
沉浸式远程全息交互旨在通过高保真的全身全息表现,彻底改变AR/VR应用中的人类交互体验。然而,现有的系统往往依赖昂贵的多摄像头设置,且对传输带宽要求极高,极大地限制了其在移动设备上的实时表现。本期将介绍我们提出的Mon3tr,这是一种创新的单目3D远程交互框架,它首次将3D高斯泼溅(3DGS)与摊销计算思想结合,实现了仅需普通单目摄像头和极低带宽即可驱动的高保真全息交互。
论文题目:《Mon3tr:基于预构建高斯头像摊销计算的单目3D远程全息交互系统》
论文链接:https://arxiv.org/abs/2601.07518
论文主页:https://mon3tr3d.github.io
团队主页:https://eejzhang.people.ust.hk/
01 昂贵硬件与高额带宽能否被“摊销”?
在AR/VR全息通话中,为了获取逼真的3D人体表现,现有主流方案往往依赖昂贵的多相机阵列,且由于传输的是原始点云或网格数据,动辄消耗上百Mbps的带宽,导致移动设备难以实时运行且极度依赖高质量网络环境。
为了解决这一痛点,我们提出了Mon3tr框架。我们的动机核心源于摊销计算(Amortized Computation)的思想:将沉重的3D重建计算负载放在离线阶段完成,而在实时通话时仅处理轻量化的语义驱动。
具体而言,我们构建了一个完整的端到端3D远程呈现Pipeline,如图1所示。在离线阶段,我们通过短视频为用户重建一个可驱动的3D高斯头像(3DGS Avatar);在实时在线阶段,发送端只需一个普通单目摄像头,通过我们设计的SPMM3人体参数化模型提取极精简的语义运动参数,并利用WebRTC数据通道以低于0.2 Mbps的极低带宽传输。接收端通过高效的神经变形网络,将这些参数重新映射回高保真的高斯头像,从而在保持低成本、低带宽的前提下,实现了电影级的全息交互体验。
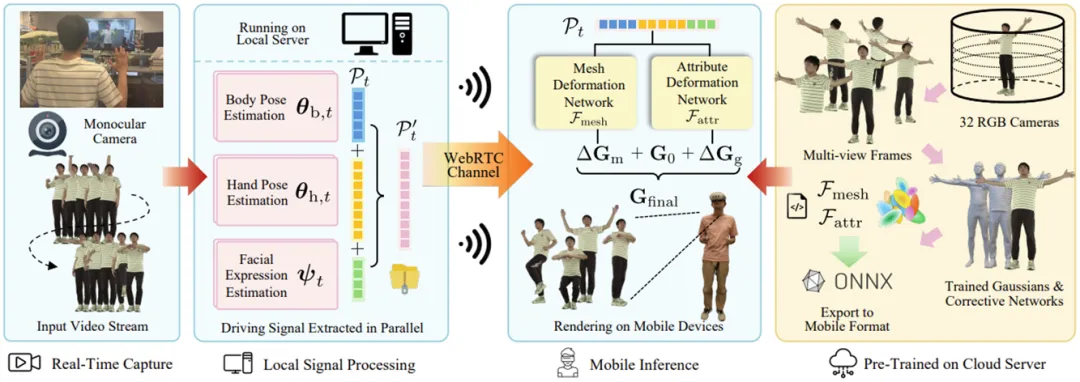

02 SPMM3参数化建模与高效的双变形网络
2.1 高保真参数化模板 SPMM3
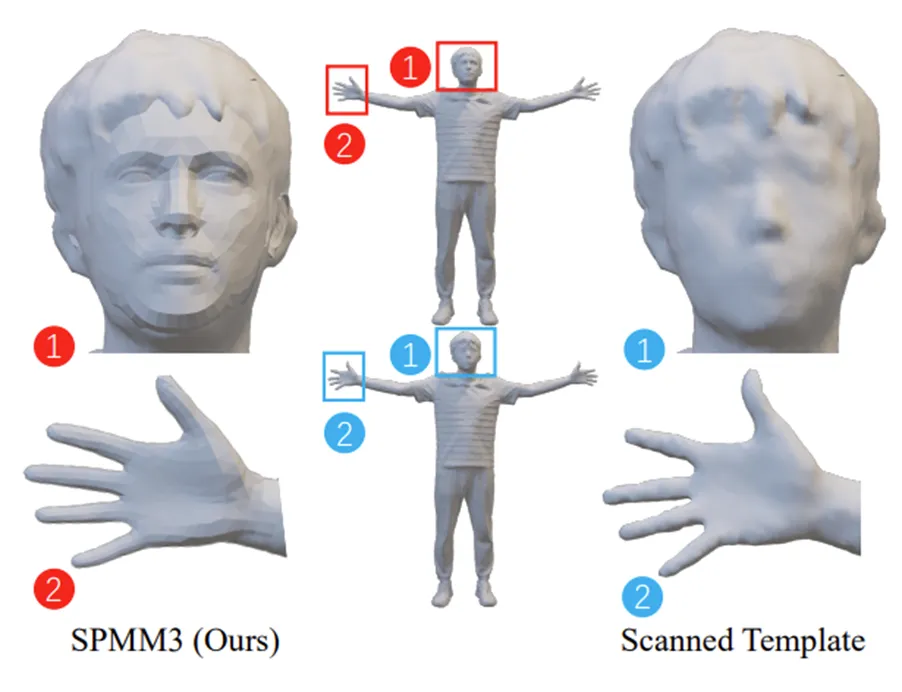
我们提出了人体参数化模型SPMM3(Skinned Person Model for Mon3tr),这是我们系统的核心拓扑基础,如图2所示。不同于传统的SMPL-X模型在处理松散衣物或复杂发型时的局限,SPMM3将高质量的人体基础网格与专业的FLAME面部模型和MANO手部模型进行了精细的模块化融合。通过构建一个包含了衣服、头发等非刚性部件的、最贴近原本人体形状的网格模版,我们得到了一个既具备语义表现力(手势、表情)又能呈现复杂几何细节的可驱动人体模型。其公式表达如下:
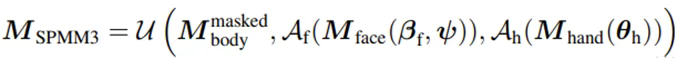
2.2 网格变形网络与高斯变形网络
为了实现动态的真实感,系统部署了两个轻量化网络,如图3所示。
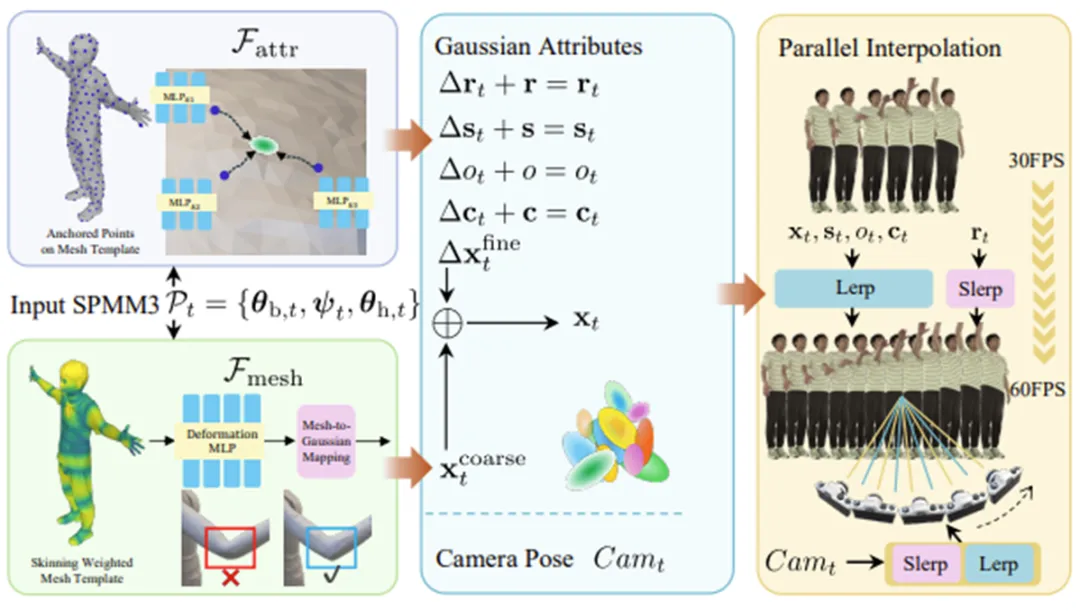
网格变形网络(Fmesh):为了学习非刚性变形(如衣服褶皱),我们设计了网格变形网络(Mesh Deformation Network),该网络通过提取的语义特征预测每个顶点的修正偏移量。通过这种方式,我们能够修正粗略骨架驱动(LBS)带来的网格畸变,确保衣服褶皱随动作自然演变。最终变形后的网格可以由如下公式表示:
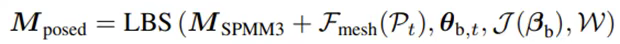
该网络的训练通过如下损失函数监督:
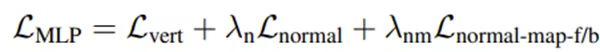
属性变形网络(Fattr):这是提升真实感的核心创新。我们引入了属性变形网络(Attribute Deformation Network),通过预测“拖拽力”(Dragging Forces)来动态调整高斯粒子的属性。对于第i个高斯粒子,其在t时刻的属性(如颜色、透明度、缩放)由其初始属性叠加一个偏移量得到:
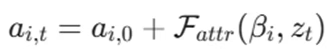
该网络并不直接预测颜色,而是学习粒子在运动过程中的属性偏移,从而模拟出逼真的光影流转和材料质感。
我们通过一个多层面的损失函数加规范化项来约束训练:
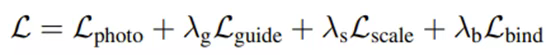
2.3 层级位置动力学
为了解决大尺度运动下的高斯粒子飞散问题,我们采用层级化公式定义粒子的最终位置:
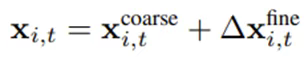
其中,第一项由SPMM3模板的粗略网格运动通过重心坐标插值决定,保证了运动的大致准确性。第二项是由属性变形网络预测的精细位置残差。这种层级设计确保了粒子始终紧密依附于人体表面,同时能捕捉到如衣服滑动、肌肉震颤等极其细微的物理交互细节。
03 实验结果:打破带宽瓶颈,定义移动端新标准
由于以后4D人物数据集都缺少丰富的表情变化,所以我们引入了自主收集的iCom4D数据集对系统进行了全方位测评。该数据集包含由32个同步相机捕获的高清动作序列,涵盖了丰富的肢体语言和细腻的面部表情。
在系统实现方面,Mon3tr充分考虑了消费级硬件的适配性。我们的发送端基于一台搭载NVIDIA RTX 5090 D显卡的PC,通过Intel RealSense相机捕获单目 RGB 视频流。为了实现极致的传输效率,我们将提取的身体姿态、表情及手势参数通过FP16量化和轻量级的LZ4算法进行压缩。接收端则选用Meta Quest 3独立头显,利用其Snapdragon XR2 Gen 2处理器的强劲性能,并通过ONNX Runtime优化后的静态计算图实现全流程硬件加速。
在通信链路层,我们采用WebRTC协议建立可靠的数据通道。为了模拟真实的移动网络环境,我们部署了搭载ImmortalWrt固件的路由器,并利用Linux tc工具对带宽进行动态控制(如模拟带宽波动),从而严谨地验证系统在各种网络条件下的鲁棒性。
为了全面评估性能,我们对比了一系列Baseline:
- 系统级对比:包括商业级闭源系统MagicStream(语义通信标杆)、TeleAloha(高authentic表现力标杆)以及开源系统MonoPort。
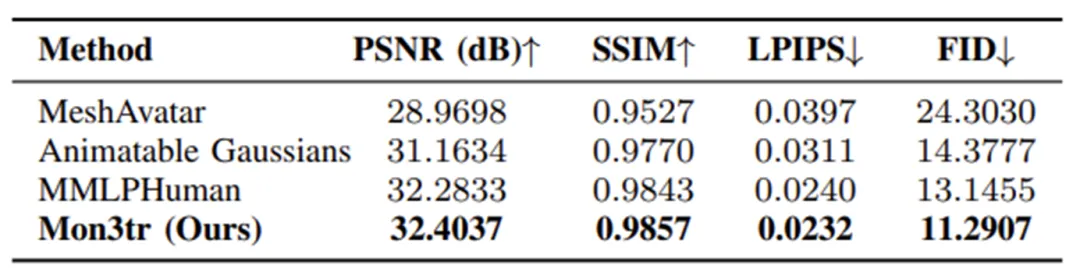
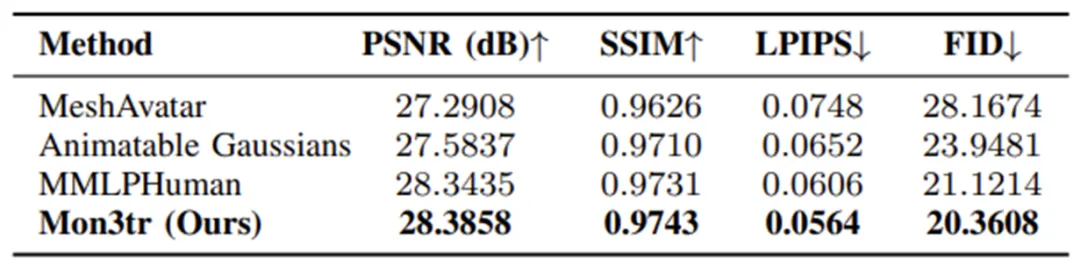
- 算法级对比:与目前最先进的动态人体建模算法Animatable Gaussians、MMLPHuman和MeshAvatar进行了基于同等实验条件的严格对标。
实验的基本系统设置对比如表1所示:

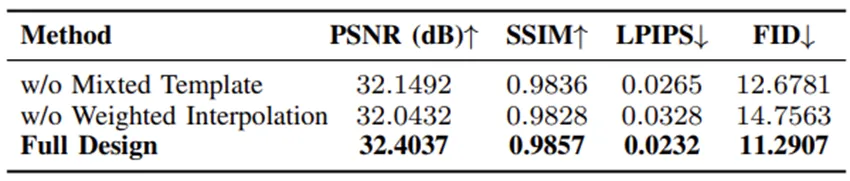
画质超越SOTA:定量评估显示,Mon3tr在处理未见过的复杂姿态时,其渲染画质(PSNR)超过了28.38 dB,在SSIM、LPIPS和FID等关键指标上全面超越了MeshAvatar和Animatable Gaussians等现有最先进模型。这证明了我们的混合拓扑与属性修正机制能够极其精准地重构人体细节。
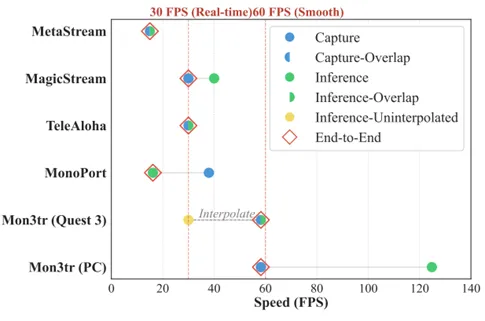
极低延迟与高帧率:在Meta Quest 3移动端,通过将计算任务卸载到NPU执行,我们实现了约60 FPS的稳定渲染流畅度。整个系统的端到端延迟控制在73.1毫秒左右,远低于沉浸式交互所需的100毫秒阈值。
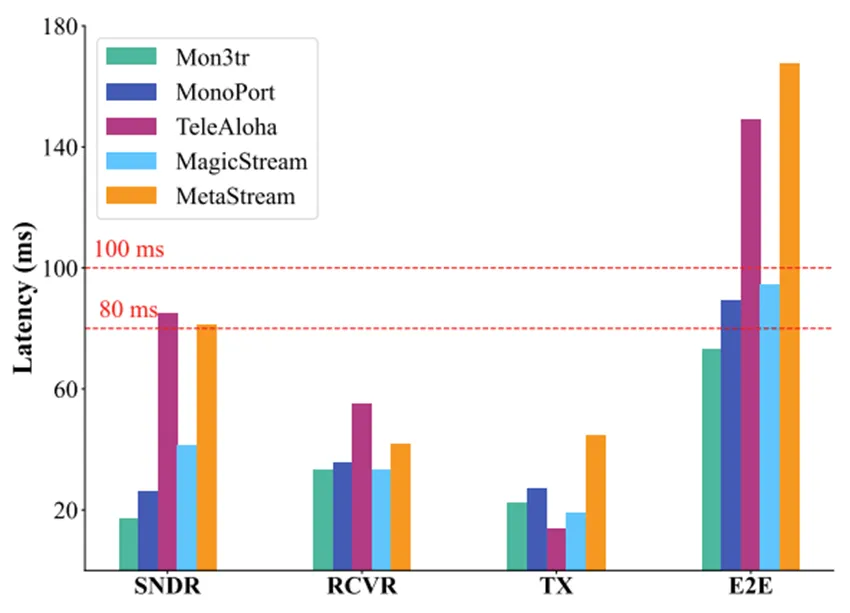
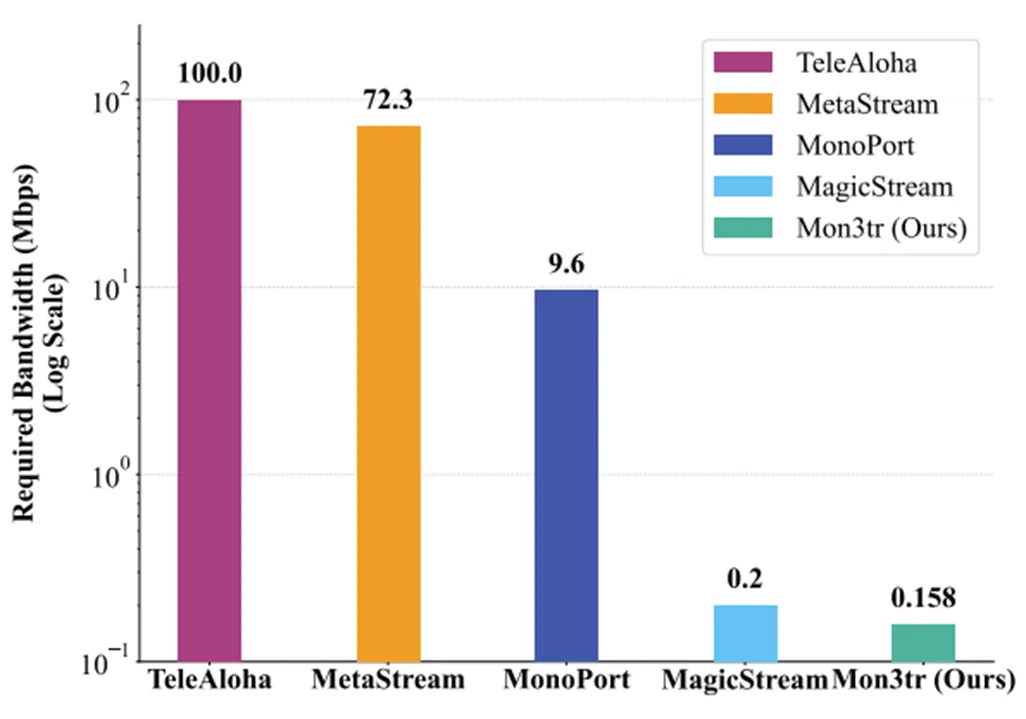
带宽压缩的新纪录:相比于TeleAloha等需要100 Mbps的传统流式系统,Mon3tr仅需0.158 Mbps即可维持流畅通话。这意味着在普通的公共WiFi甚至是4G/5G移动网络下,用户都能享受到丝滑的3D全息体验,而无需担心网络拥塞导致的画质崩溃。
04 总结: 全息通话的未来属于每一台消费级设备
通过Mon3tr,我们成功证明了“计算换带宽”在全息交互领域的可行性。我们提出的摊销计算范式彻底打破了高保真3D通讯对昂贵硬件和专线网络的依赖。
方案优势:我们的系统仅需约73美元的硬件成本(一个单目相机)和3.9 GB的显存占用,便能在普通PC或移动VR头显上跑出电影级的全息效果。这种极致的兼容性与效率,解决了全息技术难以商业化落地的痛点。
应用场景:Mon3tr的轻量化特性使其在沉浸式远程办公、跨地域远程教育、虚拟医疗问诊以及元宇宙社交等领域具有巨大的应用价值。未来,我们将进一步探索基于单张照片快速生成高保真头像的技术,真正实现“扫一扫即可开启3D对话”的美好愿景。
05 参考文献
[1]Z. Li, Z. Zheng, L. Wang, and Y. Liu, “Animatable gaussians: Learning pose-dependent gaussian maps for high-fidelity human avatar modeling,“in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 711–19 722.
[2]R. Abdrashitov, K. Raichstat, J. Monsen, and D. Hill, “Robust skin weights transfer via weight inpainting,” in SIGGRAPH Asia 2023 Technical Communications, 2023, pp. 1–4.
[3]B. Kerbl, G. Kopanas, T. Leimkuhler, and G. Drettakis, “3d gaussian ¨ splatting for real-time radiance field rendering,” ACM Transactions on Graphics, vol. 42, no. 4, July 2023. [Online]. Available: https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/.
作者:LIN, Fangyu
编辑:ZHANG, Yumeng
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。