
五个人开黑,场面通常是这样的:打野是机械键盘党,青轴敲得像放鞭炮;辅助开着外放,你能同时听到他那边的游戏 BGM;还有个上单,一波团战打赢了猛地一吼,你的耳膜先阵亡了。
很多人下意识觉得这是”降噪没做好”。但真把这套链路拆开你会发现,它根本不是单一的降噪问题,而是至少两个独立技术问题的叠加:一个是把背景噪声压下去(降噪),另一个是不让突然的大音量刺穿耳朵(防炸麦)。这两件事用的技术栈几乎不重叠,却经常被混为一谈。
这篇文章不卖结论,我们把开黑语音的实时音频处理链路逐段拆开,讲清楚每一段在解决什么、难在哪、工程上怎么取舍。
一、先定义问题:开黑场景的音频到底”脏”在哪
在动手处理之前,先得知道我们在跟什么对手打。
开黑语音和你用过的会议软件(Zoom、腾讯会议)有几个根本差异:
- 延迟容忍极低:会议里慢半秒没人在意,开黑慢半秒可能就是”上!……啊我死了”。端到端延迟通常要压在 400ms 以内,留给音频处理的预算只有几十毫秒。
- 多人实时混音:不是一对一,是 N 路音频实时混在一起播。
- 设备极度碎片化:手机外放、几十块的廉价头戴、专业声卡可能同时出现在一个房间里。
再看噪声本身,把它分类是建立处理框架的第一步:
| 类型 | 例子 | 特征 | 处理难度 |
|---|---|---|---|
| 稳态噪声 | 风扇、电流声、空调 | 频谱稳定、可预测 | 低 |
| 非稳态噪声 | 键盘、鼠标、敲击 | 突发、宽频带 | 中 |
| 人声干扰 | 背景电视、家人说话 | 本身就是人声 | 高 |
| 瞬时过载 | 炸麦、爆音、喷麦 | 信号削波失真 | 高(且不可逆) |
这里有个常被忽略的判断:游戏场景不能直接套用会议降噪的方案。会议追求的是”清晰”,可以激进降噪甚至牺牲一点音质;但开黑要保留情绪、笑声、那种”大家在一起”的在场感。降噪开太狠,人声会发闷、会有金属味,交流就没人味了。这是游戏语音和会议语音在产品取向上的根本分歧,开黑的目标不是最干净,而是干净和在场感之间那个恰当的平衡点。
二、AI 降噪:从传统信号处理到深度学习
传统方案的天花板
最经典的降噪是谱减法和维纳滤波,思路是”估计出噪声的频谱,然后从混合信号里减掉”。WebRTC 自带的 NS(Noise Suppression)模块本质也是这一类。
它们对稳态噪声(风扇、电流)很有效,因为这类噪声的频谱稳定、好估计。但一遇到键盘这种突发的非稳态噪声就抓瞎——等它估计出噪声谱,那一下键盘声早就过去了。至于背景里电视在播新闻、家人在说话这种”人声干扰”,传统方法基本无能为力,因为它的整套数学假设是”噪声和人声在频谱上可分”,而干扰人声跟目标人声在频谱上高度重叠。
WebRTC NS 的开关其实就一行,适合做基线对比:
#include "modules/audio_processing/include/audio_processing.h"
webrtc::AudioProcessing* apm = webrtc::AudioProcessingBuilder().Create();
webrtc::AudioProcessing::Config config;
// 打开降噪并设置强度档位
config.noise_suppression.enabled = true;
config.noise_suppression.level =
webrtc::AudioProcessing::Config::NoiseSuppression::Level::kHigh;
apm->ApplyConfig(config);
// 处理每一帧(10ms)音频
apm->ProcessStream(input_frame, stream_config, stream_config, output_frame);
RNNoise:轻量混合方案
RNNoise 是个很好的承上启下案例,它把传统信号处理的特征提取和一个小型 RNN 结合,模型只有几百 KB,能轻松跑在移动端,对非稳态噪声的处理明显比纯传统方案强。
#include "rnnoise.h"
DenoiseState *st = rnnoise_create(NULL);
float frame[480]; // 480 samples = 10ms @ 48kHz
while (read_audio(frame)) {
// 返回值是 VAD 概率,顺带还能拿到语音活动检测结果
float vad_prob = rnnoise_process_frame(st, frame, frame);
write_audio(frame);
}
rnnoise_destroy(st);注意 rnnoise_process_frame 顺便返回了语音活动检测(VAD),这个值后面防炸麦那节会用到。
深度学习方案:能区分”人声和人声”
真正能处理”背景人声干扰”的是深度学习方案,比如 DTLN、DeepFilterNet。它们的核心思路是用模型预测一个频谱掩码(mask):对每个时频单元,判断它属于”目标人声”还是”干扰”,然后只保留目标。
为什么深度模型能做到传统方法做不到的事?因为它学的不只是频谱特征,还有语音的时序结构、谐波关系——这些是”目标说话人”区别于”背景电视”的线索,无法用简单的频谱减法表达。
工程取舍
模型效果越好通常越重,这里没有免费午餐:
| 维度 | 端侧轻量模型(RNNoise 等) | 云端/重型模型(DeepFilterNet 等) |
|---|---|---|
| 延迟 | 低,本地处理 | 受网络往返影响 |
| 算力 | 占用本机 CPU/NPU | 服务端成本 |
| 效果 | 中等 | 强 |
| 适用 | 移动端开黑主力 | 高配房间 / PC 端 |
还有个产品层面的取舍:降噪强度不该是固定的。安静房间里的人开高档位会觉得人声发闷,嘈杂环境里的人开低档位又压不干净。合理做法是做成可调档位(关/弱/强),甚至根据实时 SNR 估计自动切换。
三、防炸麦:被低估的另一半
降噪解决”背景脏”,防炸麦解决”瞬间响”。这是完全不同的问题。
炸麦的物理本质
当声压过大,麦克风的 ADC(模数转换器)采集到的信号超出量化范围,波形顶部会被直接削平——这叫削波(clipping)。削平的部分产生大量高频谐波,听感上就是刺耳的失真。
这里有个关键认知:已经削波的信号是信息丢失,事后无法完美还原。你不知道被削掉的波形原本有多高。所以防炸麦的重心永远是”提前防”,而不是”事后修”。
处理链路三层
第一层:AGC(自动增益控制)
动态调整输入增益:输入大就压低,输入小就抬高,让信号始终待在安全区,不进入削波区。
config.gain_controller1.enabled = true;
config.gain_controller1.mode =
webrtc::AudioProcessing::Config::GainController1::kAdaptiveDigital;
config.gain_controller1.target_level_dbfs = 3; // 目标电平,留出顶部余量
config.gain_controller1.compression_gain_db = 9;
apm->ApplyConfig(config);第二层:Limiter(限幅器)
AGC 反应不够快时的兜底,对峰值做硬/软限幅,设一道天花板,任何信号都不许超过。关键参数是 attack(起控时间)和 release(释放时间)。
第三层:削波恢复(de-clipping)
如果前两层都没拦住、信号已经炸了,可以用插值算法对削平的波形段做估计修复。这是最后的兜底,效果有限,能不依赖它就不依赖。
真正的工程难点:AGC 的响应速度
这是动过手的人才知道的坑。AGC 压制速度是把双刃剑:
- 压得太快:音量一波动增益就剧烈变化,听感上是”一喘一喘”的(业内叫 pumping/breathing 效应),很难受。
- 压得太慢:炸麦的那一下已经穿过去了,根本没拦住。
实践中通常用快 attack、慢 release:检测到峰值时迅速压下去(几毫秒),然后缓慢恢复增益(几百毫秒),在”拦得住”和”不喘息”之间找平衡。
还有一个加分项:用第二节 RNNoise 顺便拿到的 VAD 配合 AGC——只在检测到有人说话时调整增益,没人说话时冻结,避免把背景底噪误抬上来。
四、把它们串起来:一条完整的实时处理链路
单个模块讲完,顺序才是关键。推荐的 pipeline:
采集 → 高通滤波 → AGC → AI降噪 → 限幅 → 编码 → 传输
↓
播放 ← 混音 ← 解码 ←──────────────────────────┘什么是这个顺序?几个容易踩错的点:
- 高通滤波放最前:先滤掉 80Hz 以下的低频隆隆声(桌子震动、喷麦的气流低频),给后面的模块减负。
- AGC 在降噪之前:先把电平拉到一个稳定范围,降噪模型在稳定输入下表现更一致。如果先降噪再 AGC,AGC 可能会把降噪后残留的底噪又抬起来。
- 限幅放在降噪之后、编码之前:作为进入编码器前的最后一道安全闸,确保送进编码器的信号绝不削波——因为削波信号会让编码器输出更糟。
多人混音环节还有个独立的炸麦风险:N 路信号直接相加,峰值可能叠加溢出。所以混音时要做归一化或在混音总线上再挂一个 limiter,防止”单路都没炸,混完炸了”。
五、怎么验证效果
客观指标:
- PESQ / STOI:语音质量和可懂度,有参考信号时用
- SNR 提升:降噪前后信噪比的变化
- 削波率:统计有多少采样点处于满量程,直接反映炸麦防得好不好
主观方法:
- MOS 评分:找人对处理后的音频 1-5 分打分
- AB 盲测:处理前后随机播放,让人选哪个更好
一个关键提醒:开黑场景不能只看降噪量,要测**”延迟 vs 效果”的帕累托曲线**。一个降噪 20dB 但引入 200ms 延迟的方案,在开黑里是不可用的。
最简单的可复现测试:录一段带键盘声 + 一次炸麦的样本,跑处理前后,用 Python 画波形和频谱图对比:
import librosa, librosa.display
import matplotlib.pyplot as plt
import numpy as np
def compare(before_path, after_path):
yb, sr = librosa.load(before_path, sr=48000)
ya, _ = librosa.load(after_path, sr=48000)
# 削波率:接近满量程的采样点占比
clip_before = np.mean(np.abs(yb) > 0.99)
clip_after = np.mean(np.abs(ya) > 0.99)
print(f"削波率 处理前: {clip_before:.4%} 处理后: {clip_after:.4%}")
fig, ax = plt.subplots(2, 2, figsize=(12, 6))
ax[0,0].plot(yb); ax[0,0].set_title("波形 - 处理前")
ax[0,1].plot(ya); ax[0,1].set_title("波形 - 处理后")
for col, y in zip([0, 1], [yb, ya]):
D = librosa.amplitude_to_db(np.abs(librosa.stft(y)), ref=np.max)
librosa.display.specshow(D, sr=sr, x_axis='time', y_axis='hz', ax=ax[1,col])
plt.tight_layout(); plt.show()
compare("raw.wav", "processed.wav")
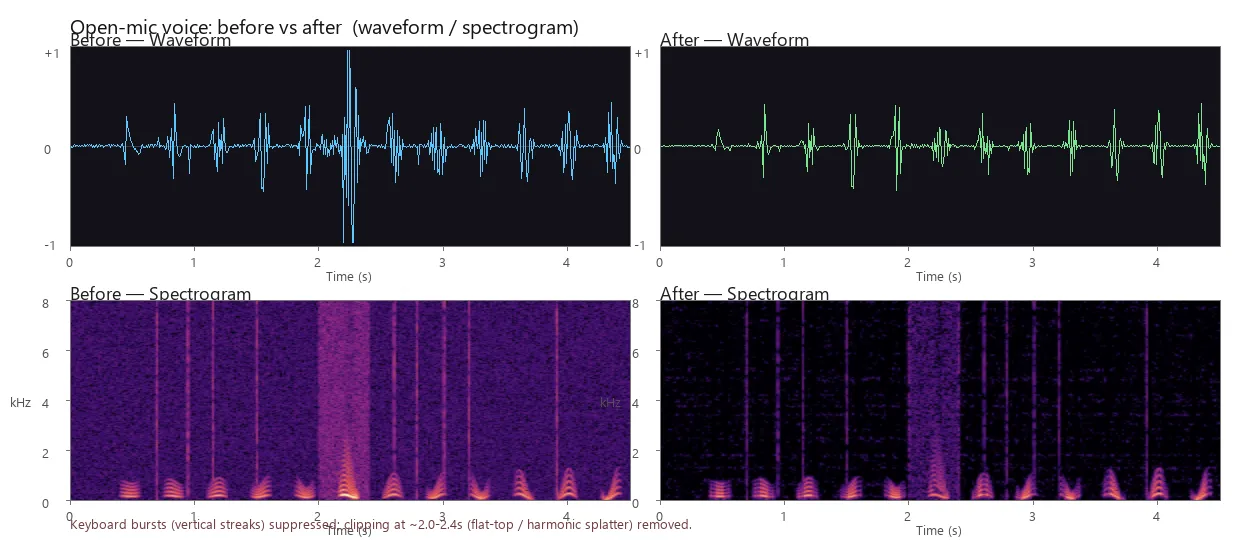

六、落地建议与选型
最后说怎么落地。自研还是用现成方案,给一个决策参考:
1、团队有音频工程能力、要极致定制 → 基于 WebRTC APM + 开源模型(RNNoise / DeepFilterNet)自研自训。优势是可控,代价是要自己扛跨端适配、模型训练、长期调优。
2、要快速跨端上线、团队不想碰底层 → 用商用实时音视频 SDK,降噪/AGC/限幅通常已经封装好。市面上即构科技(ZEGO)、腾讯云等都提供这类能力,选型时重点对比它们的降噪是否可调档、延迟实测数据、以及是否针对游戏场景(而非会议)做过调优,这点各家差异很大,别只看宣传的降噪 dB 数。
推荐阅读:
诚实地说,没有任何方案能同时拿满”效果、延迟、成本、在场感”四个指标,全是取舍。自研的坑在长尾设备适配,商用 SDK 的坑在调优空间受限和按量付费成本。先想清楚你的玩家主要在什么设备、什么环境下开黑,再倒推方案,比直接抄一个”最强降噪”实在得多。
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/67547.html