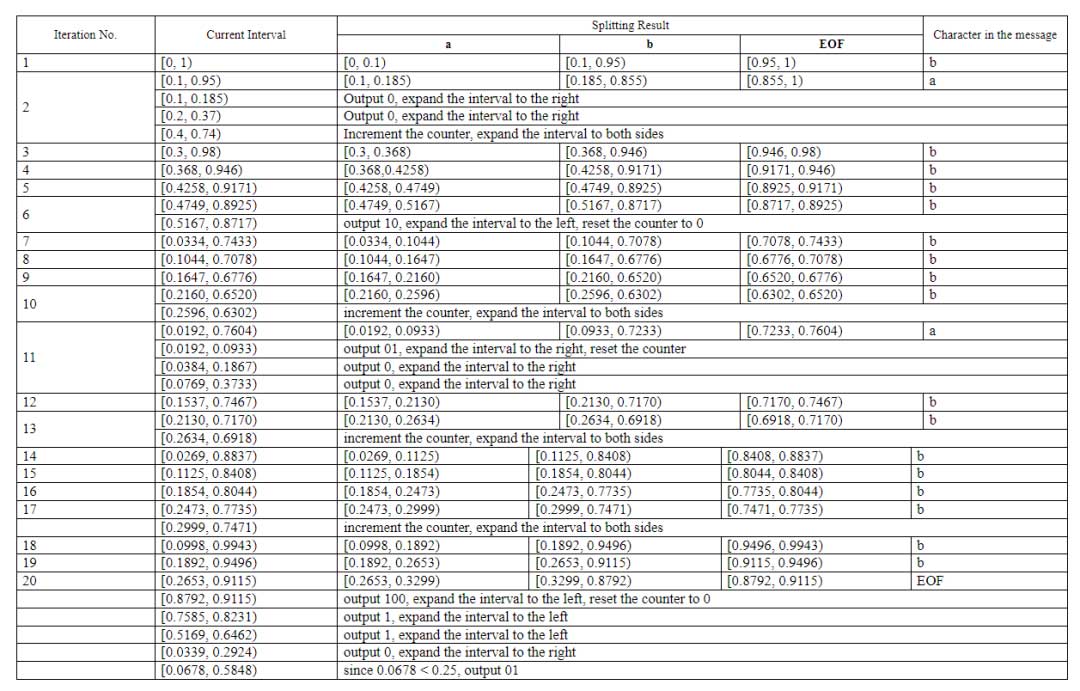
编码的结果是 001 001 001 001 100 1。这些是我们之前在不使用重新归一化程序时获得的相同的 16 位。

其中 Lc 是当前区间的左端点,L 是分割后当前区间左端点的新值,Hc 是当前区间的右端点,H 是分割后当前区间右端点的新值。
算术编码过程的流程图

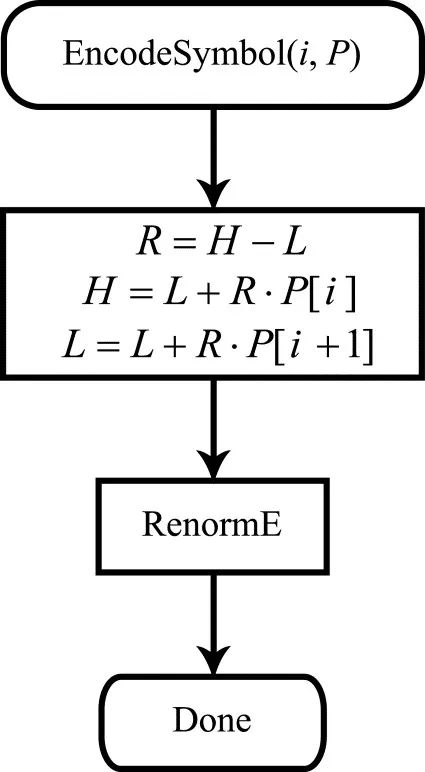
EncodeSymbol() 过程接受两个参数:要在字母表中编码的字符的编号 i ,以及,Pi 数组 P 。正如从流程图中可以看出的,第一个编码步骤包括计算当前区间长度的 R(使用左右区间端点的当前值,即 L 和 H )。数量 H 用于计算区间端点的更新值。因此,在每个消息字符的第一个编码步骤中,我们分割当前段。第二步包括一个归一化过程,如图3所示的流程图。
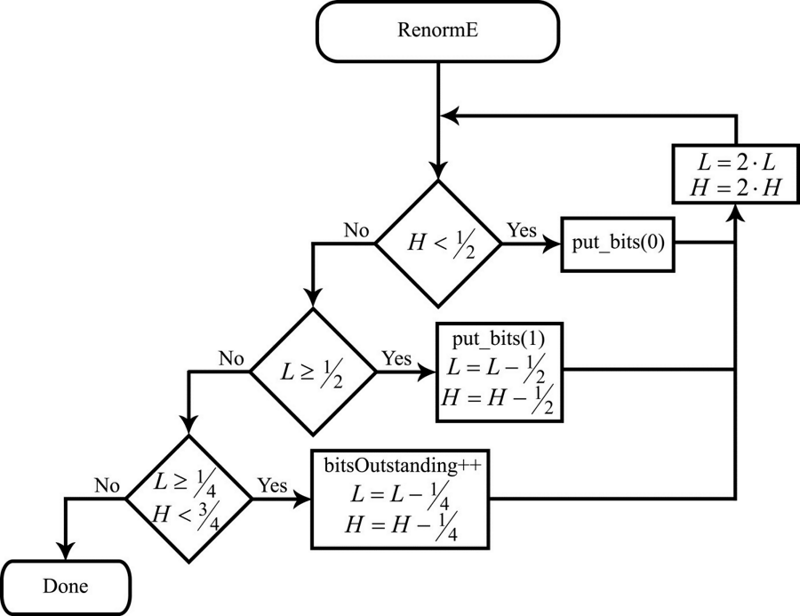
在讨论归一化时,如果当前区间完全包含在范围 [0,1) 内,即如果 H < 1/2 ,那么在结果比特流中会输出一个零,并且零后会存在长度等于bitsOutstanding变量值的一。所有这些操作都在put_bits()过程内执行,该过程在图3中以流程图的形式展示。区间端点值公式和公式会被加倍。
如果当前区间完全包含在范围 [1/2,1) 内,即:如果 L>=1/2 ,那么在结果比特流中输出一个一,后跟一系列长度等于bitsOutstanding变量值的零(此处再次使用put_bits()。在这种情况下,区间端点会被修改,以使从 L 和 H 到1的距离加倍。因此,L 和 H 的更新值可以计算为:
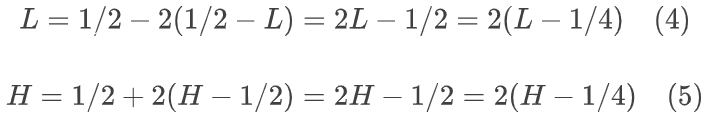
这是在RenormE过程的这个分支中执行的。
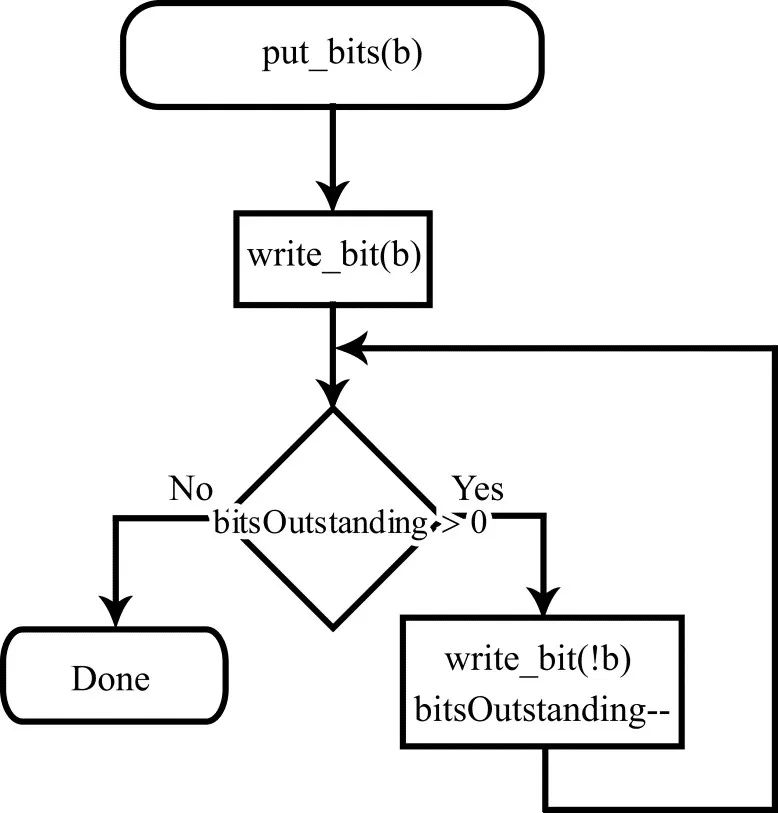
put_bits()过程的流程图如图4所示。该过程以比特值(0或1)作为参数,并将其输出到表示算术编码结果的结果比特流中。在流程图中,将比特输出到流的过程被标记为write_bit()。在完成输出后,检查bitsOutstanding的值。一系列!b值(在此,流程图使用C语言的布尔非运算的语法)等长于bitsOutstanding的值被输出到比特流中。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。