
NVIDIA 近日发布了其全新的英语实时转录模型(Nemotron Speech ASR),该模型专为低延迟语音助手和实时字幕生成而设计。Hugging Face平台上的测试版本 nvidia/nemotron-speech-streaming-en-0.6b 结合了具备缓存意识的 FastConformer 编码器与 RNNT 解码器,并针对现代 NVIDIA GPU 上的流式处理和批处理工作负载进行了优化调优。
模型设计、架构和输入假设
Nemotron Speech ASR(自动语音识别)是一个参数量为 6 亿的模型,它基于一个具有缓存感知功能的 24 层 FastConformer 编码器和一个 RNNT 解码器。该编码器采用激进的 8 倍卷积下采样来减少时间步数,从而直接降低流式工作负载的计算和内存成本。该模型使用 16 kHz 单声道音频,并且每个音频块至少需要 80 毫秒的输入音频。
运行时延迟通过可配置的上下文大小进行控制。该模型提供 4 种标准块配置,分别对应约 80 毫秒、160 毫秒、560 毫秒和 1.12 秒的音频。这些模式由一个att_context_size参数驱动,该参数以 80 毫秒帧的倍数设置左右注意力上下文,并且可以在推理时更改,无需重新训练。
缓存感知流式处理,而非缓冲滑动窗口
传统的“流式自动语音识别”通常使用重叠窗口。每个传入窗口都会重新处理之前音频的一部分以保持上下文,这会浪费计算资源,并导致延迟随着并发量的增加而上升。
Nemotron Speech ASR 则为所有自注意力层和卷积层维护一个编码器状态缓存。每个新数据块只处理一次,模型会重用缓存的激活值,而不是重新计算重叠的上下文。这带来了以下结果:
- 由于帧处理不重叠,因此工作量与音频长度呈线性关系。
- 内存增长可预测,因为缓存大小随序列长度增长,而不是随并发相关的重复代码增长。
- 在高负载下保持稳定的延迟,这对于语音代理的轮流和中断至关重要。
准确率与延迟:流式处理约束下的词错误率
Nemotron Speech ASR在Hugging Face OpenASR排行榜数据集上进行评估,包括AMI、Earnings22、Gigaspeech和LibriSpeech。准确率以不同分块大小下的词错误率(WER)形式呈现。
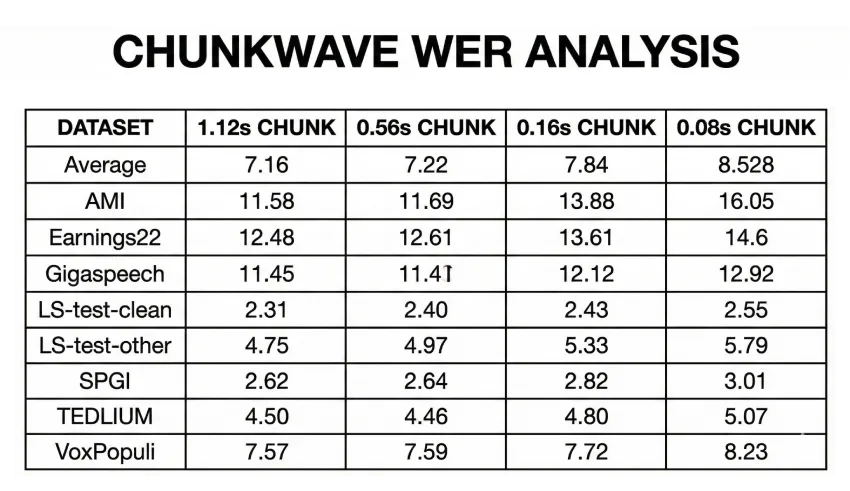

综合以上各项指标,该模型平均达到以下目标:
- 在 0.16 秒的数据块大小下,WER 约为 7.84%。
- 在 0.56 秒的数据块大小下,WER 约为 7.22%。
- 在 1.12 秒的数据块大小下,WER 约为 7.16%。
这说明了延迟与准确性之间的权衡。较大的数据块可以提供更多的语音上下文信息,并略微降低词错误率 (WER),但即使是 0.16 秒的模式也能将 WER 控制在 8% 以下,同时仍然适用于实时语音代理。开发者可以根据应用需求选择推理时的操作点,例如,对于需要快速响应的语音代理,可以选择 160 毫秒;对于以转录为中心的工作流程,可以选择 560 毫秒。
现代GPU的吞吐量和并发性
缓存感知设计对并发性有显著提升。在 NVIDIA H100 GPU 上,Nemotron Speech ASR 在 320 毫秒的数据块大小下支持约 560 个并发流,大约是相同延迟目标下基准流媒体系统并发性的 3 倍。RTX A5000 和 DGX B200 的基准测试也显示出类似的吞吐量提升,在典型延迟设置下,A5000 的并发性提升超过 5 倍,B200 的并发性提升高达 2 倍。
同样重要的是,随着并发量的增加,延迟保持稳定。在 Modal 的测试中,当 127 个 WebSocket 客户端并发且延迟设置为 560 毫秒时,系统将端到端延迟中位数维持在 182 毫秒左右,没有出现漂移,这对于需要在数分钟会话中与实时语音保持同步的智能体至关重要。
训练数据和生态系统整合
Nemotron Speech ASR 主要基于 NVIDIA Granary 数据集的英语部分进行训练,并结合了大量公共语音语料库,总音频时长约为 28.5 万小时。这些数据集包括 YouTube Commons、YODAS2、Mosel、LibriLight、Fisher、Switchboard、WSJ、VCTK、VoxPopuli 以及多个 Mozilla Common Voice 版本。标签结合了人工标注和 ASR 生成的转录文本。
要点总结
- Nemotron Speech ASR 是一个 0.6B 参数的英语流模型,它使用缓存感知的 FastConformer 编码器和 RNNT 解码器,并处理 16 kHz 单声道音频,输入块至少为 80 毫秒。
- 该模型提供了 4 种推理时间块配置,分别为约 80 毫秒、160 毫秒、560 毫秒和 1.12 秒,这使得工程师可以在不重新训练的情况下,以延迟换取准确性,同时在标准 ASR 基准测试中将 WER 保持在 7.2% 到 7.8% 左右。
- 缓存感知流式传输消除了重叠窗口的重新计算,因此每个音频帧只编码一次,与类似延迟的缓冲流式传输基线相比,在 H100 上可实现约 3 倍的并发流,在 RTX A5000 上可实现 5 倍以上,在 DGX B200 上可实现高达 2 倍。
- 在采用 Nemotron Speech ASR、Nemotron 3 Nano 30B 和 Magpie TTS 的端到端语音代理中,测得的最终转录中位数时间约为 24 毫秒,而 RTX 5090 上的服务器端语音到语音延迟约为 500 毫秒,这使得 ASR 仅占总延迟预算的一小部分。
- Nemotron Speech ASR 以 NeMo 检查点的形式,根据 NVIDIA 宽松开放模型许可发布,其中包含开放的权重和训练细节,因此团队可以自行托管、微调和分析整个堆栈,以实现低延迟语音代理和语音应用程序。
更多详细信息,请访问https://huggingface.co/nvidia/nemotron-speech-streaming-en-0.6b
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/64152.html