
最近几年,钉钉迅速成为一款国民级应用。IM 作为钉钉最核心的功能,每天需要支持海量企业用户的沟通,同时还通过 PaaS 形式为淘宝、高德等 App 提供基础的即时通讯能力,是日均千亿级消息量的 IM 平台。
我们通过 RocketMQ 实现了系统解耦、异步削峰填谷,还通过定时消息实现分布式定时任务等高级特性。另外,过程中也与 RocketMQ 深入共创,不断优化解决了很多问题,并且孵化出 POP 消费模式等新特性,彻底解决了RocketMQ 负载粒度只能到Queue级别、rebalance导致时延等问题。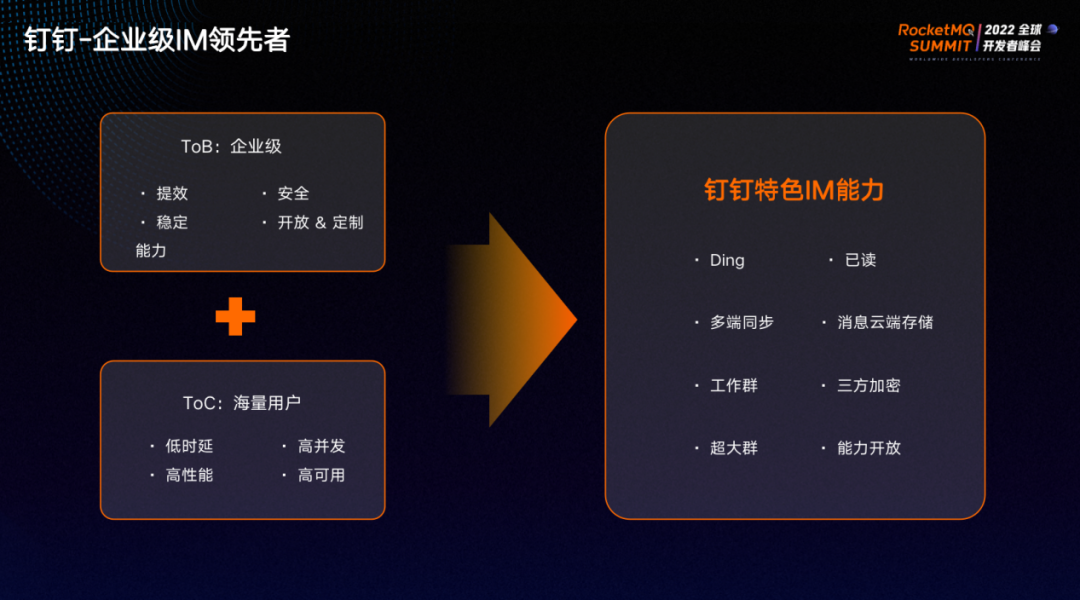

钉钉作为企业级 IM 领先者,面临着巨大的技术挑战。市面上DAU过亿的App里,只有钉钉是2B产品,我们不仅需要和其他 2C 产品一样,支持海量用户的低时延、高并发、高性能、高可用,还需保证企业级用户在使用钉钉时能够提升沟通协同效率。
因此,钉钉提供了很多竞品没有的功能,比如消息必达是钉钉的代名词。Ding和已读很好地提升了大家在企业中的沟通效率。消息多端同步、消息云端存储使得用户不管在哪里登录钉钉都能看到所有历史消息。工作场景下,信息安全是企业的生命线,我们提供了非本组织的人不能加入策略,用户退出企业即自动退出工作群,很好地保障了企业的信息安全。
同时,在钉钉官方已经支持全链路加密的基础上,还支持用户自己设置密钥的三方加密,进一步提高了系统的信息安全性。
稳定性方面,企业用户对稳定性的要求也非常高,如果钉钉出现故障,深度使用钉钉的企业都会受到巨大影响。因此,钉钉 IM 系统在稳定性上也做了非常深入的建设,架构支持异地多活和可弹性伸缩容,核心能力所有依赖都为双倍。并建立了流量防护,制定了单测和集成测试标准以及常态化的容灾演练机制。比如波浪式流量就是在做断网演练时发现。
针对不同行业的业务多样性,我们会尽可能地满足用户的通用性需求,比如万人群、全员群等,目前钉钉已经能够支持 10 万人级别的群。更多的需求我们会抽象出通用的开放能力,将 IM 能力尽可能地开放给企业和三方 ISV,使不同形态的业务都能在钉钉平台上得到满足 。
市场调研表明,钉钉 IM 的开放能力数量处于行业顶尖水平,我们将持续结合业界智慧,打造好钉钉生态。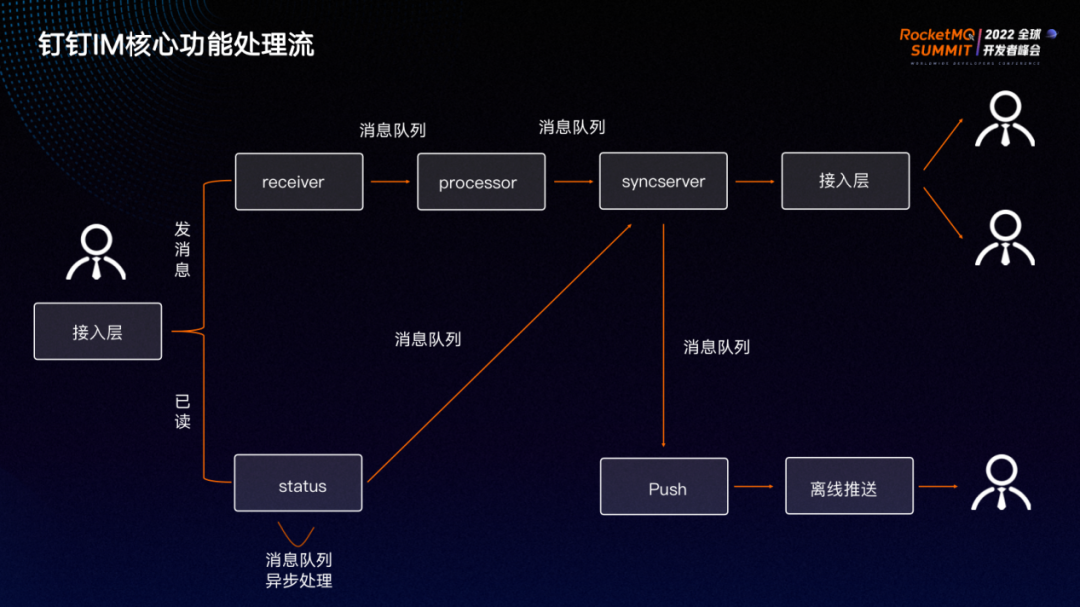
IM 本身是异步化沟通系统,与开会或者电话沟通相比,我们在发送出一条消息后,并不要求对方马上给出回应。这种异步特性与消息队列的能力很契合,消息队列可以很好地帮助 IM 完成异步化解耦、失败重试、削峰填谷等能力。
以 IM 系统最核心的发消息和已读链路简化流程(如上图),来详细说明消息队列在系统里的重要作用。
发消息链路流程如下:
处于登录状态的钉钉用户发送一条消息时,会与钉钉的接入层建立长连接。首先会将请求发送到 receiver 模块,为保证发消息体验和成功率,receiver 应用只做这条消息能否发送的校验,其他如消息入库、接收者推送等都交由下游应用完成。校验完成之后将消息投递给消息队列,成功后即可返回给用户。
消息发送成功,processor 会从消息队列里订阅到这条消息,并对消息进行入库处理,再通过消息队列将消息交给同步服务 syncserver 做处理,将消息同步给在线接收者。
对于不在线的用户,可以通过消息队列将消息推给离线 push 系统。离线 push 系统可以对接接苹果、华为、小米等推送系统进行离线推送。
用户发消息过程中的每一步,失败后都可通过消息队列进行重试处理。如 processor 入库失败,可将消息打回消息队列,继续回旋处理,达到最终一致。同时,可以在订阅的过程中对消费限速,避免线上突发峰值给系统带来灾难性的后果。
已读链路对时效性要求低,但是整个系统的已读请求量非常大,流程如下:
用户对一条消息做读操作后,会发送请求到已读服务。已读服务收到请求后,直接将请求放到消息队列进行异步处理,同时可以达到削峰填谷的目的。已读服务处理完之后,将已读事件推给同步服务,让同步服务将已读事件推送给消息发送者。
从以上两个核心链路可以看出,消息队列是 IM 系统里非常重要的组成部分。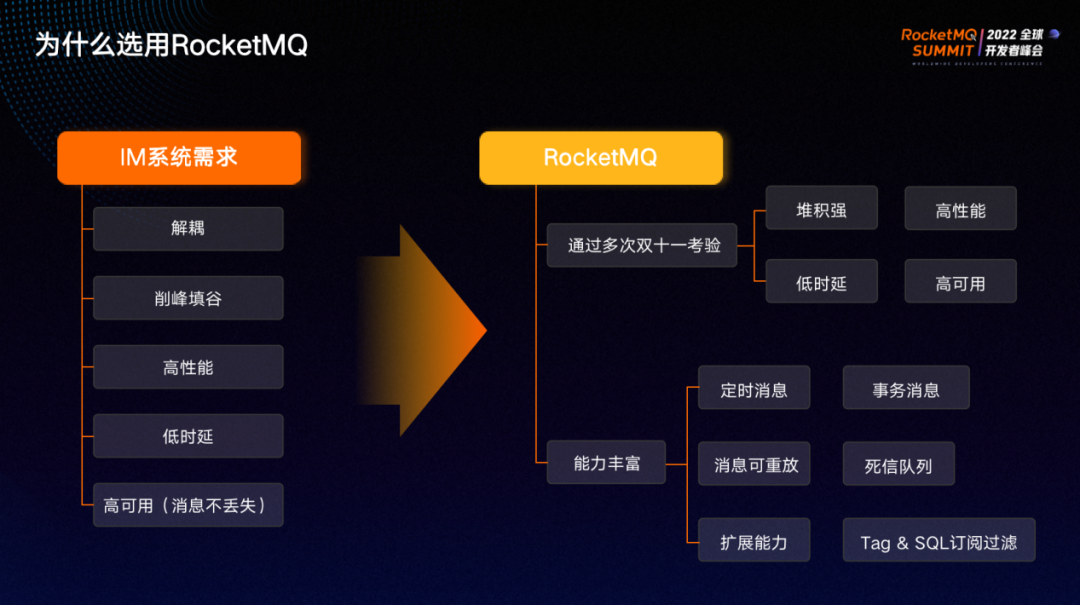
阿里内部曾有 notify、RocketMQ 两套应用消息中间件,也有其他基于 MQTT 协议实现的消息队列,最终都被 RocketMQ 统一。
IM 系统对消息队列有如下几个基本要求:首先,解耦和削峰填谷,这是消息队列的基础能力;除此之外,IM系统对高性能、低时延要求也非常高,保证亿级规模用户的情况下不产生抖动;同时,可用性方面不仅包括系统可用性,也包括数据可用性,要求写入消息队列时消息不丢失(钉钉 IM 对消息的保证级别是一条都不丢)。
RocketMQ 经过多次双 11 考验,其堆积性能、低时延、高可用已成为业届标杆,完全符合对消息队列的要求。同时它的其他特性也非常丰富,如定时消息能够以极低的成本实现分布式定时任务,事务消息的消息可重放和死信队列提供了后悔药的能力,比如线上系统出现 bug ,很多消息没有正确处理,可以通过重置位点、重新消费的方式,订正之前的错误处理。
另外,消息队列的使用场景非常丰富,RocketMQ 的扩展能力可以在消息发送和消费上做切面处理,实现通用性的扩展封装,大大降低开发工作量,比如阿里内部应广泛应用的Trace系统通过 RocketMQ 的扩展能力实现。Tag & SQL 订阅能力使得能够在broker层对消息进行过滤,无需在消费端定于所有消息,大幅降低下游系统的订阅压力。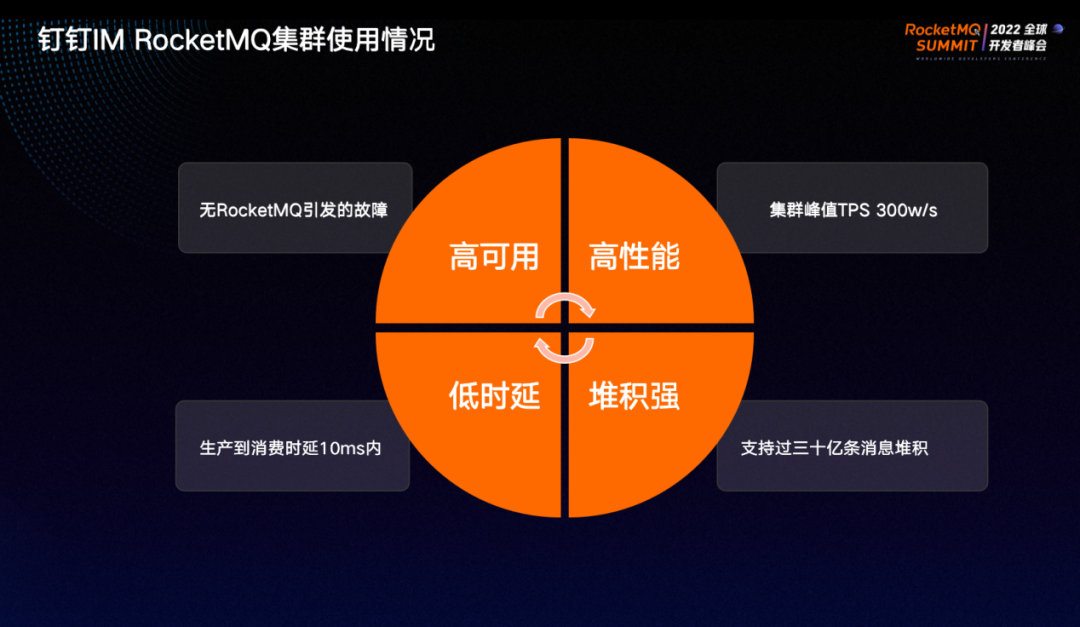
钉钉使用RocketMQ 至今从未发生故障,集群峰值 TPS 可达 300w/s,从生产到消费时延能够保证在 10 ms 以内,基本只有网络方面的开销。支持 30 亿条消息堆积,核心指标数据表现抢眼,性能异常优秀。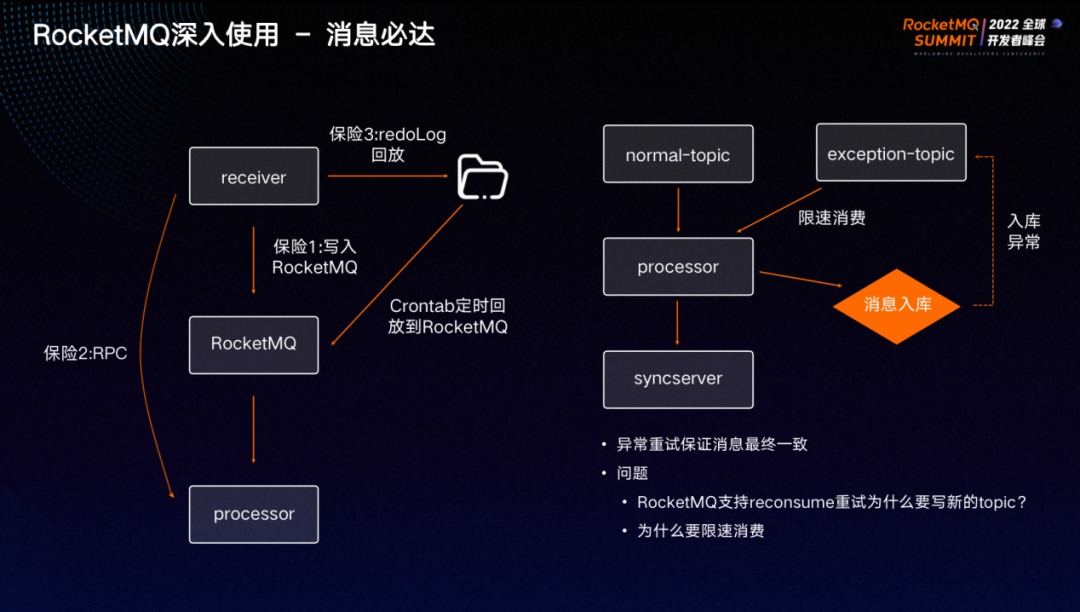
发消息流程中,很重要的一步是 receiver 应用做完消息能否发送的校验之后,通过 RocketMQ 将消息投递给 processor 做消息入库处理。投递过程中,我们提供了三重保险,以保证消息发送万无一失:
第一重保险:receiver 将消息写进 RocketMQ 时, RocketMQ SDK 默认会重试五次,每次尝试不同的 broker ,保障了消息写失败的概率非常小。
第二重保险:写入 RocketMQ 失败的情况下,会尝试以 RPC 形式将消息投递给 processor 。
第三重保险:如果 RPC 形式也失败,会尝试将本地 redoLog 通过 Crontab 任务定时将消息回放到 RocketMQ 里面。
此外,如何在系统异常的情况下做到消息最终一致?
Processor 收到上游投递的消息时,会尝试对消息做入库处理。即使入库失败,依然会将消息投给同步服务,将消息下发,保证实时消息收发正常。异常情况时会将消息重新投递到异常 topic 进行重试并在消息内带上失败节点,下次重试可直接在异常处重新开始。投递过程中通过设置delay level做退避处理,对异常 topic 做限速消费。
重试写不同的 topic 是为了与正常流量隔离,优先处理正常流量,防止因为异常流量消费而导致真正的线上消息处理被延迟。另外, Rocket MQ 的一个 broker 默认只有一个 Retry 消息队列,如果消费失败量特别大的情况下,会导致下游负载不均,某些机器打死。
此外,如果故障的时间长,虽然有退避策略,但如果不做限速处理,重试流量会持续叠加,导致雪崩。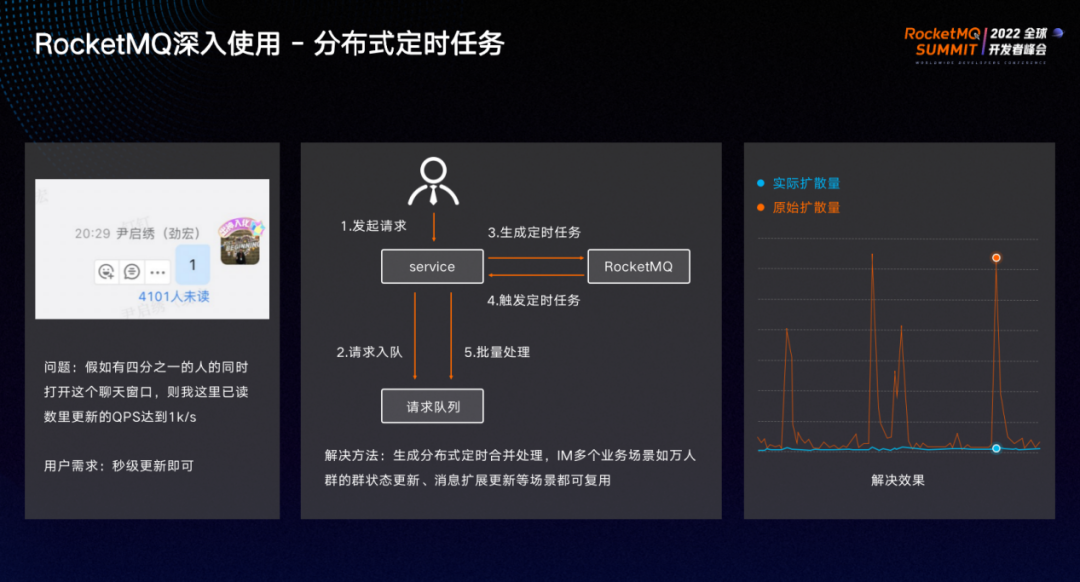
用 RocketMQ 实现分布式定时任务的流程如上图所示。
在几千人的群里发一条消息,假设有 1/4 的成员同时打开聊天窗口,并且向服务端发送已读请求。如果不对服务端已读服务和客户端需要更新的已读数做合并处理,更新的 QPS 会高达到 1000/s。钉钉能够支持十几万人的超大群,超大群的活跃对服务端和客户端都会带来很大冲击,而实际上用户只要求实现秒级更新。
针对以上场景,我们进行了优化:可以利用 RocketMQ 的定时消息能力实现分布式定时任务。以已读流程为例,如上图所示,用户发起请求时,会将请求放入集中式请求队列,再通过 RocketMQ 定时消息生成定时任务,比如 5 秒后批量处理。则5秒之后,RocketMQ 订阅到任务触发消息,将队列里面所有请求都取出进行批量处理。
我们在RocketMQ 定时消息的基础之上抽象了一个分布式定时任务的组件,提供了很多其他实时性可达秒级的功能,如万人群的群状态更新、消息扩展更新都接入了此组件,大幅降低系统压力。如上图右,在一些大群活跃的时间点成功地让流量下降并保持平稳状态。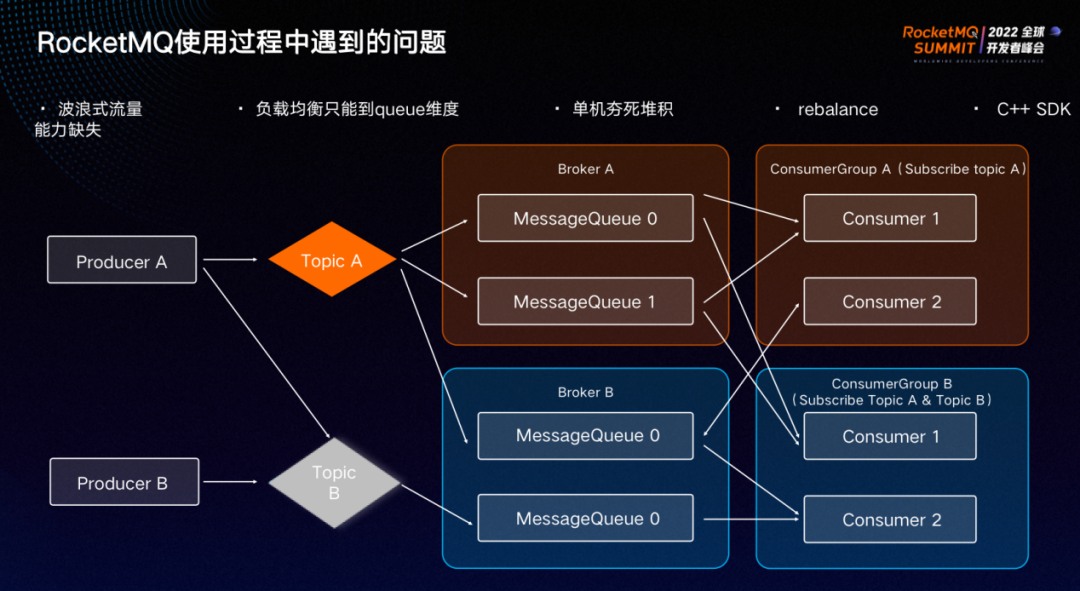
RocketMQ 的生产端策略如下:生产者获取到对应 topic 所有 broker 和 Queue 列表,然后轮询写入消息。消费者端也会获取到 topic 所有 broker 和Queue列表。另外,还需要要从 broker 中获取所有消费者 IP 列表进行排序,按照配置负载均衡,如哈希、一次性哈希等策略计算出自己应该订阅哪些 Queue。
上图中,ConsumerGroupA的Consumer1被分配到MessageQueue0和MessageQueue1,则它订阅MessageQueue0和MessageQueue1。
在RocketMQ的使用过程中,我们面临了诸多问题。
问题1:波浪式流量。
我们发现订阅消息集群滚动时,CPU 呈现波浪式飙升。经过深入排查发现,断网演练后进行网络恢复时,大量 producer 同时恢复工作,同时从第一个 broker 的第一个 Queue 开始写入消息,生产消息波浪式写入 RocketMQ ,进而导致消费者端出现波浪式流量。
最终,我们联系 RocketMQ 开发人员,调整了生产策略,每次生产者发现 broker 数量或状态发生变化时,都会随机选取一个初始Queue写入消息,以此解决问题。
另一个导致波浪式流量的问题是配置问题。排查线上问题时,从 broker 视角看,每个 broker 的消息量都是平均的,但 consumer 之间流量相差特别大。最终通过在 producer 侧尝试抓包得以定位到问题,是由于 producer 写入消息时超时率偏高。梳理配置后发现,是由于 producer 写入消息时配置超时太短,Rocket MQ 在写消息时会尝试多次,比如第一个 broker 写入失败后,将直接跳到下一个 broker 的第一个 Queue ,导致每个 broker 的第一个 Queue 消息量特别大,而靠后的 partition 几乎没有消息。
问题2:负载均衡只能到Queue维度,导致需要不时地关注 Queue 数量。
比如线上流量增长过快,需要进行扩容,而扩容后发现机器数大于 Queue 数量,导致无论怎么扩容都无法分担线上流量,最终只能联系 RocketMQ 运维人员调高 Queue 数量来解决。
虽然调高 Queue 数量能解决机器无法订阅的问题,但因为负载均衡策略只到 Queue 维度,负载始终无法均衡。从上图可以看到, consumer 1 订阅了两个 Queue 而 consumer 2 只订阅了一个 Queue。
问题3:单机夯死导致消息堆积,这也是负载均衡只能到 Queue 维度带来的副作用。
比如 Broker A 的 Queue 由 consumer 1 订阅,出现宿主机磁盘 IO 夯死但与 broker 之间的心跳依然正常,导致 Queue 消息长时间无法订阅进而影响用户接收消息。最终只能通过手动介入将对应机器下线来解决。
问题4:rebalance 。
Rocket MQ 的负载均衡由 client 自己计算,导致有机器异常或发布时,整个集群状态不稳定,时常会出现某些 Queue 有多个 consumer 订阅,而某些 Queue 在几十秒内没有 consumer 订阅的情况。因而导致线上发布的时候,出现消息乱序或对方已回消息但显示未读的情况。
问题5:C++ SDK 能力缺失。
钉钉的核心处理模块Receiver、processor 等应用都是通过 C++ 实现,而RocketMQ 的 C++ SDK 相比于 Java 存在较大缺失。经常出现内存泄漏或 CPU 飙高的情况,严重影响线上服务的稳定。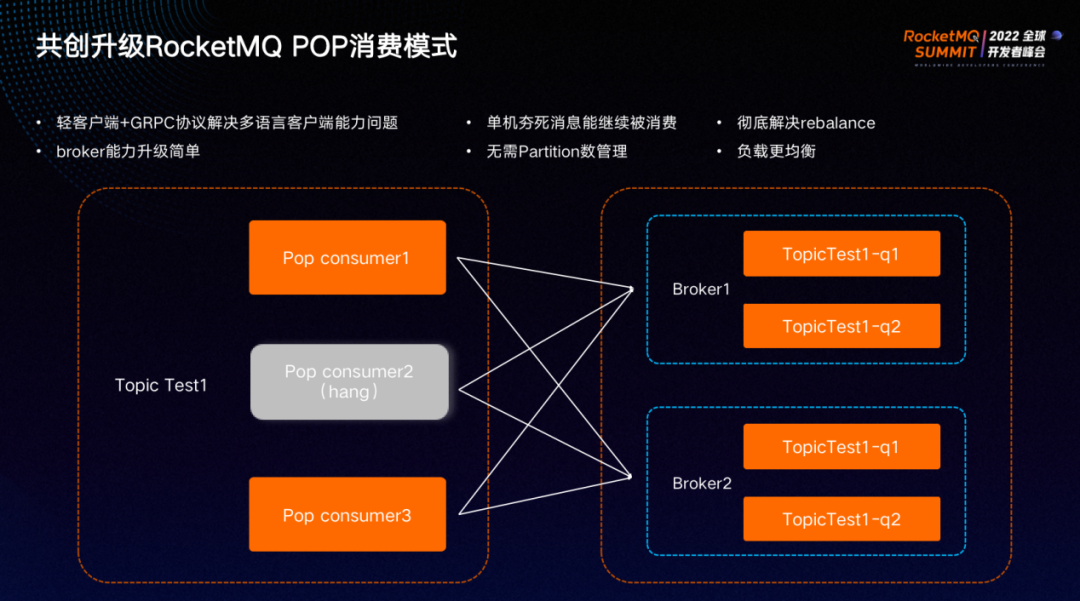
面对以上困扰,在经过过多次讨论和共创后,最终孵化出 RocketMQ 5.0 POP 消费模式。这是 RocketMQ 在实时系统里程碑式的升级,解决了大量实时系统使用 RocketMQ 过程中遇到的问题:
①Pop消费模式下,每一个 consumer 都会与所有 broker 建立长连接并具备消费能力,以 broker 维护整个消息订阅的负载均衡和位点。重云轻端的模式下,负载均衡、订阅消息、位点维护都在客户端完成,而新客户端只需做长链接管理、消息接收,并且通用 gRPC 协议,使得多语言比如 C++、Go、 Python 等语言客户端都能轻松实现,无需持续投入力去升级维护 SDK 。
②broker能力升级更简单。重云轻端很好地解决了客户端版本升级问题,客户端改动的可能性和频率大大降低。以往升级新特性或能力只能推动所有相关 SDK 应用进行升级发布,升级过程中还需考虑新老兼容等问题,工作量极大。而新模式只需升级 broker 即可完成工作。
③单机夯死消息能继续被消费。新模式下 consumer 和 broker 进行网状连接和消息订阅,由 broker 通过负载均衡策略平均分配消息给 consumer 进行消费,以往宕机夯死导致的 Queue 消息堆积问题也迎刃而解。如果 broker 发现 consumer 长时间没有进行消息 ACK ,则将不再对其投递消息,彻底解决单机夯死问题。
④无需关注partition数量。
⑤彻底解决rebalance。
⑥负载更均衡。通过新的订阅模式,不管上游流量如何偏移,只要不超过单个 broker 的容量上限,消费端都能实现真正意义上的负载均衡。
POP 模式消费模式已经在钉钉 IM 场景磨合得非常成熟,在对可用性、性能、时延方面要求非常高的钉钉 IM 系统证明了自己,也证明了不断升级的 RocketMQ 是即时通讯场景消息队列的不二选择。
本文作者:尹启绣 – 阿里云智能钉钉技术专家,Apache RocketMQ 社区。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。