
本文章将结合实例全面解析 WebRTC AEC 的基本框架和基本原理,一起探索回声消除的基本原理,技术难点以及优化方向。
回声的形成
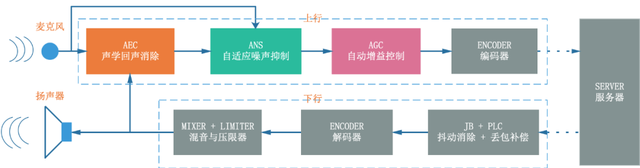
WebRTC 架构中上下行音频信号处理流程如图 1,音频 3A 主要集中在上行的发送端对发送信号依次进行回声消除、降噪以及音量均衡(这里只讨论 AEC 的处理流程,如果是 AECM 的处理流程 ANS 会前置),AGC 会作为压限器作用在接收端对即将播放的音频信号进行限幅。

那么回声是怎么形成的呢?
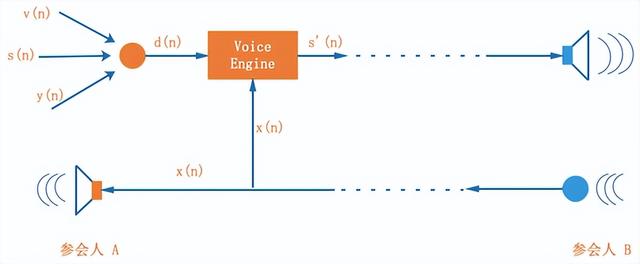
如图 2 所示,A、B 两人在通信的过程中,我们有如下定义:
x(n): 远端参考信号,即 A 端订阅的 B 端音频流,通常作为参考信号;
y(n): 回声信号,即扬声器播放信号 x(n) 后,被麦克风采集到的信号,此时经过房间混响以及麦克风采集的信号 y(n) 已经不能等同于信号 x(n) 了, 我们记线性叠加的部分为 y'(n), 非线性叠加的部分为 y”(n), y(n) = y'(n) + y”(n);
s(n): 麦克风采集的近端说话人的语音信号,即我们真正想提取并发送到远端的信号;
v(n):环境噪音,这部分信号会在 ANS 中被削弱;
d(n): 近端信号,即麦克风采集之后,3A 之前的原始信号,可以表示为:d(n) = s(n) + y(n) + v(n);
s'(n): 3A 之后的音频信号,即准备经过编码发送到对端的信号。
WebRTC 音频引擎能够拿到的已知信号只有近端信号 d(n) 和远端参考信号 x(n)。
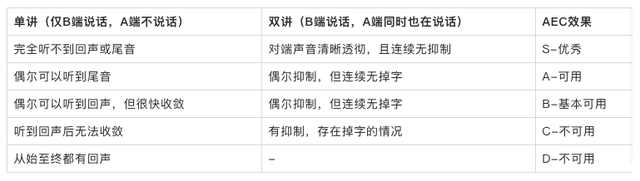
如果信号经过 A 端音频引擎得到 s'(n) 信号中依然残留信号 y(n),那么 B 端就能听到自己回声或残留的尾音(回声抑制不彻底留下的残留)。AEC 效果评估在实际情况中可以粗略分为如下几种情况(专业人员可根据应用场景、设备以及单双讲进一步细分):
回声消除的本质
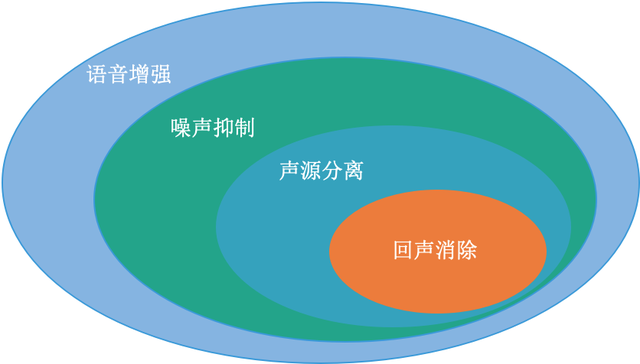
在解析 WebRTC AEC 架构之前,我们需要了解回声消除的本质是什么。音视频通话过程中,声音是传达信息的主要途径,因此从复杂的录音信号中,通过信号处理的手段使得我们要传递的信息:高保真、低延时、清晰可懂是一直以来追求的目标。在我看来,回声消除,噪声抑制和声源分离同属于语音增强的范畴,如果把噪声理解为广义的噪声三者之间的关系如下图:
噪声抑制需要准确估计出噪声信号,其中平稳噪声可以通过语音检测判别有话端与无话端的状态来动态更新噪声信号,进而参与降噪,常用的手段是基于谱减法(即在原始信号的基础上减去估计出来的噪声所占的成分)的一系列改进方法,其效果依赖于对噪声信号估计的准确性。对于非平稳噪声,目前用的较多的就是基于递归神经网络的深度学习方法,很多 Windows 设备上都内置了基于多麦克风阵列的降噪的算法。效果上,为了保证音质,噪声抑制允许噪声残留,只要比原始信号信噪比高,噪且听觉上失真无感知即可。
单声道的声源分离技术起源于传说中的鸡尾酒会效应,是指人的一种听力选择能力,在这种情况下,注意力集中在某一个人的谈话之中而忽略背景中其他的对话或噪音。该效应揭示了人类听觉系统中令人惊奇的能力,即我们可以在噪声中谈话。科学家们一直在致力于用技术手段从单声道录音中分离出各种成分,一直以来的难点,随着机器学习技术的应用,使得该技术慢慢变成了可能,但是较高的计算复杂度等原因,距离 RTC 这种低延时系统中的商用还是有一些距离。
噪声抑制与声源分离都是单源输入,只需要近端采集信号即可,傲娇的回声消除需要同时输入近端信号与远端参考信号。有同学会问已知了远端参考信号,为什么不能用噪声抑制方法处理呢,直接从频域减掉远端信号的频谱不就可以了吗?
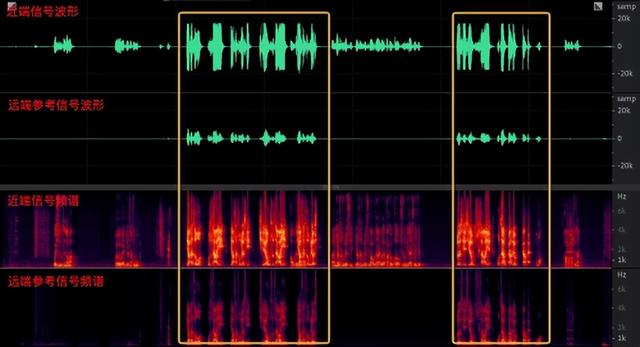
上图中第一行为近端信号 s(n),已经混合了近端人声和扬声器播放出来的远端信号,黄色框中已经标出对齐之后的远端信号,其语音表达的内容一致,但是频谱和幅度(明显经过扬声器放大之后声音能量很高)均不一致,意思就是:参考的远端信号与扬声器播放出来的远端信号已经是“貌合神离”了,与降噪的方法相结合也是不错的思路,但是直接套用降噪的方法显然会造成回声残留与双讲部分严重的抑制。接下来,我们来看看 WebRTC 科学家是怎么做的吧。
信号处理流程
WebRTC AEC 算法包含了延时调整策略,线性回声估计,非线性回声抑制 3 个部分。回声消除本质上更像是音源分离,我们期望从混合的近端信号中消除不需要的远端信号,保留近端人声发送到远端,但是 WebRTC 工程师们更倾向于将两个人交流的过程理解为一问一答的交替说话,存在远近端同时连续说话的情况并不多(即保单讲轻双讲)。
因此只需要区分远近端说话区域就可以通过一些手段消除绝大多数远端回声,至于双讲恢复能力 WebRTC AEC 算法提供了 {kAecNlpConservative, kAecNlpModerate, kAecNlpAggressive} 3 个模式,由低到高依次代表不同的抑制程度,远近端信号处理流程如图 4:
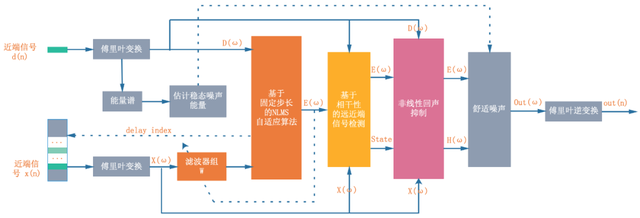
NLMS 自适应算法(上图中橙色部分)的运用旨在尽可能地消除信号 d(n) 中的线性部分回声,而残留的非线性回声信号会在非线性滤波(上图中紫色部分)部分中被消除,这两个模块是 Webrtc AEC 的核心模块。模块前后依赖,现实场景中远端信号 x(n) 由扬声器播放出来在被麦克风采集的过程中,同时包含了回声 y(n) 与近端信号 x(n) 的线性叠加和非线性叠加:需要消除线性回声的目的是为了增大近端信号 X(ω) 与滤波结果 E(ω) 之间的差异,计算相干性时差异就越大(近端信号接近 1,而远端信号部分越接近 0),更容易通过门限直接区分近端帧与远端帧。非线性滤波部分中只需要根据检测的帧类型,调节抑制系数,滤波消除回声即可。下面我们结合实例分析这套架构中的线性部分与非线性分。
线性滤波
线性回声 y'(n) 可以理解为是远端参考信号 x(n) 经过房间冲击响应之后的结果,线性滤波的本质也就是在估计一组滤波器使得 y'(n) 尽可能的等于 x(n),通过统计滤波器组的最大幅值位置 index 找到与之对齐远端信号帧,该帧数据会参与相干性计算等后续模块。
需要注意的是,如果 index 在滤波器阶数两端疯狂试探,只能说明当前给到线性部分的远近端延时较小或过大,此时滤波器效果是不稳定的,需要借助固定延时调整或大延时调整使 index 处于一个比较理想的位置。线性部分算法是可以看作是一个固定步长的 NLMS 算法,具体细节大家可以结合源码走读,本节重点讲解线型滤波在整个框架中的作用。
从个人理解来看,线性部分的目的就是最大程度的消除线性回声,为远近端帧判别的时候,最大程度地保证了信号之间的相干值( 0~1 之间,值越大相干性越大)的可靠性。
我们记消除线性回声之后的信号为估计的回声信号 e(n),e(n) = s(n) + y”(n) + v(n),其中 y”(n) 为非线性回声信号,记 y'(n) 为线性回声,y(n) = y'(n) + y”(n)。相干性的计算 (Matlab代码):
% WebRtcAec_UpdateCoherenceSpectra →_→ UpdateCoherenceSpectra
Sd = Sd * ptrGCoh(1) + abs(wined_fft_near) .* abs(wined_fft_near)*ptrGCoh(2);
Se = Se * ptrGCoh(1) + abs(wined_fft_echo) .* abs(wined_fft_echo)*ptrGCoh(2);
Sx = Sx * ptrGCoh(1) + max(abs(wined_fft_far) .* abs(wined_fft_far),ones(N+1,1)*MinFarendPSD)*ptrGCoh(2);
Sde = Sde * ptrGCoh(1) + (wined_fft_near .* conj(wined_fft_echo)) *ptrGCoh(2);
Sxd = Sxd * ptrGCoh(1) + (wined_fft_near .* conj(wined_fft_far)) *ptrGCoh(2);
% WebRtcAec_ComputeCoherence →_→ ComputeCoherence
cohde = (abs(Sde).*abs(Sde))./(Sd.*Se + 1.0e-10);
cohdx = (abs(Sxd).*abs(Sxd))./(Sx.*Sd + 1.0e-10);- 两个实验
(1)计算近端信号 d(n) 与远端参考信号 x(n) 的相关性 cohdx,理论上远端回声信号的相干性应该更接近 0(为了方便后续对比,WebRTC 做了反向处理: 1 – cohdx),如图 5(a),第一行为计算近端信号 d(n),第二行为远端参考信号 x(n),第三行为二者相干性曲线: 1 – cohdx,会发现回声部分相干值有明显起伏,最大值有0.7,近端部分整体接近 1.0,但是有持续波动,如果想通过一条固定的门限去区分远近端帧,会存在不同程度的误判,反映到听感上就是回声(远端判断成近端)或丢字(近端判断为远端)。
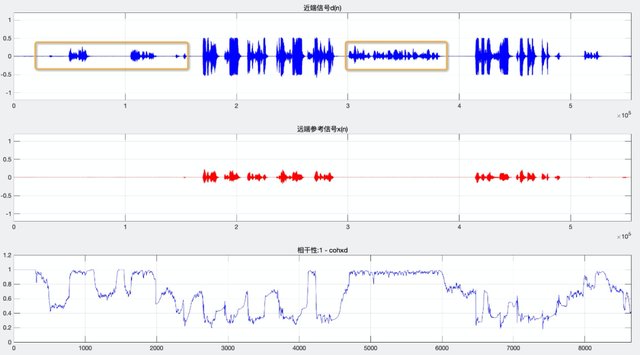
(a) 近端信号与远端参考信号的相干性
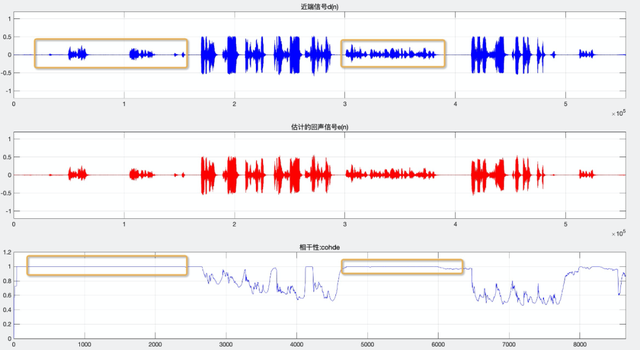
(b) 近端信号与估计的回声信号的相干性
图 5 信号的相干性
(2)计算近端信号 d(n) 与估计的回声信号 e(n) 的相干性,如图 5(b),第二行为估计的回声信号 e(n),第三行为二者相干性 cohde,很明显近端的部分几乎全部逼近 1.0,WebRTC 用比较严格的门限(>=0.98)即可将区分绝大部分近端帧,且误判的概率比较小,WebRTC 工程师设置如此严格的门限想必是宁可牺牲一部分双讲效果,也不愿意接受回声残留。
从图 5 可以体会到,线性滤波之后可以进一步凸显远端参考信号 x(n) 与估计的回声信号 e(n) 的差异,从而提高远近端帧状态的判决的可靠性。
- 存在的问题与改进
理想情况下,远端信号从扬声器播放出来没有非线性失真,那么 e(n) = s(n) + v(n),但实际情况下 e(n)与d(n) 很像,只是远端区域有一些幅度上的变化,说明 WebRTC AEC 线性部分在这个 case 中表现不佳,如图 6(a) 从频谱看低频段明显削弱,但中高频部分几乎没变。而利用变步长的双滤波器结构的结果会非常明显,如图 6(b) 所示无论是时域波形和频谱与近端信号 x(n) 都有很大差异,目前 aec3 和 speex 中都采用这种结构,可见 WebRTC AEC 中线性部分还有很大的优化空间。
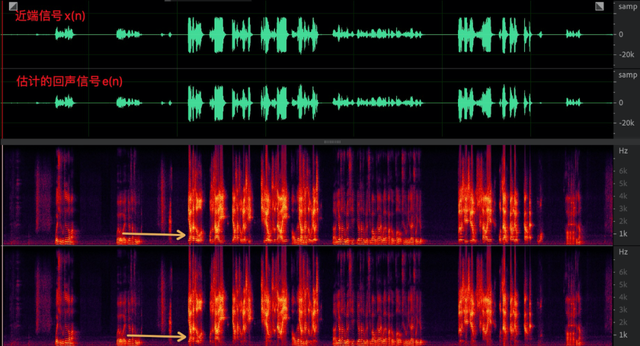
(a) WebRTC AEC 线性部分输出
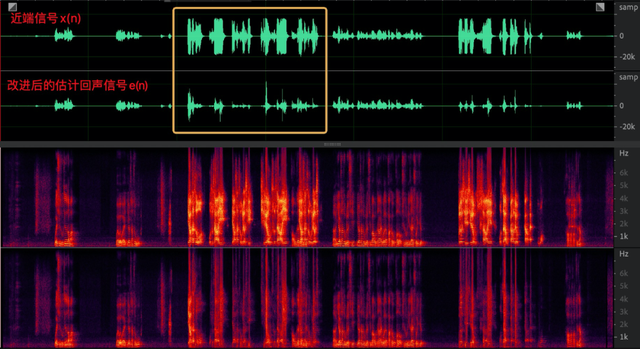
(b) 改进的线性部分输出
图 6 近端信号与估计的回声信号的对比
如何衡量改进的线性部分效果?
这里我们对比了现有的固定步长的 NLMS 和变步长的 NLMS,近端信号 d(n) 为加混响的远端参考信号 x(n) + 近端语音信号 s(n)。理论上 NLMS 在处理这种纯线性叠加的信号时,可以不用非线性部分出马,直接干掉远端回声信号。图 7(a) 第一行为近端信号 d(n),第二列为远端参考信号 x(n),线性部分输出结果,黄色框中为远端信号。WebRTC AEC 中采用固定步长的 NLMS 算法收敛较慢,有些许回声残留。但是变步长的 NLMS 收敛较快,回声抑制相对好一些,如图 7(b)。
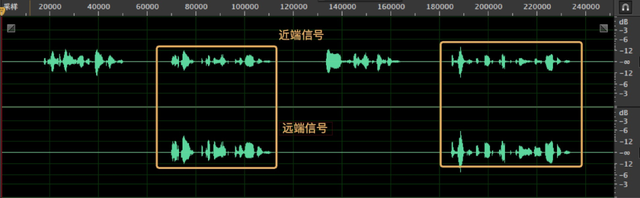
(a)固定步长的 NLMS
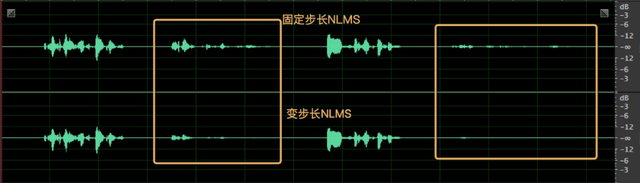
(b) 变步长的 NLMS
图 7 两种 NLMS 算法的效果对比
- 线性滤波器参数设置
#define FRAME_LEN 80
#define PART_LEN 64
enum { kExtendedNumPartitions = 32 };
static const int kNormalNumPartitions = 12;FRAME_LEN 为每次传给音频 3A 模块的数据的长度,默认为 80 个采样点,由于 WebRTC AEC 采用了 128 点 FFT,内部拼帧逻辑会取出 PART_LEN = 64 个样本点与前一帧剩余数据连接成128点做 FFT,剩余的 16 点遗留到下一次,因此实际每次处理 PART_LEN 个样本点(4ms 数据)。
默认滤波器阶数仅为 kNormalNumPartitions = 12 个,能够覆盖的数据范围为 kNormalNumPartitions * 4ms = 48ms,如果打开扩展滤波器模式(设置 extended_filter_enabled为true),覆盖数据范围为 kNormalNumPartitions * 4ms = 132ms。随着芯片处理能力的提升,默认会打开这个扩展滤波器模式,甚至扩展为更高的阶数,以此来应对市面上绝大多数的移动设备。另外,线性滤波器虽然不具备调整延时的能力,但可以通过估计的 index 衡量当前信号的延时状态,范围为 [0, kNormalNumPartitions],如果 index 处于作用域两端,说明真实延时过小或过大,会影响线性回声估计的效果,严重的会带来回声,此时需要结合固定延时与大延时检测来修正。
非线性滤波
非线性部分一共做了两件事,就是想尽千方百计干掉远端信号。
(1) 根据线性部分提供的估计的回声信号,计算信号间的相干性,判别远近端帧状态。
(2) 调整抑制系数,计算非线性滤波参数。
非线性滤波抑制系数为 hNl,大致表征着估计的回声信号 e(n) 中,期望的近端成分与残留的非线性回声信号 y”(n) 在不同频带上的能量比,hNl 是与相干值是一致的,范围是 [0,1.0],通过图 5(b) 可以看出需要消除的远端部分幅度值也普遍在 0.5 左右,如果直接使用 hNl 滤波会导致大量的回声残留。
因此 WebRTC 工程师对 hNl 做了如下尺度变换,over_drive 与 nlp_mode 相关,代表不同的抑制激进程度,drive_curve 是一条单调递增的凸曲线,范围 [1.0, 2.0]。由于中高频的尾音在听感上比较明显,所以他们设计了这样的抑制曲线来抑制高频尾音。我们记尺度变换的 α = over_drive_scaling * drive_curve,如果设置 nlp_mode = kAecNlpAggressive,α 大约会在 30 左右。
% matlab代码如下:
over_drive = min_override(nlp_mode+1);
if (over_drive < over_drive_scaling)
over_drive_scaling = 0.99*over_drive_scaling + 0.01*over_drive; % default 0.99 0.01
else
over_drive_scaling = 0.9*over_drive_scaling + 0.1*over_drive; % default 0.9 0.1
end
% WebRtcAec_Overdrive →_→ Overdrive
hNl(index) = weight_curve(index).*hNlFb + (1-weight_curve(index)).* hNl(index);
hNl = hNl.^(over_drive_scaling * drive_curve);
% WebRtcAec_Suppress →_→ Suppress
wined_fft_echo = wined_fft_echo .*hNl;
wined_fft_echo = conj(wined_fft_echo);
如果当前帧为近端帧(即 echo_state = false),假设第 k 个频带 hNl(k) = 0.99994 ,hNl(k) = hNl(k)^α = 0.99994 ^ 30 = 0.9982,即使滤波后的损失听感上几乎无感知。如图 8(a),hNl 经过 α 调制之后,幅值依然很接近 1.0。
如果当前帧为远端帧(即 echo_state = true),假设第 k 个频带 hNl(k) = 0.6676 ,hNl(k) = hNl(k)^α = 0.6676 ^ 30 = 5.4386e-06,滤波后远端能量小到基本听不到了。如图 8(b),hNl 经过 α 调制之后,基本接近 0。
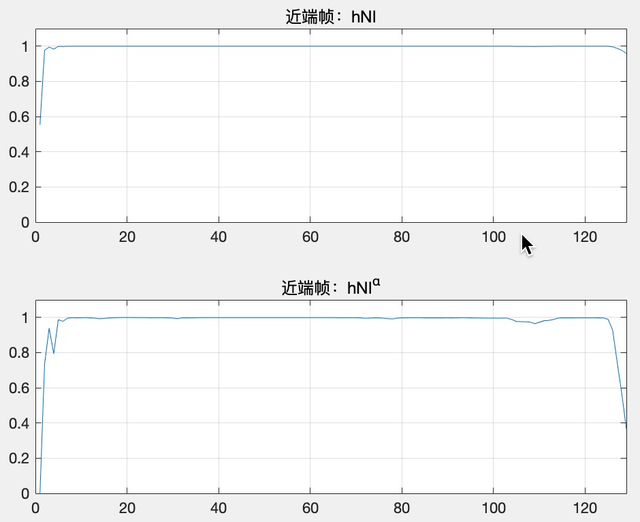
(a)近端帧对应的抑制系数
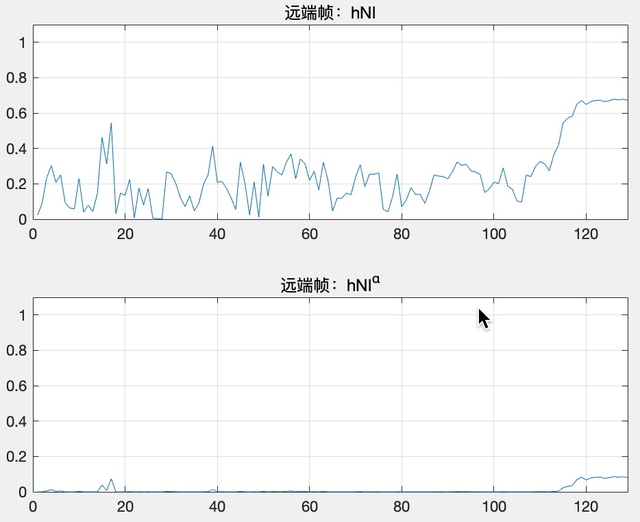
(b)远端帧对应的抑制系数
图 8 远近端信号抑制系数在调制前后的变化
经过如上对比,为了保证经过调制之后近端期望信号失真最小,远端回声可以被抑制到不可听,WebRTC AEC 才在远近端帧状态判断的的模块中设置了如此严格的门限。
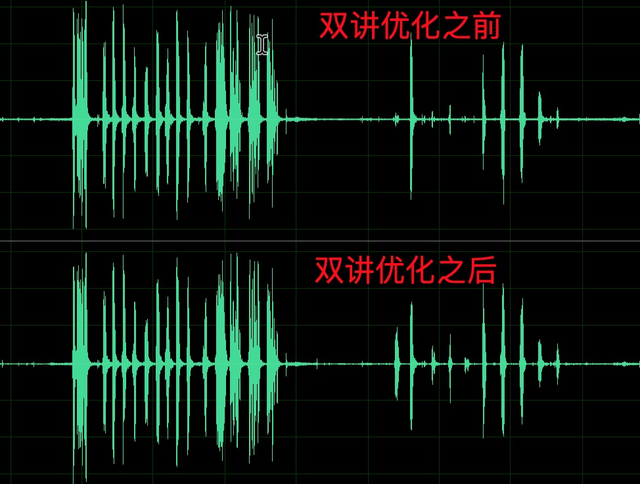
另外,调整系数 α 过于严格的情况下会带来双讲的抑制,如图 9 第 1 行,近端说话人声音明显丢失,通过调整 α 后得以恢复,如第 2 行所示。因此如果在 WebRTC AEC 现有策略上优化 α 估计,可以缓解双讲抑制严重的问题。
延时调整策略
回声消除的效果与远近端数据延时强相关,调整不当会带来算法不可用的风险。在远近端数据进入线性部分之前,一定要保证延时在设计的滤波器阶数范围内,不然延时过大超出了线性滤波器估计的范围或调整过当导致远近端非因果都会造成无法收敛的回声。先科普两个问题:
(1)为什么会存在延时?
首先近端信号 d(n) 中的回声是扬声器播放远端参考 x(n),又被麦克风采集到的形成的,也就意味着在近端数据还未采集进来之前,远端数据缓冲区中已经躺着 N 帧 x(n)了,这个天然的延时可以约等于音频信号从准备渲染到被麦克风采集到的时间,不同设备这个延时是不等的。苹果设备延时较小,基本在 120ms 左右,Android 设备普遍在 200ms 左右,低端机型上会有 300ms 左右甚至以上。
(2)远近端非因果为什么会导致回声?
从(1)中可以认为,正常情况下当前帧近端信号为了找到与之对齐的远端信号,必须在远端缓冲区沿着写指针向前查找。如果此时设备采集丢数据,远端数据会迅速消耗,导致新来的近端帧在向前查找时,已经找不到与之对齐的远端参考帧了,会导致后续各模块工作异常。如图 10(a) 表示正常延时情况,(b) 表示非因果。
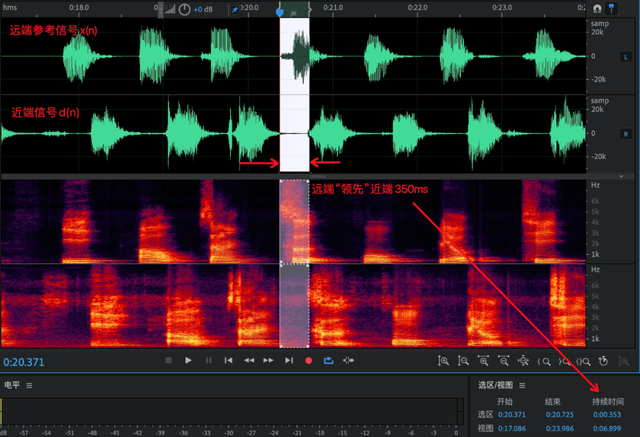
(a)远近端正常延时
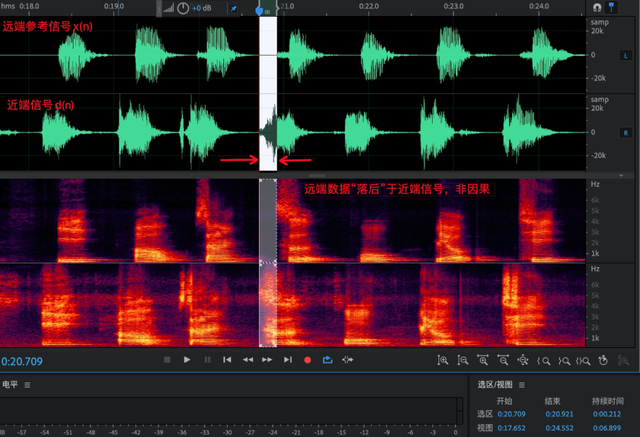
(b)远近端非因果
图10 正常远近端延时与非因果
WebRTC AEC 中的延时调整策略关键而且复杂,涉及到固定延时调整,大延时检测,以及线性滤波器延时估计。三者的关系如下:
① 固定延时调整只会发生在开始 AEC 算法开始处理之前,而且仅调整一次。如会议盒子等固定的硬件设备延时基本是固定的,可以通过直接减去固定的延时的方法缩小延时估计范围,使之快速来到滤波器覆盖的延时范围之内。
下面结合代码来看看固定延时的调整过程:
int32_t WebRtcAec_Process(void* aecInst,constint32_t WebRtcAec_Process(void* aecInst,
const float* const* nearend,
size_t num_bands,
float* const* out,
size_t nrOfSamples,
int16_t reported_delay_ms,
int32_t skew);WebRtcAec_Process 接口如上,参数 reported_delay_ms 为当前设备需要调整延时的目标值。如某 Android 设备固定延时为 400ms 左右,400ms 已经超出滤波器覆盖的延时范围,至少需要调整 300ms 延时,才能满足回声消除没有回声的要求。固定延时调整在 WebRTC AEC 算法开始之初仅作用一次:
if (self->startup_phase) {
int startup_size_ms = reported_delay_ms < kFixedDelayMs ? kFixedDelayMs : reported_delay_ms;
int target_delay = startup_size_ms * self->rate_factor * 8;
int overhead_elements = (WebRtcAec_system_delay_aliyun(self->aec) - target_delay) / PART_LEN;
printf("[audio] target_delay = %d, startup_size_ms = %d, self->rate_factor = %d, sysdelay = %d, overhead_elements = %dn", target_delay, startup_size_ms, self->rate_factor, WebRtcAec_system_delay(self->aec), overhead_elements);
WebRtcAec_AdjustFarendBufferSizeAndSystemDelay_aliyun(self->aec, overhead_elements);
self->startup_phase = 0;
}为什么 target_delay 是这么计算?
int target_delay = startup_size_ms * self->rate_factor * 8;
startup_size_ms 其实就是设置下去的 reported_delay_ms,这一步将计算时间毫秒转化为样本点数。16000hz 采样中,10ms 表示 160 个样本点,因此 target_delay 实际就是需要调整的目标样本点数(aecpc->rate_factor = aecpc->splitSampFreq / 8000 = 2)。
我们用 330ms 延时的数据测试:
如果设置默认延时为 240ms,overhead_elements 第一次被调整了 -60 个 block,负值表示向前查找,正好为 60 * 4 = 240ms,之后线性滤波器固定 index = 24,表示 24 * 4 = 96ms 延时,二者之和约等于 330ms。日志打印如下:

② 大延时检测是基于远近端数据相似性在远端大缓存中查找最相似的帧的过程,其算法原理有点类似音频指纹中特征匹配的思想。大延时调整的能力是对固定延时调整与线型滤波器能力的补充,使用它的时候需要比较慎重,需要控制调整的频率,以及控制造成非因果的风险。
WebRTC AEC 算法中开辟了可存储 250 个 block 大缓冲区,每个 block 的长度 PART_LEN = 64 个样本点,能够保存最新的 1s 的数据,这也是理论上的大延时能够估计的范围,绝对够用了。
static const size_t kBufferSizeBlocks = 250;
buffer_ = WebRtc_CreateBuffer(kBufferSizeBlocks, sizeof(float) * PART_LEN);
aec->delay_agnostic_enabled = 1;>delay_agnostic_enabled = 1;我们用 610ms 延时的数据测试(启用大延时调整需要设置 delay_agnostic_enabled = 1):
我们还是设置默认延时为 240ms,刚开始还是调整了 -60 个 block,随后大延时调整接入之后有调整了 -88 个 block,一共调整(60 + 88) * 4 = 592ms,之后线性滤波器固定 index = 4,表示最后剩余延时剩余 16ms,符合预期。


③ 线性滤波器延时估计是固定延时调整和大延时调整之后,滤波器对当前远近端延时的最直接反馈。前两者调整不当会造成延时过小甚至非因果,或延时过大超出滤波器覆盖能力,导致无法收敛的回声。因此前两者在调整的过程中需要结合滤波器的能力,确保剩余延时在滤波器能够覆盖的范围之内,即使延时小范围抖动,线性部分也能自适应调整。
总结与优化方向
WebRTC AEC 存在的问题:
(1)线性部分收敛时间较慢,固定步长的 NLMS 算法对线性部分回声的估计欠佳;
(2)线性部分滤波器阶数默认为 32 阶,默认覆盖延时 132ms,对移动端延时较大设备支持不是很好,大延时检测部分介入较慢,且存在误调导致非因果回声的风险;
(3)基于相干性的帧状态依赖严格的固定门限,存在一定程度的误判,如果再去指导非线性部分抑制系数的调节,会带来比较严重的双讲抑制。
优化的方向:
(1)算法上可以通过学习 speex 和 AEC3 的线性部分,改善当前线性滤波效果;
(2)算法上可以优化延时调整策略,工程上可以新增参数配置下发等工程手段解决一些设备的延时问题;
(3)另外,有一些新的思路也是值得我们尝试的,如开头提到的,既然回声也可以是视为噪声,那么能否用降噪的思路做回声消除呢,答案是可以的。
作者:珞神
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。