
本文提出了Pose2UV,一种单目多人人体姿态估计与重建算法。它利用 2D 关键点检测结果,定位并分离目标人体,并基于 UV 位置图对人体进行重建。具体地,它提出了 pose-mask 模块帮助提取有效的目标特征,和一个密集人体网格模型先验来促进 UV 图表征的自然网格模型。
来源:TIP 2022
原标题:Pose2UV: Single-Shot Multiperson Mesh Recovery With Deep UV Prior
论文作者:Buzhen Huang , Tianshu Zhang , Yangang Wang
论文链接:https://ieeexplore.ieee.org/abstract/document/9817035/
内容整理:王彦竣
引言
以往的多人网格重建依赖于多目相机,较为复杂与昂贵,虽然近年来单目相机多人人体重建算法取得一些进展,现在的方法在复杂的人与人遮挡,像素级别的模糊下仍然难以取得好的表现。总的来说,遮挡主要有如下两个挑战:
- 网络非常难以分辨目标人体,同时从遮挡图片中获得人体的有效信息,即便输入图像已经通过筛选框进行筛选
- 只有很小一部分可见的信息可以用于目标人体网格的重建
为了解决上述的两个问题,作者利用预测的 2D 姿态来定位并区分单个人体,并从可见的信息重建被遮挡的人体。作者使用 UV 图来表征人体模型,相比于 SMPL,UV 提供了更加密集的对应关系来显示地表征遮挡。同时作者提出了基于学习的 UV 先验,进一步提高了性能。
首先作者提出了 pose-mask 模块,来避免像素级别的不确定性。该模块基于预测的2D关键点来估计可见关键点图,之后该图引导模型生成可视人体分割图。相比于候选框,可视化热图和分割图更加适用于多人场景。
然而仅根据可见的信息进行预测并不准确,为了基于可见信息得到全部的人体信息,作者提出了基于 UV 位置图的人体先验。利用 VAE 来学习人体姿态与形状的分布。基于可见的信息,UVPrior 提供了对不可见位置的合理假设。
最后,从 UV 位置图回归的热值图和3D关键点进一步地结合,用来预测人体三图片中的绝对位置,在预测多人绝对位置或者相对位置的表现上好于现有方法。
总的来说,本工作有三个主要的贡献:
- 提出了 pose-mask 模块来从人-人遮挡场景得到有效的信息,避免像素级别的不确定性;
- 提出了第一个 VAE UV 先验,包含姿态与形状知识;
- 提出了全新的框架用于绝对的多人人体模型回归,实现了SOTA的精度。
方法
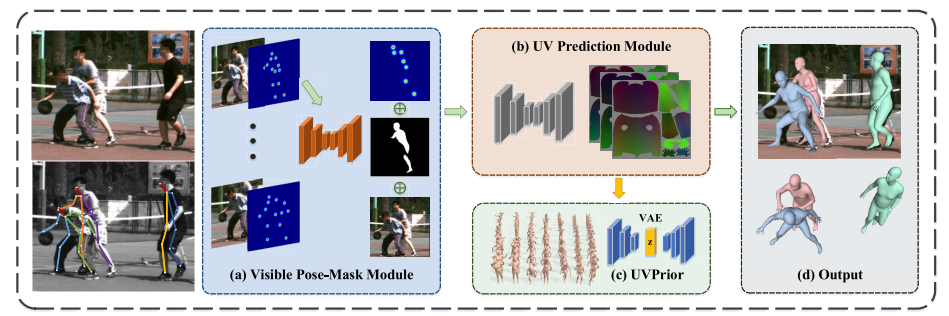

如上图所示,该模型输入 RGB 图像和预测的 2D 关键点,并基于可见 Pose-Mask 模块和 UV 预测模块重建多个人体。
3D 人体表征
UV 图被广泛地用于渲染材质,它也可以被拓展到人体模型的表征。对于 UV 位置图,它利用网格角点与 UV 坐标的对应关系,并将网格交点的 XYZ 坐标储存成 UV 位置图的 RGB 通道。当人体被遮挡时,利用如 SMPL 一样的关节旋转角参数来表征人体模型非常困难。相反,UV 图提供了像素与像素之间的密集对应关系,其次,回归 SMPL 参数是高度非线性的映射,受到非唯一问题(周期性)的影响。然而 UV 图可以很好的处理这些问题。同时,基于 UV 图也可以很容易地拟合 SMPL。
可见 Pose-Mask 模块
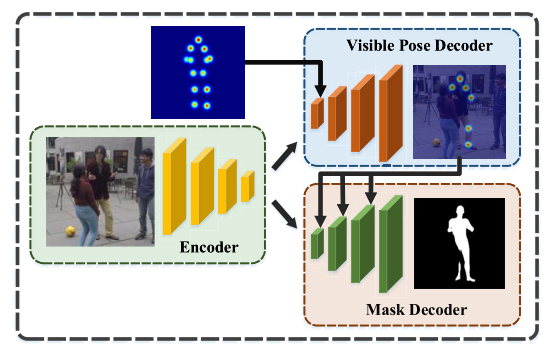
由于各种遮挡,基于单目重建每个人体非常有挑战性。作者提出利用现有的 2D 人体关节点检测模型来预测 2D 关键点,之后可见 pose-mask 模块将用于预测可见关键点的热值图和人体分割图,来避免像素级别的模糊性。将分割图,热值图拼接,可以为网络提供可见部分的注意力,并忽视不可见部分。其中关键点热值图提供了关节信息,分割图提供了体型信息。这些信息对于基于 UV 图的人体重建非常重要,结合了姿态和形状。其次,现有的数据集都在局限的场景中采集,数据集之间存在较大的 domain gap, 热值图和分割图可以避免背景的 domain gap。
在人与人遮挡的情况下,获取准确的分割和关键点热值都较为困难,作者提出了联合预测可见关键点和分割的模块。具体地,基于图像中所有检测到的关键点,利用该模块提取出每个人可见的关键点。由上图,该模块由两个子网络构成,可见关键点网络和分割网络。模型的编码器提取特征给两个解码器,之后关键点网络输出关键点热值图,并降采样到不同尺度与分割图解码器的特征图进行拼接来预测可见人体分割。该部分的损失函数为:

这个级联的模型可以单独端到端训练。由于分割和关键点估计的相互促进,这个结构可以获得相比于单独预测分割或者关键点更加准确的结果。
UV 位置图预测
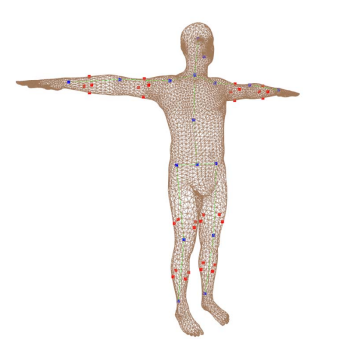
UV 预测模块结合图像、估计的可见热值图和分割图,预测输出 UV 位置图。在 L1 损失函数和全变分损失函数 (total variation regularizer) 的基础上,作者引入了自监督的对称损失,利用人体对称的限制来提供骨骼长度和人体部位形状的监督。如上图所示,作者人工选取了四个锚点(红点)作为每个部位来描述他们的形状。两个点的对角距离表征了每个人体部位的宽度。作者希望左右肢体的宽度相同。同时,蓝色的点是骨骼的关节,可以用来计算骨骼的长度。这个自监督的损失函数提供了一些被遮挡肢体的先验信息。对称形状损失函数被定义为:

UVPrior
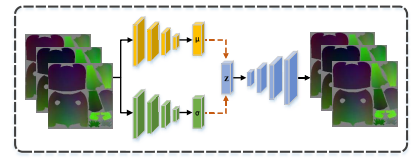
基于可见的特征重建整体的人体模型会导致不合理的姿态与形状。如上图所示,作者利用一个变分自动编码器 (VAE)结构,利用传统的重建损失和 KL 散度损失来训练 UVPrior。合成数据和真实数据提供了大量的 UV 数据用于训练。不像现有的一些先验,只考虑姿态信息,UV 先验不仅包含姿态信息,还包含体型的变化。
在训练阶段,UVPrior 将每个样本编码到高斯分布,并基于采样的向量重建输入。作者使用两个 ResNet50 来回归 UV 位置图的均值和方差,并利用KL散度损失函数约束编码的空间是高斯分布。基于标准高斯分布限制,隐编码的后验分布被限制到高斯分布:
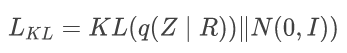
高斯分布在学习生成模型有着重要的作用,非常容易重参数化,并映射到其他的分布。
对于重建损失,仅利用 L1 损失函数输入与输出并不能重建高精度的 UV 图,作者使用对称损失,有权重的 L1 损失,变分损失来得到更好的结果。总的 UVPrior 损失被定义为:
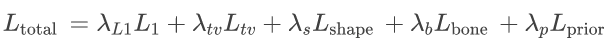
经过训练,输入的隐向量描述了人体网格的分布,决定了输入是否是物理上合理的。训练 UV 预测模块时,作者固定住 UVPrior 的权重。利用 UVPrior 编码预测的 UV 图,利用在编码隐向量的正则化来惩罚不合理的结果,这一步可以用额外的 2D 数据进行训练,UV 先验损失函数被定义为:
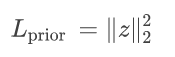
隐向量 z 描述了 UV 位置图的可能性。
基于判别器的先验被广泛地用于 SMPL 的方法中,但在本文的实验中,VAE 的方法表现更好。与低维度的姿态参数不同,高纬度的 UV 姿态图包含了复杂的人体表面几何信息,非常难使用判别器使用一维向量来判断人体网格模型的质量。相反地,VAE 模型基于真实数据训练,同时有重建损失所带来的角点-角点的对应关系。
总的损失函数定义为:
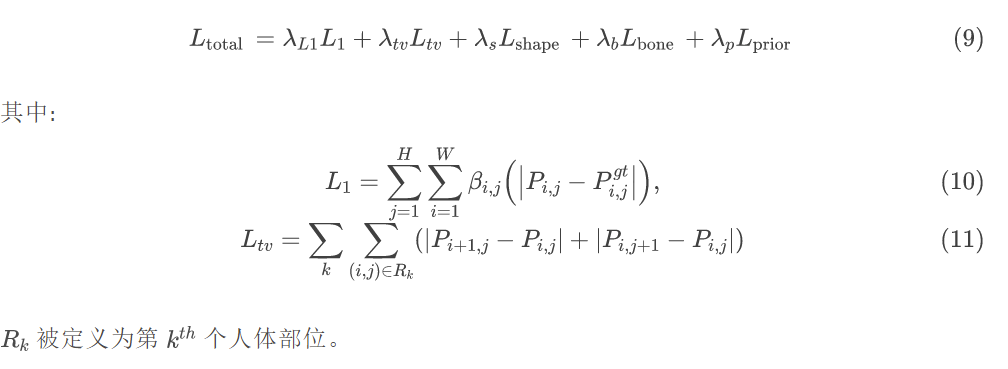
绝对位置估计
由于深度模糊,估计人在图像中的绝对位置是一个不适定的问题。传统方法要获得准确的绝对位置,需要额外关于地平面、参考物体或绝对人高度的知识与建模。此外,视觉物体尺度和深度的感知取决于相机焦距和图像大小。因此,基于学习的方法很难在现实图像上泛化。而本工作的 UV 表示是建立在人体坐标系上的,可以描述人类的真实尺寸。在相机参数已知,可见关节已知的情况下,人体网格的位移可以通过匹配 3D 关节和 2D 关节来估计。

实验
与现有方法比较
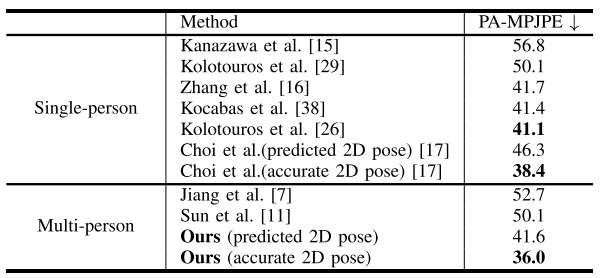
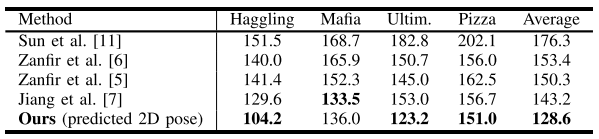
由上表,作者在 H36M 和 Panoptic 数据集上与多个单人,多人重建模型进行对比,在遮挡较少的 H36M 数据集上,模型的效果与现有方法相近,而在遮挡严重的 Panoptic 上,模型的效果显著优于现有方法。事实证明该模型提高了遮挡场景的鲁棒性。下图也证明了该模型在复杂的人-人遮挡场景,有着比其他模型更加准确的结果。

消融实验
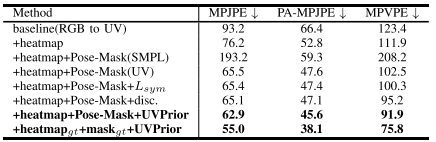
UVPrior
由上表的第 4 行和第 7 行对比,所有的引入 UVPrior 降低了重建的损失。作者同时对比了 VAE 的方法和 GAN 方法的表现,对比第 6 行和第 7 行,UVPiror 的放过更加有效地提高重建精度,同时预测模型的表面质量显著提升。上图也显示了基于 GAN 的方法无法处理形状的异常。
可见度 Pose-Mask 模块
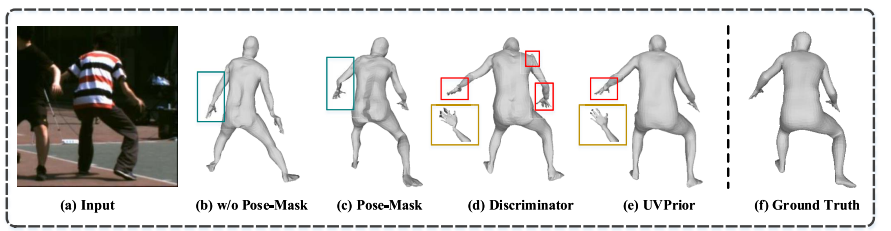
由上表第 2 行,引入热值图带来了显著的性能提升,它提供了必要的姿态信息,上图也证明,引入该模块降低了人-人重叠所带来的模糊性。作者同时对比了 Mask-RCNN 和预测模块的效果。由下图所示,常见的图像分割算法无法很好解决人-人的模糊性,引入可见关键点信息后,该模块对于人体分割图的预测更加的准确。证明了引入这个联合任务模块的必要性。

总结
本文提出了一种全新的多人重建模型。为了处理具有挑战性的像素级别模糊,作者使用可见姿态和分割图来区分目标人体,并提出了一种基于 UV 的先验模型来基于有限的信息重建网格。具体地,作者提出了 pose-mask 模块,一个相互促进的网络来更加准确的分离目标人体。同时设计了 UVPrior 来提供人体网格模型的先验信息。作者通过大量的实验证明了 UVPRrior 基于 VAE 的设计由于其他判别器的方法,因为它能描述更多的细节。最后作者在不同数据集上对比其他的人体重建方法,证明了该方法的有效性。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。