
近日,Meta推出了一种名为Voicebox的生成式人工智能文本转语音 (TTS) 工具,声称它可以生成语音,速度比当前技术水平快20倍,并且只需两秒钟的录音时间。根据Meta的说法,用Voicebox制作的深度伪造声音(Deepfake voices)非常好,以至于它不会公布所有的代码,甚至还想出了一种检测人工智能生成的音频的方法。

VOICEBOX AI
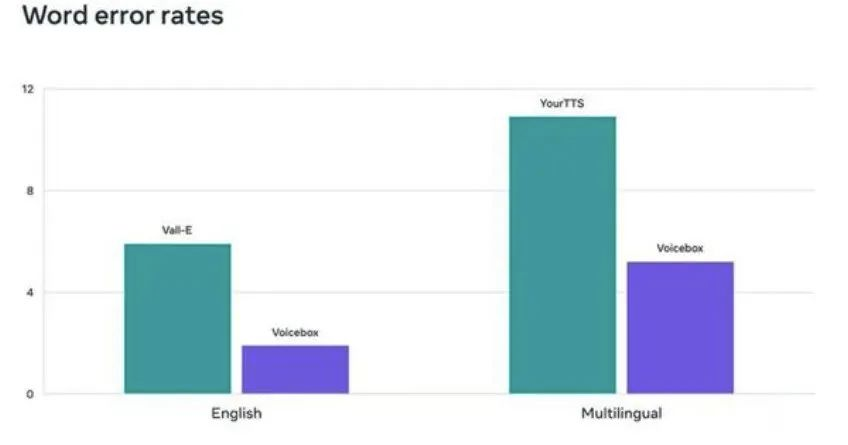
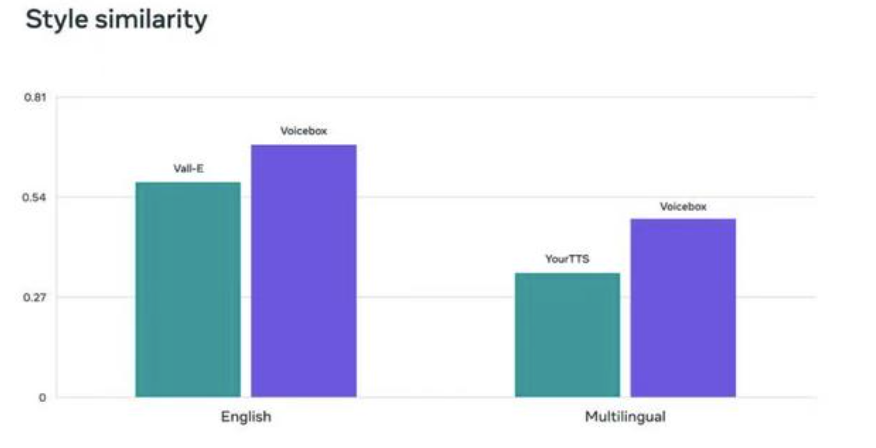
TTS模型通常需要精心策划且相对较小的标记数据集进行训练,因为音频质量会随着数据集的增长而降低。Voicebox通过使用Meta所描述的可以处理音频信息“填充”的架构来克服这一限制。用于磨练Voicebox语音合成功能的大型未标记数据库类似于ChatGPT和其他大型语言模型使用的数据库,这使Voicebox能够模仿说话者的声音来阅读文本,包括多种语言,甚至用合成版本替换噪音过多的音频。
Voicebox对个人进行深度伪造的能力足够好,以至于Meta表示担心“滥用的潜在风险”。因此,Meta还创造了一种识别何时使用Voicebox合成语音的方法,这是一种用于自己创建的深度伪造音频检测器。这与Reslikele AI开发的音频水印不同,后者可以在不降低质量的情况下将录音识别为真实而不是合成。同样的担忧导致Meta阻止了Voicebox的模型及其背后的代码,限制公众只能访问一些样本和随附的研究论文,Meta表示这有助于“在开放与责任之间取得适当的平衡”。据推测,自其LLaMA生成AI模型泄露以来,Meta已经提高了其内部安全性。
“作为第一个成功执行任务泛化的多功能、高效模型,我们相信Voicebox可以开创一个生成式语音人工智能的新时代。与其他强大的新人工智能创新一样,我们认识到这项技术带来了滥用和意外伤害的可能性,“Meta在其公告中写道。“在我们的论文中,我们详细介绍了我们如何构建一个高效的分类器,可以区分使用Voicebox生成的真实语音和音频,以减轻这些可能的未来风险。
生成式合成媒体(GENERATIVE SYNTHETIC MEDIA)
合成语音有很多用途,而生成式人工智能只是扩展了这些可能性。来自ElevenLabs和Play.ht等初创公司的深度假声音不断提出更好,更便宜的合成语音平台。实验的温床已经证明了合成语音产生人工智能女友、合成歌曲和歌手、假播客剧集、模仿广告等的能力。大品牌也没有忽视潜力。Spotify创建了一个具有合成声音的AI DJ,并希望使用它们来增强其播客广告,而流媒体服务Deezer正在研究如何发现和删除AI生成的歌曲。Meta对如何使用Voicebox有很多想法,并且正在努力将该技术嵌入到未来的产品中。
“未来,像Voicebox这样的多用途生成AI模型可以为元宇宙中的虚拟助手和非玩家角色提供自然的声音。它们可以让视障人士听到人工智能用他们的声音朗读的朋友的书面信息,为创作者提供新的工具来轻松创建和编辑视频的音轨等等,“Meta 写道。“Voicebox是我们生成人工智能研究向前迈出的重要一步,我们期待继续在音频领域进行探索,并了解其他研究人员如何在我们的工作基础上再接再厉。
信息源于:voicebot.ai
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。