
作者:Pavel Han
原文:https://mp.weixin.qq.com/s/ebeuER9vFlxNlf1fLfdE9Q
本文对 WebRTC 音频处理模块 APM(Audio Processing Module)中针对回音消除问题的AECM解决方案进行技术理论和工作流程上的大致总结,为后续在产品中通过设置AECM模块的工作参数来实现良好的回音消除效果打好基础。
从WebRTC APM模块的历史来讲,其AEC实现主要包含有四个版本:Build-in AEC,AECM,AEC(旧版本),AEC3。其中Build-in AEC和AEC(旧)在WebRTC代码中已经被废弃,如果硬件平台的处理能力不是瓶颈的话,始终建议使用AEC3,性能最优;AECM则仅建议用于处理性能比较差的低端移动和Iot设备上,其对回声的抑制能力比较有限,但胜在对计算资源的要求比较低。
正是因为AEC3算法对于硬件平台的计算资源要求较高,所以在一些计算资源有限的IoT领域仍然广泛采用了AECM来实现双向对讲下的回音消除功能。
回声产生的原因以及回声消除算法的工作原理
在包含有语音双向对讲的产品应用领域之中,通信双方的语音如何交互、如何形成回声以及如何利用AEC来实现回声消除的整体工作流程图如下图所示:
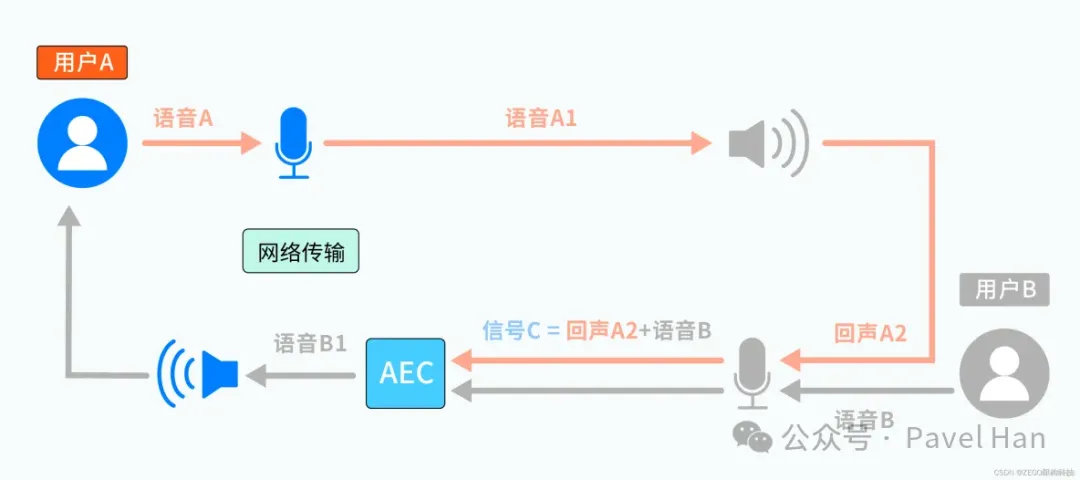

可以看到,回声产生的根源就在于远端用户A的语音信号,在用户B的扬声器上播放出来以后,在用户B的麦克风里面重新被采集,跟用户B自己的语音信号叠加在一起,再传输给A以后,用户A就能清楚地听到自己之前的语音被叠加后重新传回来。
而也正如上图所展示出来的,回音消除功能的实现,就是要想办法把用户B端麦克风所采集的混合信号C(同时包含用户B自己的近端语音信号,以及用户A语音信号在用户B扬声器上播放所产生的回声信号A2)中所包含的回声信号识别出来并消除掉。
那么问题是,用户B的麦克风所采集的信号是混合信号,如何能够从其中准确的识别出来回声信号并消除掉呢?
总体上讲,大多数回声消除的基本原理,都是以扬声器信号与由它产生的多路径回声的相关性为基础,建立远端信号的语音模型,利用它对回声进行估计,并不断修改滤波器的系数,使估计值更加逼近真实的回声,然后将回声估计值从麦克风采集的混合信号中减去,从而达到消除回声的目的。
如下图所示,进行回音消除处理时,首先要基于接收到的远端语音信号序列,在自适应滤波器中产生一个估计出来的回声模型序列,然后从麦克风采集的混合信号中减去这个回声模型序列,就可以得到回声消除处理以后的语音序列。同时根据回音消除的效果,动态更新自适应滤波器的参数,使其估计出来的回声模型更准确,从而达到更好的回声消除效果。
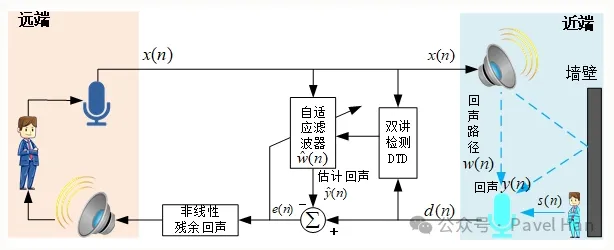
WebRTC中的AECM算法大体上也是与以上相同的工作逻辑。
AECM回音消除的模块构成和总体工作流程
AECM是WebRTC中为低算力移动设备所设计的轻量级回声消除方案,其核心思想是通过时域子带处理 + 简化的自适应滤波 + 后置非线性抑制的完整流程,在有限计算资源下实现较为基础的回声消除功能。
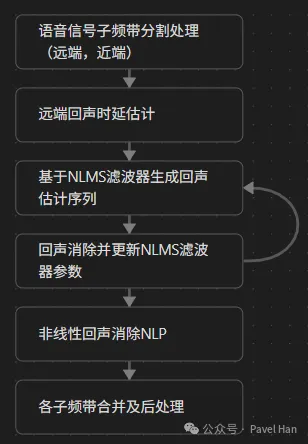
大体上讲,AECM实现回声消除的完整流程可以划分为以下几个模块:
• 子带分割与结合模块
• 回声延迟时间估计模块
• NLMS滤波器及回声消除模块
• 非线性回声消除NLP模块
• 双讲检测模块
AECM算法具体的执行流程大致如下:
1. 语音信号分带处理
把语音信号分割为多个独立的子频带,并且在后续的回音消除处理完成后再合成为全频带的语音信号,其目的是计算各个子频带的能量,仅处理能量较高的子带,以降低计算复杂度及其所需要的资源。
在具体的实现上,对近端采集的混合信号和收到的远端语音信号序列,分别通过多相滤波器组(Polyphase Filterbank),分割为多个子带信号,每个子带覆盖一定的频宽带宽(例如子带0: 0-500Hz,子带1: 500-1000Hz,依此类推)。然后计算各个子带的能量,仅对其能量大于动态阈值(根据环境噪声自适应调整)的子带进行后续的自适应滤波(NLMS)和非线性抑制(NLP)处理以减少计算量。
所以经过分带处理后,语音信号就被分割为多个独立子频带的语音信号序列,后续分别各自处理。
2. 远端回声时延估计
AECM 的回声时延(即远端信号到达近端的传播时间)估计模块通过二进制频谱异或法来实现低复杂度的实时估算。
大致的执行流程是,对远端信号序列和近端采集的混合信号序列的每个子带的频谱幅度量化为1-bit(0或1),表示能量是否超过一定的阈值,这样就生成了两个二进制频谱序列。然后对两个二值化频谱历史数据序列逐帧进行异或(XOR)运算,统计不同延迟偏移下的匹配度,选择匹配度最高(异或结果中 0 的占比最大)的延迟时间作为当前延迟估计。
3. 基于NLMS滤波器生成估计回声序列
每个独立自带的语音信号序列,都对应一个NLMS滤波器。NLMS滤波器的作用,主要就是基于收到的远端语音信号序列,以及前一阶段估计出来的时延,产生一组回声估计信号序列,用于执行回声消除。
NLMS滤波器所产生的回声估计信号序列有多逼近于实际在近端麦克风所采集到的回升信号,就决定了回声消除的效果有多好。而NLMS滤波器所生成的回音估计信号,则依赖于远端语音信号序列、前一阶段的时延以及根据回声消除效果动态调整的滤波器参数。
4. 回声消除(残差计算)以及更新NLMS滤波器参数
NLMS滤波器生成回声估计序列后,就与近端麦克风所采集的混合信号序列执行回音消除操作,回声消除后的结果就是经过NLMS滤波器回声消除过滤掉线性回声的声音信号序列。
以上回音消除的过程中,如果近端没有讲话的情况下,就可以认为是回声残差。此时以这个回声残差信号作为反馈信号,动态调整NLMS滤波器的参数。
- 实际上,也就是仅在非双讲状态下,才会去更新NLMS滤波器的参数。
5. 非线性回声消除NLP
以上经过NLMS自适应滤波器所产生的估计回声序列过滤后的语音信号序列,已经消除了大部分的线性回声。这个步骤则专门用于抑制自适应滤波未消除的非线性残留回声。
NLP模块计算各个子频带序列的残留回声能量,并与阈值比较,动态计算抑制增益对残留回声进行额外抑制。残留回声的能量越大,应使用越小的增益对其进行抑制。
6. 子带合成和后处理
如前所述,前面的所有处理流程中,都把近端采集的混合信号和收到的远端语音信号序列使用多相滤波器组分割为多个子带信号,并对各个子带序列进行的独立处理。那么在实际输出之前,就需要再通过合成滤波器组合并为全频带时域信号。此外,该环节还会在静音段(无近端语音端)适当添加低幅度白噪声,以避免听觉不适。
此外,为了支撑以上流程的运行,还有一个独立的双讲检测模块。该模块用于检测当前近端麦克风是否有采集到近端的语音,并且在有近端语言以及远端语音的能量超过一定阈值的时候,才会去动态更新NLMS自适应滤波器的参数,避免近端语音影响滤波器的参数计算。
双讲检测的逻辑,就是比较计算回音消除结果的残差序列与估计回声序列之间的相关性。相关性越高,说明残差中主要是残留回声,而非近端的语音;而相关性越低,说明回音消除的结果(残差)中包含了较多与回声无关的成分(即近端语音或突发噪声)。
参考资料
- LearningWebRTC: AECM
- 基于多相滤波器组的非线性回声抵消
- WebRTC中AECM算法简介-CSDN博客
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。