
以往的自适应 FEC 都简单地将历史网络模式作为对未来模式的预测,而忽略了历史与未来之间可能存在的复杂关系。为了充分利用历史和未来之间的上下文关系,我们提出了一种新的 FEC 算法 DeepRS,它利用深度神经网络预测网络丢包,动态调整冗余率,显着提高 FEC 方案的效率。
作者:Sheng Cheng, Han Hu, Xinggong Zhang 等
来源:ISCAS 2020
论文题目:DeepRS: Deep-learning Based Network-Adaptive FEC for Real-Time Video Communications
论文链接:https://ieeexplore.ieee.org/document/9180974
内容整理:李江龙
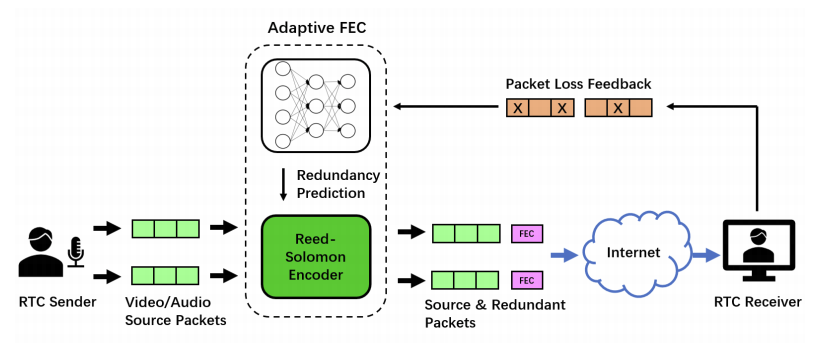
基于深度学习的自适应 FEC框架如图1所示。DeepRS根据接收方的反馈预测数据包丢失,确定冗余数据包的数量,并应用 RS 编码算法对该视频块进行编码。为了充分利用网络丢失模式的上下文相关性,我们提出了一种基于长短期记忆(LSTM)网络的丢包预测方法。大量仿真实验和真实互联网痕迹表明,在总冗余率固定的情况下,DeepRS 的恢复率比对比算法高 70%,并且 DeepRS 可以在任何网络动态下实现自适应 FEC 冗余。

系统设计
DeepRS由两个主要模块组成,LSTM网络和RS编码器。在编码开始时,LSTM 模块从接收方收集信息后预测传入的网络丢包,然后 RS 编码器根据 LSTM 的结果生成冗余数据包。
DeepRS 丢包预测
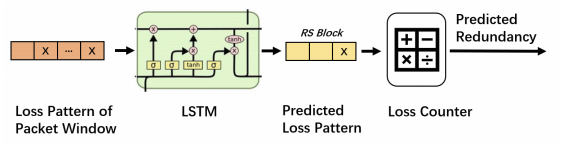
LSTM模块的结构如图 2 所示。LSTM以历史丢失模式为输入,输出预测的丢包模式。在训练步骤中,收集了大量的历史丢包序列,并将其拆分为包含 6 个数据包的块。数据集的每个样本包含 5 个块的丢包模式作为输入,下一个块的丢失模式作为标签。在参考阶段,LSTM 模块根据来自接收器的 5 个块的反馈来预测传入编码块的丢包模式。
不可预测的损失模式
一般的LSTM网络用于学习样本向量到目标向量的映射,输出形式不适合解决丢包问题。根据网络状况,可以通过学习历史模式来预测传入块中丢失的数据包数量,但由于随机性,很难准确确定每个数据包的丢失状态。然而,从 FEC 的角度来看,实际上我们不需要准确知道每个数据包的丢失状态。这个特性使我们能够避免直接预测损失模式的困难。我们使用丢失计数器根据丢失模式作为最终输出来预测每个块中丢失的数据包数量。由于它像历史丢失模式一样直接受网络条件的影响,因此可以通过训练有素的 LSTM 网络准确得出丢包数。
如图 2 所示,我们在 LSTM 之后附加了损失计数器,将损失模式转换为丢失数据包的数量。根据预测的丢包数,DeepRS 决定在这个块中应该产生多少冗余包。
延迟反馈
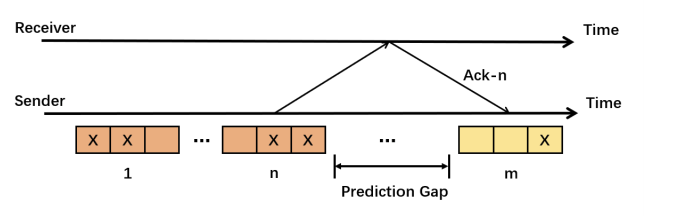
由于RTT的存在,接收方反馈的丢包模式被延迟。当一个视频块即将发送时,DeepRS 无法获取最新的网络状态。因此,我们需要根据一个 RTT 前的丢包率来预测传入的丢包模式。
为了解决这个问题,我们提出了用于预测和推理的块间隙方法,如图 3 所示。在训练步骤中,我们在历史损失模式和要预测的块之间插入一个预测间隙。Prediction Gap包含一些块,其发送时间总共为一个RTT,以模拟网络延迟的影响。在推理阶段,得益于训练阶段Prediction Gap的设计,DeepRS在RTT存在的情况下仍然可以工作
实验和评估
为了验证 DeepRS 的效率,作者对模拟跟踪和真实的互联网数据包丢失跟踪进行了基于跟踪的评估。选择原始的 RS 方法作为对比算法, Fix-RS 表示固定冗余率的 RS 算法。评估指标选择丢包恢复率和冗余比。
仿真实验
仿真实验在由 Gilbert-Elliot (GE)信道生成的模拟轨迹上进行。模拟轨迹包含从 GE 通道输出生成的 10,000 个样本。对于每个样本,收集长度为 7b 的输出向量。选择前面 5b 作为输入向量,忽略中间长度为 b 的预测间隙,取长度为 b 的最后一部分作为label。模拟轨迹分为训练集、验证集和测试集,分别占整个数据集的 60%、20%、20%。
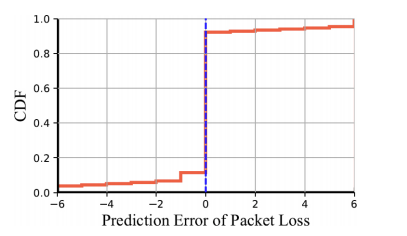
图 5 表明在不同丢包率下,DeepRS 可以通过调整其冗余率来保持其性能稳定,对比算法在较高丢包率下性能很差。
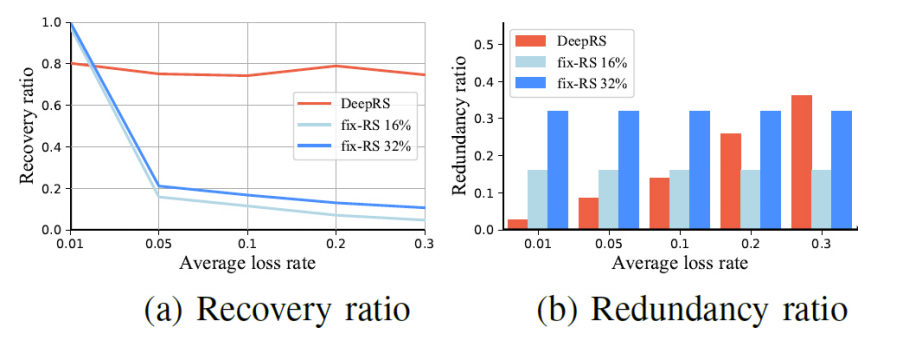
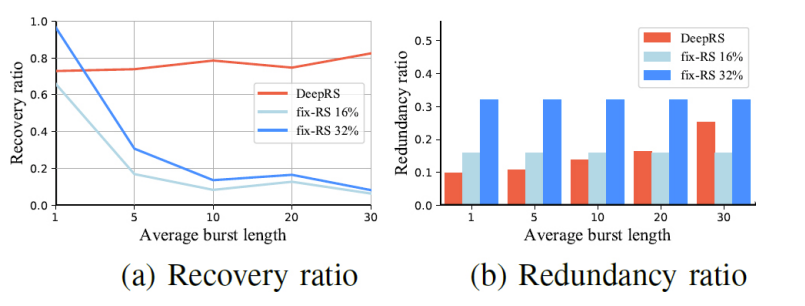
图 6 表明 DeepRS 在具有不同平均突发长度的 GE 信道下可以动态调整其冗余率,从而保持性能稳定,对比算法在较长平均突发长度下性能很差。
真实互联网轨迹的实验
作者从互联网跟踪中提取数据包丢失信息,将 20192 条轨迹分为训练部分、验证部分和测试部分,分别占 60%、20%,20%。
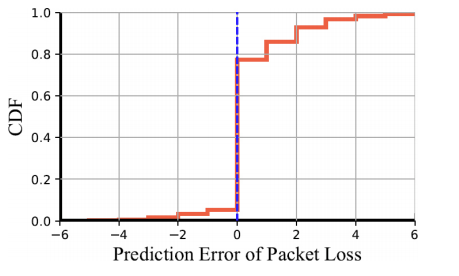
图 7 表明 DeepRS 以大约 70% 的概率准确预测丢包数,这意味着 DeepRS 在真实的互联网环境中也能很好地工作。
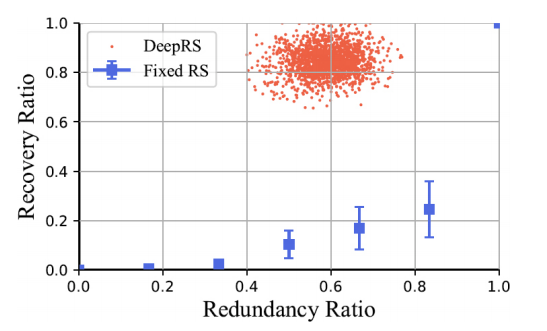
作者探索了恢复率和冗余率之间的权衡,DeepRS 和 fix-RS 的性能如图 8 所示。在本实验中,选择了 7 种不同的 fix-RS 方法作为对比算法,对于每个固定 RS 方法,绘制了 95% 置信区间。DeepRS 明显优于具有固定冗余的传统 RS 编码方法。DeepRS 恢复了大约 80% 的数据包,而 fix-RS 方法对数据包恢复几乎没有帮助。当冗余率相等时,DeepRS 的恢复率是 fix-RS 方法的几倍,这意味着 DeepRS 能够以更少的额外带宽实现更高的恢复率。
结论
作者提出了一种基于深度学习的实时视频流 FEC 系统:DeepRS。DeepRS 主要由LSTM 模型和 RS 编码器两部分组成。DeepRS 在内部嵌入了一个 LSTM 模型,解决了根据历史丢包模式预测近期丢包数量的问题。借助LSTM模型,DeepRS能够自动降低冗余率,以防止低丢包率下的带宽浪费,并在丢包频繁发生时提高冗余率。在实现上,作者对 LSTM 模型进行了修改,使其适应实际应用场景。根据实验和评估的结果,与传统的固定冗余 FEC 方案相比,DeepRS 在冗余率和恢复率之间取得了更好的折衷。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。