
文章来源于:听觉认知与计算声学实验室
作者:AudioCC Lab
一、引言
2021年以来,随着扩散模型(Diffusion Models)的兴起与普及,视觉内容生成领域迎来了迅猛发展。从 Midjourney 生成的获奖画作,到 Sora、Veo3 制作的高质量视频,生成式 AI 正以显著加速的步伐持续拓展创作的边界。
在这一背景下,音频驱动虚拟人(Audio-Driven Talking Avatar)合成作为一个重要的垂直研究方向,正逐渐受到学术界与工业界的广泛关注。这项技术的核心目标是:给定一张静态参考人像与一段驱动音频,生成一段口型、表情乃至肢体动作均与音频精准同步的视频,同时高度还原参考图像中人物的外貌特征。
这在数字人直播、智能客服、影视特效、教育内容制作等领域具有极高的商业价值。本期 Paper Corner 将从技术原理出发,系统梳理该领域的发展脉络,并重点解析三篇近年最具代表性的工作:Hallo2、Let Them Talk 与 OmniHuman-1。
二、任务定义
音频驱动虚拟人生成任务可以形式化描述为:
【输入】一张静态人物参考图像 + 一段驱动音频。
【输出】一段视频,满足两个核心约束:
① 音视频同步(Synchronization):口型与音频严格对齐,Phoneme 到 Viseme 的映射要准确;
② 身份保持(Identity Preservation):视频中的人物外貌与参考图像高度一致。
该任务可类比为音频领域的声音转换(Voice Conversion):在 VC 中,源音频的内容被用于驱动目标说话人的音色;而在 Talking Avatar 中,音频内容则作为驱动信号,控制参考图像中人物的”面部几何特征”。技术挑战主要体现在四个维度:身份保持、音视频同步、时序一致性(避免帧间闪烁)和自然运动(头部姿态、眼神、肢体协调)。
三、技术演进:从 3DMM 到 DiT
领域发展时间线
回顾该领域的发展历程,可以将其概括为”寻找最佳 3D 表示“与”寻找最佳生成模型“两条主线并行演进的过程。
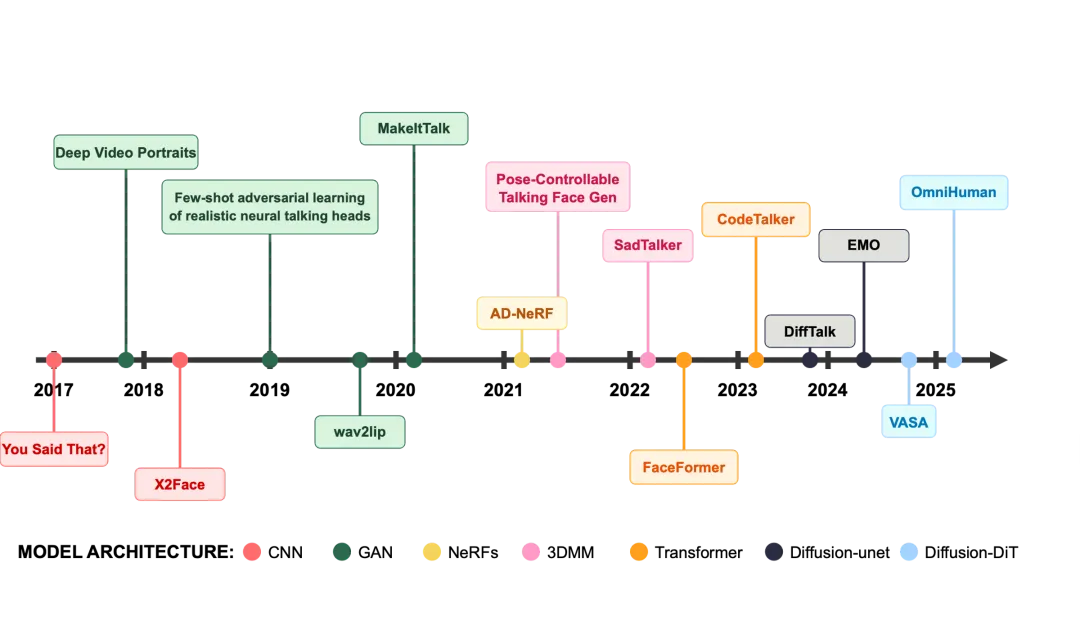

早期探索:3DMM 与 NeRF 时代
在扩散模型崛起之前,该领域主要有两大流派。
3DMM(3D Morphable Models,三维可变形模型)可类比为语音合成中的”参数化合成”方法。该方法基于海量人脸扫描数据构建,通过线性参数组合生成人脸,推理速度快,形状与纹理解耦清晰;但由于参数空间的线性假设,难以表达嘴唇微抿、皱眉等高频非线性细节,表现较为”僵硬”——这与参数化语音合成难以还原真实语音的精细变化如出一辙。代表工作包括 SadTalker(CVPR 2023)、MakeItTalk(SIGGRAPH Asia 2020)。
NeRF(Neural Radiance Fields,神经辐射场)于 2020 年提出后一度引起广泛关注。它将场景隐式编码于神经网络中,通过体绘制生成图像,具有良好的 3D 一致性。然而其主要缺陷在于训练速度极慢,且通常为人物特定(Person-specific)模型——每更换一个人物就需重新训练,泛化能力严重受限。代表工作包括 AD-NeRF(ICCV 2021)。
目前主流:Diffusion Models
从 2023 年起,扩散模型(Diffusion Models)已成为该领域的主导技术范式。EMO、VASA-1、Hallo、OmniHuman 等工作均基于扩散模型构建。其核心原因在于:研究目标已从单纯让人脸”动起来”,转变为实现 One-shot(一张图驱动)+ High-fidelity(高保真)的效果。扩散模型强大的分布拟合能力,使其成为目前唯一能同时满足这两个条件的技术路线。
四、技术基础:理解扩散模型
三大生成范式对比
在深入分析具体论文之前,有必要理解扩散模型得以超越 GAN 和 VAE、成为当前视觉生成主流架构的原因。这三种模型在数学本质上分别求解不同的问题:
- GAN(生成对抗网络):Generator 与 Discriminator 博弈竞争,生成质量高、速度快,但训练极不稳定,存在 mode collapse(模式崩塌)问题。
- VAE(变分自编码器):编码-解码结构,训练稳定,但生成图像往往模糊——像素级 L2 损失会让模型预测”安全”的均值,抹去高频细节。
- 扩散模型:综合表现最优,同时具备高质量与高多样性,天然支持图像编辑、inpainting 等功能;唯一缺点是推理速度慢,需要多次迭代去噪。

DDPM:扩散模型的数学基础
DDPM(Denoising Diffusion Probabilistic Models,Ho et al., NeurIPS 2020)是现代扩散模型的奠基之作,包含两个核心过程:
前向扩散过程(Forward Process):这是一个固定的马尔可夫链,通过预设的 Noise Schedule 逐步向数据添加高斯噪声,经过约 1000 步后,原始图像完全退化为标准正态分布的随机噪声。这个过程无需学习,完全由数学公式控制。
反向去噪过程(Reverse Process):反向过程是生成的核心环节。神经网络并非直接”创造”图像,而是学习去噪过程——准确地说,是估计每一时刻 t 下的噪声分布(即数据分布的梯度场/Score Function)。训练目标被简化为最小化预测噪声与真实噪声之间的均方误差(MSE)。一旦精确拟合该去噪分布,即可从纯高斯噪声出发,逐步恢复出真实数据。

潜在扩散模型(LDM):让生成走向实用
直接在像素空间训练扩散模型的计算开销极为巨大。生成一张 1024×1024 的图像,模型需要在这个巨大空间里对每一个像素点计算扩散过程,训练极慢,推理时也需要海量显存。
CompVis 团队(Rombach et al., CVPR 2022)基于一项关键观察提出了 LDM:图像中存在大量感知冗余。大量像素所携带的高频纹理细节对人类视觉感知的贡献有限,而真正的语义信息(如物体类别、颜色等属性)可以用更紧凑的表示加以描述。
基于此,LDM 引入了两阶段训练范式:
第一阶段:训练 Autoencoder。Encoder 将高分辨率图像 x 压缩为低维潜在向量 z(通常为原图的 1/64 大小),Decoder 再从 z 重建图像,肉眼几乎无法区分。这个阶段处理的是”感知压缩(Perceptual Compression)”——去除人眼不敏感的高频冗余。
第二阶段:在压缩后的 Latent Space 中训练扩散模型,专注于”语义压缩(Semantic Compression)”,以捕捉数据的高层语义结构。

LDM 的核心优势在于实现了计算效率与生成质量之间的有效平衡:将繁重的”感知压缩”外包给 Autoencoder,让昂贵的 Diffusion Model 只专注于”语义压缩”。这使得 LDM 既能生成结构正确的高分辨率图像,又能保留丰富的纹理细节,同时训练与推理效率大幅提升。这正是 Stable Diffusion 系列成功的理论基础。
从 U-Net 到 DiT:视觉生成的范式转换
在骨干网络的选择上,该领域经历了一次深刻的范式转换——从 U-Net 到 DiT(Diffusion Transformers)。
U-Net(CNN 架构)的优势恰恰是其劣势:它拥有强烈的归纳偏置(Inductive Bias)。CNN 假设像素只与周围像素相关(局部性),并具有平移不变性。这一归纳偏置在小数据时代能够帮助模型快速收敛;然而面对海量互联网数据,这种约束反而成为限制模型容量的瓶颈。更关键的是,U-Net 的扩展性(Scalability)不足——参数量的增加并不总能带来线性的性能提升,且需要精细调整通道数、注意力层位置等大量超参数。此外,从 2D 图像扩展至视频任务时,需将 2D 卷积替换为 3D 卷积,计算量随之急剧增长。
DiT(Diffusion Transformer,Peebles & Xie, ICCV 2023)的核心动机是:在视觉生成领域将 LLM 的成功经验迁移至视觉生成领域。它通过两个关键机制实现了这一目标:
① Patchify(分块):将 Latent 特征图切分为 Patch 并展平为 Token 序列。在模型内部,图像不再是二维网格,而是与 NLP 中的 Token 等价的序列表示。这使得 DiT 可以直接复用经过大规模验证的标准 Transformer Block。对于视频而言,帧序列本质上是更长的 Token 序列——从图像扩展到视频,无需引入额外的架构改动。
② adaLN-Zero(自适应零初始化层归一化):与 U-Net 不同,条件信息(时间步 t 和生成条件 c)并非简单拼接,而是经由 MLP 回归出动态的缩放因子 γ 和偏置 β,在每层 Layer Norm 中自适应调制。零初始化(Zero-initialization)策略使得训练初始阶段整个 Block 近似恒等映射,有效加速了收敛并稳定了深层网络的训练。这一机制意味着,在去噪过程的不同时间步(如第 1 步与第 50 步),网络的”激活状态”存在本质差异——模型可根据去噪阶段动态调整自身的表征方式。


实验结果表明:随着计算量(GFLOPS)与参数量的持续增加,DiT 的生成质量(FID)稳步提升,未见明显饱和。这一趋势印证了视觉生成领域同样遵循 Scaling Law——Sora、Flux、HunyuanVideo 等最新一代视频生成模型均建立在 DiT 之上。
五 数据集概览
数据规模是该领域模型性能的重要决定因素,也是开源与闭源模型之间差距的主要来源。

常用开源数据集包括 VoxCeleb(人脸视频)、HDTF(高清说话人视频)、CelebV-HQ 等,总规模通常在数百至一千小时量级。而字节跳动等头部企业的闭源训练集规模据估计超过 20,000 小时。这一量级差距是当前开源与闭源模型性能差距的根本原因,也印证了规模定律(Scaling Law)在该领域的主导地位。
六 评测指标体系
评测体系涵盖视觉质量、音视频同步和动作自然度三大维度:
视觉质量与身份一致性
• FVD(Fréchet Video Distance)↓:衡量视频的时序连贯性与整体真实感,越低越好,是检测帧间闪烁的关键指标。
• FID(Fréchet Inception Distance)↓:评估单帧图像质量,越低越好。
• CSIM(Cosine Similarity)↑:又称身份一致性(Identity Consistency),衡量生成人脸与参考图像的相似度,越高越好。
唇语同步
• LSE-C(SyncNet 置信度)↑:音视频同步的置信度,越高代表同步越准。
• LSE-D(SyncNet 距离)↓:音视频特征误差,越低越好。
全身动作与情感(新兴指标)
• FGD(Fréchet Gesture Distance)↓:评估全身手势的自然程度(全身模型如 OmniHuman 的核心指标)。
• HKV / HKC(手部关键点方差/置信度)↑:衡量手部动作多样性与检测率,防止”手部冻结”问题。
• E-FID(Emotion-FID)↓:情绪表达的准确性。
• MOS(Mean Opinion Score)↑:主观人工评分(1-5分),是最终的人类感知验证标准。
七 论文精讲
Hallo2:长时高分辨率音频驱动人像动画(ICLR 2025)
Hallo2 是 2024 年 GitHub Star 数最高的数字人开源项目,被 ICLR 2025 收录。它在上一代 Hallo 的基础上,重点针对两个关键技术难点展开改进:长视频生成中的身份漂移问题,以及高分辨率细节的保持能力。
核心创新在于其精心设计的训练策略(Training Recipe):通过分阶段训练,先在短视频上建立稳定的基础能力,再逐步扩展到长时序建模。对于长视频中常见的”身份漂移”问题,Hallo2 在时序注意力机制上做了专门的强化设计,确保模型在生成数十秒乃至更长视频时,人物的面部特征始终与参考图像保持高度一致。
Hallo2 在 CelebV-HQ 和 RAVDESS 等标准基准上均达到了当时的最优水平,在 FVD、FID 和 CSIM 指标上显著超越 SadTalker、VExpress 等前代方法,证明了其在长视频身份保持与整体视觉质量上的突破。
Let Them Talk:首个多人对话视频生成(NeurIPS 2025)
Let Them Talk 是该领域的一项开创性工作,也是 NeurIPS 2025 收录论文。它首次将音频驱动虚拟人生成从单人场景推广到了多人对话场景——该场景在实际应用中广泛存在,但此前鲜有专项研究。
相较于单人场景,多人场景所面临的技术挑战更为复杂:
① 音频-人物绑定:如何将不同人的音频信号精确分配给对应的人物,避免音频与人物的错误对应;
② 多人身份保持:在同一视频中同时维护多个不同人物的外貌特征;
③ 自然交互动态:如何对对话中非发言方的表情、眼神及微小肢体反应(如点头、微笑)进行自然建模,使其避免表现出静态、僵硬的状态。
Let Them Talk 的出现标志着音频驱动虚拟人从单人静态场景向多人动态交互场景的重要迈进,为数字人直播、虚拟会议等实际应用奠定了技术基础。
OmniHuman-1:字节跳动的全身数字人基础模型
OmniHuman-1 由字节跳动于 2025 年 2 月发布(闭源),代表了当前工业界在该领域的最强成果之一。它将 Talking Avatar 的概念彻底扩展到了全身数字人(Full-Body Digital Human)的范畴,是本领域 DiT 化趋势的标志性范例。
框架核心
OmniHuman 基于预训练的 Seaweed 模型(采用 MMDiT 架构),最初在通用文本-视频对上进行文生视频预训练,随后通过三阶段混合条件后训练(Post-Training),将其逐步改造为多条件人物视频生成模型。
各驱动条件的设计如下:
• 音频条件:使用 wav2vec 提取声学特征,经 MLP 压缩后与相邻时间戳的音频特征连接,生成逐帧音频 Token,通过交叉注意力注入 MMDiT 的每个 Block。
• 姿势条件:使用姿势引导器编码姿势热图序列,将姿势特征与噪声潜在向量沿通道维度拼接。
• 外观条件:参考图像经 VAE 编码为潜在表示,与噪声视频潜在向量一起展平为 Token 序列,通过修改 3D RoPE 帮助网络区分参考 Token 与视频 Token。
全条件训练扩展策略
OmniHuman 的训练遵循两条核心原则,这是其能有效利用混合条件数据的关键:
原则一:更强条件的任务可复用更弱条件任务的数据,实现数据扩展。因姿势精度等过滤条件而无法用于音频驱动训练的数据,仍可作为文本+图像条件任务的训练数据,避免了数据浪费。
原则二:条件越强,训练比例应越低。实验发现,当姿势(强条件)与音频(弱条件)同时存在时,模型会倾向于依赖更强的姿势条件来生成动作,导致音频条件无法有效学习。因此训练时需确保弱条件具有更高的训练比例。
据此设计了三个训练阶段:Stage 1 仅使用文本+图像条件;Stage 2 加入音频条件;Stage 3 加入所有条件(文本+图像+音频+姿势),且训练比例逐阶段递减。
定量实验结果显示(见图16、17),在人像动画基准(CelebV-HQ、RAVDESS)和全身动画基准上,OmniHuman 在几乎所有指标上全面超越开源最优方法,HKV(手部关键点方差)达到 47.561,远超 DiffGest(23.409)和 CyberHost(24.733),印证了其在全身动作自然度上的显著优势。
OmniHuman 的成功进一步揭示了当前领域的关键现实:开源与闭源模型之间的数据鸿沟持续扩大——开源约 1,000 小时 vs. 闭源约 20,000 小时。规模定律(Scaling Law)是当前阶段的主导力量。
八 未来方向
该领域当前正沿以下几个方向持续推进:
超越人脸:全身表达力
情绪的细粒度控制——通过文本或音频提示精确控制特定情绪状态(如”愤怒但压抑”),而非仅停留于粗粒度情绪类别(如”开心”或”悲伤”);全身协调动作(手势、重心转移、肢体语言)的自然生成。
时间可扩展性:无限流式生成
在不发生身份漂移的前提下持续生成数小时的一致性视频(StableAvatar 范式);面向直播和实时交互场景优化 DiT 推理速度,降低延迟(如 LivePortrait、OpenAvatarChat)。
复杂场景:多人与富条件控制
自然生成双人对话或多人群体交互(超越 Let Them Talk 的 Two-Person 设定);同时利用音频+文本+姿势+深度图等多路信号进行联合控制,实现更精细的内容编辑。
强化学习(RL)集成
借鉴 RLHF 在 LLM 中的成功经验,通过人类偏好反馈优化生成结果的自然度和情感表达,使数字人的表现更符合人类审美预期。
九 总结
本期 Paper Corner 以音频驱动虚拟人合成为主题,从技术原理到前沿论文进行了系统梳理。三点核心洞察:
① 架构演进:从 U-Net 专用管道(Hallo、SadTalker)→ DiT 通用生成基础模型(OmniHuman、Wan 2.2)。Transformer 的各向同性结构配合 Scaling Laws,使视觉生成模型的发展轨迹逐渐趋近于大语言模型(LLM)的演进路径。
② 数据规模的决定性作用:开源(~1,000小时)与闭源(~20,000小时)的数据鸿沟持续扩大,规模定律是当前阶段的决定性力量。这意味着,单纯的算法优化已难以弥补数据量级的差距,数据的质量与规模已成为该领域核心的竞争壁垒。
③ 范式转变:我们正在从”人脸重演(Face Reenactment)“——以口型同步为主要目标,迈向真正的”数字人生成(Digital Human Generation)“——端到端、全身、可交互。未来的数字人,将是 E2E(End-to-End)、Full-Body、Interactive 的统一体。
十 参考文献
[1] J. Ho, A. Jain, and P. Abbeel, “Denoising Diffusion Probabilistic Models,” NeurIPS, vol. 33, pp. 6840–6851, 2020.
[2] R. Rombach et al., “High-Resolution Image Synthesis with Latent Diffusion Models,” CVPR, 2022, pp. 10684–10695.
[3] W. Peebles and S. Xie, “Scalable Diffusion Models with Transformers,” ICCV, 2023, pp. 4195–4205.
[4] W. Zhang et al., “SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation,” CVPR, 2023.
[5] L. Tian et al., “EMO: Emote Portrait Alive,” ECCV, 2024.
[6] S. Xu et al., “VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time,” NeurIPS, vol. 37, 2024.
[7] J. Cui et al., “Hallo2: Long-Duration and High-Resolution Audio-Driven Portrait Image Animation,” ICLR 2025. arXiv:2410.07718.
[8] Z. Kong et al., “Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation,” NeurIPS 2025. arXiv:2505.22647.
[9] G. Lin et al., “OmniHuman-1: Rethinking the Scaling-Up of One-Stage Conditioned Human Animation Models,” ICCV, 2025.
[10] Q. Gan et al., “OmniAvatar: Efficient Audio-Driven Avatar Video Generation with Adaptive Body Animation,” arXiv:2506.18866, 2025.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。