
Summary
SRS支持将直播录制为VoD文件,在压测时,如果流路数很多,会出现CPU消耗很多的问题。
原因是写入较小视频包时,SRS使用了write,由于没有缓冲能力,导致频繁的系统调用和磁盘繁忙。
优化方案,可以选择fwrite(v5.0.133+),或者老版本用内存盘方案,可将DVR性能提升一倍以上。
Environments
SRS服务器配置如下:
- • CPU:INTEL Xeon 4110 双路16和32线程
- • 内存:32G
- • 网卡:10Gb
- • 磁盘:两块980G的SSD盘做成RAID0(可用空间共1.8T)
- • 操作系统:CentOS 7.6。
- • 流码率:3Mbps
这里需要说明一下,采用SSD盘主要是为了确保磁盘性能足够,以确保能够支撑大的并发压力,从而在大并发压测的情况下观察系统性能情况,如果本身磁盘I/O性能比较低下,大量的I/O等待可能导致观察不到CPU瓶颈的现象。
另外,在我的测试环境中,SRS经过了多进程改造,能够支持推流进来后自动将不同的流均衡到不同的SRS进程上面,从而能够充分利用服务器多核的能力,但是由此得出的结论同样适合于单进程SRS。
SRS开启DVR录存功能,使用如下命令启动SRS:
env SRS_LISTEN=1935 SRS_MAX_CONNECTIONS=3000 SRS_DAEMON=off SRS_SRS_LOG_TANK=console
SRS_HTTP_API_ENABLED=on SRS_VHOST_DVR_ENABLED=on ./objs/srs -e压测工具,用srs_bench套件中的sb_rtmp_publish模拟推流客户端进行大并发量推流模拟,一台机器压测能力不够可以开启多台机器进行压测。
./objs/sb_rtmp_publish -i doc/source.200kbps.768x320.flv
-c 100 -r rtmp://127.0.0.1:1935/live/livestream_{i}启动srs后,用压测工具进行压测,观察测试过程中的CPU、网络IO、磁盘IO相关数据,并进行对比。
write SSD Disk
SRS优化前,默认的方式就是使用write方法,直接写入磁盘。测试能支持1000路写入,CPU跑满。
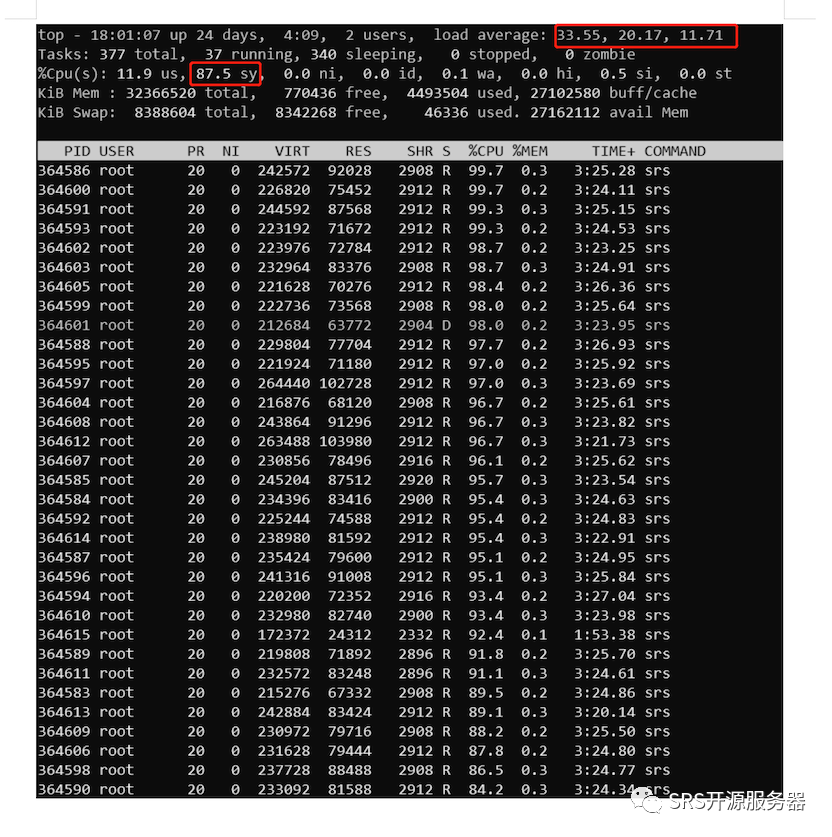

从上图可以看到,1000路3M的DVR录制已经将系统的CPU都跑满了,特别需要关注的是cpu的时间主要消耗在了内核空间上面,占了87.5%。
用nload查看当时的输入带宽情况,发现系统输入带宽平均只有2.17Gb,没有达到预期的3Gb的带宽,应该是CPU负载过高导致SRS来不及处理网络I/O引起的性能下降。
再用perf工具对其中一个srs 进程进行性能采样分析,得到下面的火焰图:
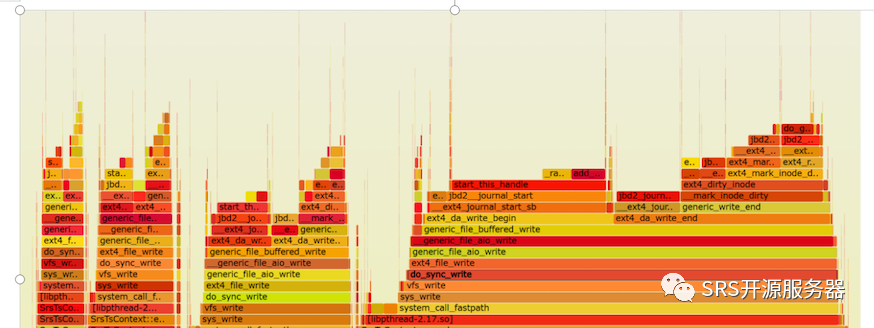
可以发现,sys_write操作占用的时间消耗是最多的,对比上面用top看到的内核态消耗的时长占比可以得出的结论是一致的。
最后看磁盘I/O情况:
从上图看磁盘的利用率没有到100%,虽然有一定的波动,但是总体上还是在合理的可以接受的性能范围内。
fwrite SSD Disk
SRS优化后,使用fwrite写入磁盘。录制1000路流,占用32%的CPU,性能提升一倍以上。
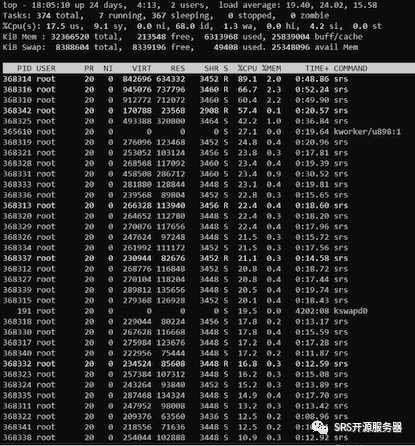
从上图可以看到,1000路3M的DVR录制已经将系统的CPU整体来说还有很多空闲(这里说明一下,部分进程的SRS占比高的原因是因为当时任务分配的不够均衡引起的)。特别值得注意的是本次测试内核时间占比大幅下降,只有9.1%。
再用nload看网络i/o情况,网络i/o相当平稳,和预期的3Gb完全吻合。
再看磁盘i/o的情况,磁盘的利用率没有到100%,虽然有一定的波动,但是总体上还是在合理的可以接受的性能范围内。
最后看火焰图:
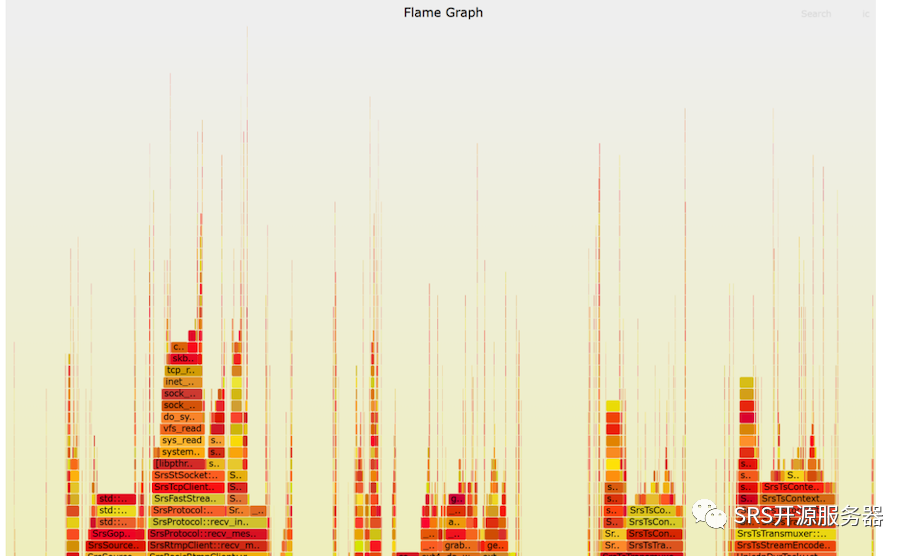
系统调用的时间占比大幅度缩短了,在上图几乎找不到sys_write的位置了。
write Memory Disk
SRS优化前,也可以挂载内存盘,使用write写入内存盘。
需要说明一下,由于我手上的服务器只有32G内存,只能分配16G内存给内存盘使用, 由于内存盘比较小,按照3Gb的写入速度,最多能写42s的DVR。
采用如下命令挂载内存盘:
mount -t tmpfs -o size=16G,mode=0755 tmpfs /data/memdisk并且修改srs的配置文件将文件写入到内存盘:
env SRS_LISTEN=1935 SRS_MAX_CONNECTIONS=3000 SRS_DAEMON=off SRS_SRS_LOG_TANK=console
SRS_VHOST_DVR_DVR_PATH=/data/memdisk/[app]/[stream].[timestamp].flv
SRS_HTTP_API_ENABLED=on SRS_VHOST_DVR_ENABLED=on ./objs/srs -e测试数据如下,占用CPU27%左右:
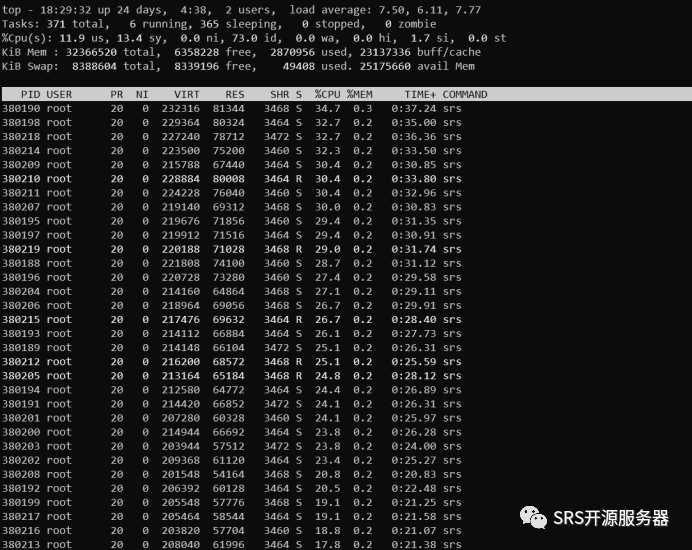
从CPU的情况看,采用内存盘也比较理想,load average只有 7.5,性能也不错。如果不需要录制大量的流,这种方式也是非常好的。
macOS Test Data
在macOS环境下,也做了一组数据,供参考:
- 1. macOS: MacBook Pro, 16-inch, 2019, 12CPU(2.6 GHz 6-Core Intel Core i7), 16GB memory(16 GB 2667 MHz DDR4).
- 2. v5.0.132优化前: RTMP to HLS, 200 streams, SRS CPU 87%, 740MB
- 3. v5.0.133优化后: RTMP to HLS, 200 streams, SRS CPU 56%, 618MB
- 4. v5.0.132优化前: DVR RTMP to FLV, 500 streams, SRS CPU 83%, 759MB
- 5. v5.0.133优化后: DVR RTMP to FLV, 500 streams, SRS CPU 35%, 912MB
- 6. v5.0.133优化后: DVR RTMP to FLV, 1200 streams, SRS CPU 79%, 1590MB
Conclusion
从以上4个测试可以得出以下结论:
- 1. 无论ssd盘还是内存盘,采用fwrite的性能比采用write的性能有明显的提升,其主要得益于fwrite内置的缓存功能减少了系统调用的数量,带来内核时间消耗的减少,从而提升了性能。
- 2. 在ssd盘情况下,fwrite的缓冲能力可以大幅度降低对于CPU的消耗,但是在采用内存盘的情况下,CPU的消耗虽然也能够降低,但是不是那么明显。
- 3. 录制到内存盘性能也很好,如果流路数不多也可以考虑这种方案。
Note: 之前想当然地认为用write写内存盘,因为系统调用引起的用户态到核心态的切换还是会导致cpu大量消耗,一样会导致CPU消耗高居不下,但是事实看到是采用内存盘以后cpu消耗明显下降了,是不是可以认为系统调用引起的用户态到核心态的切换消耗实际上并没有想象的那么大,而是内核态在处理小块的文件write写入磁盘的时候还存在着其他因素引起消耗大量的cpu。譬如,因为最终写入磁盘都是按照扇区写入的,而小块写入需要操作系统将这个小块对齐并填充到一个完整的磁盘扇区,从而引起性能大幅下降,而内存盘是不是就不会存在这个问题?由于我自己没有内核方面的经验,所以只能存疑了,也请懂内核的朋友给予指点。
What’s Next
在linux环境中,对于文件进行读写操作的时候,我们可以采用libc提供的fread/fwrite系列的一套函数,也可以采用操作系统提供的read/write系列的一套系统api函数。
对于libc提供的文件读写函数,首先它可移植性比较好,因为libc为我们屏蔽了操作系统的底层差异,在linux、windows等不同的操作系统环境下面都有标准的接口实现,因此不需要我们为不同的操作系统进行适配。其次,libc提供了带缓冲功能的读写能力,而操作系统底层文件读写API却不提供这种能力,缓冲能力在大多数情况下能够为我们带来文件i/o性能的提升。
当然libc的文件读写api函数也存在不足之处,缺少了writev/readv之类的函数。不过readv/writev的功能无非就是将多个缓冲区的内容合并成一次批量读写操作,而不需要进行多次API调用,从而减少实际物理I/O的次数,我想libc没有提供这类函数主要也是因为其缓冲功能已经能够将本来需要多次的小块物理I/O操作合并成了一次更大块的物理i/o操作,所以就没有必要再提供readv/writev了。
不管SRS也好,还是NGINX也好,虽然前者采用st-thread框架的协程能力来实现网络异步i/o,但是和后者一样,最终还是采用epoll事件循环来实现网络异步i/o的,但是对于文件i/o,目前存在的问题是,无论是write还是fwrite都是同步操作,在磁盘请求比较繁忙的情况下,必然会导致进程或者线程阻塞,从而引起系统并发性能的下降。
由于操作系统本身不支持epoll异步(linux下的ext4本身没有实现poll的回调),所以寄希望于epoll来实现文件i/o的异步操作是行不通的。NGINX对于文件异步i/o采用了aio+多线程的方式来实现的,个人感觉是由于和epoll模型来说是一套独立的框架,还是相对比较复杂。
不过,好在linux在5.1内核以后提供了io_uring的异步i/o框架,它可以统一网络i/o和磁盘i/o的异步模型,并支持buffer IO,值得我们去关注学习一下,也值得我们后面一起去探讨一下未来如何在srs上采用io_uring来实现带有fwrite一样的缓冲能力的磁盘i/o的操作,来彻底解决磁盘i/o引起的性能瓶颈的问题。
Written by 王磊(bluestn).
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。