
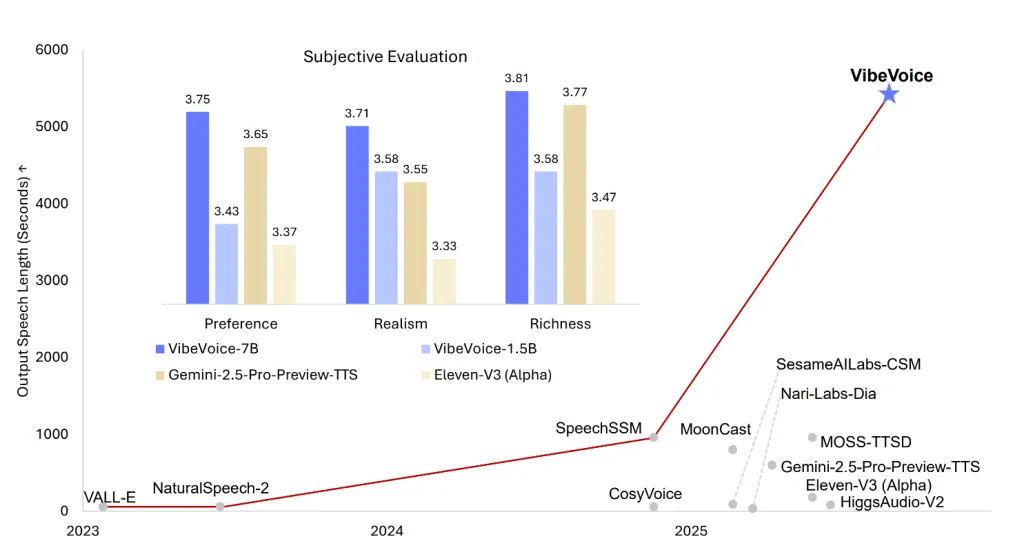
微软最新开源版本 VibeVoice-1.5B 重新定义了文本转语音 (TTS) 技术的边界。提供富有表现力、长篇幅、多说话人生成的音频,该音频获得麻省理工学院 (MIT) 许可,可扩展且高度灵活,可用于研究。该模型不仅仅是一个 TTS 引擎;它是一个框架,旨在生成长达 90 分钟的不间断、自然的音频,支持同时生成多达四个不同的说话人的声音,甚至能够处理跨语言和歌唱合成场景。VibeVoice-1.5B 采用流式架构,并在不久的将来推出更强大的 7B 模型,它将自己定位为人工智能对话音频、播客和合成语音研究的重大进步。
主要特点
- 海量语境和多说话人支持:VibeVoice-1.5B 可以在一次会话中合成最多90 分钟的语音,最多有四个不同的说话人,远远超过了传统 TTS 模型通常 1-2 个说话人的限制。
- 同时生成:该模型不仅仅是将单个声音片段拼接在一起;它旨在支持多个说话者的并行音频流,模仿自然对话和轮流发言。
- 跨语言和歌唱合成:虽然该模型主要针对英语和中文进行训练,但它能够进行跨语言合成,甚至可以生成歌唱 – 这是以前的开源 TTS 模型中很少展示的功能。
- MIT 许可证:完全开源且商业友好,专注于研究、透明度和可重复性。
- 可扩展至流媒体和长格式音频:该架构专为高效的长时间合成而设计,并预计即将推出7B 流媒体模型,进一步扩展实时和高保真 TTS 的可能性。
- 情感和表现力:该模型因其情感控制和自然表现力而受到推崇,使其适用于播客或对话场景等应用。

架构和技术深度探究
VibeVoice 的基础是一个1.5B 参数的 LLM(Qwen2.5-1.5B),它集成了两个新颖的标记器——声学和语义,两者均设计为以低帧速率(7.5Hz)运行,以实现长序列的计算效率和一致性。
- 声学标记器:一种具有镜像编码器-解码器结构(每个约 340M 个参数)的 σ-VAE 变体,可实现24kHz 原始音频的3200 倍下采样。
- 语义标记器:通过 ASR 代理任务进行训练,该仅编码器架构反映了声学标记器的设计(减去 VAE 组件)。
- 扩散解码器头:轻量级(~123M 参数)条件扩散模块可预测声学特征,利用无分类器引导 (CFG) 和 DPM 求解器来获得感知质量。
- 上下文长度课程:训练从 4k 个标记开始,扩展到65k 个标记– 使模型能够生成非常长、连贯的音频片段。
- 序列建模:LLM 了解对话流程中的轮流,而扩散头则生成细粒度的声学细节 – 分离语义和合成,同时长时间保留说话者的身份。
模型限制和负责任的使用
- 仅限英语和中文:该模型仅针对这些语言进行训练;其他语言可能会产生难以理解或令人反感的输出。
- 无重叠语音:虽然支持轮流说话,但 VibeVoice-1.5B 并不模拟说话者之间的重叠语音。
- 仅语音:该模型不生成背景声音、拟音或音乐——音频输出严格来说是语音。
- 法律和道德风险:微软明确禁止将其用于语音模仿、虚假信息或身份验证绕过。用户必须遵守法律并披露 AI 生成的内容。
- 不适用于专业实时应用程序:虽然高效,但此版本并未针对低延迟、交互式或实时流媒体场景进行优化;这是即将推出的 7B 版本的目标。
结论
微软的VibeVoice-1.5B是开放式 TTS 领域的一项突破:可扩展、富有表现力且支持多说话人,其轻量级的基于扩散的架构为研究人员和开源开发者带来了长篇对话音频合成的可能。虽然目前的应用主要集中在研究领域,且仅限于英语/中文,但该模型的功能以及即将推出的版本的前景,预示着 AI 生成合成语音和与合成语音交互方式的范式转变。
对于技术团队、内容创作者和 AI 爱好者来说,VibeVoice-1.5B是下一代合成语音应用的必备工具——现已在 Hugging Face 和 GitHub 上发布,并拥有清晰的文档和开放许可证。随着该领域转向更具表现力、互动性和道德透明性的 TTS,微软的最新产品将成为开源 AI 语音合成领域的里程碑。
常见问题解答
VibeVoice-1.5B 与其他文本转语音模型有何不同?
VibeVoice-1.5B 可生成长达 90 分钟的富有表现力的多扬声器音频 (最多四个扬声器),支持跨语言和歌唱合成,并且根据 MIT 许可证完全开源,突破了长篇对话 AI 音频生成的界限
建议使用什么硬件来在本地运行模型?
社区测试表明,使用 1.5 B 检查点生成多说话人对话会消耗 ≈ 7 GB 的 GPU VRAM,因此 8 GB 的消费级卡(例如 RTX 3060)通常足以进行推理。
该模型目前支持哪些语言和音频风格?
VibeVoice-1.5B 仅针对英语和中文进行训练 ,可以进行跨语言叙述 (例如,英语提示→中文语音)以及基本的歌唱合成。它仅产生语音,没有背景声音,并且不模拟重叠的说话者;话轮转换是连续的。
参考资料:
https://github.com/microsoft/VibeVoice/blob/main/report/TechnicalReport.pdf
https://huggingface.co/microsoft/VibeVoice-1.5B
https://github.com/microsoft/VibeVoice
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/61050.html