
1. 前言
随着互联网技术的不断发展,越来越多的人开始尝试使用或者依赖实时音视频产品解决团队沟通与协作问题。在通话过程中,我们时常会遇到因为网络波动(如拥塞、丢包、延时和抖动等)而导致的音频卡顿、掉字或者杂音等问题,影响工作效率。为解决此类音频弱网问题,业界一般采用前向纠错(Forward Error Correction,FEC)或者重传等网络策略优化方法,但这些方法存在冗余率过高、带宽利用效率低等缺点,而提升音频编码器的编码效率和抗丢包能力、提高带宽利用效率,是解决音频弱网问题更为高效的一种方法。Opus 作为 RTC 领域广泛使用的音频编码器,其编码质量较高,且提供一定的抗丢包能力,但是在高丢包以及突发丢包场景,音质会明显下降,同时,其编码效率也有进一步提升的空间。RTC 自研 NICO(Network Intelligent Audio Coding,NICO)编码器在完全兼容Opus 的基础上,极大提高了编码效率,并提供了超强的抗丢包能力。目前 NICO 已经成功集成进火山引擎 RTC,并应用于抖音和视频会议等业务,极大提升了弱网场景音频体验。
2. 音频编解码技术简介
音频编码器是一种将音频信号进行压缩和解压缩的装置。一般分为 3 大类:波形编码器、参数编码器和统一编码器。
2.1 波形编码
波形编码,顾名思义就是对音频信号的波形进行数字化处理。G.711 是由 ITU-T 制定的一个典型的波形编码器,码率为 64kbps,最早应用于固定电话场景,其核心思想是将每一个 14 比特的音频采样数据压缩成 8比特 表示。G.711 利用了人耳对大能量信号不敏感的特点,幅度大的信号量化误差大,幅度小的信号量化误差小,可以将信号码率压缩 50% 左右。
2.2 参数编码
随着科学家对语音信号的特性和人耳感知声音的机制理解更加深入,参数编码器逐渐在语音编码和音频编码领域成为主流。参数编码就是指通过对信号提取若干个特征参数,并对特征参数进行量化压缩的方法。参数编码不以波形匹配为准则,而是通过对信号中的关键特征进行提取,并以高效的量化方式进行压缩,达到高质量恢复信号关键信息的目的。因此,参数编码器的编码效率也要明显高于波形编码器。下面分别针对语音和音频信号的参数编码方法进行说明。
2.2.1 语音编码
下图是一个码激励线性预测(Codebook Excitation Linear Prediction,CELP)编码器系统框图,是一个典型的参数语音编码器。主要利用了语音信号具有短时相关性和长时相关性的特点,使用线性预测的方法去除相邻样点间的相关性(即短时相关性),提取到线性预测(Linear Prediction Coding,LPC)系数,通过分析语音信号中的长时相关性提取基音周期参数,去除语音信号中的长时相关性,然后利用随机码书拟合随机激励信号,通过分析合成的方式获得最佳编码参数。这种方式只需要对 LPC 系数、基音周期、随机码书和两个增益参数进行量化压缩,解码端就可以恢复高质量语音。参数编码器只需要不到 20kbps 的码率即可达到与 G.711@64kbps 相同的质量,编码效率具有明显的优势。典型的编码器有:G.729、AMR-NB 和 AMR-WB 等。
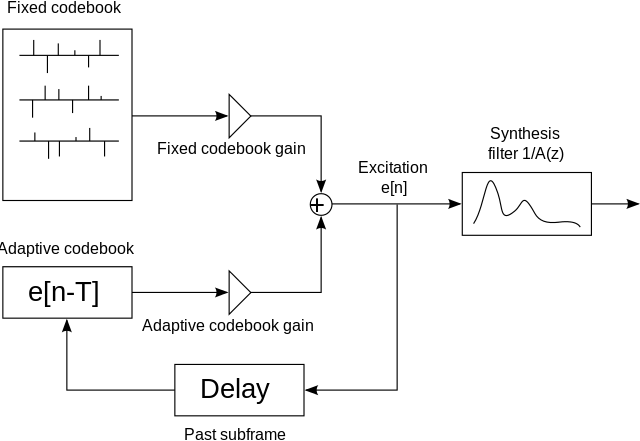

2.2.2 音频编码
下图是一个典型的频域编码器系统框图。音乐信号和自然界的声音是通过不同的载体进行发声的,发声方式也千差万别,不太可能利用发声方式进行建模。换句话说,使用语音编码的方法编码音频信号的编码效率不高,编码质量比较差。于是科学家另辟蹊径,通过对人耳感知声音的方式进行研究,发现人耳对不同频率信号的感知敏感度也有所不同,因此发明了一种基于心理声学模型的编码器,尤其适合对音乐信号和自然界声音的编码。典型的编码器有:MP3、AAC 和 HE-AAC 等。
2.3 统一编码
综上可知,语音编码器只适合编码语音信号,音频编码器只适合编码音频信号。在实际应用场景中,我们经常会遇到在说话过程中会有音乐或者其他背景声音的场景。那么是否存在一种编码器,能够依据信号的类型,自适应选择最佳编码方式,达到最佳编码质量呢?答案是肯定的。统一编码器采用统一框架高质量编码语音信号和音频信号,它能够很好的解决混合语音和音乐信号的高质量编码问题。典型的统一编码器有:Opus、EVS 和 USAC 等。
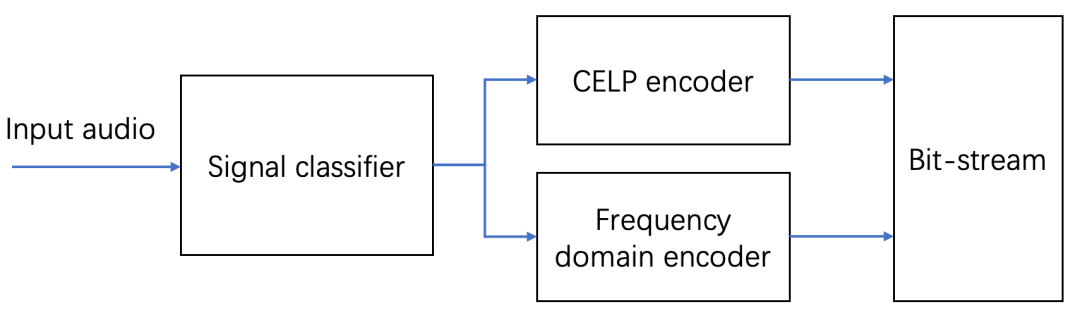
3. 自研 NICO 编码器技术优化
为了解决 Opus 编码器在高丢包以及突发丢包场景中质量变差的问题,自研 NICO 编码器引入了多种编码工具和创新技术,以提高编码器抗高随机丢包和突发丢包的能力。另外,在提高编码效率的同时,NICO 实现了与 Opus 编码器完全兼容,解决了与现网 RTC 设备互联互通的问题。
3.1 抗弱网编码技术及优化
3.1.1 多描述编码
多描述编码是一种专门为弱网场景设计的编码技术,其核心思想是“编码器产生的多个描述码流相互独立又互为补充”。单个多描述码流就可以解码获得完整语音,每多收到一个多描述码流,获得的解码语音质量可以得到进一步增强。多描述编码方法是一种非常适合在无可靠传输网络场景使用的编解码技术,能够有效减少由于丢包引起的各种音频卡顿问题,但是在无丢包场景,其解码质量差于单码流编码器。而且,多描述编码算法的复杂度要比单码流编码器高很多,多描述码流个数越多,复杂度就会成倍增加,这也在一定程度上限制了多描述编码技术的使用。
针对上述问题,我们在设计多描述编码算法时,对现有多描述编码技术和 Opus 编码器中 NSQ 量化方法进行了详细的分析。我们发现,现有算法只能做到宽带多描述编码,且高频质量明显差于Opus,同时 Opus 中 NSQ 量化方法十分复杂,基于 Opus 的多描述编码复杂度会明显偏高。我们通过多种技术优化,解决了上述难题,使 NICO 支持了窄带到全带的多描述编码,满足了不同应用场景对编码音质的差异化需求,同时保证了 NICO 在无丢包场景编码质量能对齐甚至稍优于 Opus,在高丢包场景明显优于 Opus,而编码复杂度和 Opus 相当。
3.1.2 带内 FEC 算法
带内 FEC 算法是一种在当前帧码流中携带过去历史帧码流的一种方法,与带外 FEC 算法相比,其减少了 RTP 头部开销,比特利用效率更高。当 Opus 码流携带带内 FEC 信息时,如果当前帧码流数据丢失,解码器可以通过解析下一帧码流中的带内 FEC 信息解码当前帧音频。Opus 带内 FEC 有不错的对抗随机丢包的能力,但对突发丢包无能为力,开启带内 FEC 也会导致编码复杂度明显上升,并且其带内 FEC 帧信息在无丢包时不会带来额外的质量提升,带宽利用效率不高。在实际使用场景中,我们还发现带内 FEC 占用码率过多,影响主帧编码质量,会导致杂音的问题。
为解决上面这些问题,NICO 带内 FEC 算法做了许多创新,全面优化了编码流程和码率分配等环节,提升了编码效率,降低了编码复杂度,并且在突发丢包场景,NICO 的效果远优于 Opus。
3.1.3 丢包隐藏算法
丢包隐藏(Packet Loss Concealment,PLC)算法是指当前帧的码流因为某种原因丢失时,解码器利用历史解码数据或者参数预测当前帧解码数据的算法。PLC 算法作为恢复丢失帧音频的最后解决方案,是大多数音频编码器中常用的技术,对提升丢包场景下的主观听感有较大作用。Opus 的 PLC 算法对丢包帧处理较为简单,对于能量、基音周期等参数只是做简单的衰减或者复制等操作,恢复出的音频经常会出现能量偏低、杂音等问题。NICO 对此进行了大量改进,参考了历史帧的变化趋势,对于丢包帧解码参数预测更为准确,恢复的音频听感较 Opus 有明显提升。
3.2 编码质量提升
3.2.1 带宽扩展算法
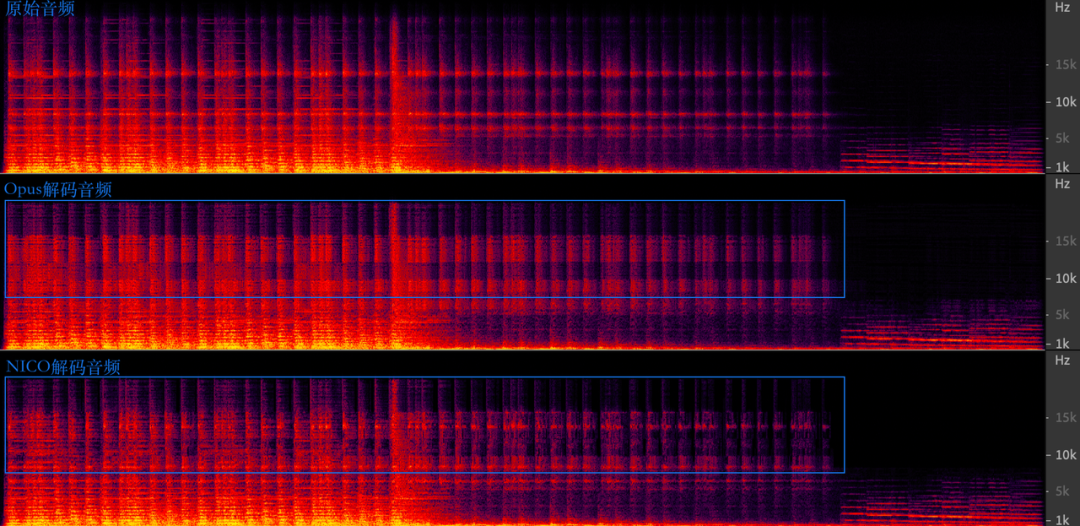
带宽扩展(BandWidth Extension,BWE)是一种使用少量比特编码高频信息,高质量恢复高频信号的算法。在 Opus 编码器中,所采用的 BWE 技术是以填充随机噪声的方式恢复高频空洞,这种方式会导致恢复出的高频信号能够听到明显的高频噪声,体验较差;在低码率编码方法中,还会使用频谱折叠的方式恢复高频,由于没有考虑高频与低频信号的相关性,折叠后的高频部分与原始信号往往相差较大,有时会听到明显的高频量化噪声。在 NICO 编码器中,我们对 BWE 算法进行了改进,充分利用高频与低频信号的相关性优化高频恢复效果,提升了低码率条件下音频信号的恢复质量。
下图是低码率 Opus 和 NICO 解码音频的频谱对比。可以看出,在高频部分,Opus 使用随机噪声恢复,而 NICO 恢复了更多的高频细节,与原始信号更为接近。
3.2.2 不连续传输算法
不连续传输(Discontinuous Transmission,DTX)是指 VAD 算法检测到非活动语音时,编码器会减少数据发送,只间隔性发送低字节数的静音描述帧(Silence Insertion Descriptor,SID),达到降低编码码率的目的。舒适噪声生成(Comfort Noise Generation,CNG)指的是解码端收到 SID 帧后会依据解码参数生成舒适噪声,保持听感连续。Opus 的 DTX/CNG 算法存在编解码端 CPU 消耗偏高、VAD 算法不够准确导致出现不平稳噪声等问题。针对上述问题,我们对 DTX/CNG 算法做了一系列优化,改进了编码端 VAD 算法和编解码处理逻辑,解决了舒适噪声不平稳问题,还大幅降低了 DTX 段编码端与解码端的 CPU 消耗。
以下是 Opus 和 NICO 解码带噪语音的效果对比,Opus 解码音频在噪声段不够平稳,而 NICO 解码音频噪声段能量平稳,听感更佳。
3.2.3 动态模式切换
在实际通话过程中,用户的网络状况可能比较复杂。为了在各种网络状况下获得最佳通话质量,我们设计了动态模式切换功能。编码器可以依据网络反馈的网络状态信息自适应调整编码模式。当用户网络状况很好时,编码器基于网络反馈的丢包率信息自动切换到 Opus 编码模式,以获得更优语音通话质量;当用户网络状况变差时,编码器基于网络反馈的丢包率以及带宽等信息,从 Opus 编码动态平滑切换到 NICO 模式编码,提升编码器的抗丢包能力。
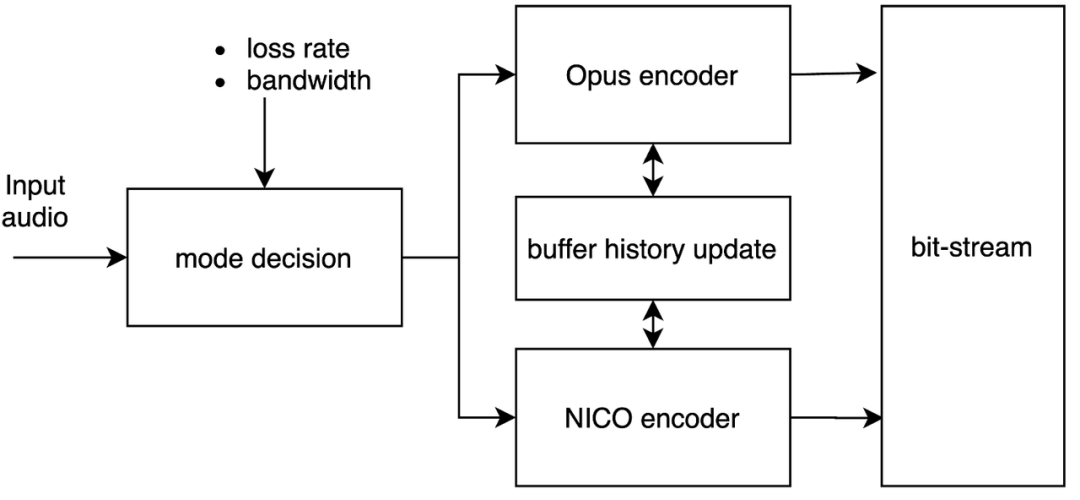
3.3 兼容 WebRTC 的设计
传统方案中,让具有不同编码器能力的终端进行通信,往往需要服务器进行转码再转发的操作,而转码操作会造成音质下降、复杂度增加和延时变长等问题。NICO 编码器通过独特的码流设计,使得 NICO 的码流与 Opus 完全兼容。换句话说,具有 NICO 编码能力的客户端能和 Web 端等原生 WebRTC 应用直接进行互通,不仅规避了转码服务器带来的各种问题,还拓展了 NICO 的应用领域,在 P2P 通信和不同厂商间互联互通等场景都能无障碍使用 NICO。
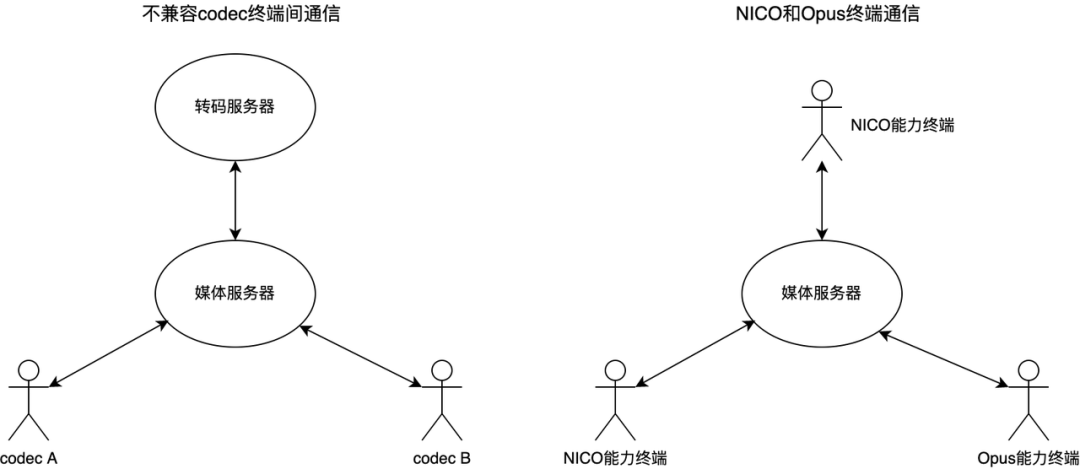
为了达到与原生 Opus 完全兼容的目的,NICO 的码流结构和 Opus 完全一致。当只有 Opus 解码能力的终端在接收到 NICO 的码流时,也能解码出正常质量的语音,听感较解码原生 Opus 的码流无明显差异;而具有 NICO 解码能力的终端解析 NICO 的码流时,便能使用到 NICO 的抗丢包能力,在丢包场景下达到远优于 Opus 的效果。
为提升抗丢包能力并完全兼容 Opus 码流,NICO 编码器做了非常多的技术创新和改进,同时对复杂度也做了很多优化工作,达到对齐 Opus 的水平。这些优化工作在保证质量的同时降低了 NICO 的复杂度,确保 NICO 在低端机器上都能够流畅运行。
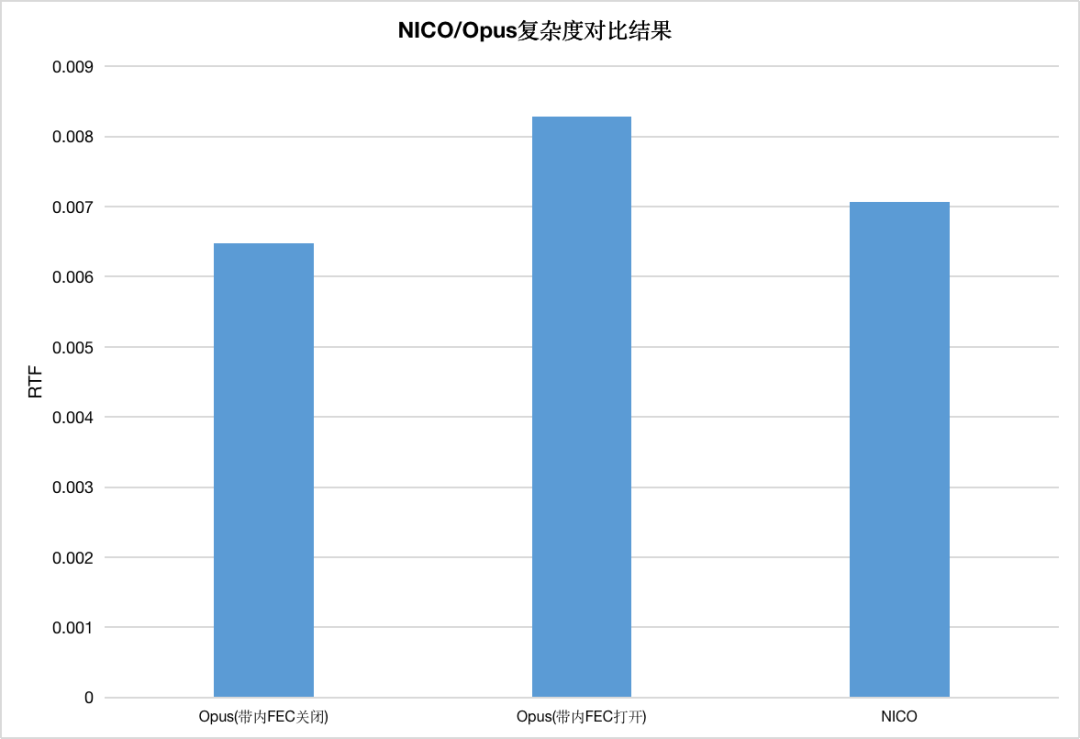
下图为 NICO 和 Opus 编码器 CPU 消耗对比结果,测试采用了实时率(Real-Time Factor,RTF)作为 CPU 消耗衡量指标。在 iPhone Xs Max 手机上,NICO 在优化特性都开启的情况下,CPU 消耗相较于 Opus 关闭带内 FEC 增加了9%,而相较于 Opus 打开带内 FEC 降低接近 15%。
3.5 质量对比
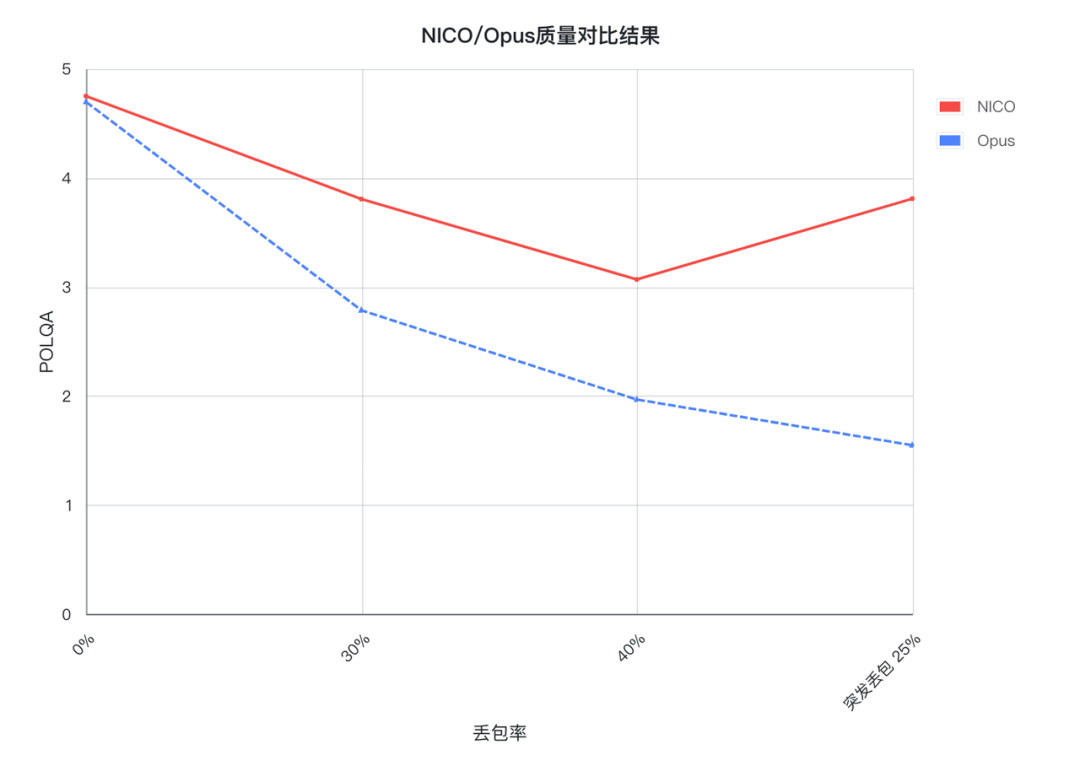
我们评估了 NICO 与 Opus 开启带内 FEC 在同等码率、无丢包、随机丢包 30%、40% 和突发丢包 25% 测试条件下的 POLQA 打分。结果显示,Opus 解码音频质量随着丢包率的增加有明显下降,在突发丢包场景下,更是降到 2 分以内。NICO 解码音频随着丢包率的增加,MOS 分有一定程度下降,但下降缓慢且明显优于 Opus。在突发丢包 25% 时,NICO 的 MOS 分接近 4 分,远远好于 Opus。
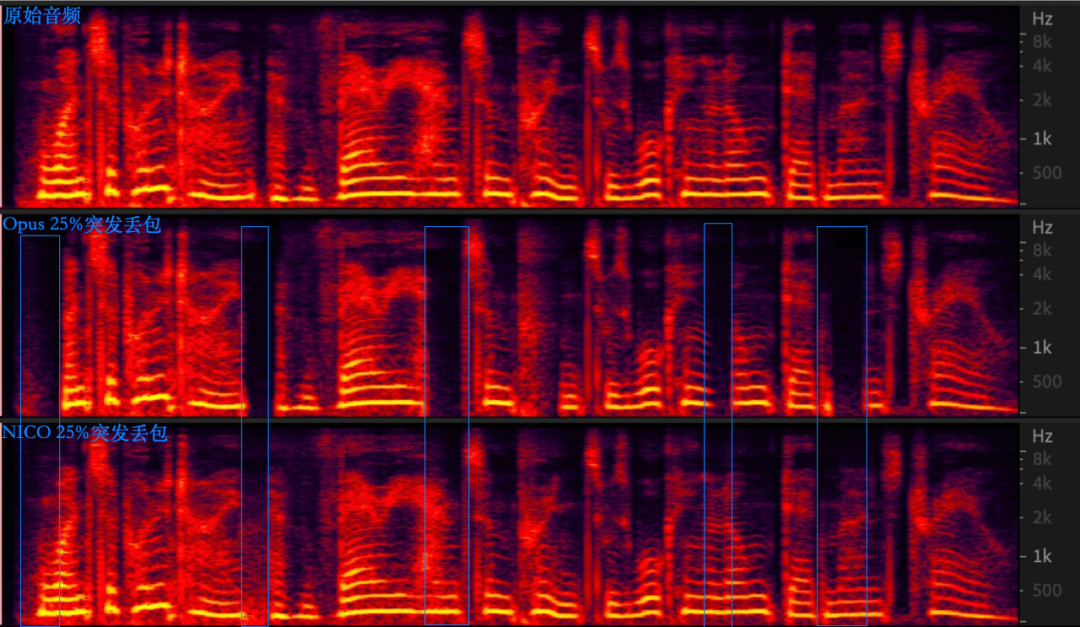
下面是 Opus 和 NICO 在 40% 随机丢包和 25% 突发丢包条件下的频谱对比示意图。从频谱图上来看,Opus 在随机丢包场景会频繁出现因 PLC 造成的能量衰减、频谱能量不连续的情况,而 NICO 的频谱恢复效果更好,有更好的连续性,没有明显的频谱上的损伤。
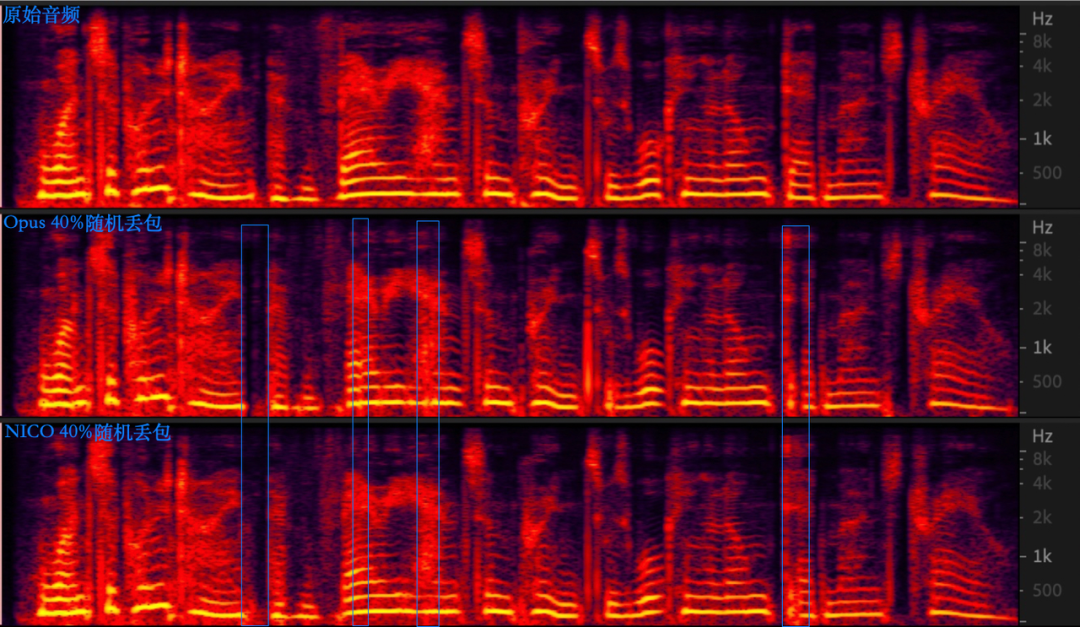
在突发丢包场景,Opus 解码音频会出现语音听感明显不连续、卡顿掉字等现象,而 NICO 解码音频的连续性非常好,无任何卡顿。
3.6 小结
可以看出,相较于带外 FEC、重传等网络策略,提升编码器抗弱网能力和编码质量是解决音频弱网痛点问题性价比更优的方案。相比业界已有方案,NICO 编码器的技术优化和创新工作具有以下几项优点:
- 全面支持窄带到全带多描述编码,满足不同业务场景对编码音质的差异化需求,改进带内 FEC 和 PLC 算法,在高丢包与突发丢包场景,弱网抗性明显优于 Opus 编码器;
- 改进 BWE、DTX 和 CNG 等算法,提出动态编码模式切换方法,明显提升编码质量;
- 独特的码流设计完全兼容 Opus,确保 NICO 终端与 WebRTC 终端以及不同 RTC 厂商互联互通,降低了端到端兼容性改造成本;
- 高效优化编码复杂度,保障在高中低端机上均可以流畅运行,使用火山引擎 RTC 应用的用户都能享受到 NICO 带来的质量提升。
4. 未来展望
目前,NICO 主要针对通话场景做了大量优化工作,提升了弱网场景的音频体验,后续我们会将其拓展到其它场景,例如直播、连麦和空间音频传输等。同时,AI 技术为编解码器方向带来了技术革新,未来有潜力在复杂度可控和超低码率条件下实现高清音频通话,进一步提升用户在弱网场景下的通话体验,我们将密切关注业界相关技术的进展,不断提升火山引擎 RTC 语音相关技术的能力上限。
参考资料
- Recommendation G.711 (11/1988): Pulse code modulation (PCM) of voice frequencies
- M. Schroeder; B. Atal, 1985. Code-excited linear prediction(CELP): High-quality speech at very low bit rates. ICASSP ’85. IEEE International Conference on Acoustics, Speech, and Signal Processing
- Andreas S., Ted Painter. Audio Signal Processing and Coding ,2007, Wiley-Interscience
- Neuendorf; et al. The ISO/MPEG Unified Speech and Audio Coding Standard – Consistent High Quality for all Content Types and at all Bit Rates, 2013, Journal of the Audio Engineering Society. Audio Engineering Society
- J.M. Valin, RFC 6716: Definition of the Opus Audio Codec, 2012
- V.K. Goyal. Multiple description coding: compression meets the network, 2002,IEEE Signal Processing Magazine
- H Sanneck, A Stenger, A new technique for audio packet loss concealment. Proceedings of GLOBECOM’96
关于我们
火山引擎 RTC,致力于提供全球互联网范围内高质量、低延时的实时音视频通信能力,帮助开发者快速构建语音通话、视频通话、互动直播、转推直播等丰富场景功能,目前已覆盖互娱、教育、会议、游戏、汽车、金融、IoT 等丰富实时音视频互动场景,服务数亿用户。
作者:张德军 字节跳动视频云技术团队
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。