
作者:Snowlyg
原文:https://www.lodan.me/zh-cn/posts/server-side-webrtc-noise-reduction-pion-ffmpeg-rnn/
WebRTC 服务端音频降噪实验应该先从一个很小的验证目标开始。它不是要证明服务端降噪应该替代 WebRTC 内置 3A,而是先回答一个更小的问题:Go 媒体服务能不能用 Pion 收到 Opus 音频,解码成 PCM,再交给 FFmpeg 的 RNN 降噪滤镜处理,并生成可验证的输出。
实验参考公开项目:snowlyg/webrtc_denoise_use_ffmpge。这是一个原型,不是可直接上线的 RTC 基础设施。
背景
WebRTC 已经内置了回声消除、噪声抑制、自动增益控制等音频处理能力。在设备质量和参数都可控的环境里,优先使用客户端 WebRTC 音频链路通常是正确选择。
但在真实落地时,设备侧不一定可控:
- 麦克风和扬声器可能随硬件批次变化。
- 声学结构变化可能快于软件发版周期。
- 供应商固件暴露出的音频行为可能不一致。
- 为每类设备深度调 WebRTC 参数会带来很高维护成本。
所以服务端降噪实验有价值。只要服务端可以收到音频、应用一个已知滤镜、并离线对比结果,就能更理性地判断它是否适合作为某些环境里的补充方案。
第一阶段的安全目标不是实时转发,而是基于文件的验证。
处理边界
服务端链路如下:
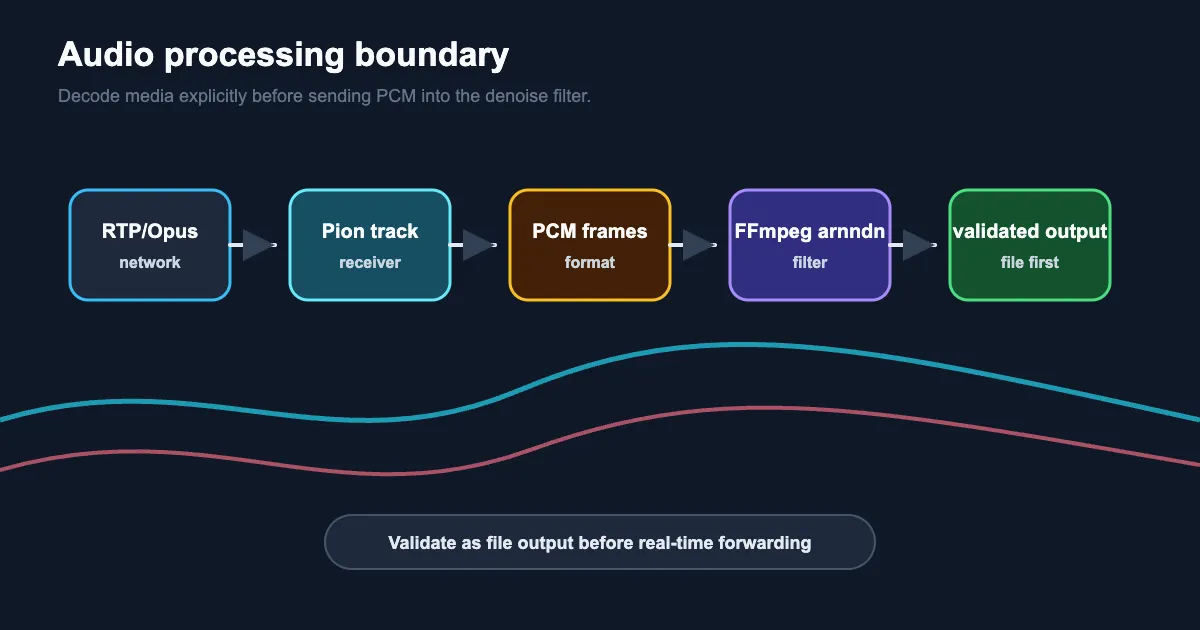

- 浏览器或客户端发送 WebRTC 音频 track。
- Pion 在
OnTrack中收到远端 track。 - 服务端通过
track.ReadRTP()读取 RTP 包。 - 将 Opus payload 解码成 PCM。
- 通过 stdin 将 PCM 写入 FFmpeg 进程。
- FFmpeg 使用
arnndn和 RNN 模型降噪。 - 把降噪后的结果写成文件,用来对比验证。
这里的边界很重要。RTP、Opus、PCM、FFmpeg raw audio input 是不同格式。格式写错也可能生成文件,但生成的不一定是可信音频。
最小实验
原型从 Pion save-to-disk 的思路开始:让浏览器页面连到 Go 进程,接收音视频,再把媒体写出来检查。
公开依赖包括:
当前原型使用 Pion v4 和 gopkg.in/hraban/opus.v2 解码器。
Opus 解码为 PCM
WebRTC 音频通常是 48 kHz Opus。示例代码显式保留采样率,并把 RTP payload 解码到 int16 PCM buffer。
var sampleRate = 48000
var channels = 2
var frameSizeMs = 60
frameSize := channels * frameSizeMs * sampleRate / 1000
pcm := make([]int16, frameSize)
dec, err := opus.NewDecoder(sampleRate, channels)
if err != nil {
return err
}
for {
rtpPacket, _, err := track.ReadRTP()
if err != nil {
return err
}
if rtpPacket == nil || len(rtpPacket.Payload) == 0 {
continue
}
n, err := dec.Decode(rtpPacket.Payload, pcm)
if err != nil {
continue
}
decoded := pcm[:n*channels]
buf := new(bytes.Buffer)
if err := binary.Write(buf, binary.LittleEndian, decoded); err != nil {
return err
}
if _, err := pipeWriter.Write(buf.Bytes()); err != nil {
return err
}
}
有两个细节不能忽略:
channels必须和实际解码假设一致。不要在协商出来是单声道时硬编码成立体声。- FFmpeg 输入格式必须和 PCM buffer 匹配。
int16PCM 对应s16le;如果用s32le读取int16字节,结果需要重新复核,不能直接当成可信结论。
运行 FFmpeg arnndn
FFmpeg 的 arnndn 滤镜可以用 RNN 模型做降噪。用于文件验证时,命令形态可以是:
cmd := exec.Command(
"ffmpeg",
"-v", "warning",
"-f", "s16le",
"-ac", "2",
"-ar", "48000",
"-i", "pipe:0",
"-af", "arnndn=m=models/cb.rnnn",
"-c:a", "libopus",
"-b:a", "64k",
"output_rnn.opus",
)
公开项目展示的是实验形态,包括把 PCM pipe 到 FFmpeg。真正进入生产链路前,raw audio 格式、声道数、frame duration、进程生命周期和错误处理都要显式化。
验证方式
第一轮我会先用文件验证:
- 采集未处理的 Opus 输出。
- 用 Audacity 之类的音频工具打开或解码检查。
- 通过 FFmpeg 链路生成
output_rnn.opus。 - 对比主观噪声、波形和频谱。
- 检查降噪的同时是否损伤了人声细节。

这个对比不能简化成“波形看起来更干净”。降噪也可能削弱弱语音、引入伪影,或者让通话听感变得不自然。所以听感测试仍然需要保留。
生产化边界
基于文件的原型不等于实时 WebRTC 媒体服务。
如果要实时使用,设计上必须回答:
- Opus 解码、FFmpeg stdin、滤镜处理、重新编码会引入多少缓冲?
- FFmpeg 是每通电话启动一次、每个参与者启动一次,还是作为 worker pool 管理?
- FFmpeg 退出、阻塞或处理跟不上时怎么办?
- CPU 和内存如何与信令服务隔离?
- 系统是把处理后的音频回传 WebRTC,还是只保存清理后的录音?
- 丢包、抖动、RTP timestamp、音视频同步如何保持?
我的默认做法是先把第一版保持为离线验证链路。只有在测过延迟和 CPU 成本后,才考虑推进到实时转发。
结论
当设备侧音频行为难以控制时,服务端降噪可能有价值,但它不是免费的能力。比较清晰的边界是:
- Pion 接收 WebRTC track。
- Opus 被解码成格式明确的 PCM。
- FFmpeg
arnndn应用 RNN 模型。 - 结果先以文件形式验证。
- 实时回传是另一个独立的工程决策。
这个原型最重要的价值不是某一条命令,而是把音频处理边界拆出来,让它可以被测量、被讨论,再决定是否进入生产基础设施。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。