
在使用语音识别服务进行语音转文字的过程中,大多数情况下模型能正确地预测高频词汇,但是对诸如人名地名、命名实体等词频较低或与用户强相关的词汇,模型往往会识别为一个发音相近的其他结果,这使得语音识别模型在日常生活中、垂直领域落地时并不完美。
热词定制化 (Hotword Customization)是针对低频偏僻词语识别而出现的语音模型研究。通过基于WFST或神经网络的热词定制化方案,模型允许用户在识别语音时预设一些已知的先验词汇,将识别结果中发音相近的词汇识别或修正为用户预期的结果。
本文介绍阿里巴巴通义实验室语音团队自研的新一代基于神经网络的热词定制化模型SeACo-Paraformer(Semantic-Augmented Contextual-Paraformer),较前一代基于CLAS的Contextual-Paraformer有着生效稳定,训练灵活,召回率更高等优势。
模型在线体验👇:https://modelscope.cn/models/iic/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/summary
学术论文👇:https://arxiv.org/pdf/2308.03266v4.pdf
运行脚本@FunASR开源仓库👇:https://github.com/alibaba-damo-academy/FunASR/blob/main/examples/industrial_data_pretraining/seaco_paraformer/demo.py
支持我们🌟:https://github.com/alibaba-damo-academy/FunASR/stargazers
WFST热词定制化
在去年11月份上新的FunASR离线文件转写软件包3.0迭代中,我们分享了基于WFST的热词激励技术,通过AC自动机结构进行热词网络构图,采用对解码过程中弧上权重的过程渐进激励(incremental bias)与整词激励(word bias),FunASR离线文件转写软件包支持用户指定热词并设置热词权重。
WFST热词激励方案从解码过程入手,召回稳定,但是需要在ASR模型推理之外进行基于N-gram的解码,并且对于一些训练数据中出现较少的词,ASR模型提供的后验概率过低,导致候选路径中没有包含待激励的词,此时基于WFST的热词增强大概率失效。
NN热词定制化–CLAS
如何能够利用神经网络的建模与拟合能力,将用户自定义的热词纳入端到端语音识别模型的解码过程中,输出热词定制化的识别结果是ASR领域多年来备受关注的问题之一。
在2018年,Google提出了Contextual Listen, Attend and Spell (CLAS)框架,在LAS这一经典的E2E ASR模型中进行了基于神经网络的热词定制化。CLAS主要通过两个核心思想进行热词建模:
1.在训练阶段从label中随机采样文本片段模拟热词;
2.在decoder的建模中引入额外的attention以建立文本隐状态与热词embedding的注意力连接;
后续大量的工作证明了CLAS方案的有效性,在近几年出现了CPP-Network,NAM,Col-Dec CIF,Contextual RNN-T等等基于不同ASR基础框架的热词定制化工作,其算法核心均与上述两点一致。
在对通义实验室自研的非自回归端到端语音识别模型Paraformer进行NN热词定制化支持时,我们首先采用了结合CLAS算法的方案,开源了工业级Contextual-Paraformer模型,有很强的热词召回能力,受到开发者的关注与欢迎,Modelscope下载量490万余次。
SeACo-Paraformer
在Contextual-Paraformer开源一年之后,我们进一步开源新一代的NN热词定制化模型SeACo-Paraformer,旨在解决随机初始化CLAS模型生效不稳定的问题,同时进一步提升热词召回率。
SeACo-Paraformer在Paraformer的encoder-predictor-decoder框架中引入了用于热词建模的bias decoder,通过与感知热词位置的label计算loss进行显式的热词预测训练,在解码阶段将热词后验概率与原始ASR后验概率进行加权融合,实现了更加稳定的热词召回。
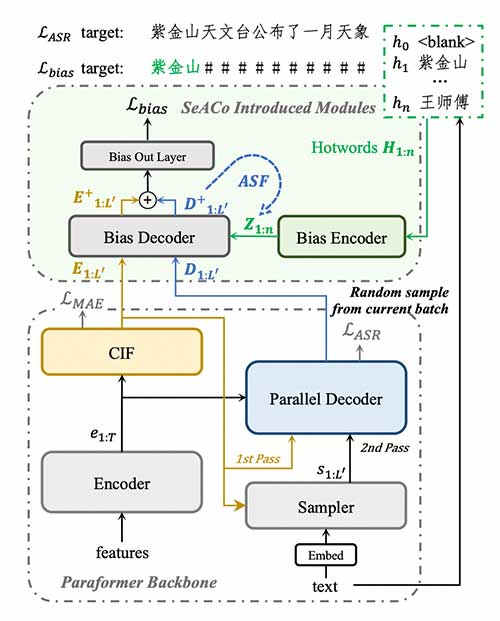

NN热词方案对decoder状态与热词embedding进行attention计算以捕捉相关性,在热词数量上升时attention会由于稀疏问题导致注意力分散,SeACo-Paraformer利用了bias decoder中深层attention的score进行了注意力预计算与筛选(Attention Score Filtering,ASF),实验表明ASF能够缓解热词数量增加导致的召回性能损失。
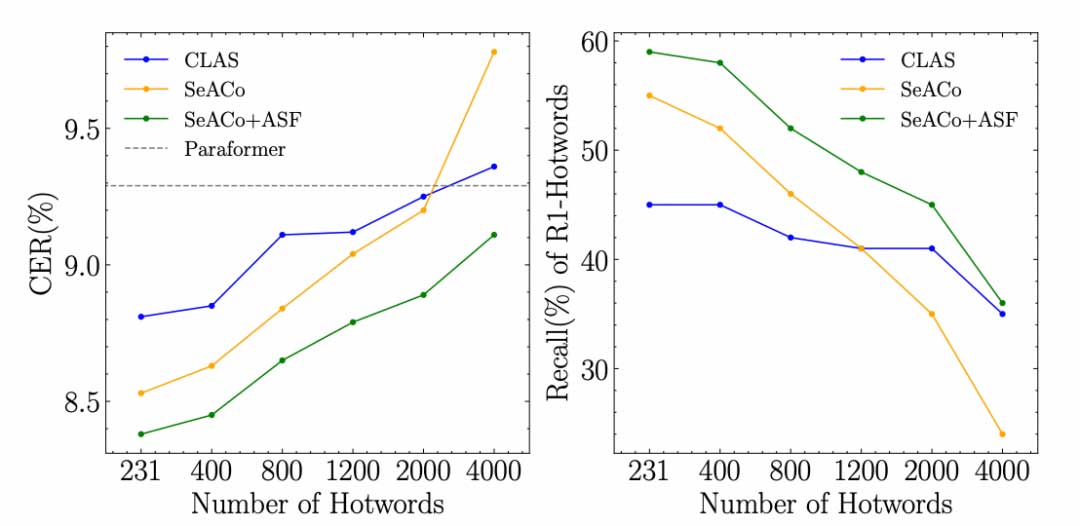
在阿里巴巴内部热词测试集与基于Aishell-1-NER构建的热词测试集上,我们开源的SeACo-Paraformer获得了较Contextual-Paraformer更优的识别与召回能力。同时我们也开源了Aishell-1-NER热词测试集用于研究者与开发者公平对比各种模型的热词召回能力。
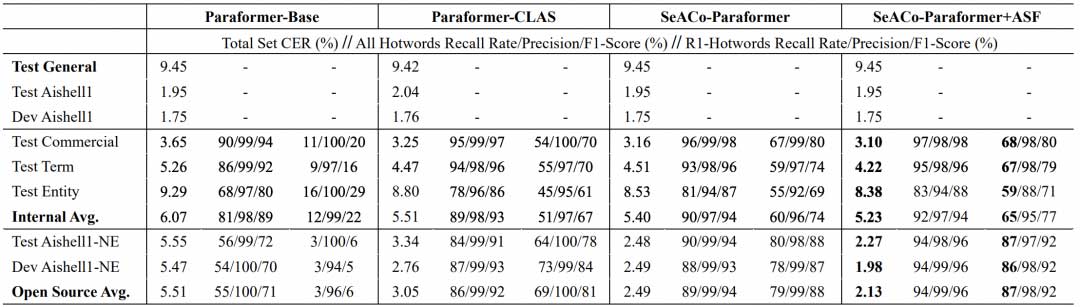
上表展示了在内部测试集与开源测试集上Paraformer基础模型以及三种热词模型的热词激励效果。以开源测试集为例,Paraformer-CLAS模型将低档位(在通用ASR识别中召回率低于40%)热词召回率从3%提升至69%,SeACo-Paraformer将这一指标进一步提升至79%,最后在ASF的加持下,召回率提升至87%(较Paraformer-CLAS相对提升26%)。
极速体验
上述介绍的多个模型:Paraformer-Large,Contextual-Paraformer与SeACo-Paraformer均已在Modelscope社区完全开源,它们使用了上万小时的阿里巴巴内部工业数据训练,其中SeACo-Paraformer同时支持时间戳预测、热词定制化与说话人预测多种功能,上线近两个月累积下载量40w余次。通过如下简单的代码即可完成ASR推理,以SeACo-Paraformer为例:
from funasr import AutoModel
model = AutoModel(model="paraformer-zh", # seaco-paraformer的绑定名
vad_model="fsmn-vad", # 支持长音频输入
punc_model="ct-punc", # 进行标点恢复
spk_model="cam++" # 支持说话人识别
)
res = model.generate(input="your_speech.wav",
hotword='通义实验室 魔搭') # 配置热词
print(res)更多ASR相关前沿技术与工业模型在FunASR社区,通过FunASR工具包进行快速的推理、微调:https://github.com/alibaba-damo-academy/FunASR
参考文献:
[1]Shi Xian, Yexin Yang, Zerui Li, Zhifu Gao and Shiliang Zhang. “SeACo-Paraformer: A Non-Autoregressive ASR System with Flexible and Effective Hotword Customization Ability.” ICASSP 2024.
[2]Gao Zhifu, Zerui Li, Jiaming Wang, Haoneng Luo, Xian Shi, Mengzhe Chen, Yabin Li et al. “Funasr: A fundamental end-to-end speech recognition toolkit.” INTERSPEECH 2023.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。