
计算机视觉如今已大受欢迎,其应用也因时代的发展而有了惊人的增长。然而,在实时反馈上实施计算机视觉算法时仍存在许多差距。想象一个场景,您必须对闭路电视录像执行对象检测,而边缘设备的计算能力不足以运行深度学习推理代码,而且您也不想设置 IP 摄像头网络。虽然边缘推理被推荐用于时间紧迫的工作流,但如果我告诉你,即使是时间紧迫的工作流也可以在云上执行近乎实时的推理呢?
在本文中,我将说明如何使用 WebRTC 在远程实时流上逐帧执行计算机视觉等机器学习任务,但在此之前,让我们先深入了解一下什么是 WebRTC。
WebRTC 是一个低延迟框架,是谷歌的一个开源项目;也就是说,它是标准、协议和 JavaScript API 的组合,它们共同运行以提供实时通信。当我们说 “实时通信 “时,WebRTC 流媒体不仅能实现亚秒级传输,还能实现亚 500 毫秒级视频传输。它是目前延迟最低的流媒体技术,几乎可以实现瞬时流媒体传输。WebRTC 是作为专有技术的替代技术而诞生的,它是一种免费、开放的实时通信标准,也不需要插件。它通过一套标准化协议支持浏览器与浏览器之间的通信(以及人与人之间的实时流媒体)。因此,你去年在家工作期间参加的那些 “点击加入 “会议,很可能都是使用 WebRTC 进行的。
说了这么多,现在让我们动手实践一下吧!
下面的流程图解释了我们架构的工作流程。
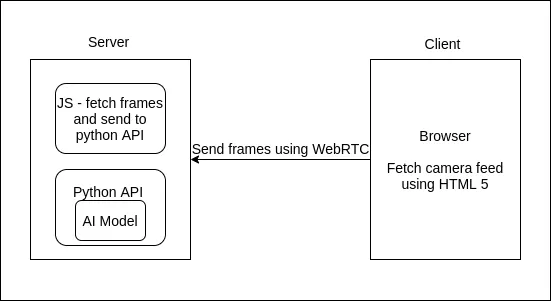

我们将首先处理后端部分,即 Python flask 应用程序。我们将创建一个 server.py 文件,在其中加载我们的模型,并定义一个函数来处理从前端接收到的帧。
我们将定义模型架构并加载训练好的模型权重,我建议这是加载 TensorFlow 模型的最佳方式,否则权重会被随机化。请不要从模型来判断我的人工智能技能。我在这里开发了一个非常简单的模型,因为人工智能模型不是本文的重点。

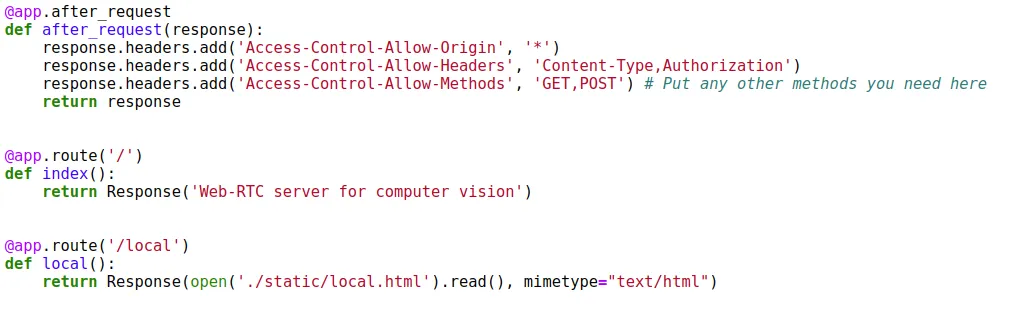
下一步是编写函数,逐个获取帧,对其进行预处理,并将其输入保存的模型以获得预测结果。我们将调整数组大小,扩大维度(用于批量大小),然后将其传递给模型。我们将在控制台打印模型输出。你可以用它将预测结果发送到目标源(可以使用 MQTT 或数据库查询)。目前我们没有任何要返回的内容,但我们仍将返回一个 json,以便我们的 JS 代码可以接收它并发送下一个发布请求。
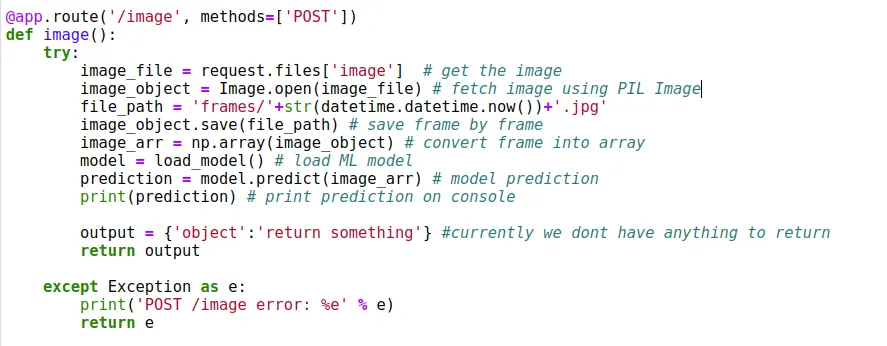
现在,让我们关注前端部分。在前端,我们必须执行以下操作:使用浏览器获取流、在画布上绘制每一帧、将其转换为 Blob(字节数组)并将其发送到 python flask API 进行预测。因此,为了捕获第一帧,我们将在 JavaScript 中编写一个 startFrameCapture 函数。在此,我们将根据视频尺寸定义画布大小。

现在我们将编写一个函数 postFile,它将递归调用我们的 python API 并将帧发送到该 API。

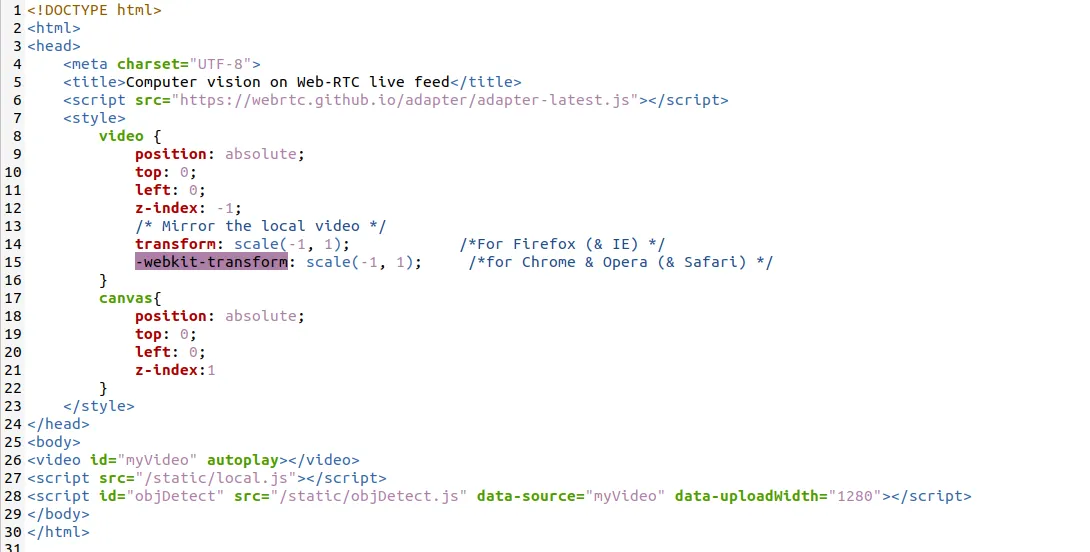
我们的索引页面仅包含一个简单的 JavaScript,用于使用 HTML 5 从浏览器本身捕获视频帧:
我们的教程到此结束。您可以在我的 GitHub 代码库中查看完整代码。不过,它不包含模型检查点,您肯定需要花时间来参加模型训练部分。其余部分可以从仓库中叉取。如果想减少延迟,可以减少 JS 代码中的上传宽度参数,但这会影响 feed 的清晰度和维度,因此请确保使用类似数据训练模型,以获得相关预测。
GitHub地址: https://github.com/darshil3011/webrtc_cv
作者:Darshil
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/webrtc/29668.html