
1.视频行业趋势
5G、云、AI 已经成为ICT 行业甚至是整个社会的发展趋势,促使整个视频行业需求和技术不断演进,推动整个视频行业不断升级。视频生命周期的每个环节都在更新升级,包括视频生产、视频处理、视频传输和视频消费。
视频生产:多源数据的采集,包括超高清、VR、自由视角、3D建模和视频渲染
视频处理:基于 AI 让视频处理更实时、智能和准确,包括各种编码方式
视频传输:超低时延的传输,云边协同等等
视频消费:智能终端的深度结合提供视频服务的最佳体验
视频行业本质是对媒体数据的处理,背后是算力、存储、网络、AI 的支撑,同时视频行业又推动着5G、云、AI 的不断前行,相辅相成!
2. 深度学习融入视频增强领域
随着深度学习和AI的算法和算力的增强,衍生出视频增强特别是超高清领域类的新的玩法,本文主要介绍目前两种典型的能力:视频插帧和超分辨率重建。
3. 深度学习视频帧插值
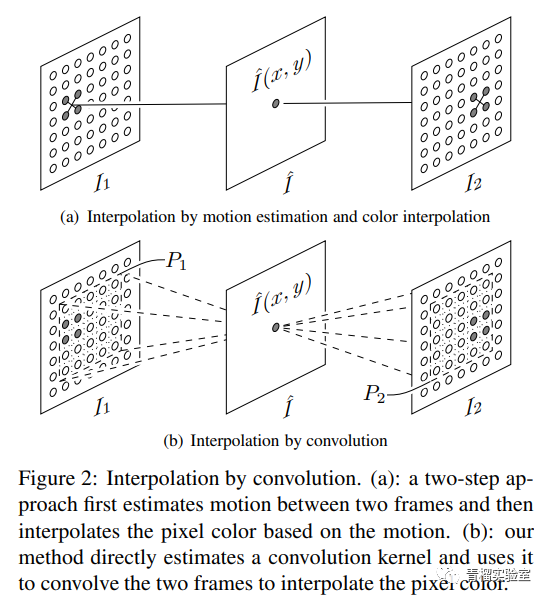
我们将研究旨在在现有视频中合成视频帧的深度学习论文。这可以在视频帧之间(称为插值),也可以在视频帧之后(称为外插)。插值在软件编辑工具以及生成视频动画中很有用。它也可以用于在视频模糊的部分生成清晰的视频帧。视频帧插值是非常常见的任务,尤其是在电影和视频制作中。光流是解决此问题的常用策略之一。光流估计是估计帧序列中每个像素运动的过程。在本文中,我们将研究使用深度学习技术的视频帧插值的高级方法。这里主要介绍两种主流的插帧方法:
3.1. 通过自适应可分卷积进行视频帧插值
该网络具有两个输入帧,并为所有像素估计成对的一维内核。该方法能够估计内核并立即合成整个视频帧。这使得可以合并感知损失来训练神经网络,以产生视觉上吸引人的帧。其目的是在两个视频帧的中间插值一个新帧。然后,基于卷积的插值方法估计一对2D卷积内核。然后将其用于对两个视频帧进行卷积,以计算输出像素的颜色。像素相关的内核同时捕获插值所需的运动信息和重新采样信息。通过将信息流引导到四个子网中,可以估算出四组一维内核。每个子网估计一个内核。整流线性单元与3×3卷积层一起使用。


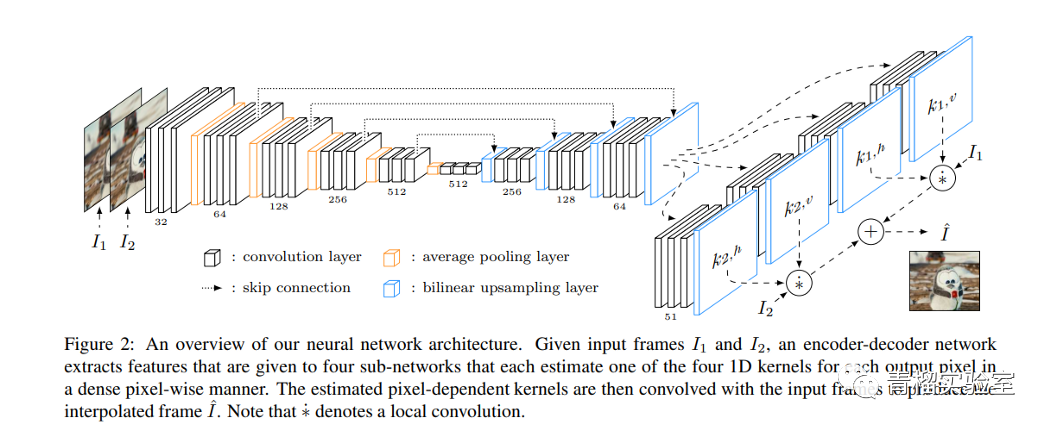
使用AdaMax优化器对网络进行了训练,学习率为0.001,最小批量为16个样本。数据扩充是通过随机裁剪来执行的,以确保网络没有偏见。卷积神经网络的实现是使用Torch完成的。与其他模型相比,此模型的性能如下。
3.2 通过自适应卷积的视频帧插值
将运动估计和像素合成结合到单个过程中进行视频帧插值,实施了深层全卷积神经网络,以估计每个像素的空间自适应卷积核。
对于内插帧中的像素,深度神经网络将以该像素为中心的两个感受野斑块作为输入,并估计卷积核。卷积核用于与输入补丁进行卷积以合成输出像素。给定两个视频帧,此模型旨在在它们之间创建一个临时帧。
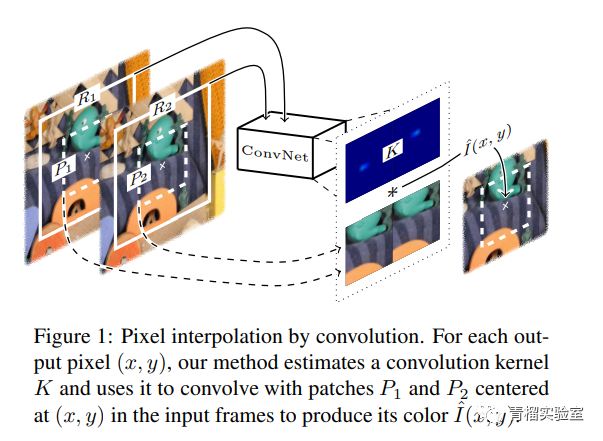
该方法直接估计卷积核,并使用该卷积核对两个帧进行卷积以插值像素颜色。像素合成是通过卷积内核捕获运动和重新采样系数来完成的。像素插值作为卷积使像素合成可以在单个步骤中完成,这使该方法更加可靠。
卷积神经网络由几个卷积层和向下卷积组成,以作为最大池化层的替代方案。为了进行规范化,作者使用ReLU作为激活和批处理规范化。下表说明了此网络的体系结构。

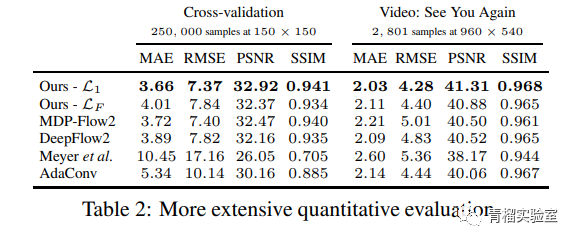
该模型是使用Torch实现的。这是模型的性能:
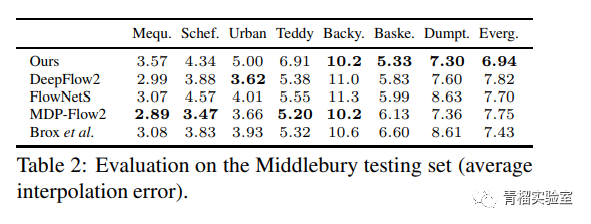
以上介绍了目前两种主要的插帧方法,大体的介绍了理论依据和训练和实际运用的效果。
4.深度学习超分辨率重建
旨在从低分辨率图像中恢复高分辨率图像(或视频)的超分辨率(Super Resolution)是计算机视觉中的经典问题,在监视设备,卫星图像和医学成像中具有重要的价值。
Super Resolutio是一个反问题,因为对于任何给定的低分辨率像素都存在多种解决方案。通常通过强先验信息约束解决方案空间来缓解这种问题。在传统方法中,可以通过出现几对低高分辨率图像的示例来学习此先验信息。基于深度学习的Super Resolutio通过神经网络直接学习分辨率图像到高分辨率图像的端到端映射功能。
定量评估SR质量的两个常用指标是峰值信噪比(PSNR)和结构相似性指标(SSIM)。这两个值越高,重建结果的像素值就越接近黄金标准。
以下是一些经典的深度学习Super Resolutio方法:
4.1 SRCNN
较早提出超分辨率卷积神经网络作为SR的卷积神经网络。网络结构非常简单,仅使用三个卷积层。
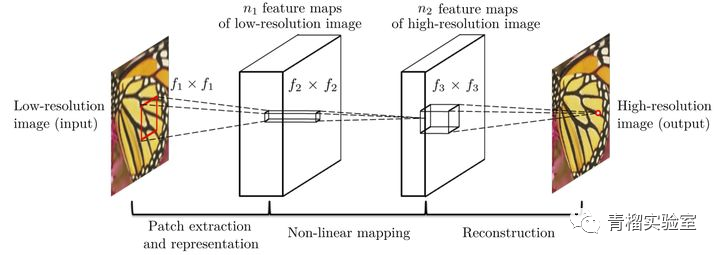
该方法首先对低分辨率图像使用双三次插值法将其放大到目标尺寸,然后使用三层卷积网络进行非线性映射。
下图显示,在不同放大倍数下,SRCNN的效果要优于传统方法。
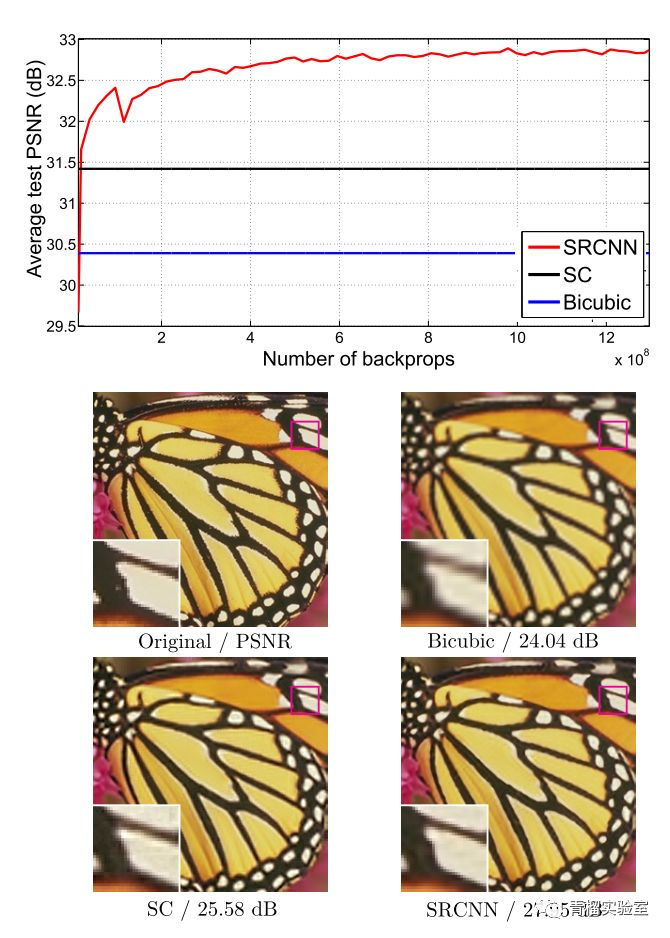

除了最早将CNN用于Super Resolution问题外,作者还将三级卷积的结构解释为与传统Super Resolution方法相对应的三个步骤:图像块提取和特征表示,特征非线性映射以及最终重建。
4.2 DRCN
SRCNN的层数较少,因此视野较小(13×13)。DRCN(用于图像超分辨率的深度递归卷积网络,CVPR 2016,代码)提议使用更多的卷积层来增加网络接受域(41×41),并避免使用过多的网络参数,本文建议使用递归神经网络( RNN)。网络的基本结构如下:
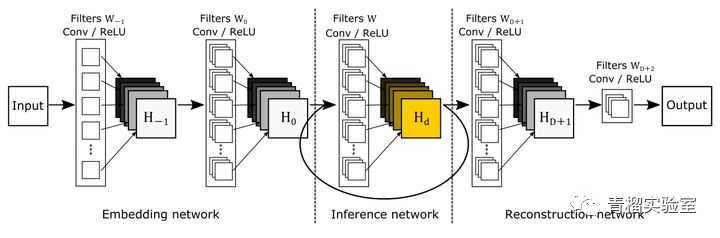


以上介绍了目前两种主要的超分辨率重建方法,大体的介绍了理论依据和实际使用的实验数据。除了以上两种,目前业界还有包括ESPCN,VESPCN等等应用于Super Resolution的方法。
5.总结
以上是目前我们将深度学习应用于视频增强技术中的一些探索,随着AI和深度学习的快速发展,有更多的算法和模型不断的产生和发展,我们也将持续的跟进和研究。
作者:张文俊
来源:青榴实验室—超高清音视频技术的传播者
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。