
Meta的RTC观测团队旨在创建一个高度可靠的分析平台,该平台能够提供对通话性能的可见性,支持顶层仪表板和指标,并使得对RTC平台进行调试的关键日志可用,该平台每天为数以亿计的用户在多个不同应用程序(如Messenger、Instagram和Oculus)中提供通话服务。我们的首要任务是确保用户数据的隐私,并平衡日志记录的可靠性与效率,以及使合作伙伴的接入过程更加顺畅。通话调试是高效、有效运营RTC平台的一个特别重要的需求。必须有适当的工具,使工程师能够快速识别特定问题的根本原因,并能够对大量通话进行实时分析。本文将提供Meta在此类工具进化方面的一个概览。具体而言,我们将探讨日志隔离所带来的问题,以及我们开发的一种全新的实时数据聚合解决方案,用以解决这些问题。
标题:RTC Observability
视频链接:https://atscaleconference.com/?post_type=video&p=521422
内容整理:陈梓煜
日志记录
提供调试动力的主要数据来源是日志记录。参与通话的所有实体都会生成日志。我们有可以分为以下几类的不同类型的日志:
- 结构化事件:一次性的、有模式的事件
- 快速性能日志(QPL):QPLs用于测量通话流程的性能和延迟
- 控制台日志:轻量级的任意调试信息和错误消息
- 时间序列日志(TSLogs):通话过程中的媒体质量数据,以时间序列格式呈现
为了效率,我们尽可能利用Meta的标准日志平台。标准日志平台主要支持有模式的日志。日志模式简单,由字段名称和值类型组成。最终,所有不同类型的日志都被转换为有模式的日志,以利用该平台。例如,时间序列日志通过有一个类型为字符串的字段,其中存储了原始日志的所有内容,以base64编码的字符串形式存储。
还需要注意的是,有不同类型的结构化事件日志。例如,客户端在通话开始时发出一个connection_start事件,在通话结束时发出一个call_summary事件,以及通话过程中发出许多其他事件。总的来说,我们最终得到了几十种不同类型的有模式日志。
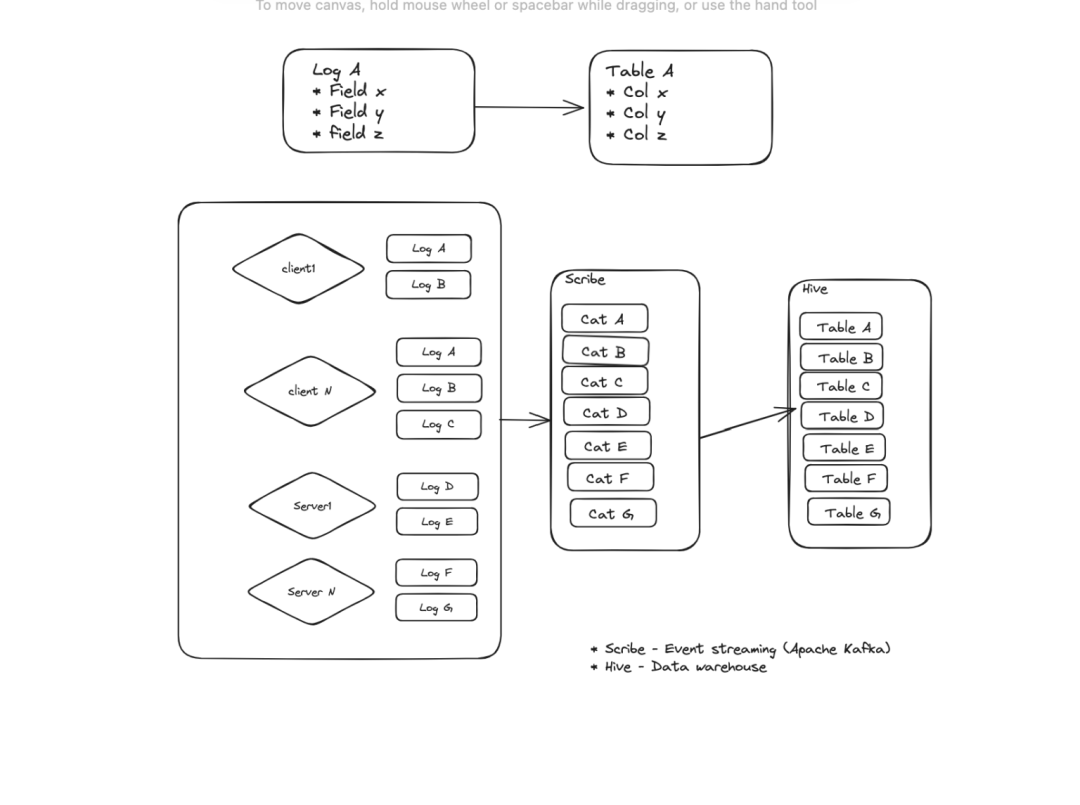

作为标准日志基础设施的一部分,所有有模式的日志首先被记录到Scribe。Scribe是Meta的分布式事件流平台,类似于Apache Kafka。从这里,这些日志事件被流式传输到Meta的数据仓库Hive。日志类型和数据仓库表之间有一对一的映射。一个日志字段一对一映射到一个数据库表。
工具
通话深入调试
最初,为了调试问题,工程师使用标准仓库工具查询日志数据。这很快变得繁琐,因为执行单个通话调查涉及到几十个表。这在为新工程师提供培训时也增加了很大的摩擦,因为他们必须学习并记住不同类型的表存储的名称和相关数据。此外,还不支持对诸如时间序列数据之类的事物进行自定义可视化。作为一种自然的反应,开发了一个名为Call Dive的自定义工具。Call Dive有一个视觉界面,用户可以在其中看到涉及通话的所有日志的概览。他们可以点击一个日志以查看日志数据。此外,根据日志类型,它可以提供自定义的可视化。
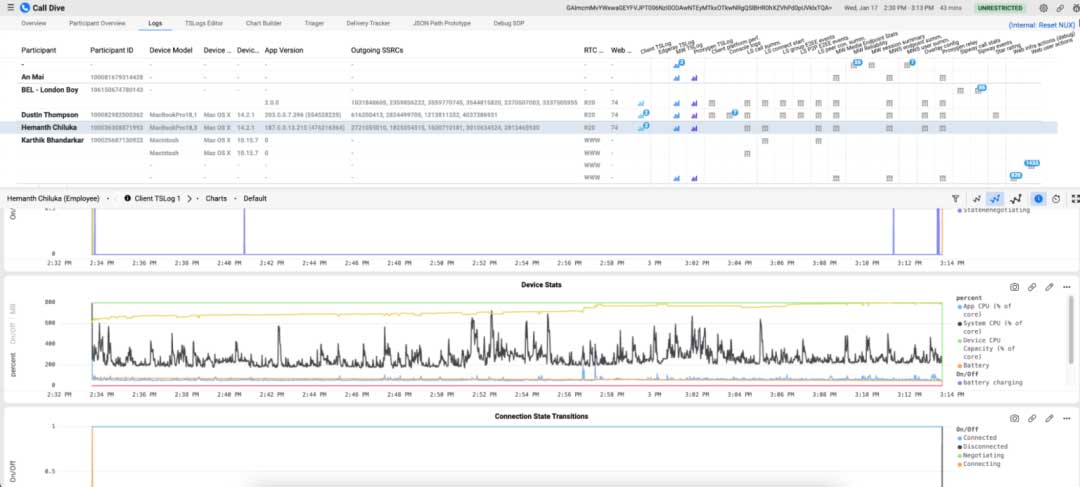
这无疑是一个升级。然而,仍有几个关键的痛点未得到解决。由于Hive是一个数据仓库,它不是设计来支持UI工具的低延迟后端的。P90日志获取延迟可能需要几分钟,而且我们需要发出几十个请求来获取日志以渲染单个通话的UI,很有可能会遇到P90延迟。Call Dive UI的初始页面加载需要访问所有日志,导致它极其缓慢。
此外,数据在Scribe到达后到落地Hive之间有相当大的延迟。尽管这一点随着时间的推移有所改善,但通常需要数小时。工程师需要在问题报告后等待数小时才能进行调查和修复。这种延迟可能会因人为因素而进一步放大。工程师可能会在此期间参与其他任务,可能不会在很长一段时间内返回处理该问题。
此外,分析日志对于开发和测试周期至关重要。对于分布式系统,这通常是开发和测试的唯一方式。由于反馈循环缓慢,Call Dive无法完全实现其在这个用例中的全部潜力。
实时数据分析
除了能够深入研究单个通话外,还需要能够对大量通话进行快速分析。Meta的RTC平台依赖于许多不同产品中的RTC服务器组件和许多客户端版本之间共享的基础设施。这与Meta的持续部署模型和庞大的用户群相结合,导致问题经常被频繁报告,并可能意外出现。因此,为了确定报告问题的影响并确定我们的响应优先级,我们通常需要工具来对大量数据进行实时数据分析。此外,需要进行趋势分析,以隔离特定于某些产品和版本的问题,并将趋势变化与系统的众多组件之一的部署相关联。幸运的是,这个问题不仅限于RTC,许多公司团队都有共享此问题,并且已经存在标准工具来解决它。
由于这些工具是共享基础设施的一部分,可以通过简单的配置更改来启用支持。然后,工具可以从Scribe流式传输日志数据,类似于从Hive流式传输的方式,并写入到它们自己特定的后端数据库。再次,日志类型和这些数据库中的表之间有一对一的映射。与使用Hive不同,数据通常是实时读取的,并且为了优化特定用例而进行采样。然而,这些后端的一个限制是,它们不支持表之间的连接。因此,工程师无法使用它们来进行需要不同类型日志数据的分析,这通常是必要的。类似于涉及Hive的情况,即使分析不需要来自多个表的数据,工程师仍然需要处理记住不同日志类型的名称和它们存储的数据以进行调查的认知负担。
实时日志聚合
影响实时分析工具和Call Dive可用性的关键根本原因是不同日志类型的隔离。因此,我们设计了一个名为RAlligator(实时日志聚合的简称)的新系统来解决这个基本问题。
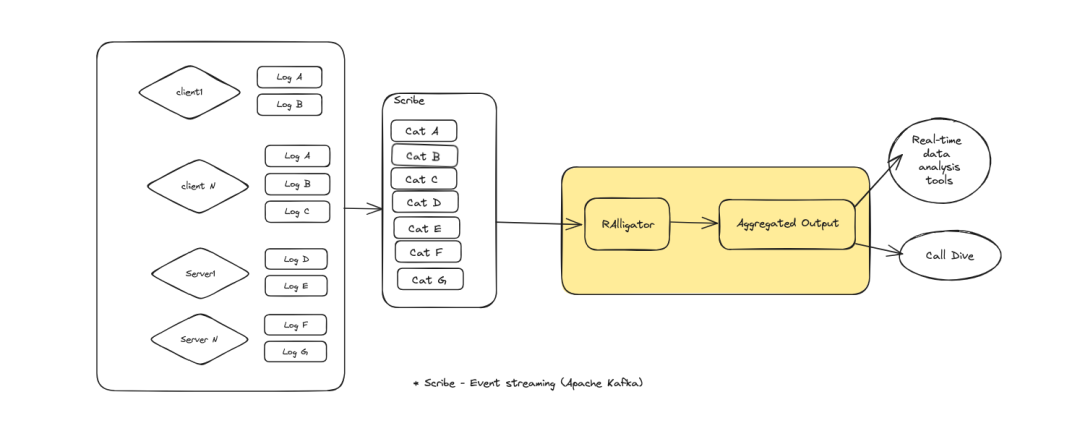
RAlligator旨在尽可能利用现有的日志记录。它从Scribe读取数据,并为Call Dive和实时数据分析工具产生聚合输出,供它们使用。
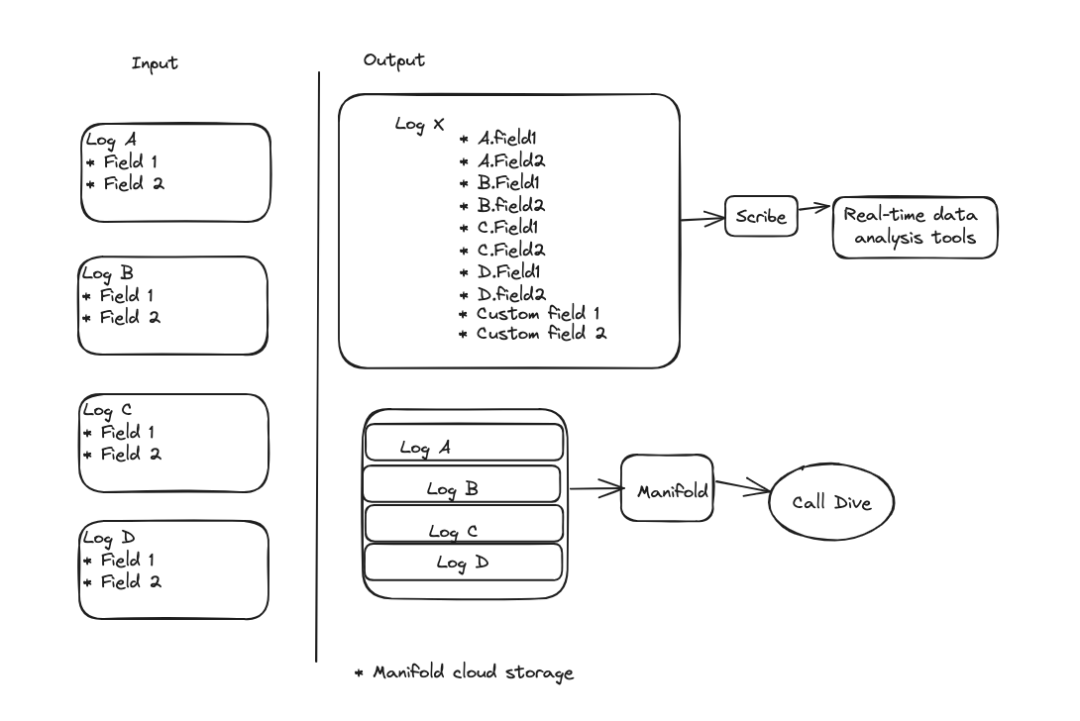
所有输入日志共享一些公共字段,包括通话标识符。这可以用来聚合属于同一通话的不同日志类型,并产生两个输出。第一个输出是一个新的聚合输出日志,由输入日志的每个字段组成。这实际上执行了一个基于通话标识符的所有表/日志的连接。这个新日志也利用标准日志平台,因此它的数据会传到Scribe,然后到我们的实时数据分析工具的后端。第二个输出是所有原始日志事件的列表,这些日志事件存储在我们的云存储Manifold中的一个文件里。这使得所有日志可以通过仅一次请求就被获取,从而消除了Call Dive UX面临的需要发出数十个请求的性能问题。此外,如果日志还未写入Manifold,它们可以直接从RAlligator内存中提供给Call Dive,这消除了日志写入与在Call Dive中查看它们之间的任何延迟。
RTC平台架构
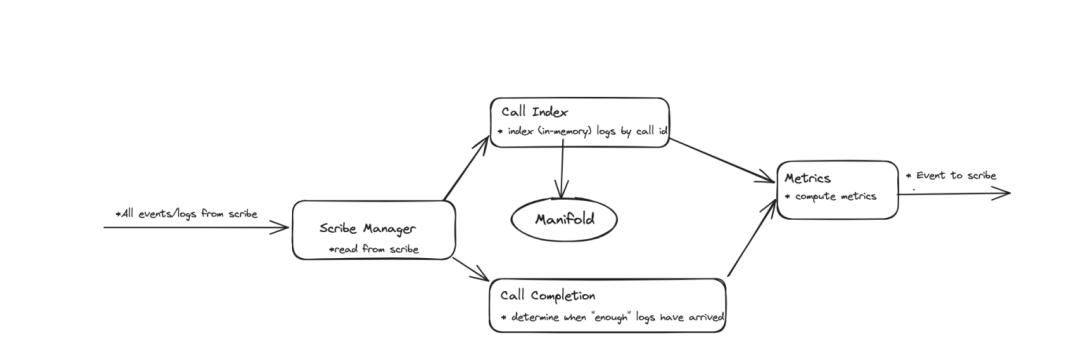
- Scribe管理器:负责从Scribe读取数据。
- 通话索引:内存中的键值存储,键是通话标识符,值是各种类型关联日志的列表。
- 通话完成:用于判断已接收到足够的通话日志且可以处理然后刷新到Manifold以释放内存的启发式方法。
- 指标:从输入日志提取字段,计算任何附加的自定义指标,并输出一个聚合日志。
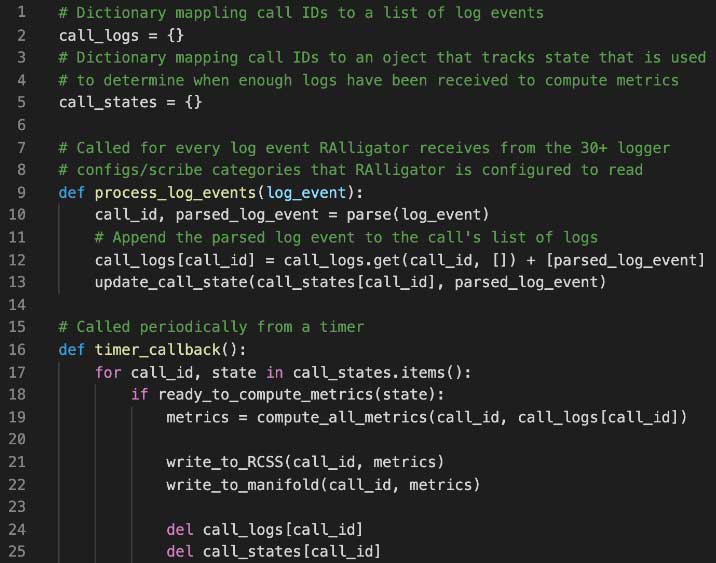
整个系统可以分为输入和输出两部分。输入部分实时从Scribe读取所有日志数据,然后根据通话标识符在通话索引中索引数据。它还填充一些每次通话的内部账本信息,如最后一条日志的到达时间和收到的不同类型的日志。输出部分定期在计时器上运行,由通话完成的启发式方法组成,该方法使用账本信息来识别已收到所有日志的通话。这些通话被从索引中移除并用于生成聚合输出。这可以用伪代码表示如下:
挑战
通话完成
RAlligator将聚合数据存储在内存中。它是一个内存受限的系统。我们清除日志的速率必须与输入日志的速率相同或更低。否则,由于我们处理的数据量巨大,主机会很快耗尽内存。
从这个角度看,我们希望尽可能快地完成然后清除日志。然而,这与完全聚合一个通话的所有日志以产生两种聚合日志输出的要求相冲突。另一方面,快速清除数据的需求与我们尽可能快地产生聚合输出以最小化开始调查的延迟的愿望一致。通话完成的启发式方法负责实现这种精细平衡。
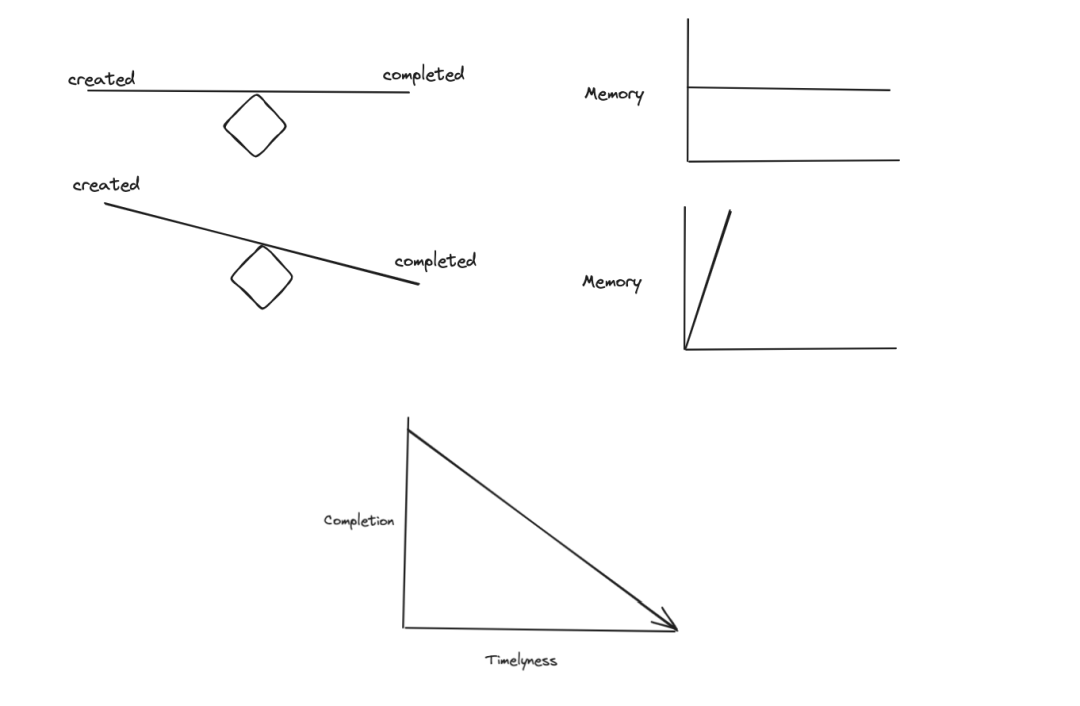
通话完成的启发式方法做出了一个基本假设来实现这一点。它假设日志是在通话结束或更早之前写入的。然而,由于平台问题,日志可能会迟到或根本不到达。特别是,由于客户端带宽/网络问题,客户端日志的可靠性和延迟经常会降低。我们必须遵守合作伙伴应用程序(如IG、Messenger等)的规则,日志只在选定的时间和特定条件下上传,比如在有足够wifi可用时,以避免干扰应用性能和增加用户的网络成本。
实际上,我们观察到了不同类型日志的延迟。我们发现服务器日志的可靠性相当高:几乎100%的日志在写入后几秒内到达。服务器日志用来确定通话何时结束以及预期接收哪些客户端日志。如果在达到某些超时之前没有收到预期的客户端日志,客户端日志永远不会到达的可能性很高。这些超时基于客户端日志到达时间的实际测量的p99、p95、p90和p50延迟。为了确保可靠性,我们必须持续监控日志到达的延迟,并确保这些假设不被违反。
虽然有点棘手,但我们已经能够可靠且成本效益地做到这一点。RAlligator可以在有限数量的机器上运行并处理所有数据,还有足够的成长空间。大约90%的聚合输出在接收到服务器日志后的10分钟内写出。

在图8中的示例中,大约95%的聚合数据已完成,意味着所有到达的日志已被分组到一个单独的聚合输出中。另外5%分到另一个额外的聚合输出中。这对我们的用例来说是非常合理的。
状态管理
RAlligator是一个有状态系统,因为它将通话完成和聚合日志数据存储在内存中。这增加了由于部署或计划维护导致的重启时必须对状态进行快照的额外复杂性。这简单地通过在关闭前将状态卸载到Manifold并在重启后重新加载来处理。
这里的关键挑战是处理在没有优雅关闭的情况下发生的意外崩溃。这通常导致内存中的聚合数据丢失。可以实施一种回填解决方案,该方案从Scribe重新播放数据。然而,通常的重点是尽量减少这种情况,因为任何回填解决方案都会延迟聚合输出的到达时间,这与我们最小化该延迟的要求相冲突。
值得注意的是,我们探索了使服务无状态并在我们的分布式键/值存储ZippyDB中存储状态的替代方案。由于相关成本高昂,这一方案被放弃。
总结
Meta的RTC可观测性依托于标准的日志基础设施。一个单独的通话会产生来自各种客户端和服务器的数十个日志。标准基础设施是一个很好的构建块和起点,但它有局限性。特别是,它无法直接支持用户友好的通话调试体验。支持通话调试的两个主要工具面临性能问题和功能缺口:
- Call Dive UX在获取来自数十个表的日志时需要花费几分钟才能加载。
- 日志直到几小时后才能对Call Dive可用。
- 由于缺乏对连接的支持,实时数据分析工具的分析类型受到限制。
这些问题的一个关键根本原因是日志隔离。为了克服这些挑战,开发了RAlligator这一实时日志聚合后端来补充标准日志基础设施。现在,随着实时日志聚合解决方案的部署:
- Call Dive UX在几百毫秒内加载。
- 日志一到达即可供Call Dive使用。
- 为我们的实时分析工具生成了一个新的聚合表,有效地起到了连接的作用。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。