
Transformer 模型显著影响了 AI 系统处理自然语言理解、翻译和推理任务的方式。这些大型模型,尤其是大型语言模型 (LLM),在规模和复杂度上不断增长,如今已涵盖了各个领域的广泛功能。然而,将这些模型应用于新的专业任务仍然是一项复杂的操作。每个新应用通常都需要精心选择数据集、进行数小时的微调,并具备强大的计算能力。尽管这些模型提供了坚实的知识基础,但它们在处理数据量极小的新领域时仍显得僵化,这仍然是一个核心限制。随着研究人员致力于使 AI 更接近人类的适应性,研究重点已转向更高效的方法,使此类模型无需重新训练每个参数即可调整其行为。
定制 LLM 以适应新任务的挑战
核心难点在于如何将基础模型适配到独特的应用场景中,而无需重复成本高昂且耗时的训练周期。目前大多数解决方案依赖于为每项任务创建新的适配器,这些适配器是经过训练以控制模型行为的独立组件。这些适配器必须为每个任务从头开始构建,并且从一个应用场景中汲取的经验教训通常无法迁移到另一个应用场景。这种适配过程耗时且缺乏可扩展性。此外,针对特定数据集调整模型通常需要对超参数选择具有极高的精度,而如果配置不当,则会导致结果不佳。即使适配成功,结果也往往是一堆孤立的、特定于任务的组件,难以集成或重用。
为了应对这些限制,研究人员采用了低秩自适应 (LoRA) 技术,该技术仅修改一小部分参数而非整个模型。LoRA 将低秩矩阵注入冻结的 LLM 的特定层,从而允许基本权重保持不变,同时实现特定于任务的自定义。此方法减少了可训练参数的数量。但是,对于每个任务,仍然需要从头开始训练一个新的 LoRA 适配器。虽然比完全微调更高效,但这种方法无法实现快速的动态自适应。最近的进展尝试进一步压缩这些适配器或在推理过程中组合多个适配器;然而,它们仍然严重依赖于先前的训练,并且无法动态生成新的适配器。
引入文本到 LoRA:根据任务描述即时生成适配器
Sakana AI 的研究人员推出了Text-to-LoRA (T2L) 技术,旨在根据目标任务的文本描述即时生成特定任务的 LoRA 适配器,而无需为每个任务创建和训练新的适配器。T2L 充当超网络,能够在单次前向传递中输出适配器权重。它从涵盖 GSM8K、Arc-challenge、BoolQ 等各个领域的现有 LoRA 适配器库中学习。训练完成后,T2L 可以解读任务描述并生成所需的适配器,而无需额外训练。此功能不仅消除了手动生成适配器的需要,还使系统能够推广到以前从未遇到过的任务。
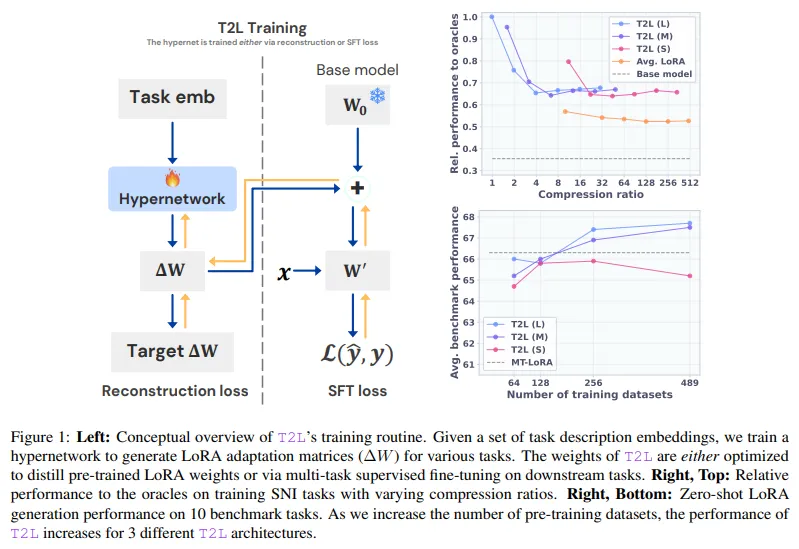

T2L 架构结合使用特定于模块和特定于层的嵌入来指导生成过程。测试了三种架构变体:一个包含 5500 万个参数的大型版本,一个包含 3400 万个参数的中型版本,以及一个仅包含 500 万个参数的小型版本。尽管规模各有不同,但所有模型都能够生成适配器功能所需的低秩矩阵。训练使用了超级自然指令数据集,涵盖 479 个任务,每个任务都以自然语言描述并编码为向量形式。通过将这些描述与学习到的层和模块嵌入相结合,T2L 创建了适配器功能所需的低秩 A 矩阵和 B 矩阵。这使得一个模型能够取代数百个手工制作的 LoRA,从而以更小的计算占用空间产生一致的结果。
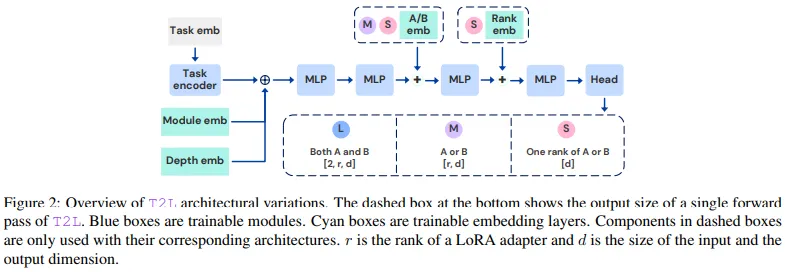
T2L 的基准性能和可扩展性
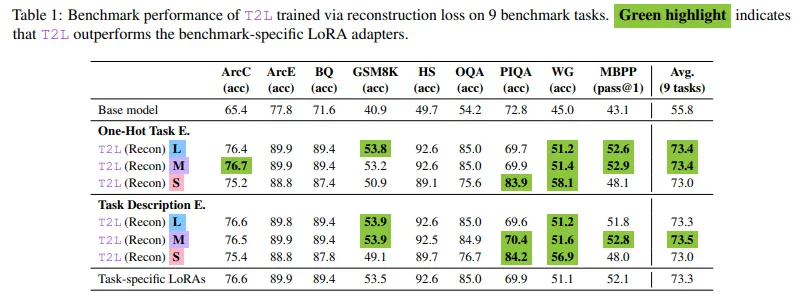
在 Arc-easy 和 GSM8K 等基准测试中,T2L 的性能与特定任务的 LoRA 相当甚至超越。例如,使用 T2L 在 Arc-easy 上的准确率为 76.6%,与最佳手动调整适配器的准确率相当。在 BoolQ 上,其准确率达到了 89.9%,略高于原始适配器。即使在 PIQA 和 Winogrande 等难度更高的基准测试中(过拟合通常会损害性能),T2L 也比手动训练的适配器取得了更好的结果。这些改进被认为源于超网络训练中固有的有损压缩,它充当了一种正则化形式。当训练数据集的数量从 16 个增加到 479 个时,零样本设置下的性能显著提升,这表明 T2L 能够在训练过程中通过更广泛的接触进行泛化。
该研究的几个关键要点包括:
- T2L 允许仅使用自然语言描述来即时调整 LLM。
- 它支持对训练期间未见过的任务进行零样本泛化。
- 测试了 T2L 的三种架构变体,参数数量分别为 55M、34M 和 5M。
- 基准包括 ArcE、BoolQ、GSM8K、Hellaswag、PIQA、MBPP 等。
- T2L 实现了 76.6%(ArcE)、89.9%(BoolQ)和 92.6%(Hellaswag)的基准准确率。
- 它在多项任务上的表现与手动训练的 LoRA 相当甚至超过了后者。
- 使用来自超自然指令数据集的 479 个任务进行训练。
- T2L 使用 gte-large-en-v1.5 模型来生成任务嵌入。
- T2L 生成的 LoRA 适配器仅针对注意力块中的查询和值投影,总共 3.4M 个参数。
- 即使重建损失较大,性能仍保持一致,显示出对压缩的弹性。
总而言之,这项研究凸显了在灵活高效的模型适配方面迈出的一大步。T2L 不再依赖重复且耗费资源的程序,而是利用自然语言本身作为控制机制,使模型能够使用简单的任务描述进行专业化。这一能力显著减少了将 LLM 适配到新领域所需的时间和成本。此外,它表明,只要有足够多的先前适配器可用于训练,未来的模型就有可能在几秒钟内适应任何用简单英语描述的任务。使用超网络动态构建适配器也意味着模型专业化所需的存储空间更少,从而进一步提高了该方法在生产环境中的实用性。
论文地址:https://arxiv.org/abs/2506.06105
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/58858.html